具身智能读书会启动:走向现实世界的下一代AI系统

Jeffrey Fisher for Quanta Magazine
导语
集智俱乐部联合上海交通大学助理教授李永露、银河通用机器人合伙人史雪松、南京大学LAMDA组博士生陈雄辉、香港大学在读博士生穆尧,共同发起首季「具身智能」读书会。读书会计划采用“自下而上”的层级结构,探讨四个核心模块:硬件系统(机器人本体设计),数据、仿真环境与Benchmark,机器人学习,具体场景任务。希望通过重点讨论经典、前沿的重要文献,帮助大家更好地学习机器人与具身智能技术前沿技术,为相关领域的研究和应用提供洞见。
读书会从2025年1月19日开始,每周日14:00-16:00,持续时间预计 6-8 周左右。每周进行线上会议,与主讲人等社区成员当面交流,之后可以获得视频回放持续学习。
背景介绍
背景介绍
人工智能的发展正面临着一个根本性的挑战:如何让AI系统真正理解和适应物理世界的复杂性。尽管在数字领域取得了巨大突破,但在与现实世界的交互方面,AI系统仍然显得局限。这种差距揭示了智能系统在“具身性”方面的重要缺失——它们缺乏通过物理交互来获取和验证知识的能力。
-
复杂性挑战:如何在这种复杂环境中实现稳定可靠的感知、控制和决策?
-
学习与泛化:如何从有限的物理交互中学习并泛化到新的场景?
-
多尺度整合:从底层的传感器数据到高层的任务规划,如何实现跨越多个尺度的有效整合?
-
系统鲁棒性:在开放、动态、不确定的环境中,如何保证系统的可靠性和安全性?
-
智能涌现:具身经验如何促进更高层次智能的产生?物理交互是否是实现真正智能系统的必要条件?
这些问题的探索需要跨越多个学科领域,从机器人学、控制论、认知科学到机器学习。特别是在当前大语言模型蓬勃发展的背景下,如何将语言理解与物理交互能力相结合,成为一个极具前景的新方向。
读书会框架
读书会框架
针对具身智能首季读书会,我们设计了一个系统化的学习框架,希望大家对具身智能这个领域有全局的了解。这个框架采用“自下而上”的层级结构,按照技术栈从底层到高层依次包含:硬件系统(机器人本体设计)、数据、仿真环境与Benchmark、机器人学习、以及具体场景任务。这种划分既反映了技术之间的依赖关系,也体现了从物理实现到智能应用的自然演进过程。
其中,在框架的核心部分—机器人学习(robotics learning)中,我们从两个互补的维度进行深入探讨:
第一个维度是决策框架,按照信息处理流程分为感知、控制和规划三个层次,同时也考虑端到端的方法。这个划分遵循“从物理到任务”的原则—越靠近左侧越贴近物理世界的原始信息,越靠右侧越接近最终要完成的目标任务。
第二个维度是学习方法论,包括从真实数据直接学习、从仿真环境学习并迁移、基于世界模型学习、利用多模态数据学习、以及从其他领域知识迁移学习。这个维度体现了一个重要的权衡—从左到右,数据的获取难度逐渐降低,但与目标场景的差异也逐渐增大。

发起人介绍
发起人介绍

史雪松老师是银河通用机器人合伙人、算法工程负责人,CCF智能机器人专委会常务委员,复旦大学博士。曾任高仙机器人算法总监,历经高仙商用清洁机器人全球大规模部署过程,带队攻克诸多算法问题。曾任英特尔研究院主任研究员,为英特尔自主移动机器人软件包的主要算法贡献者,OpenLORIS系列数据集作者,IROS 2019 Lifelong Robotic Vision Challenge竞赛主席。史雪松博士曾于信号处理、机器人学和计算机视觉的顶级学术会议与期刊发表十多篇论文,拥有十多项机器人和人工智能方向的国际专利。

陈雄辉:南京大学LAMDA组博士生,导师是俞扬教授。研究重点在于解决强化学习在在线交互成本敏感的真实应用场景中的挑战和基于大模型的决策研究,涉及技术包括离线强化学习,世界模型学习,sim2real 迁移,因果推断,基于大语言模型的决策和决策大模型等。目前有10+篇论文发表在NeurIPS,ICML,ICLR,TPAMI等顶会上。其研究成果也在互联网,化工和军工等多行业成功落地。
https://xionghuichen.github.io/

穆尧:香港大学在读博士生,师从罗平教授。研究方向:具身智能、强化学习、机器人控制和自动驾驶。个人主页:yaomarkmu.github.io。先后在NeurIPS, ICML, ICLR, CVPR等顶会顶刊发表论文20余篇,曾获ICCAS2020大会最优学生论文奖,IEEE IV2021最优学生论文提名奖等多项学术奖励,于2021年在清华大学取得硕士学位,荣获香港博士政府奖学金,香港大学校长奖学金,国家奖学金,清华大学优秀硕士毕业生,清华大学优秀硕士论文奖等荣誉称号。

李永露老师是上海交大助理教授,博导,研究具身智能、视觉推理、行为理解,代表工作HAKE(引用1200+,Github Star 1.5K+,官网全球访问15万+次)、AlphaPose(引用500+,Github Star 8K+),大幅提高视觉行为理解精度。发表研究成果40+(TPAMI、NeurIPS、ICML、CVPR、ICCV、ECCV、IJCV),谷歌引用2200+,他引超100论文7篇(一篇ESI排名前千分之八);开源项目20余项,获Github star 1.2万+。任上海交大ACM班《计算机视觉》、AI班《虚拟现实》课程教师,NeurIPS 2024 Area Chair,多种AI顶会顶刊审稿人,VALSE EAC,中国人工智能学会-具身智能专委会执委、秘书处成员。
https://dirtyharrylyl.github.io/
报名参与读书会
报名参与读书会
运行模式
从2025年1月19日开始,每周日下午14:00-16:00,持续时间预计 6-8 周左右,按读书会框架设计,每周进行线上会议,与主讲人等社区成员当面交流,会后可以获得视频回放持续学习。
报名方式

