语言交流在我们的社会生活中扮演着重要角色,因此,文本分析被广泛地应用于社会科学研究中。随着社交媒体大数据时代的到来,计算社会科学兴起,传统文本分析逐渐从手工编码过渡到数据驱动的大规模文本分析。在集智俱乐部「计算社会科学第二季第七期」,密歇根大学安娜堡分校信息科学在读博士裴嘉欣以量化语言亲密度的研究为例,介绍自然语言处理的基本流程,并重点讨论了如何将传统的手工编码拓展到大规模自动化的文本分析。以下是此次读书会内容的整理。
集智俱乐部「计算社会科学读书会第二季」由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友报名参加!
裴嘉欣 | 讲者
秦晓艳 | 整理
邓一雪 | 编辑
语言在社会生活中扮演了很重要的角色,人与人之间的交流、法律条文、社会组织、人的思考等,都是以语言为载体进行的。同时语言在社会科学研究中也非常重要,例如:社会学中会研究性别词汇在不同场景中的表达;传播学中对新闻、社交媒体的讨论;心理学中对人际沟通、辩论、观点和态度的研究;政治学中对政治观点的研究,均与语言(文本)相关。因此,文本分析被广泛地应用于传统的社会科学研究中。
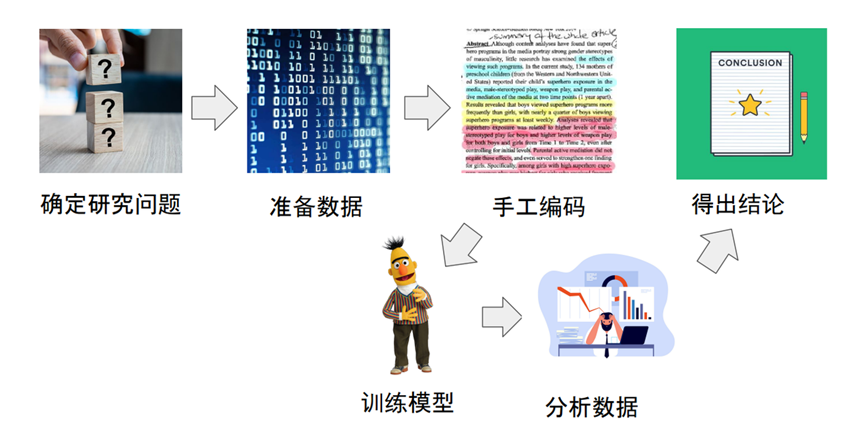
在传统的社会科学研究中,文本分析主要分为4个过程:确定研究问题;准备数据;手工编码;得出结论。
随着计算社会科学的兴起,研究中使用的数据规模增大,传统文本分析存在一定的局限性:
(1)数据规模小。由于传统文本分析采用手工编码,因此可以处理的数据量级限制在100~10k;
(2)很难被重复使用。对于任何一个哪怕是类似的问题,都需要重复的编码;
(3)可复现性差。手工编码过程受到编码人员个人经验的影响,其他研究者很难复现和验证其他人所做的工作。
因此,传统文本分析逐渐从手工编码过渡到大规模文本分析。
大规模文本分析的基本流程包括:确定研究问题;准备数据;手工编码;训练模型;分析数据;得出结论。
可以看出,与传统文本分析相比,大规模文本分析中的手工编码是数据驱动的,并且手工编码的目的不再是为了直接得出结论,而是为了训练模型,进而将模型应用于数据中,这一过程使得文本分析不再受到数据规模的限制。以下详细阐述大规模文本分析的每个阶段。
确定研究问题应该从大的角度出发。例如,我们可以研究“什么样的微博会获得更多点赞”,这是一个切入点较大的问题,其数据量也较大,得出的模型适用于多个微博用户场景;而如果我们研究“Papi酱微博评论的点赞分析”,这便是一个切入点较小的问题,最终的研究结论很难适用于其他的微博用户,其研究数据量小,是一个传统的文本分析问题。
确定研究问题应该从理论出发。例如“人类群体的情感是如何在一天之内变化的”是一个建立在理论根基上的研究问题;而“基于Python的微博情感挖掘”是一个仅仅基于工具和模型而脱离理论根基的问题,其研究意义不大。
确定研究问题还应该从可获取的数据出发。目前在计算社会科学中取得重要研究成果的领域集中在社交媒体、新闻、科学领域等,可以发现,这些领域都拥有很多数字化的数据,便于研究者进行深入研究。
