突破基尼系数,如何捕捉更多隐藏的不平等信息?

导语
基尼系数能反映出收入分布的整体不平等水平,是目前使用最为广泛的不平等度量指标。然而,这样的单参数指标难以捕捉分布的局部信息,如低收入和高收入群体内部的不平等程度。近日,Nature Human Behaviour 的一项研究基于美国3056个县级收入分布数据集,发现多参数模型的洛伦兹曲线拟合效果始终优于单参数模型,且最佳拟合模型为双参数 Ortega 模型。该研究强调了多参数模型和数据驱动方法研究不平等性时的重要性。
研究领域:基尼系数,收入不平等

胡一冰 | 作者
梁金 | 审校
邓一雪 | 编辑

论文标题:Measuring inequality beyond the Gini coefficient may clarify conflicting findings
论文链接:https://www.nature.com/articles/s41562-022-01430-7
1. 基尼系数无法充分体现不平等分布差异
1. 基尼系数无法充分体现不平等分布差异
长期以来,经济不平等和不平等所带来的的影响都是热门研究问题。然而,不同研究中往往出现自相矛盾的结论。例如,肥胖和经济不平等的相关性有正有负,主观幸福感与或高或的经济不平等程度都有关系。虽然这些研究结论不同,但都采用了单一参数指标来量化不平等,最常见的就是基尼系数。
基尼系数是衡量一个国家或地区居民收入差距的常用指标,数值在0~1之间,基尼系数越接近0表明收入分配越趋向平等。基尼系数最主要的缺点在于,当基尼系数相同时无法充分区分不同的收入分配模式。
如图1b所示,美国两个县(俄亥俄州的普特南县和德克萨斯州的钱伯斯县)的收入基尼系数均为0.46,但可以从洛伦兹曲线直观看出两个县的收入分布并不相同。所有的不平等程度都需要通过信息压缩来体现,这几乎成为了所有的单参数量化指标共同面对的难题。因此,有必要采取更全面的方法来捕捉收入的不平等分配信息。在该研究中,研究者通过理论推导和数据驱动相结合的方法,系统性地确定应使用多少参数和何种参数来获取收入分布所包含的相关信息。
