如何在在多通道博弈中设计一个成功的策略?近日,西北工业大学王震教授团队、云南财经大学初晨教授联合上海人工智能实验室胡舒悦研究员在多通道囚徒博弈困境场景下提出了基于累积互惠的博弈策略——MCSUC。该策略通过博弈双方背叛次数的累积差异进行动作选择,理论证明该策略具有友好、报复、宽容和无敌等性质,是多通道博弈中的占优策略。该论文目前已被人工智能顶会 IJCAI2024 接收。
研究领域:囚徒博弈,多智能体,多通道博弈,累积互惠,策略设计
曹兆恒(西北工业大学) | 作者
无论是研究团队同时推进多个项目,还是公司在不同地区同时竞争,抑或是国家之间在多个领域合作或竞争,人们每天都在面临着决策的难题。同时,这些博弈并不总是互相独立的,有时人们会与同一个人同时进行多个重复的博弈,即多通道博弈(multichannel games),每个通道包含一个博弈,在进行其中一个通道的决策时需要综合考虑所有博弈,而该通道的决策和结果又会接着影响其他通道,这种通道之间的相互影响增加了决策的难度。在多通道博弈中该如何抽丝剥茧,正确决策?
过去几十年来,研究者们提出了一系列策略,如以牙还牙(TFT,Tit-For-Tat)和赢留输换(WSLS,Win-Stay, Lose-Shift)等。然而,这些策略并未考虑到多通道博弈中不同通道之间的相互影响,其在很多场景下也缺乏灵活性和适应性,难以令人满意。而针对多通道博弈场景设计的策略有多通道-WSLS (Win-Stay, Lose-Shift) 和CIC(Cooperate if Coordinated)策略,虽然考虑到了多通道博弈的特点,但在部分场景下的表现反而不如一直背叛(ALLD)等策略。所以,多通道博弈中缺乏表现良好的策略。
如何在多通道博弈中设计一个成功的策略?近日,西北工业大学王震教授团队,云南财经大学初晨教授联合上海人工智能实验室胡舒悦研究员在多通道囚徒博弈困境场景下提出了基于累积互惠的博弈策略——MCSUC。该策略通过博弈双方背叛次数的累积差异进行动作选择,理论证明该策略具有友好、报复、宽容和无敌等性质,是多通道博弈中的占优策略。
论文标题:A Successful Strategy for Multichannel Iterated Prisoner’s Dilemma
论文作者:王震,曹兆恒,时娟,朱培灿,胡舒悦*,初晨*
