大语言模型在分子科学中的知识学习偏好:一项定量研究


论文题目:A quantitative analysis of knowledge-learning preferences in large language models in molecular science
论文地址:https://www.nature.com/articles/s42256-024-00977-6
期刊名称:Nature Machine Intelligence
深度学习在分子建模和设计领域取得了显著进展,尤其是大语言模型的引入,为从自然语言处理的角度处理科学问题提供了一种新范式。然而,如何量化模型与数据模态的匹配程度以及识别模型的知识学习偏好仍然是关键问题。本文提出了一个多模态基准ChEBI-20-MM,通过1263次实验来评估模型与数据模态的兼容性和知识获取能力。
多模态基准的构建与实验设计
多模态基准的构建与实验设计
为了有效地分析大语言模型在分子科学中的表现,研究人员构建了一个新的多模态基准ChEBI-20-MM。该基准结合了多种数据模态类型,包括SMILES、InChI、IUPAC names、SELFIES、说明文字和图像。研究通过设计跨域知识学习分析,探索模型在不同任务中的学习机制,通过局部特征过滤方法发现上下文特定的知识映射。
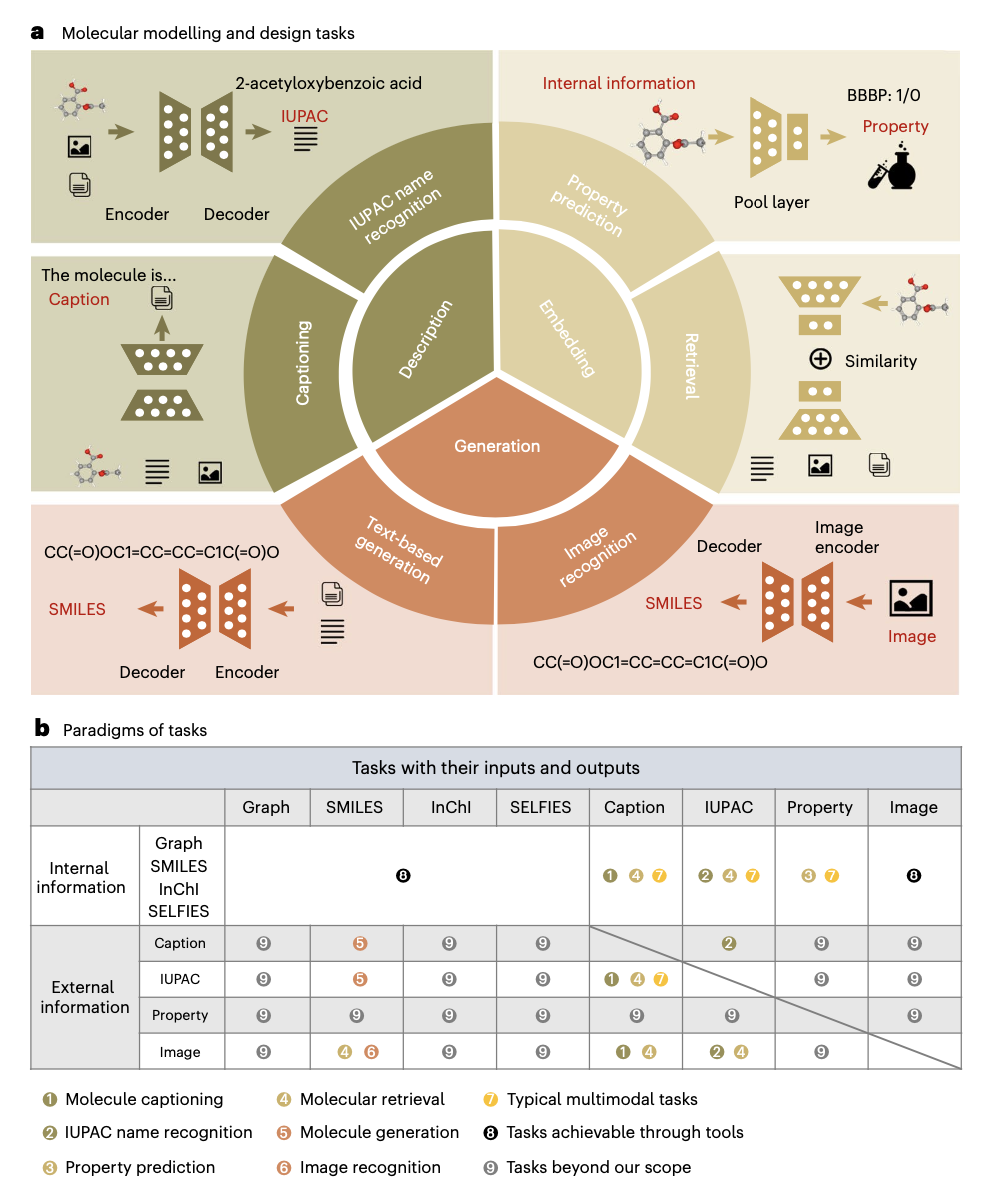