PS:为确保专业性和讨论的聚焦,本读书会谢绝脱离读书会主题和复杂科学问题本身的空泛的哲学和思辨式讨论;如果出现讨论内容不符合要求、经提醒无效者,会被移除群聊并对未参与部分退费。
加入社区后可以获得的资源:

参与共创任务获取积分,共建学术社区:
读书会采用共学共研机制,成员通过内容共创获积分(字幕修改、读书会笔记、论文速递、公众号文章、集智百科、论文解读等共创任务),积分符合条件即可退费。发起人和主讲人同样遵循此机制,无额外金钱激励。

PS:具体参与方式可以加入读书会后查看对应的共创任务列表,领取任务,与运营负责人沟通详情,上述规则的最终解释权归集智俱乐部所有。
Embodied AI topic 列表
Embodied AI topic 列表

推荐理由:这是非常重要的综述之一,梳理的框架参考这篇文献,所以下面多个地方都有涉及,这是这篇综述对应整理的github文献:
https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List
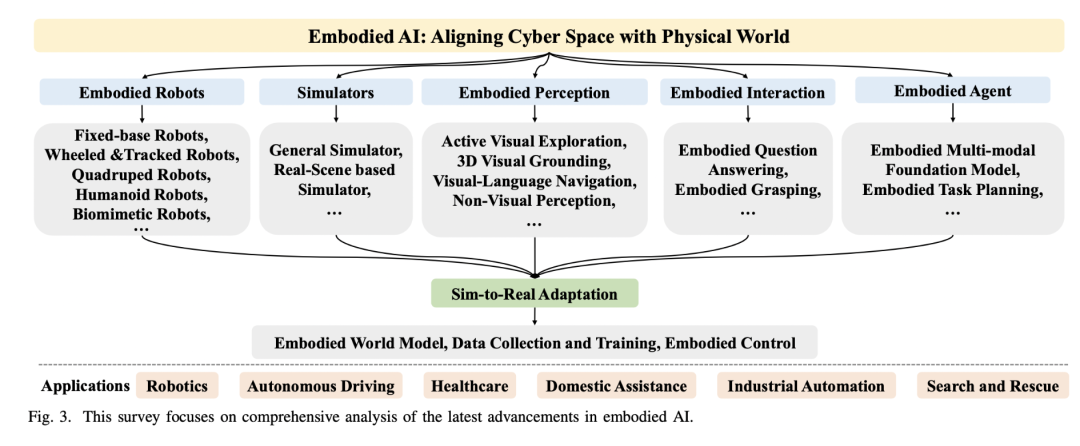

机器人本体作为具身智能的物理载体,其形态设计、材料和功能实现直接决定了系统的操作能力。在各类机器人硬件中,我们会重点分享灵巧手(Dexterous Hand)的相关研究,作为机器人与物理世界进行复杂交互的核心执行器,灵巧手的研究面临三个根本性的科学问题:如何实现类人水平的触觉感知能力、如何解决高维度动作空间下的规划与控制、以及如何构建可泛化的操作知识表征。
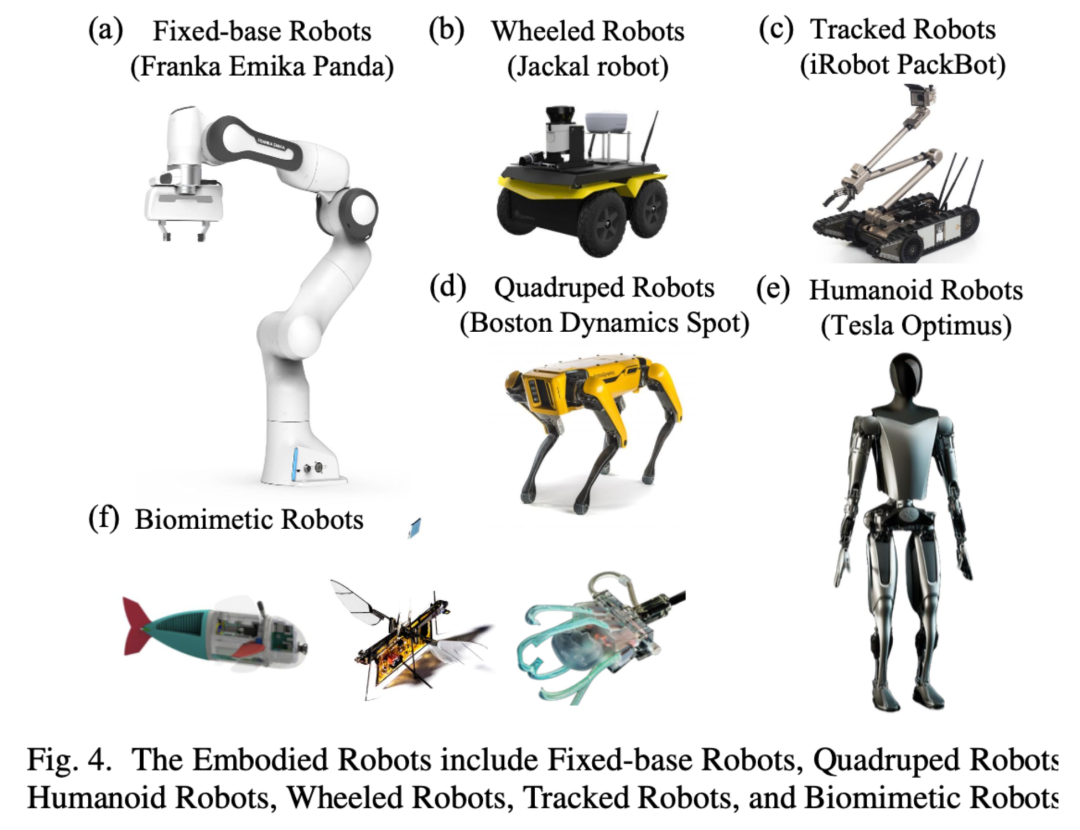