项目主页:https://github.com/1335077753/A-Successful-Strategy-for-Multichannel-Iterated-Prisoner-s-Dilemma
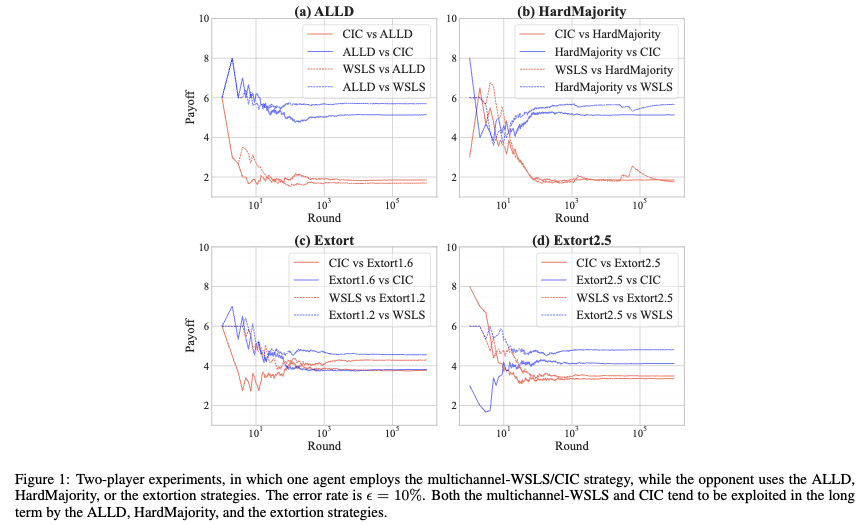
虽然目前已有的多通道博弈策略多通道-WSLS和CIC在部分场景下能够促进合作,然而当两个策略的智能体面对使用一直背叛策略(ALLD)以及其他常见策略的智能体时,它们的期望收益低于对手,会被长期剥削(图1)。
通常而言,大多数现有策略只考虑有限的记忆,比如假设智能体拥有上一轮或者上几轮的记忆,尽管这些策略在部分场景下能够满足需要,但是这种考虑预定义长度记忆的策略通常会难以捕捉人类行为的一些重要特点,比如说,人们更倾向于宽容在过往互动中更友好的人,然而如果策略仅有有限的或者固定的记忆,可能会遗忘对方过去是否友好。如果要刻画出这些更细微的人类行为习惯,智能体要关注与对手互动的整个过程的累积行为。
考虑整个互动过程的累积行为和多通道博弈中通道之间的相互影响,文章提出MCSUC,该策略统计每个智能体在所有通道上的累积背叛次数,然后根据双方的背叛次数差进行动作选择。MCSUC满足成功策略的三项基础原则:(i)友好;(ii)报复;(iii)宽容。同时,MCSUC策略拥有收益大于等于任意对手策略的‘无敌’性质,在多种场景下表现良好并具有稳定性。而且,在两策略种群演化实验中,MCSUC还拥有相对其他九个策略的演化优势,并能够促进和维持合作。
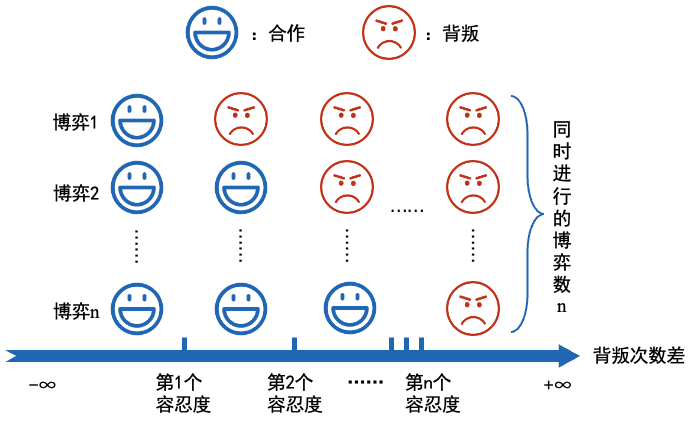
在博弈过程中,MCSUC统计对手和自己的累积背叛次数差,并根据通道数设置同等数量的容忍度个数,容忍度代表MCSUC对对手的容忍程度,当对手累积背叛次数小于等于自己累积背叛次数,或者虽然比自己多,但该差值小于自己的第一个容忍度时,MCSUC在所有通道中选择合作,如果该差值超过自己的第一个容忍度时,则在一个通道选择背叛,在其他所有通道选择合作;当差值超过自己的第二个容忍度时,则在两个通道选择背叛,其他所有通道选择合作;以此类推;当差值超过自己的最大容忍度时,则在所有通道都选择背叛。