应用模态转换概率矩阵
应用模态转换概率矩阵
研究中构建了模态转换概率矩阵,分析各模态转换的效率。通过评估不同任务的模态适应性,研究人员使用METEOR评分和ROC_AUC等指标评估模态转换的有效性。通过这种分析,研究发现IUPAC names在生成和说明任务中具有优越的文本生成能力,而SMILES在IUPAC识别任务中表现突出。
模型架构的比较与优化
模型架构的比较与优化
研究表明,基于text-to-text transfer transformer(T5) 的大语言模型在分子科学中表现出色,超过了BERT和GPT变体的能力。实验结果显示,T5系列模型在编码和解码任务中具有明显优势。其中,平均池化机制在特征提取任务中展现了卓越的性能,验证了其在分子嵌入任务中的有效性。
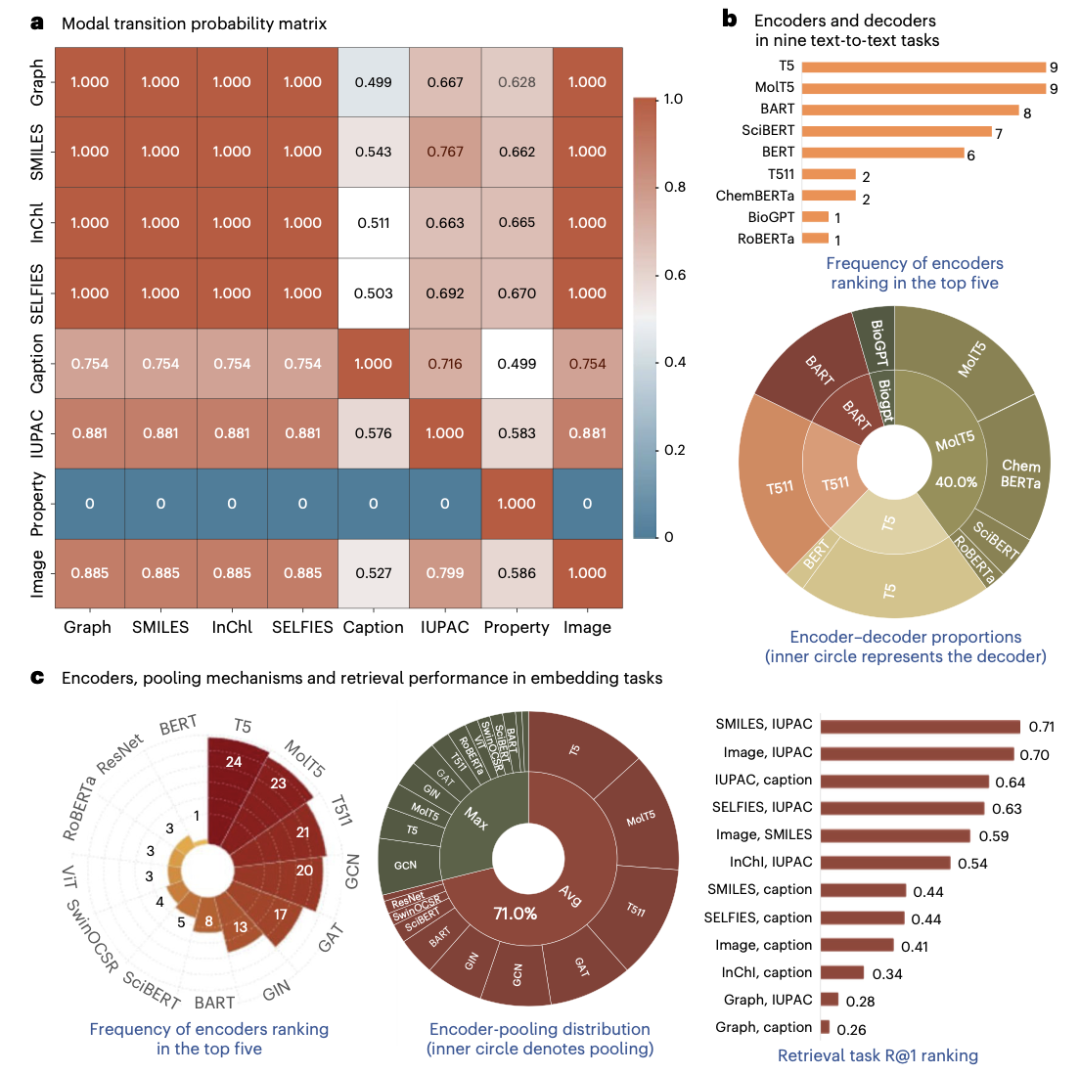
知识学习偏好的案例研究
知识学习偏好的案例研究
通过分析IUPAC names到说明性文字、SELFIES到说明性文字的映射过程,研究揭示了大语言模型在化学任务中的知识学习偏好。使用局部特征过滤方法,研究识别出特定高频映射对,并通过分子案例研究验证了其在实际应用中的有效性。
大模型2.0读书会启动
详情请见:大模型2.0读书会:融合学习与推理的大模型新范式!
6. 加入集智,一起复杂!
微信扫一扫,分享到朋友圈