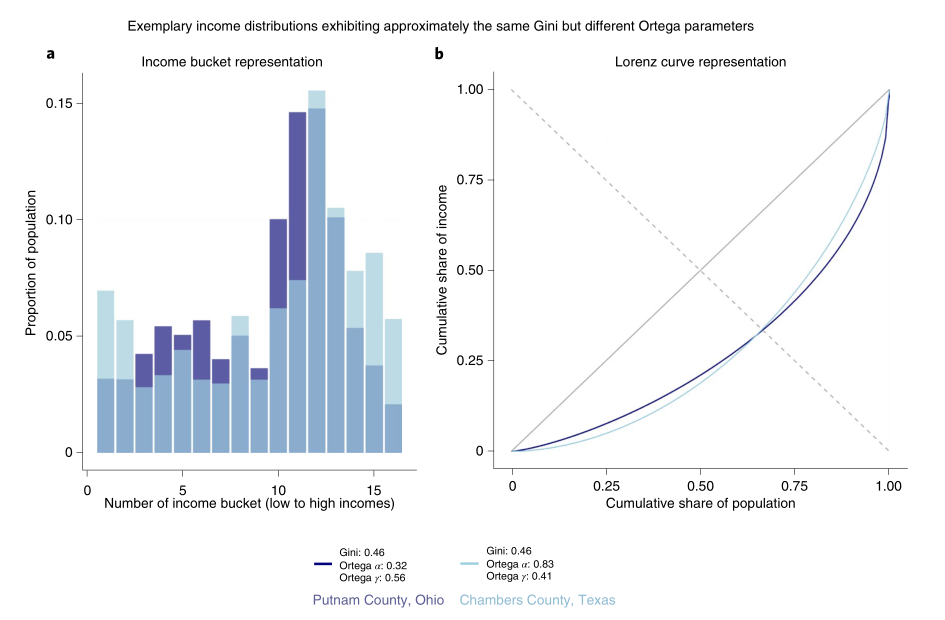 图1. 上图为俄亥俄州普特南县和德克萨斯州钱伯斯县的收入分布图。图a反映了基尼系数大致相同(均为0.46)的两个县不同收入层次的收入者人数比例。图b为两个县收入分布的洛伦茨曲线表示法,这表明尽管两种分布的整体的不平等水平相同(即曲线下的面积相同),但各县之间不平等集中的地方不同。
图1. 上图为俄亥俄州普特南县和德克萨斯州钱伯斯县的收入分布图。图a反映了基尼系数大致相同(均为0.46)的两个县不同收入层次的收入者人数比例。图b为两个县收入分布的洛伦茨曲线表示法,这表明尽管两种分布的整体的不平等水平相同(即曲线下的面积相同),但各县之间不平等集中的地方不同。
2. 多参数洛伦兹曲线模型能更好捕捉分布差异性
2. 多参数洛伦兹曲线模型能更好捕捉分布差异性
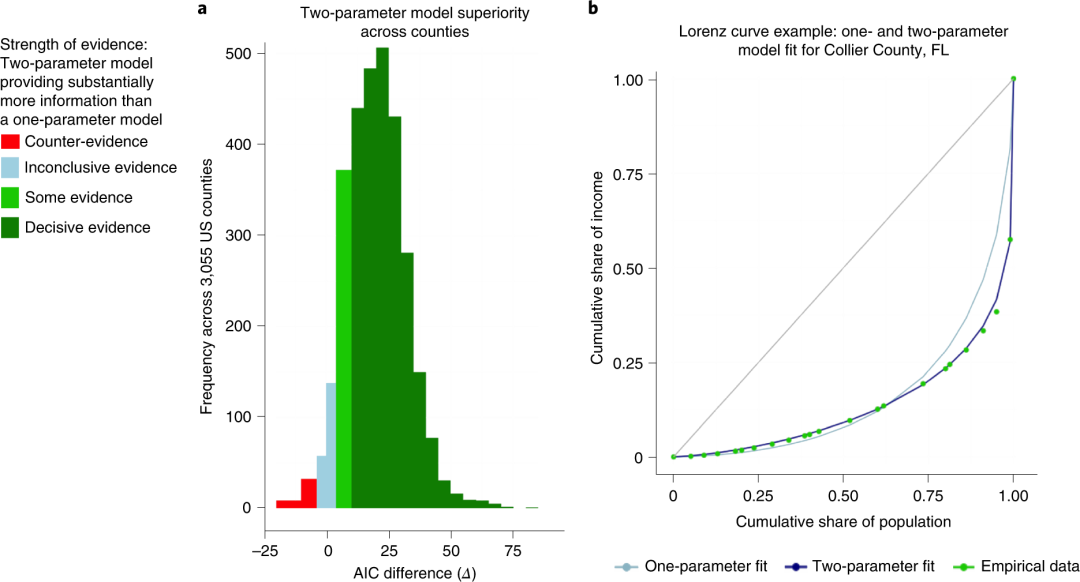
研究者创建了一个包含美国3056个县的真实收入分布数据集,并收集了17个不同分布的洛伦兹曲线模型。接着,使用MLE方法评估数据集中每个县、每个模型的拟合优度,并在Borda计数投票环节为拟合优度更高的模型分配更多的权重,从而在所有洛伦兹曲线模型中识别出最优模型。
如图2所示,研究者针对单参数与双参数模型的AIC差值作出直方图,并分别对实证数据进行拟合。可以看出当使用AIC作为拟合优度检验标准时,多参数洛伦兹曲线模型几乎优于所有单参数洛伦兹曲线模型,且双参数Ortega模型能满足绝大多数数据的最优拟合,可以更全面地捕捉美国各县收入分布中包含的信息。研究者也通过鲁棒性测试,验证了上述结论的可靠性。
3. Ortega模型的不同参数能反映分布的不同性质
3. Ortega模型的不同参数能反映分布的不同性质