在具身智能领域,数据集、Benchmark 和仿真三者紧密关联,共同构成研究的基础框架。数据集提供训练和评估的多模态数据,仿真环境生成数据并模拟真实世界场景,而 Benchmark 则通过标准化任务和评价指标推动技术的对比与进步。它们解决了数据稀缺、研究标准化和实验可控性的问题。然而,该领域仍面临数据集质量与多样性、仿真与现实的差距(Sim-to-Real Gap)、任务复杂性与多样性,以及统一性与可扩展性等关键挑战。
Wang, Zipeng, et al. “All Robots in One: A New Standard and Unified Dataset for Versatile, General-purpose Embodied Agents.” arXiv preprint arXiv:2408.10899 (2024).
推荐理由:提出ARIO标准,是首个统一的具身智能数据集标准,包含全面的传感器模态和机器人平台。
Kulkarni, Mihir, Theodor JL Forgaard, and Kostas Alexis. “Aerial Gym–Isaac Gym Simulator for Aerial Robots.” arXiv preprint arXiv:2305.16510 (2023).https://arxiv.org/abs/2305.16510
推荐理由:提出的Aerial Gym是一个突破性的空中机器人仿真平台,其高度并行化特性使其能同时模拟数百万架多旋翼飞行器。
Nvidia isaac sim: Robotics simulation and synthetic data, NVIDIA, 2023 https://developer.nvidia.com/isaac/sim
推荐理由:NVIDIA开发的高性能仿真平台,提供高保真物理仿真、实时光线追踪和丰富的机器人模型库,支持深度学习和大规模并行计算。
Genesis: A Generative and Universal Physics Engine for Robotics and Beyond;GitHub:https://github.com/Genesis-Embodied-AI/Genesis 推荐理由:最新发布的Genesis生成式物理引擎代表了物理模拟领域的重大突破。Genesis是一个全面的物理模拟平台,专为通用机器人、具身AI和物理AI应用设计,这是一个历时24个月、由20多个学术和产业机构共同研发的项目。
Mu, Yao, et al. “Robotwin: Dual-arm robot benchmark with generative digital twins (early version).” arXiv preprint arXiv:2409.02920 (2024).https://arxiv.org/abs/2409.02920
推荐理由:提出了一个结合真实遥操作数据和数字孪生生成数据的创新基准,专注于双臂机器人工具使用和人机交互,是具身智能领域 benchmark 研究的重要参考文献。

