涌现的计算方法:从计算力学到层级涌现

导语
什么是涌现?关于涌现是否存在一个形式化的计算方法?从默里·盖尔曼到P.W.安德森,许多科学家都探讨了复杂系统中的涌现现象。今天的文章选自意大利帕多瓦大学物理学教授、物理学家和复杂系统科学家 Manlio De Domenico 的博客,在文中,De Domenico 就因果涌现理论研究者 Fernando Rosas 的最新工作“涌现的计算方法”分别采访了 Rosas 和算法信息论专家 Hector Zenil。
Manlio De Domenico | 作者
杨明哲 | 译者
梁金 | 编辑
学者简介

什么是涌现?
什么是涌现?
碳原子中没有爱,水分子中没有飓风,美元钞票中没有金融危机。——Peter Dodds《复杂性解释》
你不需要更多的东西来得到更多的东西。这就是涌现的含义。——M. 盖尔曼
心理学不是应用生物学,生物学也不是应用化学。——菲利普·安德森
在软物质、硬物质和生物物质中,介观组织是在我们目前对(在非常大的粒子聚集体中长波长处)涌现组织行为(结晶性、铁磁性、超导性等)原理的理解的背景下进行考察的。 特别注意到尚未发现的组织原则可能在介观尺度上起作用的可能性,介于原子和宏观维度之间,以及它们的发现对生物学和物理科学的影响。寻找这种规则的存在性和普遍性,证明或反驳适用于介观领域的组织原则,被称为中间道路。


图1. 有关涌现现象的流行书籍和最近一期皇家学会的特刊。
论文题目:From the origin of life to pandemics: emergent phenomena in complex systems 论文地址:https://royalsocietypublishing.org/doi/10.1098/rsta.2020.0410 相关文章:从生命起源到流行病:复杂系统中的多尺度涌现现象
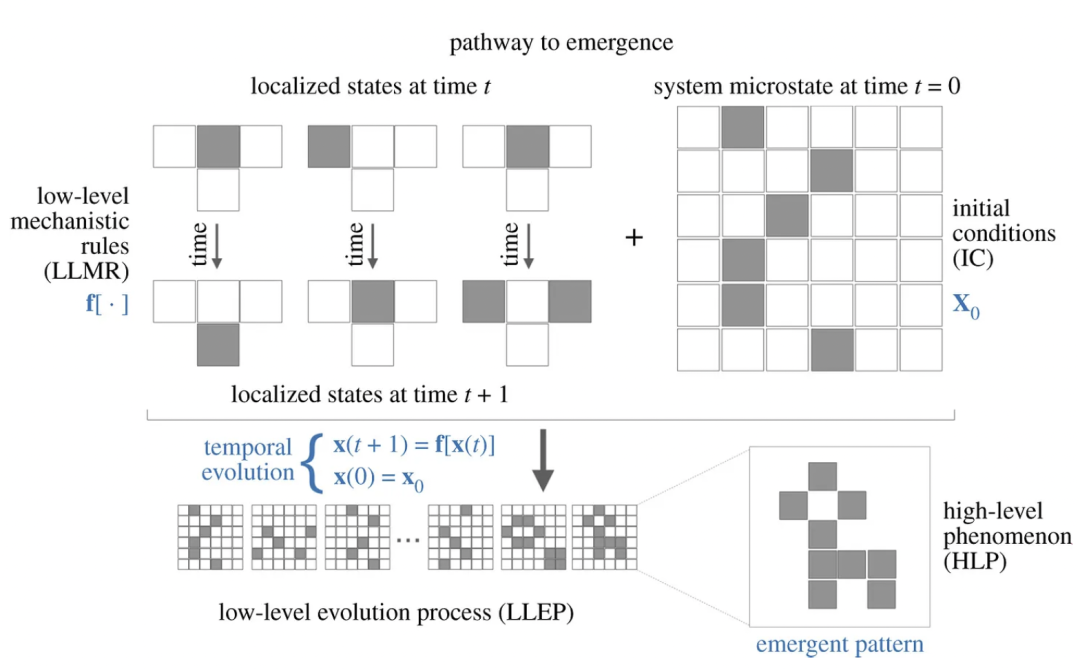
层次涌现的计算方法
层次涌现的计算方法
论文题目:Software in the natural world: A computational approach to hierarchical emergence 论文地址:https://arxiv.org/abs/2402.09090 相关文章:从生命到星系,新数学揭示大尺度秩序如何涌现
