计算美学百篇论文大综述:如何从复杂性科学视角进行审美

对于艺术、美学的定量研究是跨学科研究的代表。最近物理学家 Matjaž Perc 在英国皇家学会 Interface 期刊发表了一篇综述,梳理了近年来上百项利用网络科学和物理学方法对烹饪、视觉、音乐、文学这四类艺术表现形式美的研究。我们对这篇论文做了全文翻译,希从复杂性科学的角度,和你一起探讨对艺术的理解。
美究竟是什么?是主观体验,还是客观属性?
这个问题在哲学和美学中曾经长期争论不休。
尽管古希腊柏拉图在《大希庇阿斯篇》就曾讨论过美,区分了“美的事物”和“美本身”,然而最终却没有给出满意的答案,以“美是难的”结束了对话。就如评论家常用“高贵的单纯”与“静穆的伟大”形容古希腊艺术,同时兼具沉静与激情特性一样,在美中我们确实能看到蕴含了许多矛盾的因素。哲学家雷恩 (Michael Wreen)曾对此评价:
美表达了有限的、形式中可感知的东西,以及无限的、超越形式的东西,联结着可测度的东西与不可测度的东西,联结着人的世界与自然和神灵。

拉奥孔:动与静完美的结合。复原自古希腊的群雕“拉奥孔与儿子们”,兼具和谐与扭曲之美,作为古典雕像却在千年后启发了浪漫主义美学
论文题目:
Beauty in artistic expressions through the eyes of networks and physics
论文地址:
https://royalsocietypublishing.org/doi/10.1098/rsif.2019.0686
该论文回顾了现有文献,特别是对烹饪、视觉、音乐和文学艺术的研究,介绍了包括艺术绘画的熵复杂性,饮食风味网络的创造和食物配对的原理等一系列精彩的研究。此外还探讨了文化史和文化组学(culturomics),以及物理学和社会科学之间的联系等。
以下为论文全文翻译:
目录
一、从社会物理学到计算美学
二、烹饪艺术
三、视觉艺术
四、音乐艺术
五、文学艺术
六、总结与展望
一、从社会物理学到计算美学
在过去十年里,数据科学已经成为科研领域的新的热点,这一被《哈佛商业评论》称为“21世纪最性感的工作”,以数据维度的丰富性和每天海量数据的增长速度[1],利用数学、物理、计算机科学、信息科学,当然还有统计学的方法和技术,以及可视化技术的生动呈现,超越了各学科界限发挥协同作用,为社会科学和自然科学之间的架起一座桥梁。
若从历史发展看,自然科学,尤其物理科学和社会科学之间的协同作用已经存在了几个世纪。
早在十七世纪,托马斯·霍布斯就把他的国家理论建立在运动定律的基础上,特别是惯性定律;然后才由同时代的伽利略在物理上推导出来。亚当·斯密在18世纪下半叶提出的“看不见的手”与现在著名的经济与社会自我组织[18,19]概念惊人地相似,在当时被认为和万有引力定律一样可靠[20]。
而在十九世纪,不断发展的物理学理论将物质视为原子和分子的巨大集合,启发了人们对社会的统计学,包括可预测的平均值的观点。法国政治经济理论家亨利·德·圣西蒙(Henri de Saint-Simon)更是切实提出,社会可以用类似于物理学中的规律来描述。正如气体中分子的随机运动产生了数学形式简单的气体定律一样,人们认为社会也可以用类似集体可预测性的方式来描述。因此,正如菲利普·鲍尔(Philip Ball)指出那样[21],早期社会学就在根据一种隐含的信念来建构,即存在着一种“社会的物理学”,尽管至今大部分还在星空深处。
直到如今拥有了大数据以及各种计算方法,人们才可能超越古典社会学诸多隐含假设,直接对人类集体行为进行研究,就像对物质粒子进行研究一样[2]。类似统计物理学的方法被大量应用到诸如交通[3]、犯罪[4]、流行病[5]、疫苗接种[6]、合作[7]、气候怠惰[8],以及抗生素的过度使用[9]和道德行为[10]等课题中。
总之,在统计学和计算物理学的进步、数据的可获得性以及网络科学[13-16]与计算社会科学[17]等相关研究领域的推动下,一种社会系统物理学,社会物理[11]或曰社会物理学(sociophysics)[12]——无论其名称如何,在过去二十年里都保持了极好的增长势头。
当然,对人类社会的中可测现象进行研究和数学化描述是一回事,对艺术来说,试图做同样的事情又是另一回事。正如意识现象的神秘莫测一样,艺术中,可能也有一些东西是科学理性永远无法触及的。然而尽管如此,有些地方我们很可能永远无法理解,但还是有许多研究者试图弥合这一鸿沟,并成功地取得了让科学和艺术都感到满意的结果。
这条研究路线中最具代表性的就是计算美学[22],其思想根源早在20世纪上半叶就已经诞生。当时美国数学家 George D. Birkhoff 提出,秩序与复杂度之间的比值作可以作为一种美学度量[23]。因此,计算美学的主要任务就是发展新的科学方法来量化美,并建立人类审美感知的模型[24],尽管此外它也影响着计算机生成式艺术(computer-generated art)。
这里举一个介于社会和艺术之间的研究案例:艺术引发的人类集体行为——重金属音乐。
Silverberg 等[25]研究了人类在重金属音乐会上的集体运动,表明这种社交聚会会产生极端的行为,类似无序的气体状或有序的漩涡。如图1所示,这两类呈现的所谓“迷雾坑”(mosh pit)和“圆坑”(circle pit)之间的差异可以在群体模拟中精准重现,从而证明即使是相对非常简单的数学模型也能准确描述人类集体行为的本质。

二、烹饪艺术
烹饪是否是一门艺术还有些争议。或许在麦当劳拼装一个汉堡包,更多的是自动化流程,但为自己家人亲手打造一道美味佳肴可以说是一门艺术,(译者注:正如“西厨之王”奥古斯特·埃科菲(Georges Auguste Escoffier)以一己之力将烹饪提升到了艺术的境界一样)。
不过显然,烹饪即使作为艺术,也主要与食材准备与烹饪过程有关,和物理、网络又有什么关系?