机器人学习是具身智能实现从感知到执行完整闭环的核心途径。在学习架构上,通过多模态感知、规划决策和控制执行等机制,让智能体在物理世界中获得类人的交互能力。在学习范式上,包括从真实数据直接学习、通过仿真到现实迁移学习、基于世界模型的学习、跨具身学习以及从其他领域知识迁移学习等多种方式。随着Vision-Language-Action大模型的发展,机器人学习正从传统的任务特定范式向通用化、端到端的方向演进,这些学习范式也在与大模型深度融合,以提升系统的泛化能力。
Ma, Yueen, et al. “A Survey on Vision-Language-Action Models for Embodied AI.” arXiv preprint arXiv:2405.14093 (2024).https://arxiv.org/abs/2405.14093
推荐理由:这篇文献系统性地综述了视觉-语言-动作模型(VLAs)的最新进展,重点探讨其在具身智能中作为多模态基础模型的核心作用。
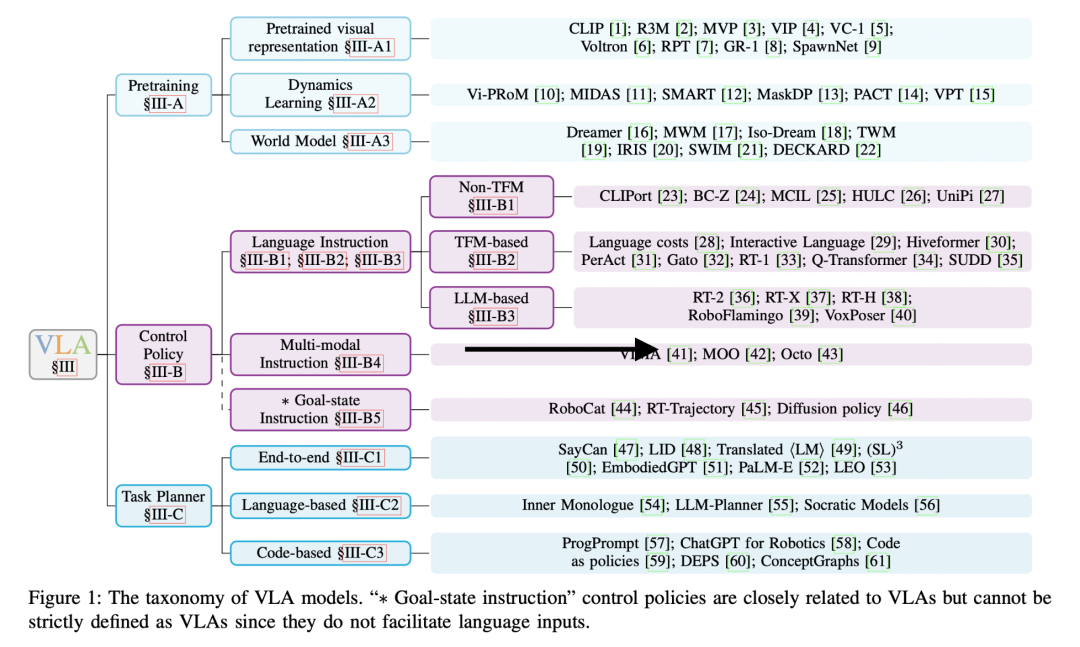
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
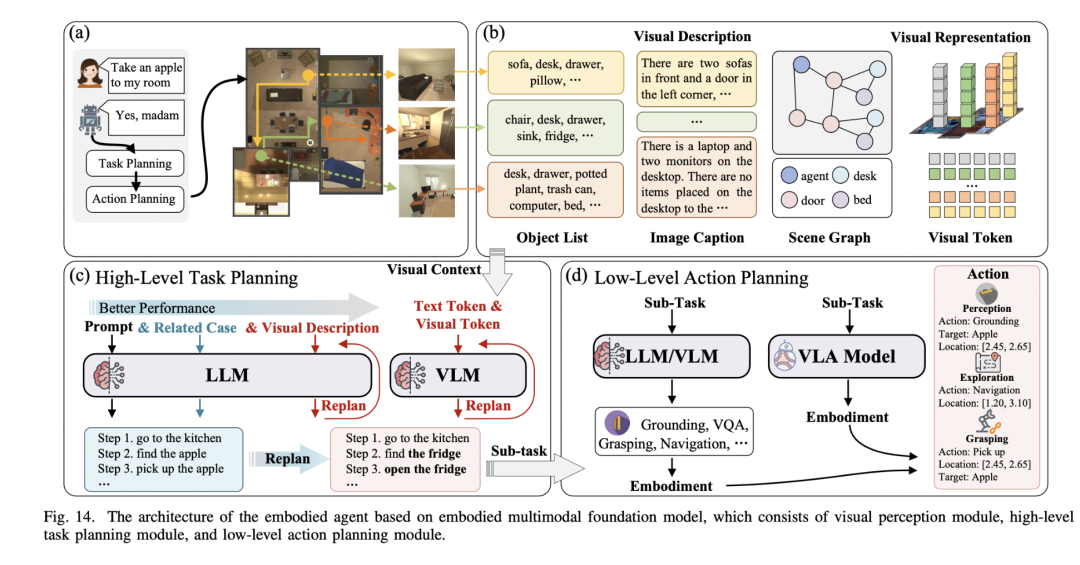
学习架构
感知(perception)
感知是指智能体通过多模态传感器获取环境信息并进行理解和推理的能力,涵盖3D场景理解、动态环境中的实时感知与推理、多模态信息整合等方面。对于感知这个话题来说,最重要的问题之一是多传感器数据如何融合并产生稳定可靠的场景理解?主要挑战包括动态环境中的感知鲁棒性、多模态感知的整合、主动探索策略的设计,以及感知与决策的协同。
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
推荐理由:系统总结了具身感知的关键技术(如视觉SLAM、3D场景理解)和未来方向。
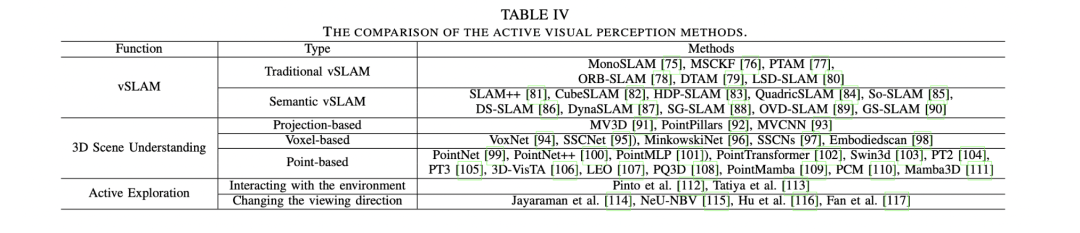
控制器(controller)
控制器是指负责将高层任务规划转化为具体机器人动作的低层次控制系统,主要包括关节位置控制、末端执行器姿态控制等具体动作的执行。这部分最重要的科学问题是:如何实现从高层指令到底层动作的可靠映射?其主要挑战包括如何在动态环境中实现高精度控制、提升数据效率与泛化能力、融合多模态感知信息,以及解决仿真到现实的迁移问题(Sim-to-Real Gap)。
Xu, Zhiyuan, et al. “A survey on robotics with foundation models: toward embodied ai.” arXiv preprint arXiv:2402.02385 (2024).https://arxiv.org/abs/2402.02385
推荐理由:该综述全面梳理了具身智能领域中控制系统的发展脉络,特别是详细分析了基于强化学习、模仿学习等方法的控制策略学习框架(如RT-1、RT-2等),并系统性地讨论了当前面临的挑战和未来发展方向,对控制器研究具有重要的指导意义。
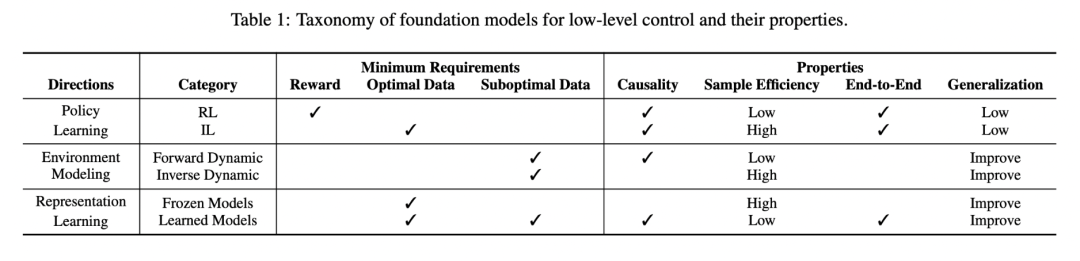
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
推荐理由:综述文章,梳理了具身智能(Embodied AI)领域的核心方向,包括感知、控制、决策以及仿真等关键环节,全面总结了多模态学习、主动探索、数据生成、仿真与现实融合等方法,并探讨了领域未来的科学挑战和研究趋势。也有对于控制器的全面的系统的梳理。