Fernando Rosas 在因果涌现读书会第五季的分享 整合信息分解框架提出者 Fernando Rosas:涌现现象的计算操作方法 https://pattern.swarma.org/study_group_issue/644
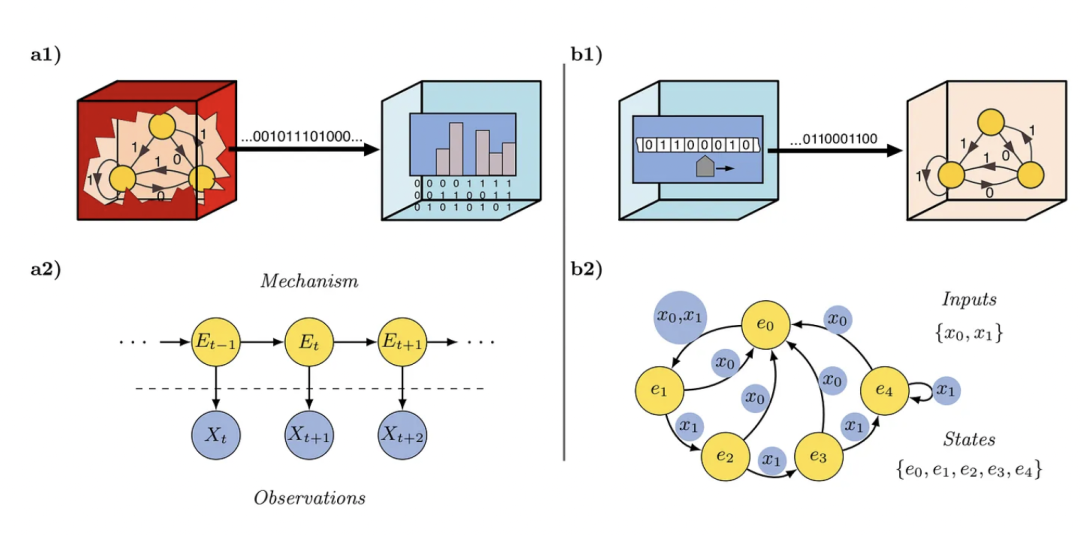
[1] Quantifying causal emergence shows that macro can beat micro
相关文章:《量化因果涌现表明:宏观可以战胜微观》
相关读书会:https://pattern.swarma.org/study_group_issue/79
[2] Reconciling emergences: An information-theoretic approach to identify causalergence in multivariate data
相关文章:《量化涌现:信息论方法识别多变量数据中的因果涌现》
相关读书会:https://pattern.swarma.org/study_group_issue/239
[3] Dynamical independence: Discovering emergent macroscopic processes incomplex dynamical systems
相关文章:《动力学独立性:在复杂动力系统中发现涌现的宏观过程》
相关读书会:https://pattern.swarma.org/study_group_issue/371
De Domenico:您认为粗粒化方法如何处理在两个不同描述层次之间发生的相互作用?这个框架在捕捉这些相互作用时是否存在局限性?
Rosas:确实。这种方法捕捉到了与“闭合”——可以被视为自给自足——相关的特定类型的涌现。这种方法并不适合研究跨层次的相互作用,例如自上而下的因果作用或类似现象。对于这些,人们必须使用其他方法。顺便说一下,目前还完全不清楚所有这些不同的方法是否能够统一到一个单一的方法中。澄清这一点将是未来重要的工作。
De Domenico:拥有信息闭合性为什么很重要?与传统的统计力学相比,它在关注宏观层面时可以忽略微观细节,这增加了什么?