大约八年前,Ahn 等人[29]发表了一篇论文,引入了风味网络来揭示食物搭配的基本原理,结果如图2所示。他们从诸如 cookpad.com 和 foodpairing.com 等美食网站获得大量食物搭配信息,以数据驱动方法为系统理解烹饪艺术开辟了新道路。
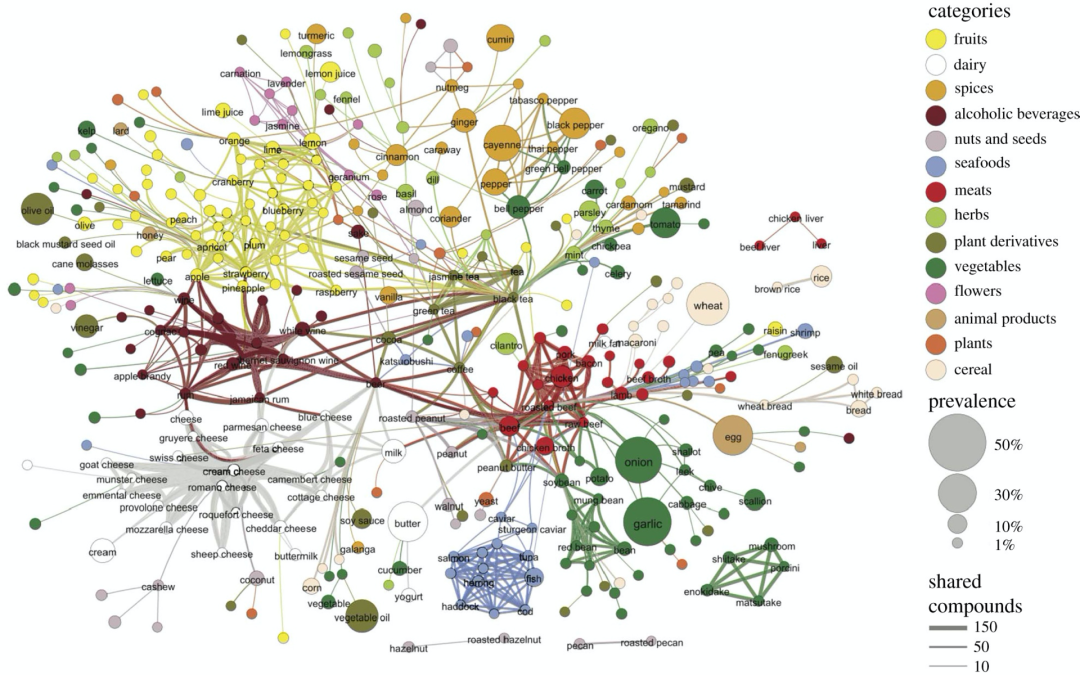
图2. 美食风味网络。每个节点代表一种食材,颜色代表所归属食物种类。节点大小反映了一种食材在菜谱中的普遍性。如果两种配料有显著数量风味的化合物共享,则表示它们之间有关联,链接的粗细代表两种配料之间共享化合物的数量。为了防止网络过于密集,只有在p值为0.04的情况下,统计学上有显著性的链接才会被标示出来。进一步的细节请参考原文献[29]。
在探索这些差异机制时,Ahn等人[29]发现,美食风味搭配效应的产生是由于在某一特定菜肴中经常使用的几种成分造成的。例如,北美的牛奶、黄油、可可、香草、奶油和鸡蛋,东亚的牛肉、姜、猪肉、辣椒、鸡肉和洋葱。这些发现与众所周知的“风味原理”[30]相呼应,根据这一原则,地方菜只有少数几种关键配料,比如亚洲的酱油或匈牙利的辣椒与洋葱。
在风味网络研究之前,Kinouchi 等人[31]就已经通过取自巴西的 Dona Benta、英国的 New Penguin Cookery Book《新企鹅烹饪书》、法国的 Larousse Gastronomique 和中世纪的 Pleyn Delit 等书对食材和食谱进行了统计。他们观察到食材的普遍分布具有尺度不变量行为,这促使人们建立了一个类似于网络中增长和偏好依附的数学模型[32],简而言之即所谓马太效应[33]。烹饪进化的复制-突变模型(copy-mutate model)[31]也被证明很好地拟合了经验数据。作者们还认为,这个模型表明了一种进化动力学控制着几个世纪以来食谱的进化,在这种进化中,一些特异性成分以类似于生物学中的奠基者效应的方式被保存了下来[34]。
近年来,随着烹饪艺术研究的不断深入,人们开始运用网络科学、物理学等相关学科的方法对烹饪艺术进行研究。例如,Teng 等人[35]展示了如何改进基于成分网络的食谱推荐。他们的研究表明,食谱评级可以很好地预测成分网络和营养信息的特点。
食物桥接假说(food-bridging hypothesis)被提出:假设两种成分没有共享一种很强的分子或具有经验亲和力,他们可能通过一系列成对的亲缘链联姻[36]。这与食物搭配假说(food-pairing hypothesis)[29]一道,可以区分出四类不同烹饪:东亚菜系倾向于避免食物搭配和食物桥接,拉美菜系倾向于包括食物搭配和食物桥接,东南亚菜系倾向于避免食物搭配但包括食物桥接,西方烹饪倾向于包括食物搭配但避免食物桥接[36]。
除此之外,这方面还有一些较小规模的研究工作。例如,关注阿拉伯美食,研究它是否符合食物搭配假说[37]。对中世纪欧洲美食[38]研究也涉及了风味配对,包括历史风味演变。作者特别关注数据不完全和错误的作用,为此使用了两个不同清洁度的独立化合物数据集,表明它们给出了与中世纪欧洲风味配对假说相矛盾的结论。
当许多新的配料突然出现时,对烹饪艺术的发展可能会出现一些预测,这些推论也被提出来讨论。例如中国地方菜系地理位置与气候相似性的关系,研究表明,决定中国地方菜肴相似性的关键因素是地理上的接近,而不是气候上的相似。
根据 Kinouchi 等人[31]烹饪进化的复制-突变模型,类似的模型也被专门用于研究不同的印度菜肴[40]。作者们认为,除了已确定的各地区之间的异同之外,在风味的化合物水平上对这些模型进行比较,可能会开辟一条通往分子水平研究的道路,将特定成分与糖尿病等非传染性疾病联系起来。