准备数据主要包括数据收集和数据预处理。在数据收集阶段,我们需要从研究问题出发确定数据,确保数据有一定的代表性和可挖掘性。同时,原始数据中的脏数据将会对结果的准确性产生影响,一般需要对无效数据、机器人数据、确实数据和非特定语言数据等类型的脏数据进行预处理。
数据驱动的手工编码阶段首先需要进行采样,采样的同时需要考虑类别不平衡问题对模型结果的影响;其次,确定明确的编码方式和清晰的标注规则,进而确定标注人员和标注系统,标注人员可以选择学生、专业人员和众包平台等,常见的众包平台有 Amazon mechanical turk 和Prolific。以上完成之后,由于标注中会有很多未知的因素,需要通过不断地预先试验来确定最优的标注方案,最后采用一致性检验衡量试验标注和最终标注的质量。
训练模型阶段需要根据任务的不同选择不同的模型。基于词的模型,例如:Bag of Words/embedding + Linear model/SVM,速度较快但模型效果较差。预训练语言模型,例如Bert、Roberta等,模型准确率高但速度较慢。
最后,可以将得到的模型用于更大的数据集上进行数据分析,研究感兴趣的话题或者社会现象,进而得出结论。
3. 量化语言亲密度:
性别、社交距离和匿名性的影响
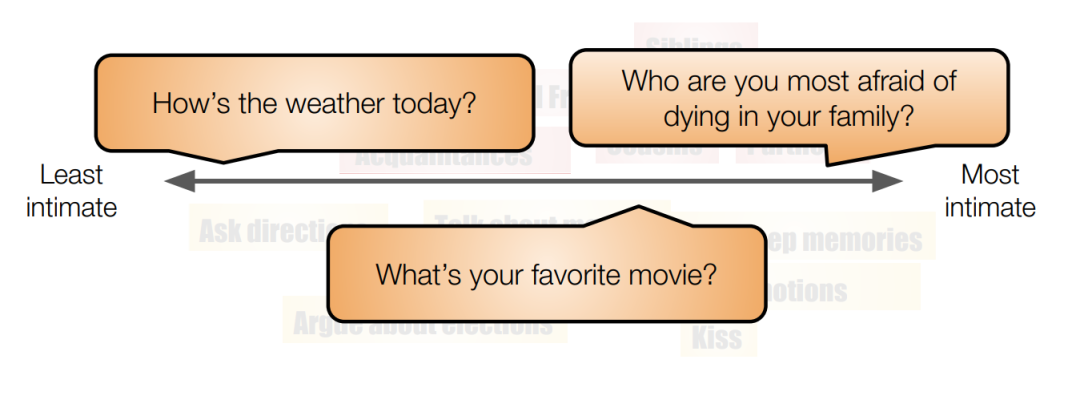
现实生活中,我们会对不同的人问不同的问题。例如:“在你的家庭中,你最担心谁先去世”,这是一个比较亲密的问题,我们更倾向于问关系亲密的朋友或家人,却很少问陌生人;在向陌生人打招呼时,“今天天气怎么样”似乎不利于话题的深入,我们更倾向于选择“你最喜欢的电影是什么”,这样的问题更有利于话题的深入和彼此的初步了解。
因此,我们产生两个感兴趣的话题:这些问题有什么不同? 什么因素决定这些问题的合适性?我们将其看作一个计算社会科学与文本分析相结合的研究,将基于大规模文本分析的基本流程展开研究和讨论。
为了衡量这些问题的不同,我们引入心理学中“亲密度”的概念。在社交关系中,我们与陌生人的亲密度低,与恋人、家人之间的亲密度高;在社交行为中,问路、握手是亲密度较低的行为,接吻、拥抱是亲密度较高的行为。因此,基于研究背景可知,在语言中,“在你的家庭中,你最担心谁先去世”是一个亲密度较高的问题,“今天天气怎么样”是一个亲密度较低的问题,而“你最喜欢的电影是什么”的亲密度介于前两者之间。因此可以定位研究问题:如何量化语言中的亲密度?
围绕“如何量化语言中的亲密度?”这一问题,在 r/AskReddit 平台上收集了近300万个问题,并且根据不同月份进行采样,每个月采样1000个问题,便于后续进行数据标注。
由于每个人对亲密度的感知和衡量亲密度的尺度不同,标注问题的亲密度是一个挑战,为确定明确的编码方式和标注规则,采用 Best-Worst-Scaling 方法来标注亲密度:标注者被要求选择最亲密和最不亲密的问题;其次通过标注的亲密度产生问题对之间的比较,进而采用排序算法计算出每个问题的亲密度得分,实现了量化语言中的亲密度的过程。
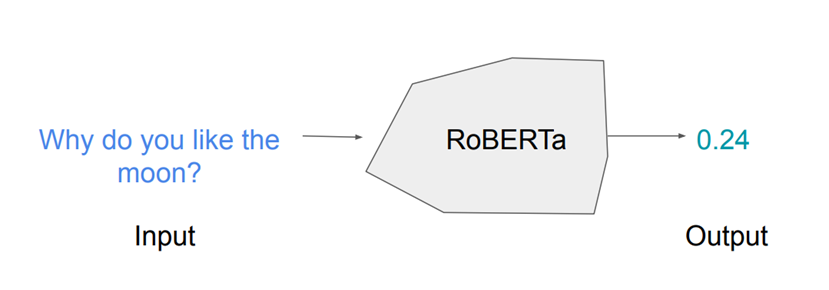
基于标注完成的数据,训练预测亲密度的 NLP 模型,称之为RoBERTa模型。由图可以看出,该模型的输入为某一个问题,输出为该问题的亲密度评分。
