生命游戏是一种简单的符号表示模型,却可以产生复杂的结果。我们可以发现对生命游戏显然有效的,几组神经网络的初始参数解;但随机输入初始参数和选择样本的神经网络,却极难理解生命游戏,成功收敛到最优解需要一定“运气”。我们也可以选择,提高神经网络的复杂性,得到较优解,但这使资金和能耗水涨船高,不可持续。这种现状要求我们探索新的学习算法。
原文题目:
Why neural networks struggle with the Game of Life
原文地址:
https://bdtechtalks.com/2020/09/16/deep-learning-game-of-life/
本文属于我们的《AI研究综述》(reviews of AI research papers)——一系列追踪、探讨人工智能领域最新发现的报道。
生命游戏,是一种在科学、计算和人工智能领域广泛应用的网格自动机,这个模型所产生的行为表现出,简单的规则可以产生复杂的结果。
尽管生命游戏设定简单,但对于人工神经网络仍是一个挑战,来自斯沃斯莫尔学院和洛斯阿拉莫斯国家实验室的AI研究人员在他们最近的一篇论文中指出了这一点。
以 It’s Hard for Neural Networks To Learn the Game of Life 为题,他们研究了神经网络学习生命游戏的过程,以及神经网络经常错过正确解的原因。
原文题目:
It’s Hard for Neural Networks To Learn the Game of Life
原文地址:
https://arxiv.org/abs/2009.01398
他们的研究结果强调了深度学习模型的一些关键问题,并对AI研究的下一步方向,提供了一些有趣的线索。
英国数学家John Conway于1970年发明了生命游戏。
一般来说,生命游戏通过一个随时间演化的元胞网格呈现,每个元胞都具有两种状态:“存活”或“死亡”。
在每一个时刻,整个元胞网格,都会遵循一组简单规则进行演化——通过确定哪些元胞下一时刻转向“存活”或保持“存活”,以及哪些元胞下一时刻转向“死亡”或保持“死亡”,即以下四条规则:
1、如果一个“存活”元胞的“存活”元胞邻居少于两个,则因为种群密度过低,该元胞转为“死亡”元胞;
2、如果一个“存活”元胞的“存活”元胞邻居多于三个,则因为种群密度过高,该元胞仍转为“死亡”元胞;
3、如果一个“存活”元胞的“存活”元胞邻居恰好有两个或三个,该元胞仍保持“存活”;
4、如果一个“死亡”元胞的“死亡”元胞邻居恰好有三个,该元胞转为“存活”元胞;
基于这一组规则,我们可以通过设定元胞网格的初始状态,生成各种稳定的、振荡的和移动的斑图。
例如,下面就是被称为“滑翔机枪”的斑图,“滑翔机枪”可以不断地产生“滑翔机”斑图,“滑翔机”斑图是一种典型的移动斑图(经过一个固定的时间步周期,斑图变回原来的形状,且位置离开原处),“滑翔机枪”本身则是一种振荡斑图(周期变化的斑图)。
我们可以用生命游戏生成非常复杂的斑图,例如下面这个:

有趣的是,不论一个元胞网格有多复杂,我们都可以用同一组规则预测,下一个时间步上每个元胞的状态。
鉴于神经网络是一种强大的预测模型,研究人员想探究深度学习模型能否学会生命游戏的内在规则。
生命游戏之所以被选为神经网络的实验对象,原因众多。斯沃斯莫尔学院的计算机科学学员,也是这篇论文的共同作者 Jacob Springer 对 TechTalk 的采访人员说:“我们已经得出了一些结论。”
“我们可以人工编写一个能实现生命游戏的神经网络模型,然后再和通过训练生成生命游戏的神经网络模型进行对比。这不是问题所在。”
在生命游戏中,通过控制是时间步数就可以灵活的修改深度学习模型要预测的目标斑图。
神经网络处理生命游戏的方式,与在计算机视觉或自然语言处理这些领域的表现并不一样。因为,如果神经网络学会了生命游戏的规则,就可以达到百分之百的预测精度。
Springer谈到:“这种预测不会有任何模糊,换句话说,神经网络的预测只要错了一次,就意味着,它没有正确地学会生命游戏的规则。”
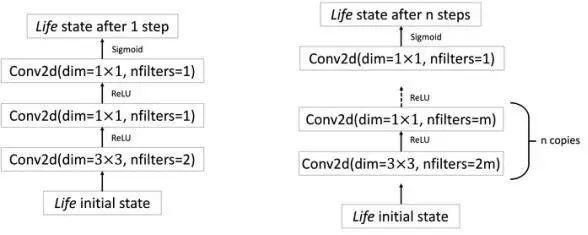
在他们的工作中,研究人员首先生成了一个小型卷积神经网络,通过手动调参校准使神经网络可以准确预测,生命游戏元胞网格的演化。他们证明了,存在一个最小化的神经网络能表示出生命游戏的规则。
接下来,研究人员尝试,通过数据剪接的手段,能否使同一个神经网络收敛到最优解?他们随机输入初始化参数值,并使用由生命游戏随机生成的一百万个样本作为训练集。
研究人员猜测,神经网络唯一能达到百分之分预测精度的模型,就是收敛到先前凭借手动调参得到的参数解。这意味着AI模型可以设法成功使得,对生命游戏内部的演化规则,进行参数化表示。