除了对地理和时代的兴趣之外,烹饪艺术和更硬的科学结合,也产生了类似《告诉我你吃什么,就知道你从哪里来:基于一种网络全球食谱的数据科学方法》(Tell me what you eat, and I will tell you where you come from: A data science approach for global recipe data on the web)这样的研究。正如标题所示,它催生了食物计算[42] ,从不同来源获取和分析各种食物数据,用于食物的感知、识别、检索、推荐和监测。这些计算方法,可以应用于解决食品相关的问题,在医学,生物学,美食学和农学等领域。
基于一个大型在线食谱平台的服务器日志数据,研究者还探索了网络上的食物偏好[43]。研究表明,食谱偏好在一定程度上是由食材驱动的,食谱偏好分布比食材偏好分布表现出了更多的地区差异,工作日的偏好与周末的偏好也明显不同。根据类似思路,研究人员还通过推特(twitter)[44]以及网络日志使用情况研究了网民的食物消费和饮食模式,得出了“你吃什么就推什么”(you tweet what you eat)的结论[45]。
最后我们以一本当代书籍《人人都吃》( Everyone Eats)[45]来结束这一部分探讨。该书探讨了我们为什么吃我们所吃的,为什么有些人喜欢香料、糖果和咖啡,为什么大米会成为东亚很多地方的主食。这本书聚焦于我们选择食物的社会和文化原因,可能是超越物理和网络、进一步探索饮食这个迷人主题的好帮手。
三、视觉艺术
三、视觉艺术
只不过一直以来,研究者面临的瓶颈是如何将视觉艺术转化为高质量的数字形式,尤其是对大量的美术作品。但自从有了 wikiart.org,这一问题得到了完美的解决,它为使用物理方法大规模分析艺术的铺平了道路。
熵-复杂性:艺术历史与艺术风格之树
基于大量数字影像数据,Sigaki 等人[56]通过熵和复杂性视角研究了艺术绘画的历史。包括近14万幅跨越近一千年艺术史的画作被纳入研究。结果很有趣,“复杂性-熵”平面(complexity-entropy plane)能很好反映了艺术史中的传统概念,如 Wölfflin 对美术线绘与涂绘的双重概念,Riegl 对有关触觉与光学的二分法[57,58]等。
线绘艺术作品(linear artworks)由清晰和分明的形状组成,而涂绘艺术品(painterly artworks)则通过融合图像边缘传递流动性的理念,轮廓往往模糊不清。类似地,触觉艺术品(haptic artworks)将物体描绘成有形的离散实体,被区分和限制,而光学艺术品(optic artworks)则通过利用光、色和阴影效果等创造开放空间中连续体,将物体描绘成在深层空间中相互关联的整体。
对以上特性与复杂性和熵联系起来,可以看出,线绘/触觉艺术作品可以描述为小的熵值H和较大的复杂性值C,而涂绘/光学艺术作品则预期会产生较大的熵值和较小的复杂性值。
通过日期对图像进行分组后取H和C的平均值,Sigaki 等人[56]做了量化艺术品在历史上的演变的研究。
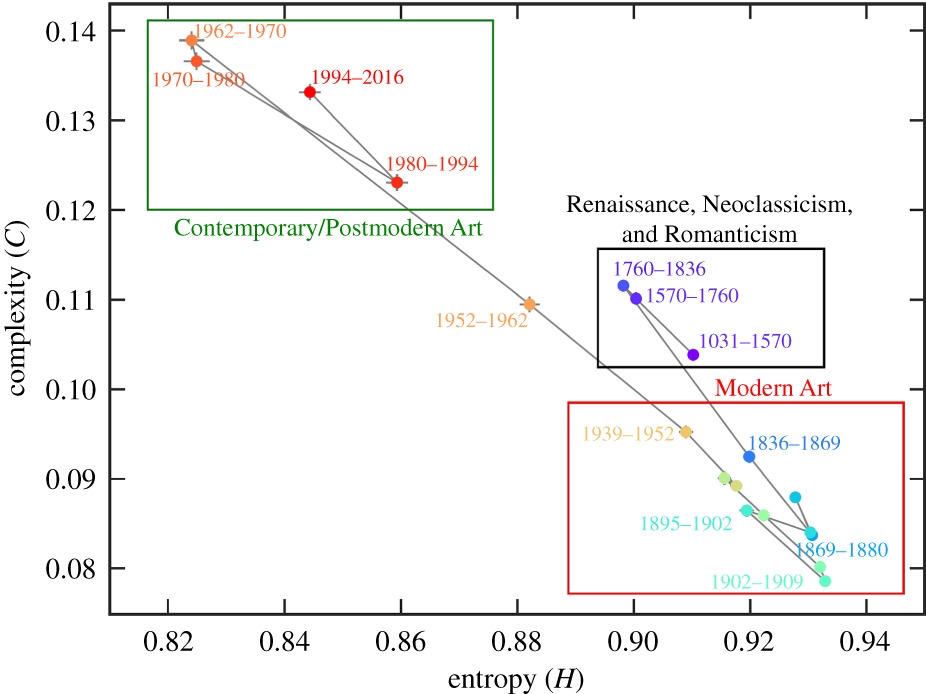
图3:量化艺术品在艺术史中的演变。描述了对应于给定时段内熵H和统计复杂度C的平均值随时间的演变。误差条代表均值的标准误差。突出标示的区域表示不同的艺术时期(黑色:文艺复兴时期、新古典主义和浪漫主义;红色:现代艺术;绿色:当代/后现代艺术)。可以看到,复杂性-熵平面正确地区分了不同艺术时期和过渡阶段[56]。
图3结果显示,在9世纪和17世纪之间创作的艺术品,平均来说比在19世纪和20世纪中期创作的艺术品更具有秩序。但有趣的是,在1950年后产生的艺术品,却比前两个时期的艺术品更规则有序。进一步可以观察到,在19世纪后,复杂性-熵平面的变化急剧加速,而这一时期恰恰与新古典主义和印象主义等几种艺术风格的出现时间相吻合。此外如图3所示,三个画出的区域与艺术史上三个主要分期也很好对应上了。