Rosas:我认为信息闭合性是三种闭合性中最让人兴奋的类型。然而,通过将信息闭合性与因果闭合性和计算闭合性联系起来,人们可以以一种严格的方式将统计力学的概念与干预和计算的思想联系起来。因此,例如,人们不仅可以忽略微观细节,而且可以直接看到通过这样做计算是如何被简化的。顺便说一下,我相信还有很多工作需要更牢固地建立这些桥梁。这篇预印本只是朝那个方向迈出的第一步。
另外我们发现,各个层次可能是不可比的:也就是说,人们可能没有一个完全有序的层次序列,而是一个部分有序的晶格。我相信拥有多种不可比的粗粒化对于生物学和人工智能特别有趣,而充分利用这一点也是未来的工作。
这篇工作基于“ε-machine”的概念,这是 James Crutchfield 引入的一个概念框架,用于理解和分析数据序列中的模式和结构。理解和识别自然现象中复杂性的涌现涉及一个主观但关键的科学方法。它严重依赖于观察者如何构建模型来解释来自他们环境的数据,这些模型受到他们的计算工具的影响(他们可以收集的数据、他们用于存储的内存,以及他们可以投入分析的时间)。观察者可能认为有序、随机或复杂的东西直接与这些计算资源及其组织方式相关。识别模式的有效性在很大程度上取决于观察者使用的计算模型,这反过来可以显著影响观察者识别数据中规律的能力。
Computational Mechanics: Pattern and Prediction, Structure and Simplicity 相关文章:计算力学:量化涌现的又一条路径 相关读书会:https://pattern.swarma.org/study_group_issue/532
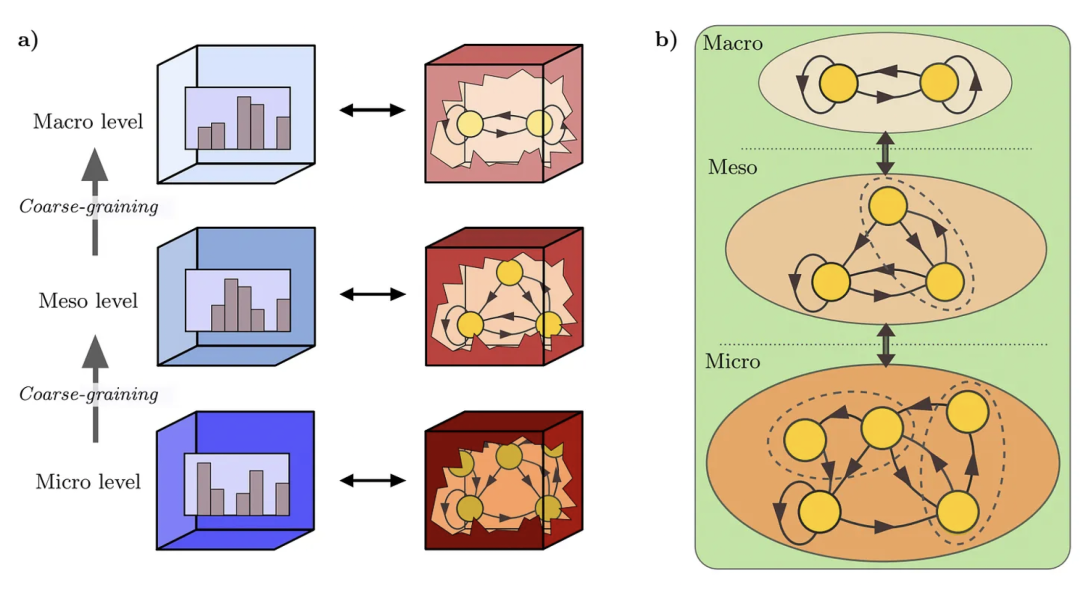
De Domenico:为什么需要考虑(或考虑的主要优势是什么)在每个尺度上使用 ε-machine?