规划(planning)
在具身智能领域,规划分为高层任务规划(Task Planning)和低层动作规划(Action Planning)两个层次。Task Planning负责将复杂抽象任务分解为具体可执行的子任务序列,而Action Planning则负责将这些子任务转化为具体的控制动作。这涉及多个关键挑战:包括长期任务的连续执行、对动态环境变化的实时适应、任务分解与具体执行的有效衔接、多模态信息(视觉、语言等)的整合利用,以及规划系统在新场景和新任务中的泛化能力。
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
推荐理由:一开始的推荐综述文章,其中有系统的梳理planning的模块。
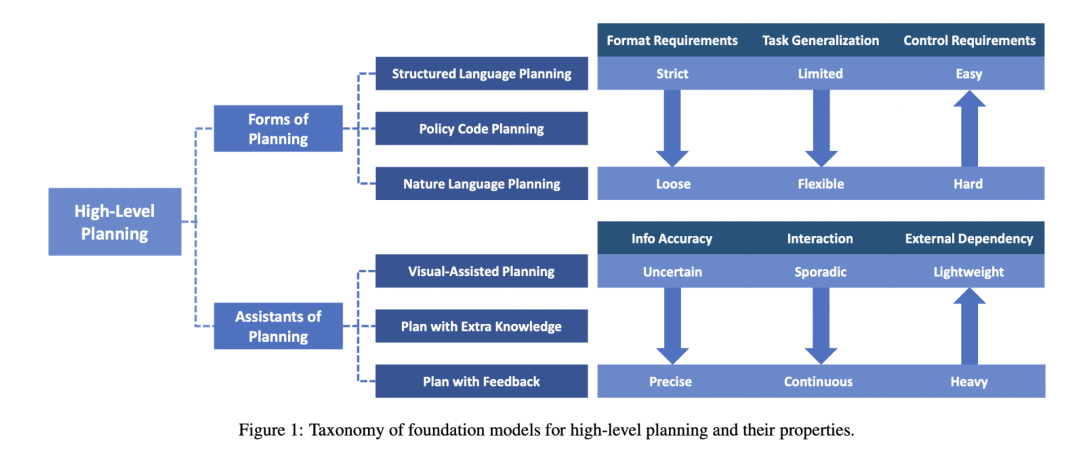
端到端(end-to-end)
端到端系统致力于实现从感知输入(视觉、语言指令等)直接映射到机器人控制动作的完整闭环能力,这一方向随着Vision-Language-Action (VLA)大模型的发展取得重要突破。当前面临的核心科学问题包括:如何提高数据效率并解决真实场景数据获取困难、如何增强模型在新场景新任务中的泛化能力、如何实现有效的仿真到现实迁移,以及如何将VLA大模型的强大表征能力与实时机器人控制需求相平衡。这些挑战推动着端到端学习方法与大模型的深度融合,通过多模态信息的有效整合来提升系统性能。
VLA大模型(Vision-Language-Action Model)
不同于端到端小模型(如专门用于某项任务的模仿学习模型或RL policy),VLA大模型具备人类常识,能够接受开放指令、理解开放场景;不同于诸多将非具身LLM/VLM与机器人系统以搭积木般组合的工作,VLA大模型需要整体训练。这部分工作门槛最高、难度最大,但正是VLA方面的研究进展和前景,推动了具身智能的投资热潮。
1. 用于导航的VLA大模型:NaVid,NaVILA
Zhang, Jiazhao, et al. “Navid: Video-based vlm plans the next step for vision-and-language navigation.” arXiv preprint arXiv:2402.15852 (2024). https://arxiv.org/pdf/2402.15852
Cheng, An-Chieh, et al. “NaVILA: Legged Robot Vision-Language-Action Model for Navigation.” arXiv preprint arXiv:2412.04453 (2024). https://arxiv.org/abs/2412.04453
2. 用于操纵的VLA大模型:OpenVLA,π0
Kim, Moo Jin, et al. “OpenVLA: An Open-Source Vision-Language-Action Model.” arXiv preprint arXiv:2406.09246 (2024). https://arxiv.org/abs/2406.09246
π0: Our First Generalist Policy https://www.physicalintelligence.company/blog/pi0
学习范式
从真实数据中学习(learning from real data)
Learning from Real Data是指机器人通过直接从真实世界环境中收集的数据进行学习,这些数据包括视觉、触觉、动作等多模态信息。近年来,随着RT-1、RT-2等大模型的发展,这一范式越来越受到重视。在这个方向下,面临的核心挑战包括:数据收集的高成本和低效率问题(需要昂贵的设备和大量人力)、数据质量和多样性的保证(如何确保收集的数据具有足够的代表性和覆盖性)、跨平台数据的标准化问题(不同机器人平台的数据格式不统一)、以及如何有效整合和利用人类示范数据。
Brohan, Albert, et al. “RT-1: Robotics Transformer for Real-world Control at Scale.” arXiv preprint arXiv:2212.06817 (2022).https://arxiv.org/abs/2212.06817
推荐理由:首次展示了基于大规模真实数据训练的机器人transformer模型,建立了从视觉到控制的端到端映射。
Majumdar, Arjun, et al. “Openeqa: Embodied question answering in the era of foundation models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
https://openaccess.thecvf.com/content/CVPR2024/html/Majumdar_OpenEQA_Embodied_Question_Answering_in_the_Era_of_Foundation_Models_CVPR_2024_paper.html