进一步地,复杂性和熵也可以以H-C平面来区分不同艺术风格[56]。由于H和C的值反映了艺术风格之间在图像像素局部排序方面的相似度,因此可以检测风格之间可能的层次组织关系。即H-C平面上的一组艺术风格之间的欧几里得距离可以当成它们之间相似的度量:两种艺术风格之间的距离越近,它们之间的相似性越显著,反之亦然。
对这个过程计算所得的结果如图4所示,可以理解为艺术之树,就像达尔文在《物种起源》对生物演化著名的生命之树比喻一样。
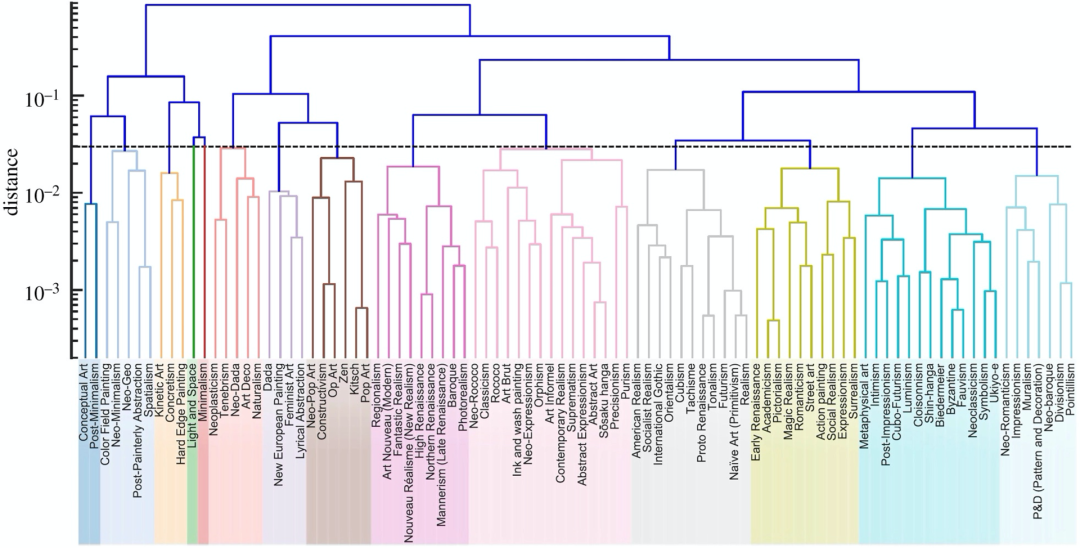 图4:艺术之树(艺术风格的组织层级)。以最小方差法计算矩阵距离,通过在距离阈值0.03处切割,获得由彩色树枝表示的14组风格的树形图。该数值最大化了定义数据集中聚类数量的轮廓系数(silhouette coefficient)。进一步的细节参考原始研究[56]。
图4:艺术之树(艺术风格的组织层级)。以最小方差法计算矩阵距离,通过在距离阈值0.03处切割,获得由彩色树枝表示的14组风格的树形图。该数值最大化了定义数据集中聚类数量的轮廓系数(silhouette coefficient)。进一步的细节参考原始研究[56]。艺术家风格转变
当然,Sigaki 等人[56]的研究并不是最早的。早在四年前,为了在艺术和科学之间架起一座桥梁,Kim [59]等就已经对绘画艺术进行了大规模的定量分析。他们重点关注单个色彩的使用、色彩的多样性和亮度的粗糙化情况。结果显示,古典绘画与摄影作品在色彩使用上存在差异,中世纪时期色彩使用种类则明显较少。在绘画技法如明暗法(chiaroscuro)和模糊法(sfumato)中,亮度粗糙化指数也有所增加,这与当时的历史情况是一致的。
这个小组后来还研究了现代绘画中的色彩距离的异质性,正确指出总体统计数据不能很好地衡量画家的个性,因为差异可能不仅来自不同的画家,还可能来自同一个画家使用不同的风格。
图5显示了对这方面[60]的深入分析,详细描述了几名具有代表性画家,囊括了几种截然不同但互补的艺术风格,即相对于时代主流他们的艺术生涯独特性的演变。这项研究为定义当代创造个性和多样性的非凡演进提供了宝贵的见解。
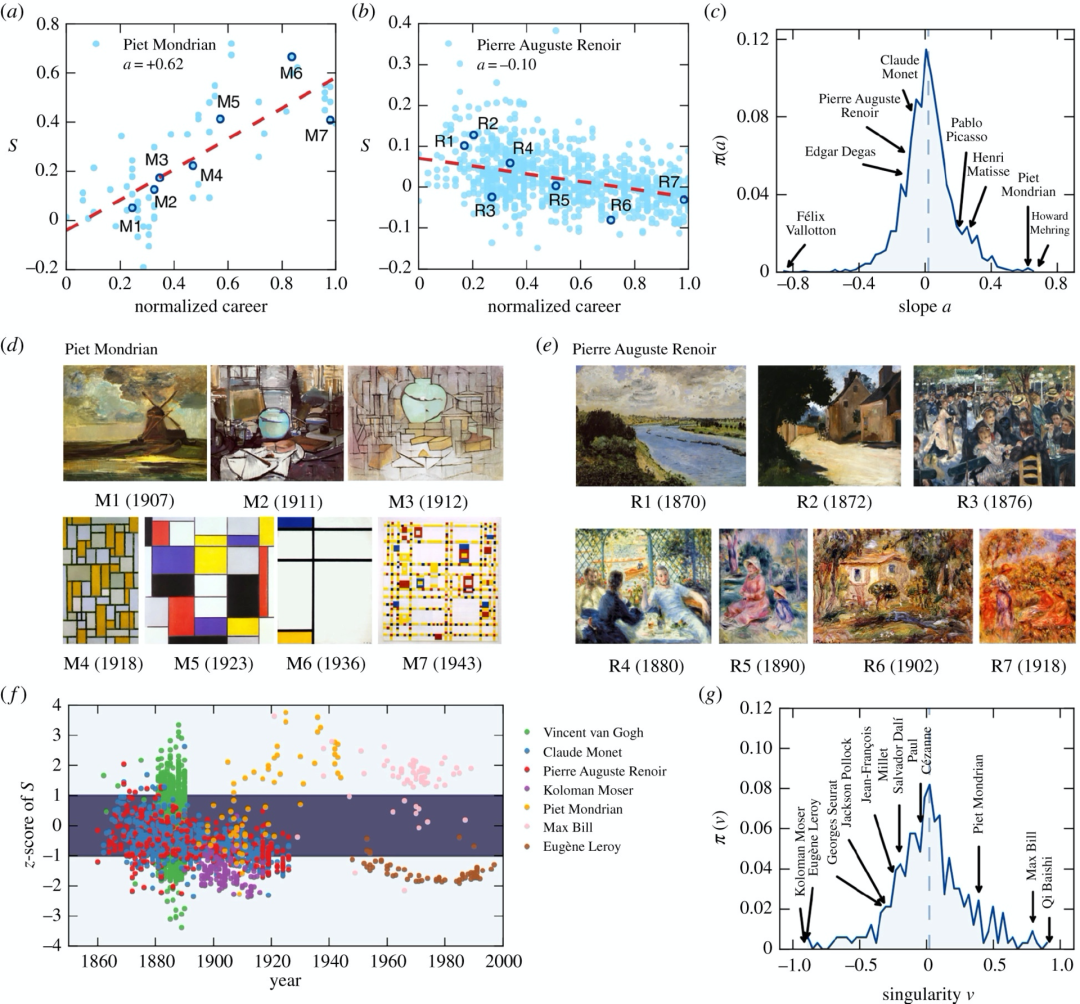
图5:对个别画家深入分析。(a,b)蒙德里安和雷诺阿绘画生涯的成长点线,红色虚线表示最佳线性拟合(c) 线性拟合1326个艺术家在至少五年不同绘画创作情况的直方图, 一些著名的艺术家被标出 (d,e)蒙德里安和雷诺阿绘画代表样本,展示了两位艺术家不同时期的风格转变(f)七位作品风格独特的艺术家(g)采样40幅以上330位艺术家绘画作品独特性的直方图。更多细节参考原始研究 [60]。
审美度量相关研究
在对视觉艺术进行量化研究之前,就已经产生了相关思想。如前面所提到,早在1933年,美国数学家 George D. Birkhoff 就出版了他的《美学度量》(Aesthetic Measure)一书[23],这本书催生了计算美学[22]。在这本书中,他提出利用图像中发现的秩序数与图像元素总数之比,即秩序 O 和复杂度 C 对则一个事物进行审美度量,审美值 M= O/C。
只是这个思想第一次应用时已到了在21世纪之初。Taylor [61]等人的研究表明,波洛克的绘画作品在其艺术生涯中的特点是分形维度越来越大。这随后启发了分形分析法在绘画中的应用[62-66]、艺术家演变 [67,68]、绘画[69]和艺术家[70-72]的统计属性、艺术运动[73]以及其他视觉表现形式[74-76]等方面的研究。