Rosas:使用 ε-machine 提供了数据的双重表示,使得因果或信息闭合的粗粒化格点在 ε-machine 空间中有一个对应的图像,这与计算闭合的自动机格点相对应。这是有用的,因为通常情况下,从“实空间”的格点到“理论空间”的映射并不是一一对应的,所以后者通常更简单。而且,理论空间的格点形状是能最清晰地洞察系统多层次计算结构的形状。
根据 Crutchfield 的工作,我们知道 ε-machine 通过提供一个简化的计算模型来简化复杂数据,这使得理解系统不同部分如何相互作用和发展变得更容易。在这篇新论文中,如果我理解正确的话,作者使用粗粒化进一步将复杂数据简化为模型空间中的可操作结构(由 ε-machine 描述的“理论空间”),并确信这种选择提供了系统多层次组织最简洁(或类似)的描述。[注:我很想在描述长度方面测试一下]。
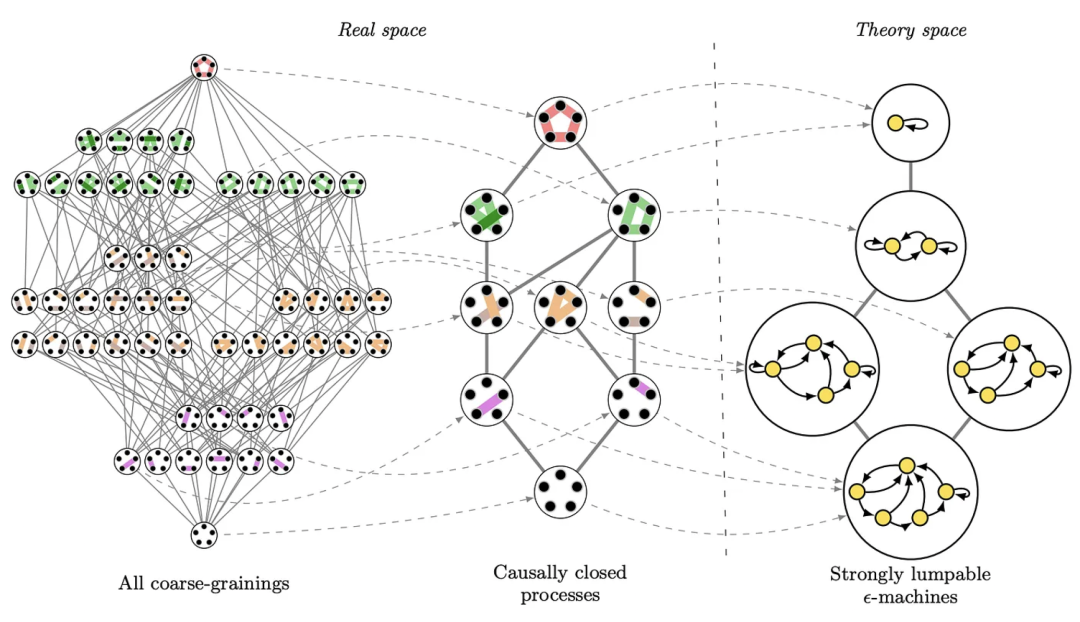
De Domenico:对于最简单的随机游走动力学,其中转换规则仅是局部的,达到目的地(B)的稳态概率不依赖于网络拓扑和起点(A),因为它仅依赖于目的地的度。然而,对于其他各种随机游走和更现实的动力学来说,情况可能并非如此。您能更好地解释这个问题吗?
Rosas:这是一个非常好的观点。我们的预印本并不是试图对网络上的随机游走说些什么一般性的内容,而是使用一个非常特定的网络来说明计算闭合是如何工作的。所以,虽然人们倾向于将随机游走视为一个局部过程,但对于这个特定案例,下一步的计算可以分解为三个嵌套的任务:
-
选择下一个社区的大小,
-
在相同大小的社区中选择某个特定的社区,
-
在选定的社区中选择节点。
小结
小结
James Crutchfield 关于涌现自组织原理的最新综述 On principles of emergent organization 相关文章:Physics Reports 最新综述:涌现自组织的原理
De Domenico 采访 Hector Zenil
De Domenico 采访 Hector Zenil
定义涌现的挑战之一是,一个观察者的先验知识可能导致一个现象被认为是涌现,而对另一个观察者来说,这一现象似乎是可简化的。通过将观察行为形式化为动态系统之间的相互扰动,我们证明了算法信息的出现确实依赖于观察者的知识,同时对其他主观因素具有鲁棒性。——Abrahão 和 Zenil
论文题目:Emergence and algorithmic information dynamics of systems and observers 论文地址:https://royalsocietypublishing.org/doi/10.1098/rsta.2020.0429
De Domenico:你能详细介绍一下你在《皇家学会哲学汇刊》发表的这篇论文中描述的软件算法方法与 F. Rosas 等人在 Arxiv上提出的 ε-machine 方法的对比吗?更具体地说,这些方法在建模涌现上的关键区别是什么?