推荐理由:展示了如何利用真实场景数据来训练开放词汇的具身问答系统,体现了真实数据对语言引导任务的重要性。
Brohan, Albert, et al. “RT-2: Vision-language-action Models Transfer Web Knowledge to Robotic Control.” Conference on Robot Learning. PMLR (2023): 2165-2183.https://arxiv.org/abs/2307.15818
推荐理由:通过结合互联网预训练和真实机器人数据微调,实现了知识迁移和技能泛化。
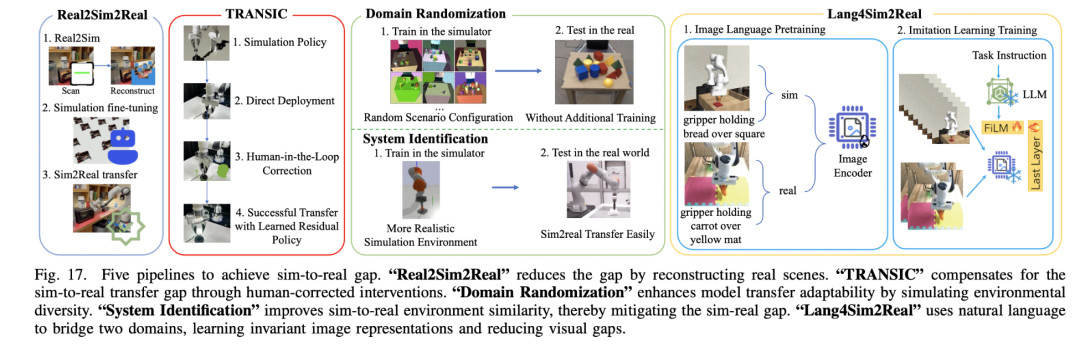
从仿真到现实(sim2real / real2sim2real )
Sim2Real/Real2Sim2Real是具身智能领域中实现虚拟环境与物理世界对齐的关键技术范式,旨在将仿真环境中训练的模型能力有效迁移到真实世界。其中Real2Sim2Real通过扫描和重建真实场景构建“数字孪生”环境,在仿真中进行强化学习训练后再迁移回真实世界。在这个方向下,如何提升仿真环境的物理真实性以缩小与现实世界的差距,如何确保模型在迁移过程中的鲁棒性和泛化能力,以及如何高效收集和利用真实世界的数据来优化迁移效果是最重要的挑战之一。
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
推荐理由:一开始的推荐综述文章,其中有系统的梳理Sim2Real/Real2Sim2Real相关的模块。
从世界模型中学习(learn from world model)
从世界模型中学习是指通过构建和利用世界模型(World Model),让机器人或具身智能体在虚拟或物理环境中学习和推理。世界模型通过模拟环境的物理规律和因果关系,预测输入与输出之间的状态转变,从而为机器人提供感知、规划和决策的能力。
然而,当前World Model仍面临几个关键挑战:如何提升模型的泛化能力以适应未见场景,如何有效学习和表达物理规律与因果关系,如何平衡数据效率与计算成本,以及如何确保在实时任务中的鲁棒性。
Liu, Yang, et al. “Aligning cyber space with physical world: A comprehensive survey on embodied ai.” arXiv preprint arXiv:2407.06886 (2024).https://arxiv.org/abs/2407.06886
推荐理由:一开始的推荐综述文章,其中有系统的梳理World Model相关的模块。
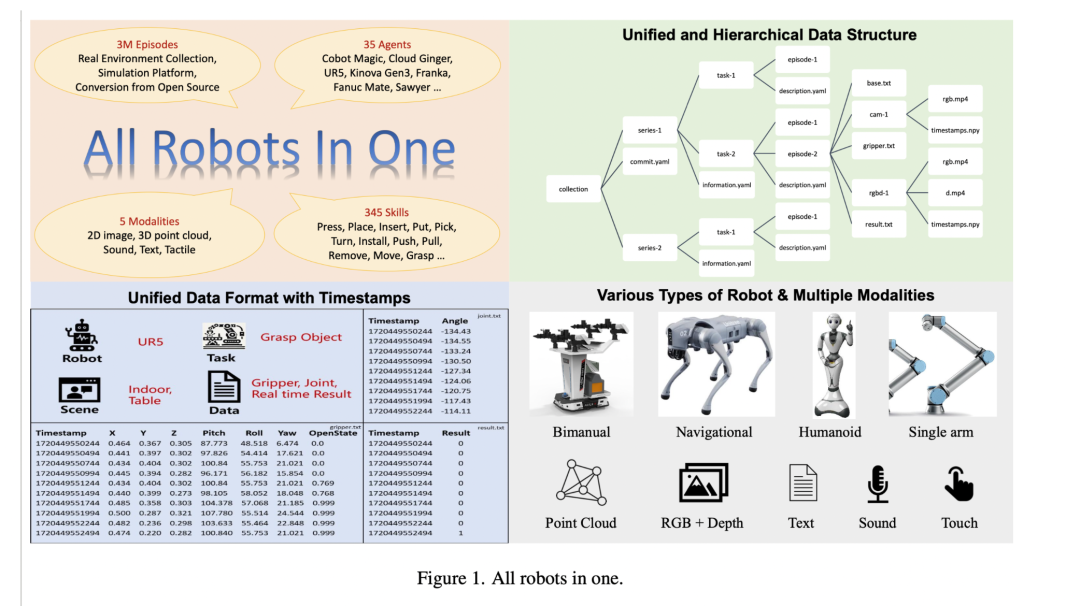
跨具身学习(cross-embodiment learning)
跨具身学习是指通过共享和迁移知识,使机器人能够在不同形态(如单臂、双臂、人形、轮式等)和平台之间进行学习和适应,从而提升其在多样化任务中的泛化能力和协作能力。这一方向面临的主要科学问题包括:如何设计统一的动作和感知表示以跨越不同机器人形态的差异、如何处理多模态数据的标准化与整合,以及如何有效地解决模拟与现实之间的差距(sim-to-real gap)。
Wang, Zhiqiang, et al. “All robots in one: A new standard and unified dataset for versatile, general-purpose embodied agents.” arXiv preprint arXiv:2408.10899 (2024).https://arxiv.org/abs/2408.10899
推荐理由:系统总结了跨平台和多形态机器人学习的最新进展,提出了统一数据格式和多模态整合的解决方案,是具身智能领域 cross-embodiment learning 研究的重要参考文献。
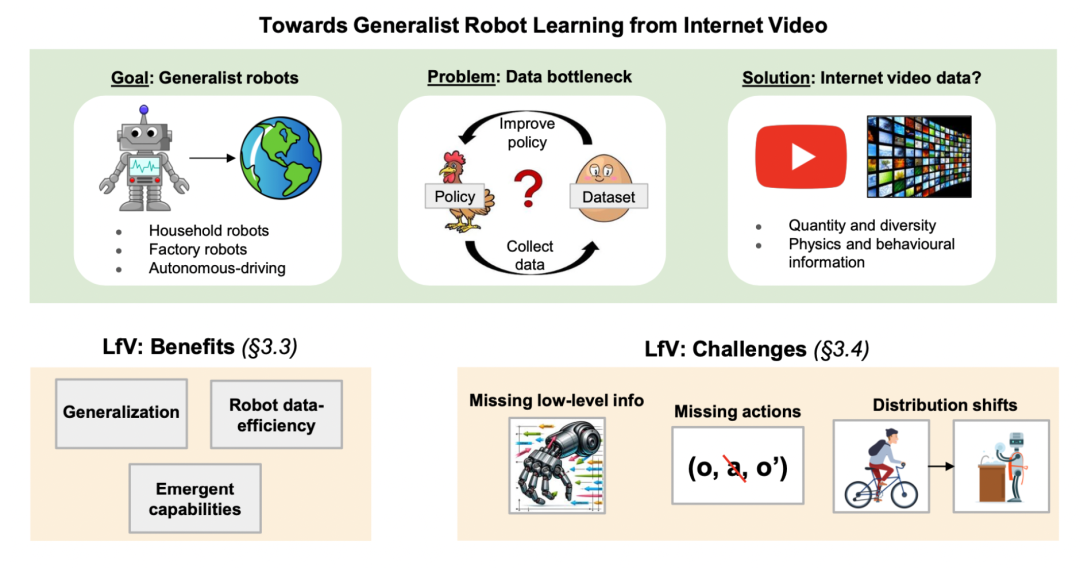
从其他领域知识中学习(learning from other domain knowledge)
从其他领域知识中学习是指通过利用其他领域(如互联网视频、自然语言处理或计算机视觉)中已有的丰富数据和模型,提取通用知识并将其迁移到机器人学习中,以弥补机器人领域数据稀缺和任务复杂性带来的挑战。这一方向的核心科学问题包括如何从异构数据中提取与机器人任务相关的知识,以及如何应对数据分布差异、缺乏低级感知信息(如力觉和触觉)和高维数据处理的挑战。
McCarthy, Robert, et al. “Towards Generalist Robot Learning from Internet Video: A Survey.” arXiv preprint arXiv:2404.19664 (2024).https://arxiv.org/abs/2404.19664
推荐理由:系统综述了如何从互联网视频等其他领域知识中提取和迁移信息以提升机器人学习能力,是具身智能领域学习跨领域知识的重要参考文献。