值得一提的是,分形艺术本身就是一个很吸引人的主题[77 ]。它在伊斯兰文化中很常见,例如土耳其塞利米耶(Selimiye Mosque)清真寺的主圆顶上,以及遍及世界各地的印度教寺庙中都有分形艺术。
此外最近还有一些创新的研究,主要是通过分析大规模的数据集,估算绘画和其他视觉艺术表现形式的平均亮度和饱和度[78,79]。
其他视觉艺术
除了绘画艺术之外,其他的视觉艺术还包括雕塑、陶瓷、摄影、摄像、录像、电影制作、设计、工艺品和建筑等。
值得注意的是,电影制作一直以来都是以演员网络为研究对象——如果两个演员一起出现在一部电影中,他们就会联系在一起。
在这个方向上最近的一次尝试是对《星际之门》和《星际迷航》系列电视剧中人物互动的社会网络分析。研究表明,这两部剧集的人物关系网都具有小世界特性,而且一集的基本网络结构可以告诉我们该集故事情节的复杂性。研究发现,剧集网络要么是封闭的网络,要么是有瓶颈(bottlenecks)的网络——这些瓶颈将互不相连的集群连接起来,又或者是二者的混合体。通过更详细的阅读,这二者也可以连接到相应的故事情节。不过除此之外其他形式的视觉艺术尚未与物理学和网络科学联系起来。
四、音乐艺术
四、音乐艺术
在所有艺术中,将音乐与科学联系在一起研究是最具有历史传统的。因此这里只关注一些相对较新的研究工作,主要是与物理学和网络科学两个学科之间的建立桥梁。
首先是 Park 等人[81]的研究,他们研究了西方古典音乐作曲家网络的拓扑和演化,基于 arkivmusic.com 和allmusic.com 的数据,建立了一个以 CD 和作曲家为两类节点的二分网络。具体来说,当一个作曲家的作品被记录在CD上、或两个作曲家在某CD上有共同出演的作品,作曲家和 CD、作曲家之间就会被连线。
在此基础上,Park 等[81]报告了大量的结果。包括网络表现出了许多现实世界网络的共同特征,如小世界属性、存在巨分量(giant component)、高聚集性和幂律度分布等。
他们还通过中心性、近似节点配对和群落结构探索了全球作曲家的关联模式,结果表明音乐家网络和人们对西方音乐传统的音乐理解之间存在着有趣的相互作用。此外,对“CD-作曲家”的二分网络历时增长研究发现,超线性偏好依附(superlinear preferential attachment)是解释增加顶层节点周围的边缘集中度和幂律度分布一个强力候选因素。

具体来说,提出了一个马尔科夫模型来分析记谱节奏事件的时间序列,并利用主成分分析(principal components analysis)和线性判别分析法(linear discriminant analysis)进行特征分析。前者是一种无监督多元统计方法,而后者是一种有监督的方法。两种不同的分类器,即高斯假设下的参数贝叶斯(parametric Bayesian)和凝聚层次聚类(agglomerative hierarchical clustering)被同时用来识别节律类别。
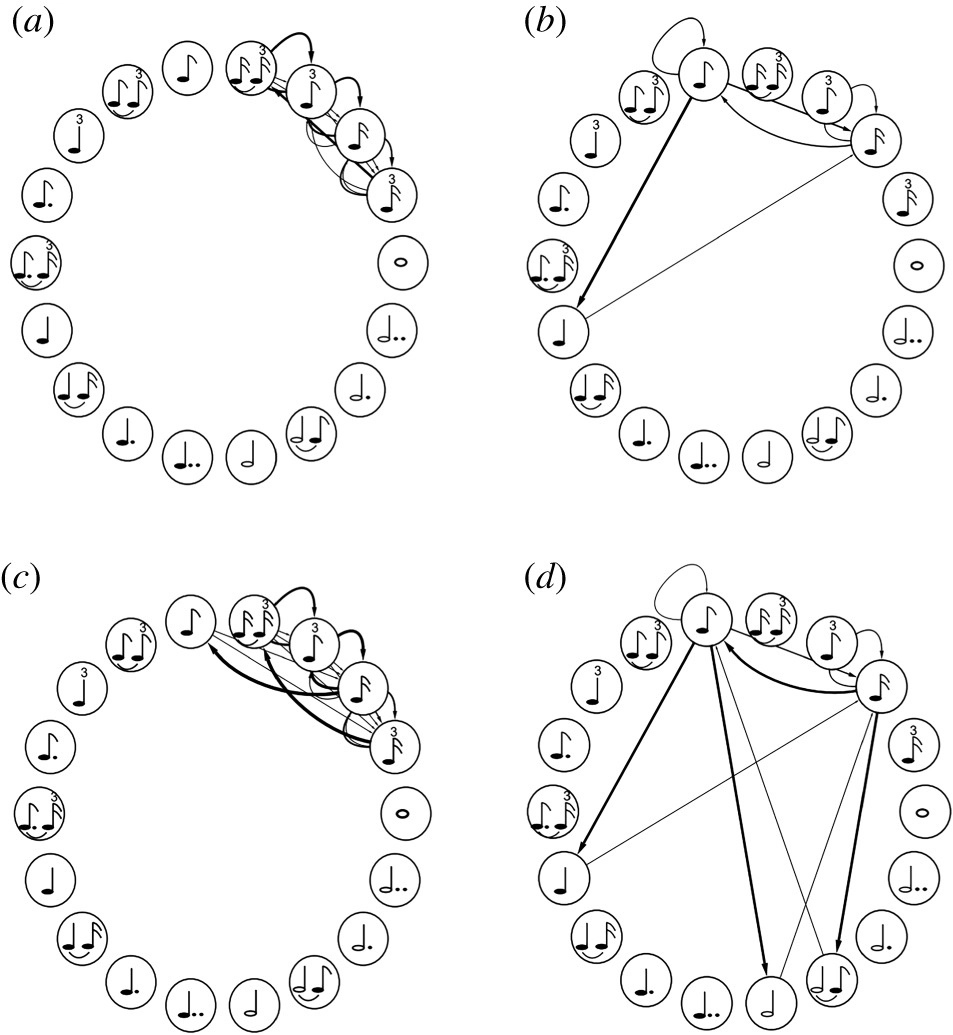
图7. 四个音乐样本的有向图示例。(a) B. B. King 的《How Blue Can You Get》(b) Tom Jobim 的 Fotografia (c) Bob Marley 的 This Love (d) The Beatles 的 From Me to You。自研究[82]。
有向图的每个顶点表示一个可能的节奏符号,例如四分音符、半音符、八分音符等等。而边缘则反映了后续的音符对。例如,如果有一条边从顶点 i(以四分音符表示)到顶点 j(以八分音符表示),这意味着四分音符之后至少有一次八分音符。此外,边越粗,这两个节点之间的联系就越强。