Zenil:Rosas 等人的工作和我们的工作之间的主要区别在于,我们的工作强烈植根于因果关系方法的一些最基本的原则。我们的模型没有一个内在的随机方面,这可能是其处理涌现的主要创新,因此它拒绝了所谓强涌现的形式,以及涌现超出本体论还原论的所有神秘主义光环。相反,它将强涌现的出现转稼到观察者的限制上,从而选择了认识论还原论。
译注:本体论还原论侧重于认为在实在的本质上,复杂的事物和现象能够归结为更基本的实体或物质存在形式,强调的是事物本质层面的可还原性;而认识论还原论重点在于知识层面,关注复杂知识能否还原成简单知识去理解,二者侧重点有所不同。例如对于意识现象,本体论还原论可能会主张意识本质上就是大脑神经活动(将意识归结为物理基础存在形式),而认识论还原论则是探讨能否通过对大脑神经细胞、神经递质等基础的相关知识去彻底理解意识这一复杂的认知现象。
在最近的后续论文中(见下文),我们在使用无损统计压缩来近似算法(柯尔莫哥洛夫)复杂性的背景下,进一步研究这个问题。例如,一些编码算法在数据中找到因果模式的能力可能比其他算法更好。这种缺陷是由引入启发式方法的人的特定实例的主观性质引入的。这种主观性之所以可能,是因为最终压缩的不兼容性和不可判定性。当人们被迫采用完全可计算的方法时,例如,通过使用香农熵来近似随机性时,可以检索到“精确值”,但会失去主观性方面,除非像我们在香农熵中那样通过以无法获取联合概率分布的形式人为地将主观性注入模型中。我们的方法是在基础模型中不嵌入概率或随机性,因此在定义涌现方面不发挥任何根本作用。
在某种程度上,我们扼杀了让该领域困惑了几十年的强涌现概念。我认为我们以一种根本的方式做到了这一点,利用了我们认为唯一的因果关系理论,即算法复杂性(Kolmogorov-Chaitin),该理论规定了如何找到和选择可以编写为计算机程序的简短机械答案。换句话说,这些模型是可测试的,可以由机器或人类逐步执行,不需要其他假设,这是科学和科学方法的基础。这是已故 Barry Cooper 教授在可计算性背景下解释涌现的想法的基础。
论文题目:Emergence as a computability-theoretic phenomenon 论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0096300309004159
我们将这种大尺度上的简单性解释为一种斑图形成机制。在这种机制中,大尺度上的斑图的背后,是支配大尺度动力学的简单规则。— Israeli and Goldenfeld
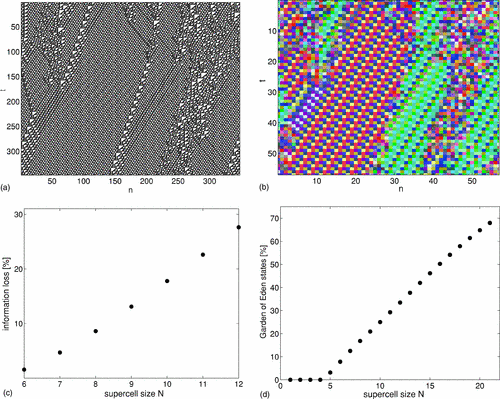
论文题目:Coarse-graining of cellular automata, emergence, and the predictability of complex systems 论文地址:https://journals.aps.org/pre/abstract/10.1103/PhysRevE.73.026203
De Domenico:你引用了 Israeli 和 Goldenfeld 近20年前发表的工作。你能告诉我更多关于早期研究如何与最近关于涌现的研究联系起来的,并加深我们对这些研究的理解吗?当然,共性是粗糙的,但是你认为这项工作的哪些具体方面或发现是关键的,但目前在 Rosas 的工作中体现不足?
