大数据因果推断:数据驱动式学习下的因果混淆去偏算法

导语
随着计算机科学技术的发展,大数据驱动因果推理和因果指导的可信机器学习正在成为多学科交叉融合的趋势。大数据驱动的因果推理旨在通过机器学习赋能因果推理,因果指导的可信机器学习旨在从大数据关联中恢复因果关联,实现因果指导的可信机器学习。
浙江大学计算机学院况琨老师课题小组结合最新研究工作,介绍大数据驱动因果推理和因果指导的可信机器学习。本文针对数据驱动式的统计学习模型,总结了大数据下统计机器学习中潜在的由混淆因素带来的虚假关联性偏差。结合深度学习算法,回顾了三篇目前较新的混淆去偏模型,这三篇文章分别从混淆数据的来源、不同变量的重要性以及如何考虑未观测到的混淆偏差等方面展开了讨论。
研究领域:因果推断,混淆去偏算法

吴安鹏 | 作者
邓一雪 | 编辑
1. 机遇与挑战
1. 机遇与挑战
“万物皆有联系”是数据驱动式学习的核心思想,在过去的机器学习模式中,尽管关联式学习已经在众多学科领域取得了惊人成就,如模式识别、人脸图像、自然语言处理等。但普遍的现象是,现有的大部分机器学习模型过分追求手头收集到的数据训练集和测试集上的性能提升,无约束地利用一切相关关系来学习给定训练集和测试集的数据分布模式,从而导致模型对数据分布外的新环境新任务几乎无法做出有效推理——即,模型泛化能力差。例如:健康铀矿工人效应,在铀矿工作的工人与其它人的寿命一样长(或更长),这并不能说明暴露于铀矿不会影响寿命,而可能是因为铀矿工人是经过挑选出来的身体健壮的人,假若当年他们不暴露于铀矿的话,寿命可能会更长一些。
统计相关性并不等价于因果关系。在数据驱动的模型范式下,传统机器学习算法倾向于直接捕捉大数据相关关系进行模型推理,却忽略了潜在的混淆变量将会导致数据之间的虚假相关和虚假独立,从而导致推理结果不可信。在上述例子中,铀矿工人经由身体素质的挑选,最后影响铀矿工人的寿命,这里身体素质同时影响铀矿工人的选拔以及工人最终的寿命,在因果理论里面,我们将其称之为混淆因素(或成为混淆变量)。在教科书[Pearl J. 2009]中,Pearl将由于数据中存在混淆因素导致结果出现偏差的现象,称之为混淆偏差现象。混淆偏差现象和辛普森悖论选择性偏差现象同为造成统计式机器学习算法泛化能力和鲁棒性模型学习能力差的主要原因。
为此,因果推理提出采用因果视角识别数据中潜在的混淆变量并消除混淆误差,从而提高模型大数据推理的准确性和泛化性。在二值干预场景下,主要研究内容和创新成果如下:(1)面向高维数据,提出了混淆变量识别解耦框架来消除混淆误差;(2)面向高维数据,对混淆变量进行区分性识别并匹配;(3)针对未观测到的隐性混淆变量,提出了工具变量表征识别框架来进行去混淆数据推理。
论文题目:
Learning Decomposed Representations for Treatment Effect Estimation
论文链接:
https://ieeexplore.ieee.org/document/9712445
2. 混淆变量识别
2. 混淆变量识别
论文 Learning Decomposed Representations for Treatment Effect Estimation 认为在现实场景中,以医疗场景(图1)为例,数据的本质可以分解为四个部分:仅影响干预分配的工具变量I、同时影响干预分配和结果的混淆变量C、只影响结果的调整变量A、与干预分配和结果都不相干的无关变量(无关的噪声变量信息将被模型稀释和删除,将不会出现在模型数据流内,因此在图中不进行标注)。通过解耦表征模型(DeR-CFR),我们期望模型在学习到干预分配信息的同时,也能够保留有效的用于预测结果的信息,并剔除无关信息的干扰,相信这能进一步推动大数据领域的发展。