基于这种方法,Corrêa 等人[82]的研究表明,音乐节奏具有惊人的复杂性,并且包含许多冗余,需要许多特征来区分它们。事实上,正是因为特征太多,无法在此全面回顾。研究还发现,通过允许多流派分类,可以实现流派分类法的泛化,新的子流派会自发地从原来的流派中派生出来。虽然这项研究只关注节奏分析,但作者指出,对节奏进行更深入的分析,依然能提高此方法的有效性。
最近,部分同一组作者通过使用递归量化分析,研究了巴洛克作曲家约翰·塞巴斯蒂安·巴赫的十首作品是否源自马尔科夫链[83]。毫不奇怪,研究发现,”巴赫的大脑是马尔科夫链“这一相当难以置信的假设,在足够精细的代数分析下,可以被一致拒绝。
除了上面提到的例子展示了如何通过网络和物理学的手段研究音乐艺术的不同方面之外,类似的研究还包括:
-
应用复杂性-熵因果关系平面来区分歌曲[84]
-
识别歌曲和音乐流派的声音振幅中的普遍模式[85]
-
通过网络中的群落相关性提取音乐节奏模式[86]
-
对人群聚集声景(soundscape)的动力学量化[87]
此外,还有音乐理论方面的基础性工作,例如关于和弦的几何学[88],希望这种跨学科的研究能够为更好地理解音乐及其跨体裁、跨地域和跨时间的流行做出贡献[89]。
五、文学艺术
五、文学艺术
对艺术数字化影响最大的可能还是文学艺术。
以前只存在于纸上的东西变成了比特和字节。像 books.google.com/ngrams (谷歌n-gram浏览器)和 gutenberg.org 古腾堡计划这样的网站,以及像推特和脸书这样的社交网站,极大地促进了对大规模书面文本的定量调查研究[90-101]。然而,对这方面的研究的主要内容是统计特性,或者是寻找模因,文本中异同,而非艺术特性方面的研究。
其中一项引入瞩目的关注内容本身的研究成果是由 Reagan 等人[102]做出的:他们研究了从古腾堡项目小说集中筛选的1327个故事作为子集的情感弧线(emotional arcs)。作者使用了三种主要方法进行分析:奇异值分解(singular value decomposition),一种标准的线性代数技术;以 Ward 的方法产生故事的分层聚类,该方法最小化书本的聚类之间的方差[103];以及自组织映射[104],一种无监督的机器学习方法来聚类情感弧线。情感弧线是通过使用 hedonom.org 和 labMT 数据集[105,106]分析滑动10000字窗口的情绪而构建的。
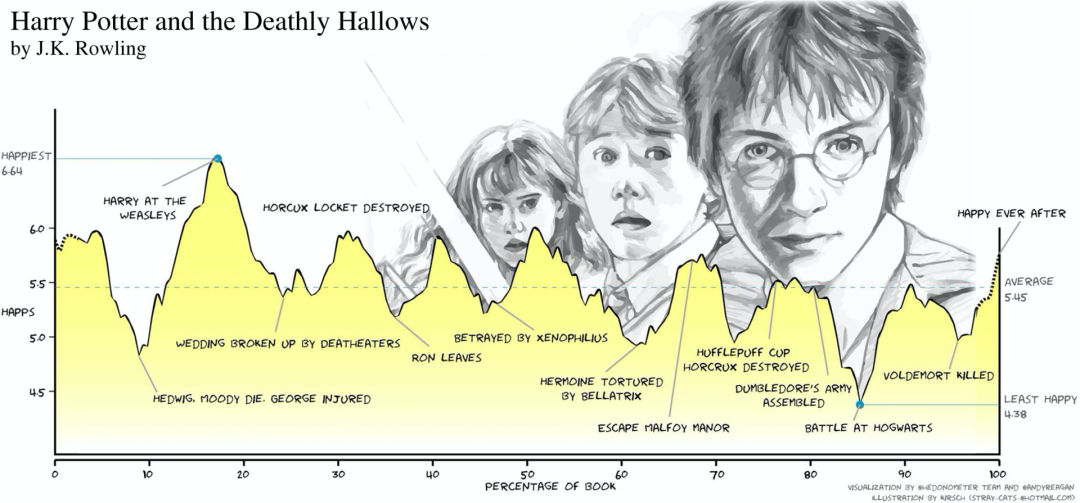
J.K.罗琳的《哈利·波特与死亡圣器》的结果如图8所示。故事的高潮和低谷都可以清楚推断出来。正如作者在论文中指出的那样,整个七部曲系列都可以归为“杀死怪兽”[107]类情节 ,只不过众多子情节相互联系又使得每一本书的情感弧线变得更加复杂化。这种方法的缺点是不会抓住那些简单的情感瞬间,如一个单独的段落或某一个句子。
至于图8中结果是否与读者的阅读体验相符,取决于多种因素。对于拥有全部哈利·波特书籍和DVD的笔者一家来说,它似乎确实非常适合,我十几岁的女儿 Ela 和她的朋友们都同意,最幸福的结局应该是”从此永远幸福”,而不是 “哈利在韦斯利家”。当然,但这是来自于一个群体的说法,其他人可能有不同的感受,完全不赞同图8所示的分析。
在更大范围内,Reagan 等人[102]的研究主要发现是,所有故事的情感弧都不超过六种基本模式:“飞黄腾达”(上升)、”悲剧 “或 “家道中落”(下降)、”人在洞穴”(下降—上升)、”伊卡洛斯”(上升—下降)、”灰姑娘”(上升—下降—上升)、”俄狄浦斯”(下降—下降—下降)。
强调这点很重要,即这相同六种情感弧是从所有可能弧线中获得的,是前面提到三种独立方法的共同结果,每种都发挥了各自独特的作用:奇异值分解找到所有情感弧的基础,聚类将情感弧分类成不同的组,自组织映射则使用随机过程从噪声中产生与语料库中情绪相似的弧。因此,这一结果切实可靠,有充分的证据支持。