含参数的洛伦兹曲线模型通过参数变化来表征收入分布的形状,或许这些参数本身就可以作为不平等的衡量标准。双参数Ortega模型可以表示为:S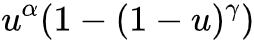 。研究者模拟了不同参数组合下的Ortega洛伦兹曲线(如图3所示),对比这两个参数可以发现,第一个Ortega参数α更能反映集中在收入分配底部的不平等,而第二个Ortega参数γ则反映集中在收入分配顶部的不平等。也就是说,虽然综合的参数能反映整体的不平等程度,但每个参数单独反映了收入分配局部区间的不平等差异。
。研究者模拟了不同参数组合下的Ortega洛伦兹曲线(如图3所示),对比这两个参数可以发现,第一个Ortega参数α更能反映集中在收入分配底部的不平等,而第二个Ortega参数γ则反映集中在收入分配顶部的不平等。也就是说,虽然综合的参数能反映整体的不平等程度,但每个参数单独反映了收入分配局部区间的不平等差异。

4. Ortega模型参数与决策变量的相关性
4. Ortega模型参数与决策变量的相关性
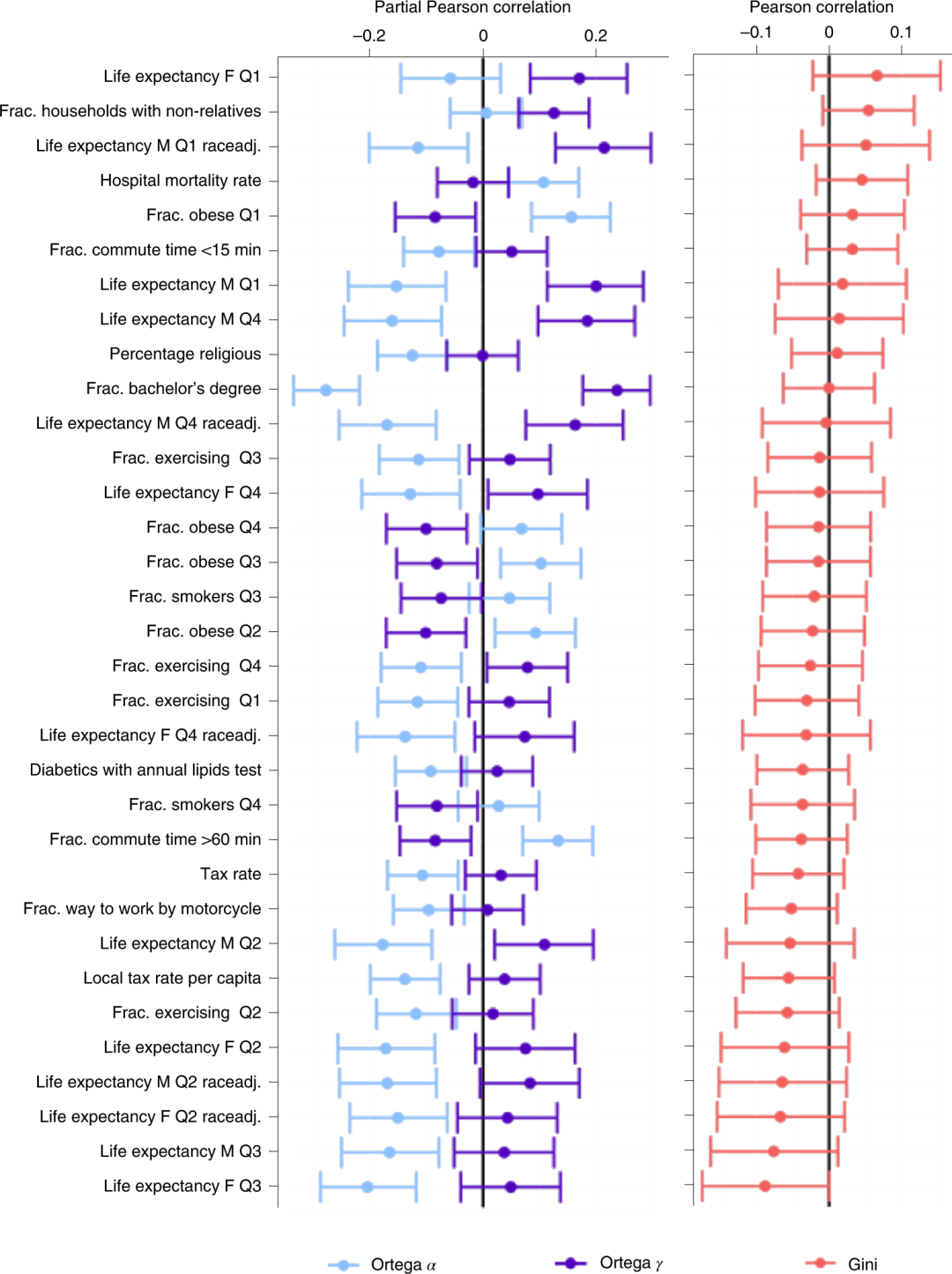
该研究计算两个Ortega参数与县级大量政策有关的决策变量之间的相关性,并将其与基尼系数和这些相同决策变量之间的相关性进行比较。换句话说,就是探索两个Ortega参数是否能检测到基尼系数遗漏的统计显著相关性(即基尼系数没有统计显著相关性)。在对100个案例进行分析后发现,有33个案例中至少有一个Ortega参数能够检测到统计上显著的相关性,而基尼系数却不相关。
图4展示了这种情况的样例,包括肥胖、通勤时间和拥有学士学位的人口比例等情况。另外,在59个案例中,基尼系数具有统计学上的显著相关性,至少一个Ortega参数也是如此,这说明收入集中在收入分配的底层或顶层驱动了这种相关性。
5. 不平等问题的未来研究方向
5. 不平等问题的未来研究方向
该研究通过理论推导和数据驱动分析发现,广泛使用类似基尼系数这样的单参数、不平等衡量指标可能会忽略收入分配中包含的关键信息。研究证实,双参数Ortega模型在美国县级收入分配数据集上表现出了更好的拟合优度,能有效反映收入不平等的集中区域。这些信息可以帮助人们更好地评估与决策,并识别经济不平等与社会、政治或心理现象的关联性。