Zenil:Israeli 和 Goldenfeld 以及 Rosas 等人的方法之间有许多共同点。Israeli 和 Goldenfeld 认为,多尺度动力学可以看起来彼此独立。他们在元胞自动机(CA)上证明了这一点,就像 Rosas 等人在 CA 上所做的那样,但与 Rosas 等人不同的是,Israeli 和 Goldenfeld 在引用更大规模更新 CA 规则的 Kolmogorov 复杂性时涉及了实际的有限自动机,出现了作为“粗粒度”函数的缩放定律(scaling law)。他们表明,大尺度粗粒度允许在其他细粒度随机系统中的预测能力(如 ECA 规则30),并且独立性是显而易见的。他们论文中因果的成分很少,完全是机械和计算的,而在我看来,Rosas 的论文中的因果和计算内容更少,尽管标题涵盖了计算模型,但不是一种统计方法,是用词不当。
这并不是说 Rosas 等人的贡献毫无价值。如果我没用科学家的偏见视角去看它,我会发现它更有趣,除了我认为与“自然世界中的软件”或“计算方法”相关的层次涌现可能会分散读者的注意力,而且是没有根据的。我们之所以认为这种方法是计算的,就是因为它包含了 ε-machine,而这实际来自名字的误用,也许它是受到实际的自动机使用的启发。我非常尊敬的 ε-machine 的最初作者,称他们的“机器”变量为“因果态”,他们的领域为“计算力学”等等,部分原因是这些变量,根据作者的说法,是“筛选”属性,这些属性对于 Pearl、Spirtes 和其他人在80年代和90年代引入的因果推理统计方法的基础至关重要,但与物理因果关系或计算机程序的因果关系没有任何关系。
De Domenico:你注意到 ε-machine 在很大程度上是随机的,因此仅限于探索相关性而不是因果关系。你能讨论一下使用随机模型研究涌现现象的潜在好处和局限性吗?这些模型如何(或可能)影响复杂系统领域的结果解释?
Zenil:ε-machine 由 James Crutchfield 和 Karl Young 在80年代提出,可能是由有限自动机等实际机器驱动的,但它们根植于80年代由 Judea Pearl 和 Peter Spirtes 等研究人员率先提出的因果方法。ε-machine 是黑盒函数,旨在通过相关函数捕捉因果关系。这就是 Rosas 等人在他们的文章中描述方法时的第一个解释的意思。ε-machine 存在第二个解释,但它不能真正与第一个解释共存,它们是相互排斥的。第二个解释来自原始作者的初衷,不幸的是,迄今为止,Rosas 等人的工作将 ε-machine 描述为某种“自动机”。如果第二种解释成立,论文的贡献会更大,但是论文论证第一种解释是正确的。论文是因为错误的原因而被信任的。
在我看来,基于 ε-machine 的方法研究涌现几乎没有计算或因果内容。这是一种有趣的系统方法,可以在统计相关领域内研究抽象和涌现的程度。对我来说,这篇论文最有趣的部分是这种结合传统信息论和微扰分析的多尺度动力学实验方法。
然而,当一个人认真地把自动机作为对涌现现象的解释时,我们已经使用科学中最传统假设之一(机器解释)的算法信息论原理正式表明,“强涌现”的概念只是一个人工制品。这也与认识论中的随附概念有关。在心智的背景下,这意味着不可能有两个事件在所有物理方面都相同,但在某些“精神”方面有所不同,或者一个物体在不改变某些物理方面的情况下不能改变某些精神方面。换句话说,没有隐藏的无法解释的原因导致了无法从其他潜在原因解释的涌现现象。没有什么是不能被解释的,只有我们作为有限的观察者不能解释。只能有弱涌现,这种涌现类型只出现在旁观者无知的眼睛上。当然,问题有两个方面:(1)我们没有目睹过,所有多重尺度和因果轨迹导致明显的涌现现象,(2)历史上我们在处理因果关系方面一直很糟糕。