在更小范围内,Markovič 等人[108]最近研究了斯洛文尼亚语文本 belles-lettres 中的结构和复杂性,重点是不同年龄组对文本评价的差异。
研究发现,单词的句法连接形成了复杂的异质网络,其特点是信息能够进行有效传递。研究还表明,随着读者推荐年龄的增加,文本的长度、平均单词长度、不同短语组合、文学人物之间的社交复杂性都会增加。反之,独特词汇的各种分量则表现为减少。
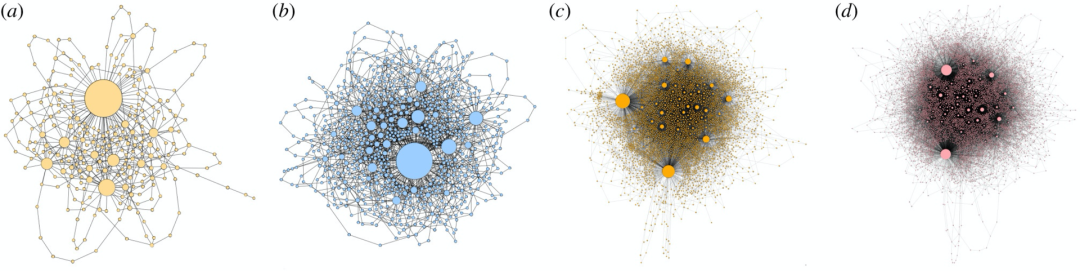
图9:斯洛文尼亚语文本在不同年龄组的语言网络。(a)为1-5岁的儿童(b)为6-8岁的儿童(c)为9-11岁的儿童(d)12-14岁的儿童。尽管网络规模和复杂性存在明显差异,可以明显看到网络的度都呈现幂律分布。此外,平均度和平均聚类系数随着读者推荐年龄增加,模块化程度下降;平均最短路径长度随年龄的增加而减少,尽管网络规模的增加又会引起小世界属性[109]。然而尽管有以上变化,所有网络直径几乎都是相同的。这些网络属性的详细数据请参考原始工作[108]。
在语言网络方面,如图9所示,Markovič 等人[108]发现,尽管网络规模有明显的差异,但在四个年龄组中,度分布都呈现幂律特征,并且幂律指数相似。显然,不同年龄组句法模式的一些属性并没有太大的差异,尽管所研究相对较小的规模的网络不允许更精确的比较。
其中语言网络的无标度特性在以前其他研究[110]中已有所报道。至于其它网络属性,研究显示平均度和平均聚类系数随着读者推荐年龄而增加。这一结果与独特词汇密度的递减趋势相一致。也就是说,对于较高的年龄组,在较长的文本中使用较少的独特词汇,因此需要更多的单词组合,这反过来也导致单个单词之间更多的联系以及更高水平的从属关系。
出于同样的原因,网络也会随着读者的推荐年龄的增加而变得不那么模块化。由于连接数量的增加,平均最短路径长度随着推荐年龄的增加而逐渐减少,尽管网络规模会大幅度增加。
这反过来又导致了所提取的语法网络的小世界拓扑特征。有趣的是,尽管平均连通性、平均最短路径长度和网络大小都发生了变化,但网络直径(diameter)在不同年龄组中基本保持不变。
总体而言,网络科学使得对斯洛文尼亚文学进行深入理论探索成为可能,能清楚看到不同年龄组之间统计特性的明显区别,从而以一种互惠互利的方式将艺术和精确科学联系起来。
最近 Ferraz de Arruda 等人[111]在进一步推进这一主题研究时,指出虽然建立起的词汇邻接(word-adjacency)或共现网络(co-occurrence) 成功地把握了书面文本的句法特征,但无法捕捉到主题结构。为了解决这个问题,他们提出了一个网络模型,以相邻的段落作为节点,每当它们共享最小语义内容时就连接起来。以刘易斯·卡罗尔的《爱丽丝梦游仙境记》为例,研究表明这种方法可以揭示文本的许多语义特征,否则这些特征是将被隐藏起来的。
从“只是单词”和短语转向不同程度的介观结构,如句子、段落或篇章,可能是使文学艺术更切合网络科学和物理学方法的下一步。
六、总结与展望
六、总结与展望
我们回顾了最近的研究,旨在弥合不同艺术表现形式与网络科学和物理学之间的差距。虽然其中所涉及的大多数作品都不是关于美本身的。但回过头来看,它确实能让我们通过量化和理解,当我们受到某种艺术形式影响时,有什么东西让我们觉得是吸引人、或者说是美的。
如果是喜欢的食物,我们现在可以欣赏到哪些食物搭配能让我们多吃一口,哪些搭配让我们重新回到餐馆。总体来说,东亚美食就像果酱,菜单上既不应该有食物配菜,也不应桥接,而东南亚美食吸引了那些不喜欢搭配但是喜欢桥接食物的人。西方美食则几乎完全是食物搭配而没有桥接,拉丁美洲食物则适合那些既喜欢食物搭配又喜欢食物桥接的人。