这个模块,是对前面两个主题的一个综合讨论,最终,具身智能的价值要在实际应用任务中得到验证。运动控制、物体操作、远程操作、场景理解与交互等方向各有其独特的挑战。例如:如何实现像人类一样自然流畅的双足行走?如何让机器人能够理解并使用各种日常工具?如何在人机协作中实现高效的交互?这些问题不仅需要解决技术挑战,还需要思考如何将具身智能更好地服务于实际应用场景。
移动(locomotion)
移动在机器人领域通常指机器人在环境中进行自主移动和导航的能力,包括通过轮式、履带式、足式(如四足、仿生等)以及其他生物启发式方式来完成越障、保持平衡和执行移动任务。在这一方向下面临的主要科学问题主要是:如何实现高速、高动态条件下的稳定控制?
Liu, Min, et al. “Visual Whole-body Control for Legged Loco-manipulation.” arXiv preprint arXiv:2402.16967 (2024).
推荐理由:提出基于视觉的全身控制框架,实现了腿部运动和机械臂操作的协调控制。
Bledt, Gabriel, et al. “MIT Cheetah 3: Design and Control of a Robust, Dynamic Quadruped Robot.” IEEE/RSJ International Conference on Intelligent Robots and Systems (2018): 2245-2252.
推荐理由:展示了四足机器人在鲁棒性和动态性能上的突破,包括跳跃和越障等高难度动作的实现。
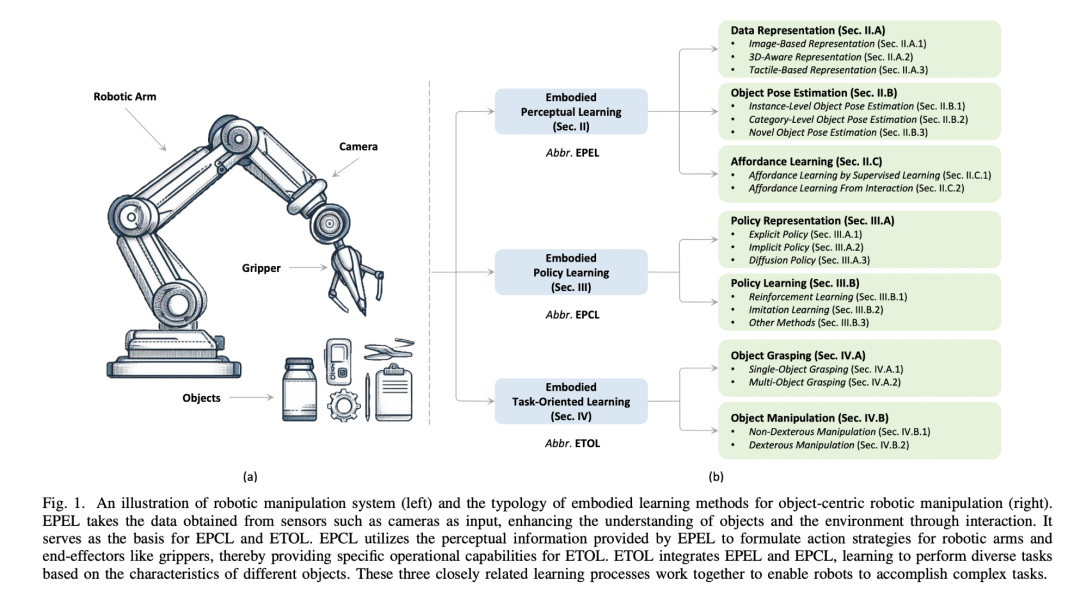
操控(Manipulation)
操控是指机器人通过感知、规划和执行一系列动作,与环境中的物体进行交互的过程,包括抓取、移动、调整和使用物体等任务。其目标是使机器人能够在动态和复杂的环境中完成多样化的任务,广泛应用于工业、服务和医疗等领域。操控面临的主要科学问题包括:如何在非结构化环境中实现高精度的感知与决策、如何生成灵活且高效的操作策略,以及如何应对实时性要求、环境不确定性和多模态数据融合的挑战。
Zheng, Ying, et al. “A Survey of Embodied Learning for Object-Centric Robotic Manipulation.” arXiv preprint arXiv:2408.11537 (2024).https://arxiv.org/abs/2408.11537
推荐理由:在这个综述里面,系统综述了以物体为中心的机器人操控领域的最新进展,涵盖感知、策略生成和任务导向学习等关键方向,是研究具身智能领域操控技术的重要参考文献。
抓取(Grasping)
抓取作为最基础的机器人操纵任务,可能也是最先被研究到成熟的任务,值得专门重点讨论。
GraspNet:https://graspnet.net/
推荐理由:GraspNet 是一个大规模、多样化、支持模拟与真实评估的机器人抓取数据集和基准平台,为具身智能抓取任务提供了标准化评估和强大的工具支持。
Shi, Jun, et al. “Asgrasp: Generalizable transparent object reconstruction and 6-dof grasp detection from rgb-d active stereo camera.” 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024.https://pku-epic.github.io/ASGrasp/
推荐理由:ASGrasp是一种基于RGB-D主动立体相机的6自由度抓取检测网络,专为解决透明和镜面物体抓取问题而设计。