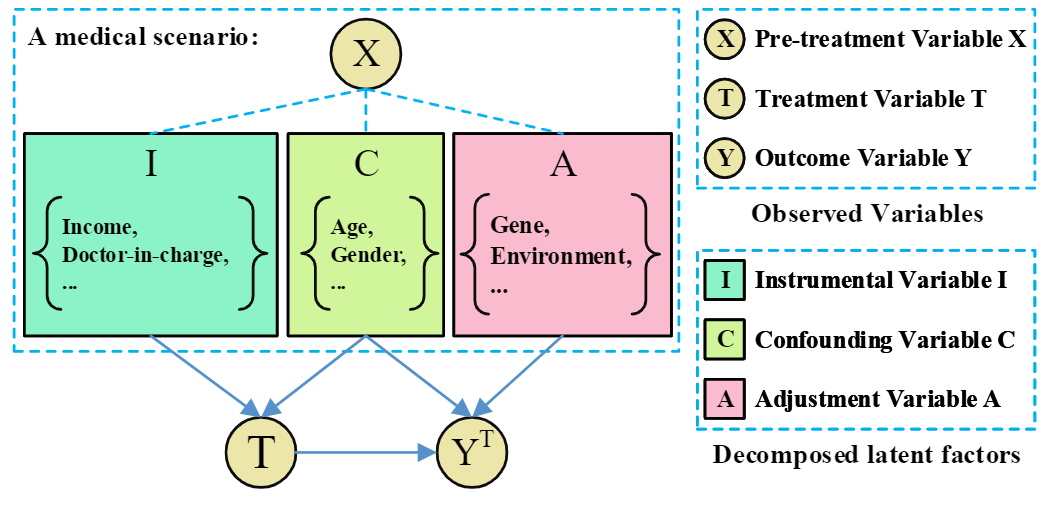
图1 混淆变量识别分离表征框架
其核心思想如下:
调整变量表征分离:基于调整变量只影响结果变量而不影响干预变量的性质,我们可以利用调整变量与干预变量独立的性质来学习调整变量的表征信息A(X),该独立约束将会严格限制工具变量I和混淆变量C的信息进入表征网络A(X)。此外,为了约束调整变量的信息完整全部进入调整变量网络,而不会被像误差变量一样稀疏丢弃,我们还采用gA网络尽可能准确地去使用表征信息A(X)准确预测结果变量Y,从而确保调整变量的信息完整进入表征网络A(X)。
混淆变量表征平衡:经过我们模型的迭代训练,我们将可以识别得到工具变量表征、混淆变量表征以及调整变量表征。但在此之前,我们还需要对混淆变量表征加以平衡,不同于先前的依赖于倾向值准确性的逆倾向值加权法,我们通过神经网络自适应学习一个样本权重进行样本加权,并采用最大均值差异指标(Maximum Mean Discrepancy,MMD)衡量干预组和控制组混淆变量表征分布的差异度量独立指标,当两个分布的差异等于0时,我们可以认为混淆变量的表征分布与干预分配独立,即无论是干预组还是分布组,其混淆表征分布都相同。
工具变量表征分离:基于工具变量只通过影响干预变量从而间接影响结果变量的性质,我们可以利用给定干预变量和混淆平衡,工具变量条件独立于结果变量的性质来学习工具变量的表征信息I(X),该条件独立约束将会严格限制混淆变量C和调整变量A的信息进入表征网络I(X)。此外,为了约束工具变量的信息完整全部进入工具变量网络,我们同样采用一个gI网络尽可能准确地去使用表征信息I(X)准确预测干预变量T,从而确保工具变量的信息完整进入表征网络I(X)。
3. 混淆区分匹配
3. 混淆区分匹配
因果推理的一个基本问题是使用变量混淆的观察数据来估计因果效应。控制混淆偏差的经典方法是匹配具有不同干预但协变量相似的个体。但是,传统的匹配方法无法在众多潜在的混淆变量中进行选择和区分,从而导致性能不佳。通过学习变量和个体匹配的混淆变量权重,提出了一种新颖的区分性匹配(Differentiated Matching,DM)算法,用于估计个体和平均因果效应。
Estimating Treatment Effect via Differentiated Confounder Matching 指出:在匹配法中,因果效应的偏差主要由匹配到的控制个体以及干预个体 的差别所导致。即被选为匹配样本难免会与当前样本有所出入,这导致了结果偏差的引入。因此,为了减小结果偏差,DM算法认为在待匹配的所有变量中也需要进行重要性区分,对结果偏差影响更大的变量应该接受更多的关注。传统的匹配法对所有匹配变量都一概而论,在匹配中,所有变量接受的关注程度都是一致;针对此,DM算法提出一种倾向权重区分性匹配法,考虑不同变量对匹配的重要程度,从而改进匹配机制。

论文题目:
Estimating Treatment Effect via Differentiated Confounder Matching
论文链接:
https://dl.acm.org/doi/abs/10.1007/978-3-030-93046-2_58
4. 工具变量重建
4. 工具变量重建