但是在绝大多数训练过程中,神经网络并未找到最优解,并且神经网络的表现随着训练步数的推进,不仅没有进步甚至还出现了退化。而且神经网络训练的结果,很大程度上受到了选定的训练样本集、初始参数值的影响。
不幸的是,我们并不清楚,神经网络的初始权重参数应该选为什么值。绝大多数训练采用的,是从正态分布中选取随机值的方法。因此选取到正确的初始权重参数,也要靠运气。
另外,对于训练数据集,在很多的一些训练情境中,我们并不清楚哪些样本是合适的,而在另外一些情境中,我们却又没得选。
Springer认为,对很多问题,在数据集中我们没有多少选择余地。“你拿着你能搜集得到的数据进行训练,所以如果你的数据集出现了问题,你就很难训练好神经网络。”
左图:一个手工设计的卷积神经网络能完全准确地预测生命游戏元胞网格的演化;右图:在实际训练中,通过数据剪接的手段,需要一个大得多的神经网络才能获得一样的预测准确度。
对于学习效果欠佳的模型,机器学习领域广泛应用一种策略,以提升预测精确度:那就是提升复杂性。该方法同样适用于对生命游戏的学习。
随着研究人员向神经网络嵌入更多的隐层,设置更多的参数,神经网络的学习能力逐步得到改进,最终神经网络已经可以产生接近百分百准确度的预测解。
然而,神经网络一变大,训练和运行深度学习模型所耗费的资金也会水涨船高。
一方面,这表现出大型神经网络的灵活性:尽管一个巨型深度学习模型可能并非解决所给问题的最优架构,它仍有很大的可能找到一个比较好的解。
但是在另一方面,它也表明,很有可能存在一个深度学习模型,量级更小,却可以提供相同甚至更好的结果——当然,前提是,你要能找得到。
这些结果符合“彩票假说”——由MIT的AI研究人员于2019年在国际学习表征会议(ICLR)中提出。
原文题目:
THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS
原文地址:
https://arxiv.org/pdf/1803.03635.pdf
该假说认为,对每一个大型神经网络,都有一个更小的神经网络,也可以收敛到一个解上,只要小型神经网络的初始化权重参数选取到“幸运”、“优胜”的值,也即“彩票”。
这篇生命游戏论文的作者写道:“彩票假说提出,在训练一个神经网络时,那些‘幸运的’小型神经网络,可以迅速收敛到一个解上。”
“这表明,不同于为求得最优解而广泛地搜索权重空间的方法,梯度下降方法也许依赖于权重参数的‘幸运的’初始化。这组‘幸运’参数恰好定位到一个子网络,靠近一个能使神经网络收敛的,合理的局部极小值。”
研究者在他们的论文中提到:“Conway的生命游戏是一种游戏问题,并且没什么实际的应用。我们的成果,对那些相似的学习任务可以提供启示。即这类神经网络有多个隐藏层,要训练学习一套有限的规则。”
这些成果可以应用于:使用逻辑或数学方法求解、气象与流体力学模拟、语言或图像的逻辑演绎,处理这些问题的机器学习模型。
Springer 认为:“鉴于我们已经发现,小型神经网络对学习生命游戏,这类通过相对简单的符号就能表达的模型,存在困难。我不妨估计,绝大多数复杂的符号处理,对于神经网络来说,应该会更难学习,也会需要更大的神经网络。”
“我们的成果并非意味着,神经网络不能学习和执行符号规则,做出决定。相反,我们其实在强调,这一类的这些系统可能非常难以学习,尤其是随着问题的复杂度增长的时候。”
研究人员进一步认为,他们的成果适用于机器学习的其他领域,包括那些不一定依赖严格逻辑规则的领域,例如图像和语音分类。
目前,我们知道,在某些情境下,通过提高神经网络的大小和复杂性,可以解决深度学习模型表现欠佳的问题。但我们也应该考虑,习惯把更大的神经网络作为常备解决方案,所产生的消极影响。
一方面来说,为训练大型神经网络所消耗的计算资源,都需要消耗更多的能源和产生更多的碳排放。
另一方面,这会导致我们收集更大的训练数据集,而非依赖于在更小数据集上设计理想的训练数据分布对策,来满足训练需要。在数据服从道德规范和隐私法律要求的今天,前者可能是不可行的。
最后,AI领域的总趋势正朝向于认可过度完备和规模巨大的深度学习模型。这会强化大型科技公司在AI领域的势力,而使更小的入场者难以负担海量的资金人力。
这篇论文的作者写道:“我们希望,这篇论文可以推进有关神经网络局限性的研究,使得我们可以更好地理解,凡事必用巨型神经网络,这一习惯所具有的瑕疵。”
“我们也希望,我们的成果可以推动更好的学习算法的发展,从而避免梯度学习方法带来的弊病。”
Springer 说:“我认为,这些成果当然可以促进搜索算法的改进研究,以及改进大型神经网络的效率。”
集智斑图收录来自 Nature、Science 等顶刊及arXiv预印本网站的最新论文,包括复杂系统、网络科学、计算社会科学等研究方向。每天持续更新,扫码即可获取:

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!
👇点击“阅读原文”,了解更多论文信息