当我们看到一幅我们觉得美的画作时,就可以把这种美与熵和复杂性联系起来。如果我们喜欢有序、重复的图案,那就是低熵、高复杂度;此外一切 “绘画性”的东西都是高熵、低复杂度。这两个物理量可以很好地与艺术史上的传统概念联系起来。
由不同轮廓形成的图像会产生重复有序模式的。因此线绘/触觉艺术作品可以用小熵值和大复杂度值来描述;另一方面,由模糊边缘界定相互关联部分组成的图像会产生更多的随机图案,相应的涂绘/光学艺术品会预期产生更大的熵值和更小的复杂度值。
更进一步说,Wölfflin 的线绘与涂绘性的双重概念,和 Riegl 的触觉与光学的二分法,实际上可能限制了所有尺度界限的表现形式,因此熵值和复杂度值连续体的概念可能有助于艺术史学家在更精细尺度上进行评判。
当我们重复听一首歌时,从物理学和网络科学层面的研究可以帮助我们弄清楚超出经典音乐理论范畴的一些属性。
从网络的角度来看,基于节奏的特征,不同作曲家和流派的社区,以及复杂-熵因果关系平面,都可以帮助我们准确定位出特定歌曲中我们觉得美好的东西,改善个性化的音乐推荐,同时也可以提高我们对周围的人在特定音乐中的吸引力的理解。这些方法也可以用来尝试和预测几个著名艺术家的未来,并解读音乐网络的发展动态。即使不从传统音乐理论如几何和弦或类似的概念中抽取任何东西,网络和物理学研究也可以起到非常大的作用。
最后,当读到一个真正能打动我们的故事时,我们可以看看它的情感弧线是像“灰姑娘”一样的“升-降-升”,还是仅仅如“伊卡洛斯”那样的“升-降”。我们也可以了解自己是否喜欢那些来去无踪谜样的角色,还是更喜欢两三个主要人物来推动故事的发展。
从网络科学视角也能让我们看到故事的模块性,故事某些部分是否脱离了其他部分,以及它们又在什么时候结合在一起。在这里,介观文本结构的概念,如句子、段落或章节,可能成为定量语言学的新的前沿,不仅在统计方面,而在内容、故事性和情感弧方面。
从更广阔的角度来看,推动艺术发展的人、知识、工艺和技术,与我们的文化历史有关。在这方面,近年来网络科学和物理学的方法也发挥了重要作用,推动了相关学科主题研究[26-28]。
Michel 等人[28]的提倡的文化组学(culturomics),即那篇名为《利用数百万本数字化书籍对文化进行定量分析》(Quantitative Analysis of Culture Using Millions of Digitized Book)的论文,甚至过于乐观地估计,我们能对文化进行全面定量分析,以确切地理解到我们的文化。虽然随后的网络评论和研究很快就指出了这种基于数据推断社会文化和语言演化方法的局限性[112]。这意味着很多研究工作,例如[113,114],很可能是过早跳上了文化组学的浪潮[115]。不过这也往往是一个快速发展的领域本身的性质。最初过度热情和积极性被后来更慎重和谨慎的方法所抑制后,才开始最终成熟阶段,随之而来的是不可避免的衰退。
尽管如此,这条研究进路的受欢迎程度,以及通过计算美学[22] 与人工智能的联系,近年来一直在稳步增长。额外涉及的科学成果[116-118] 可参见 matjazperc.com/aps ,以及相应同行评审[119],以补充我们在导言中已提到的社会许多其他方面的研究,包括这里所回顾的艺术。
我们希望这篇综述对那些本职不同但又对互补研究领域着迷的研究者,特别是对那些寻求艺术和定量科学之间相互促进的研究者来说,能提供有益的信息和帮助。
列表可上下滑动显示更多
译者:十三维 审校:刘培源 编辑:曾祥轩
推荐阅读

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧!
👇点击“阅读原文”,了解更多论文信息
微信扫一扫,分享到朋友圈