当前,大部分因果推理文献,几乎都依赖无混淆性假设,即同时影响目标因变量和果变量的混淆变量已经全部观察到了。这在实际场景中,通常是很难保证的,因为我们无法对无观察到的混淆变量进行分析。解决上述未观测到的混淆误差的一个典型方法是引入工具变量,构建两阶段式回归学习,但在现实场景中,工具变量的检验和发现依赖于大量的专家知识以及实验验证。且因为选择过程的人工介入,人类经验是有可能给出错误的工具变量的——即不能严格满足工具变量的三条假设:(1)相关性假设,工具变量和干预变量强相关;(2)排他性假设,工具变量只能通过影响干预变量从而间接影响结果变量;(3)无混淆假设,工具变量与所有的混淆变量都独立。

论文题目:
Auto IV: Counterfactual Prediction via Automatic Instrumental Variable Decomposition
论文链接:
https://dl.acm.org/doi/abs/10.1145/3494568
为了放宽工具变量对人类先验知识的依赖,论文 Counterfactual Prediction via Automatic Instrumental Variable Decomposition 提出了从工具变量候选集中利用条件独立性等条件来自动分离识别工具变量表征(AutoIV),然后将工具变量表征嵌入工具变量回归方法进行因果推理。
相关性假设:使用神经网络构建工具变量Z和混淆变量C的表征,即ΦZ(X)和ΦC(X),并且要求表征ΦZ(X)和T相关、和Y关于T条件独立,同时使得ΦC(X)和T、Y都相关。此外,我们还要求ΦZ(X)和ΦC(X)尽可能独立,以对进入Z和C的信息进行正则约束。相关性假设成立,首先工具变量Z需要和干预变量相关,即P(X|Z)≠P(X)。因此我们要求可观测变量中和相关的信息能够进入的表征中。由于互信息需要使用的是条件分布信息,而数据是基于样本的,因此首先使用变分分布qθθZT(T|ΦZ(X))近似真实的条件分布P(T|Z),然后基于该条件分布进行互信息最大化学习。
排他性假设:排他性假设成立,工具变量Z还需要满足结果排除条件,即P(Y|Z, T)=P(Y|T)。因此需要对Z和Y的条件互信息进行最小化。同样地,我们首先通过变分近似来学习条件分布,然后基于条件分布进行条件互信息最小化学习。
无混淆假设:基于可观测变量X、干预变量T、结果变量Y,假设并提取出和不可观测的误差独立的可观测变量X,构建反事实预测数据集: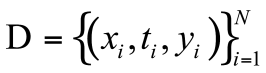 。
。
5. 总结
5. 总结
随着数据驱动式机器学习的盛行,我们越来越意识到传统的统计相关式学习往往会受限于数据存在的混淆变量和选择变量的影响,从而导致模型学习到虚假的相关性或独立性知识。而因果推理是强大的解释性工具,可以有效帮助我们矫正虚假独立或是虚假相关,从而达到泛化能力更强、稳定性更高的模型。本文分别从观察数据中的变量类型、数据中各变量不同的重要程度以及潜在混淆变量的影响等三个角度,讨论了如何提升数据驱动式因果推理的性能,这些算法将能够帮助我们在不同的场景下学习到更加鲁棒、知识利用率更高的模态知识。
因果科学读书会第三季启动
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
图模型与因果推理基础- SCM框架和Do-Calculus -
崔鹏:稳定学习——挖掘因果推理和机器学习的共同基础 -
从非完整和含噪声的数据中推理复杂网络动力学 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