以上完成了基于采样数据的数据标注及模型训练,模型可以预测某个问题的亲密度,完成了量化语言亲密度的工作。进而我们可以将模型应用于更大的数据集上,分析决定问题合适性的因素是什么,进而得出结论。该研究定位三大可能的因素:社交距离、性别和匿名性。
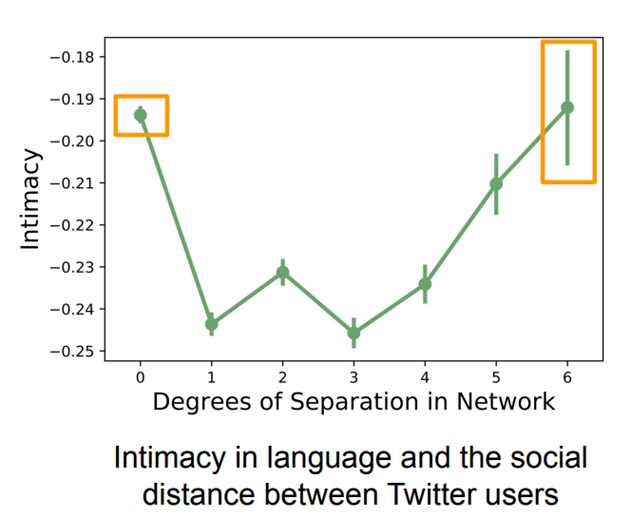
首先研究了社交距离对人与人之间的问题亲密度的影响。采用人与人在社交网络中的分割度表示社交距离,研究了社交网络中的分割度与语言亲密度的关系,如下图。图中的横坐标代表人与人在社交网络中的分割度,分割度越小,则存在更加直接的联系;纵坐标则为亲密度。曲线整体呈U型,说明了“最亲密的关系发生在关系最亲密的朋友之间以及完全的陌生人之间”,前者普遍发生于人与人的交往中,而后者说明在与陌生人交往的过程中,随着分割度的增加,人们逐渐打破了交往的社会约束,因此最亲密的关系也有可能发生在完全的陌生人之间。
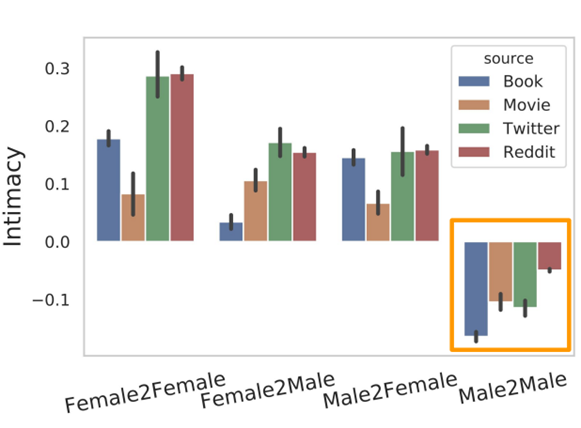
其次研究了性别对人与人之间的问题亲密度的影响。主要研究了“男性对男性”、“女性对女性”、“男性对女性”、“女性对男性”四个性别组在四个不同平台上的亲密度,如下图可知, 不论在哪个平台,男性之间的对话是最不亲密的,说明男性之间存在更强的社会约束。相比而言,女生与女生之间的对话亲密度最高,说明女性之间的对话更容易打破原有的社会约束。
最后研究了匿名性对人与人之间的问题亲密度的影响。首先说明三类匿名身份:Depersonalized accounts:账号中没有明确的身份标记;Name Containing:账号中仅包含与个人身份相关的用户名;Anonymous accounts:账号中包含“throwaway” 或“anonymous”字样。研究了三类匿名身份与亲密度的关系,发现账号类型为Anonymous的账号会问最为亲密的问题,而即使账号中仅包含与个人身份相关的用户名时(Name Containing),人们也不会提出较为亲密的问题。说明只有当人们完全脱离社会约束时,才会问一些更加亲密的问题。
在大数据时代以及计算社会科学的研究背景下,传统的手工编码逐渐过渡到大规模文本分析,大规模文本分析主要通过预先训练模型,进而将模型应用于更大规模的数据集上来分析数据,克服了大规模数据集上传统文本分析手工编码困难、很难被重复利用、可复现性差的局限性。因此,大规模文本分析被逐渐应用于计算社会科学的研究中,例如语言中的亲密度研究,通过大规模文本分析量化了语言中的亲密度,进而研究了语言亲密度的影响因素,得出了一系列可解释性的结论,在心理学、计算社会学科学和自然语言处理领域具有较大的研究价值与意义。
裴嘉欣,密歇根大学安娜堡分校信息科学博士在读,研究方向为计算社会科学和自然语言处理,致力于构建新的自然语言处理模型来分析大规模人类行为,目前主要关注人际传播和科学传播,相关成果发表于ACL, EMNLP, WWW等会议。
https://jiaxin-pei.github.io/
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
新一季【计算社会科学读书会】由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动