未来对于不平等现象的研究不能只停留在考虑整体不平等水平上,而应更多地考虑收入分配中不同的不平等集中度。该研究为使用多参数不平等测度解释不平等相关性提供了初步证据,未来需要更深入理解特定区域收入分配集中不平等的产生机制和影响。突破基尼系数所反映的整体不平等水平,有助于理解不同类型的不平等,并做出有意义的决策来缓解不平等。
复杂经济学读书会第二季招募中
经济学理论的发展与社会环境变化密切相关。一方面,伴随计算机的发展,相应的研究技术日渐成熟,例如非线性动力学、复杂网络、ABM等,为研究者提供了更强大的分析工具;另一个方面,对“均衡”的经济学的研究,不能够解释实际的经济现象,例如金融危机、创新产生的新的发展模式等,研究者开始重视经济学的“非均衡”现象,把经济系统看做复杂系统,并力图做出更能反映现实的研究。经济学内慢慢出现了一种基于更加现实的假设的研究进路,复杂经济学一个新的经济学框架正在形成。为了促进此领域的交流与合作,我们发起了复杂经济学读书会。
复杂经济学读书会第二季由北京师范大学李红刚、王有贵、张江、陈清华老师以及中山大学袁先智老师联合发起,从7月11日起每周一 19:00-21:00 进行,预计持续 10-12 周。我们将围绕复杂经济学的内涵、基本方法、普适规律、应用场景四个方面进行探讨,并计划组织三次圆桌讨论,与国内外学者进行深入探讨。热诚欢迎对复杂系统研究和经济学感兴趣的学生和学者加入这个读书会,一起探索和探讨经济复杂系统的真谛!

推荐阅读
-
人类不平等的起源:为什么每一次技术变革都加剧了贫富分化 -
超越经济普查:从航空影像判断城市中的贫富差距 -
为什么经济必须持续增长?多主体模型揭示规模、复杂性与财富增长的关联 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