Wei, Songlin, et al. “D3 RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation.” ECCV 2024 Workshop on Wild 3D: 3D Modeling, Reconstruction, and Generation in the Wild. 2024.https://openreview.net/forum?id=jFRUsiuhUy
推荐理由:D3RoMa 提出了一个基于扩散模型的深度估计框架,能够在复杂场景中生成高质量的深度图,特别是在透明和镜面物体等传统方法失效的场景。
Wang, Ruicheng, et al. “Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation.” 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.https://ieeexplore.ieee.org/abstract/document/10160982/
推荐理由:DexGraspNet 提出了一个大规模灵巧抓取数据集,专注于灵巧手在复杂场景中的抓取任务,涵盖了多样化的物体和抓取策略。
Zhang, Jialiang, et al. “DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes.” 8th Annual Conference on Robot Learning. 2024.https://openreview.net/forum?id=V6XHKFicwc
推荐理由:DexGraspNet 2.0 提出了一个大规模合成抓取数据集,并结合生成式灵巧抓取算法在复杂场景中实现高成功率的灵活操作。
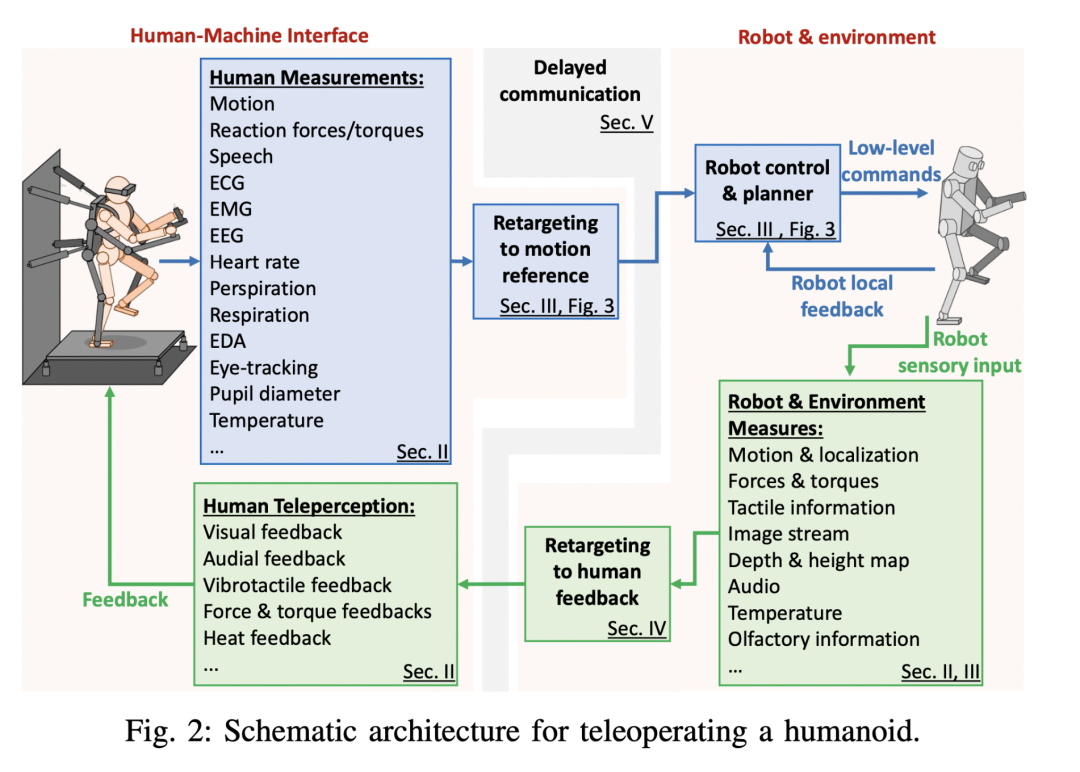
遥操作(Teleoperation )
遥操作是具身智能领域连接人类智能与机器人系统的关键桥梁。它通过人类操作者的远程控制,为机器人系统提供了获取和学习复杂操作技能的重要途径。当前遥操作研究的核心科学问题是如何建立高效自然的人机技能映射机制,这涉及操作技能的本质表征、人机交互的自然性以及控制系统的实时性等多个方面的挑战。
Darvish, Kourosh, et al. “Teleoperation of humanoid robots: A survey.” IEEE Transactions on Robotics 39.3 (2023): 1706-1727.https://ieeexplore.ieee.org/abstract/document/10035484
推荐理由:这篇文献全面综述了人形机器人遥操作领域的最新进展,涵盖技术挑战、控制方法、界面设计及应用场景,特别强调了遥操作在复杂环境中的潜力与未来发展方向,是研究具身智能与遥操作技术的重要参考。
社区伙伴致谢
社区伙伴致谢
感谢以下社区伙伴的支持。
Datawhale
Datawhale成立于2018年——是国内AI领域最大的开源学习组织,汇聚了众多有开源精神和探索精神的开源贡献者,致力于构建开源学习社区,和学习者一起成长。成立5年来,Datawhale开源学习成为全国知名的学习活动,覆盖了海内外2000多所院校,致力于打造关注青年人才成长的主阵地,加快高校和产业的链接,持续推动青年AI人才培养。
计算机视觉life平台
计算机视觉life (CV life) 是国内领先的机器人与人工智能领域综合性平台,由中国科学院博士程小六创立于2018年。作为机器人AI领域的第一梯队技术服务平台,CV life致力于打造完整的机器人AI行业生态圈,涵盖媒体、教育培训、人才服务、技术研发、就业对接等多个维度。
具身智能知识库社区
学习机器人与具身智能技术前沿技术平台,包含具身智能从浅入深的知识体系,立志与全网具身智能研究人员共建最全具身智能知识库和数据平台。

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