文章以两通道重复囚徒困境为例,设置两个容忍度,当累积背叛次数差小于等于第一个容忍度时,则在两个通道都选择合作;若差值大于第一个容忍度但小于等于第二个容忍度,则以p的概率在通道1背叛,通道2合作,以1-p的概率在通道1合作,在通道2背叛;若差值大于第二个容忍度,则在两个通道都背叛。
MCSUC具有友好、报复、宽容、公平和无敌等良好性质。
友好(nice):从不首先背叛。
报复(retaliatory):对背叛行为充分报复。
宽容(forgiving):在对手背叛后能够恢复与对手的合作。
公平(fair):与任意对手策略的期望合作率必然相等,并且在特定条件下双方期望收益也相等。
无敌(invincible):与任意对手策略博弈时,期望收益必然大于等于对手策略。
稳定性(stability):当不存在‘颤抖手’错误时,策略组合(MCSUC,MCSUC)是纳什均衡,且为子博弈纳什均衡。当存在‘颤抖手’错误,但足够小的时候,(MCSUC,MCSUC)为近似纳什均衡。
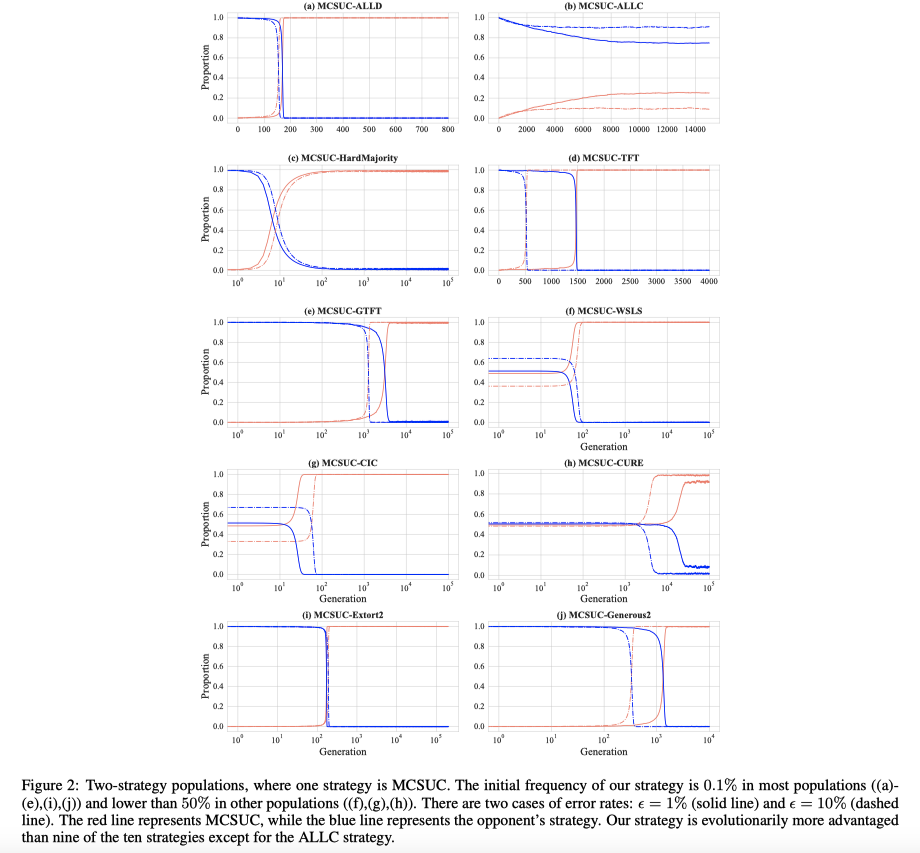
为了探索MCSUC是否具有演化优势,文章以拓展到多通道后的ALLC、ALLD、TFT、GTFT、HardMajority、CURE、剥削策略或宽容策略为对手策略进行了仿真实验。下图结果显示,MCSUC成功入侵了十种策略中除了ALLC策略的其他九种策略。这意味着MCSUC相对于这些策略(除ALLC策略外)具有演化优势地位。
在两策略种群演化实验中,MCSUC最终与ALLC共存,文章进一步进行了三策略种群实验。如图3(a)所示,ALLD策略能够入侵ALLC策略,然而在一个包含ALLC、ALLD和MCSUC的三策略种群中,如图3(b)所示,MCSUC可以保护ALLC策略免受ALLD策略剥削,促进和维持了合作。
集智俱乐部联合西湖大学工学院特聘研究员赵世钰、浙江大学教授任沁源、鹏城实验室高级工程师崔金强,共同发起「大语言模型与多智能体系统」读书会,探究大语言模型给机器人领域带来的新思想新价值。
集智俱乐部联合美国东北大学博士后研究员杨凯程、密歇根大学安娜堡分校博士候选人裴嘉欣,宾夕法尼亚大学沃顿商学院人力资本分析研究组博士后研究员吴雨桐、即将入职芝加哥大学心理学系的助理教授白雪纯子,共同发起AI+Social Science读书会,从3月24日开始,每周日晚20:00-22:00,探究大语言模型、生成式AI对计算社会科学领域带来的新思想新价值。
点击“阅读原文”,报名读书会