科学史及其实践可以被看作是两股相互对立的力量,或者是对非因果 vs 因果解释的发现,从摆脱随机性和偶然性,魔法和神圣的解释到摆脱占星术,再到过去的几十年里摆脱相关性。科学史基本上是我们在每一个给定时间处理因果关系的有限程度的历史,从逻辑的发展到发现自然物理定律。传统上,我们不知道如何处理或衡量因果关系,但在80年代引入了另一种强大的工具,即扰动和干预分析以及反事实的概念。反事实是一种人为的假设,可以再次作为相关性或通过计算机模拟(因此是机械的)来探索。Rosas 等人的工作属于前者(通过相关性来探索),但方向是正确的。
从这个意义上说,Rosas 等人的论文成功地将这些因果工具与传统信息论相结合,以研究涌现的概念。我们团队多年前通过实际的有限自动机(接近通用图灵机和计算机程序)将这些工具与算法信息论相结合,涵盖了过去10年发表的几篇论文,如《Nature Machine Intelligence》、《Physics Reviews E》、《皇家学会汇刊》等,最近由 Springer Nature 出版了一本书,去年由剑桥大学出版社出版了另一本书。我们称之为算法信息动力学的理论和框架(AID)。

为了解释我们是如何将涌现的问题完全推给观察者的,可以参考我们去年发在 Arxiv 上的另外两篇论文。我们发现我们能够不可知地重建消息的寓意,即使这些消息可能包含噪音或部分加扰或解构。这是因为压缩算法的缺陷和不可计算性。如果我们用终极压缩算法完美地度量算法复杂性,消息的所有配置都将携带相同的(算法)信息内容,我们将一开始就无法重建它。因此,大多数观察者的限制揭示了另一个主观发送者的原始意图。因此,在两端,我们都有主观错误系统,它们只能理解对方,因为它们是我们自己的技术问题和数学上的限制。因此,不可计算性导致了意义发现,我们认为这是交流的基础,可以捕捉意义的意义,并可能导致开放的演化。
论文题目:An Optimal, Universal and Agnostic Decoding Method for Message Reconstruction, Bio and Technosignature Detection 论文地址:https://arxiv.org/pdf/2303.16045 论文题目:Decoding Geometric Properties in Non-Random Data from First Information-Theoretic Principles 论文地址:https://arxiv.org/pdf/2405.07803
De Domenico:您认为还有哪些其他关键论文或研究人员应该包含在关于基于算法和软件的涌现的讨论中?
Zenil:Rosas 等人的论文在引用以前关于经典信息论和涌现的工作方面做得很好,但是当谈到结合算法、计算和软件方法来处理因果关系和涌现时,我已经在上面提到了一些,包括 Cooper 的、Israeli 的和 Goldenfeld 的以及我们自己的工作,我认为这些工作帮助推动了这个领域的发展。
我经常感到不幸的是,科学写作已经变成了某种科学小报新闻,试图为一篇科学作品找到最佳的商业角度来吸引人们的注意力。一些科学媒体和作家在决定公众应该消费什么以及如何消费科学方面变得过于强大,科学媒体只是复制文章,放大可能发出错误信息的信号,现在甚至连科学影响者也制作视频复制已经大肆宣传的原始来源。这不应该是科学新闻对我们今天生活的后真相的、分裂的社会所提供的价值。我们应当追求更客观的平衡和准确性。关于一个话题的新闻工作应该是提供信息、背景和真正对立的观点。
后记
后记
本文翻译自 Manlio De Domenico 的博客文章。
原文链接:
https://manlius.substack.com/p/a-computational-approach-to-emergence
https://manlius.substack.com/p/a-computational-approach-to-emergence-536
因果涌现读书会第五季
跨尺度、跨层次的涌现是复杂系统研究的关键问题,生命起源和意识起源这两座仰之弥高的大山是其代表。从2021年夏天至今,集智俱乐部已经陆续举办了四季「因果涌现」读书会,系统梳理了因果涌现理论的发展脉络,深入探讨了信息整合与信息分解的本质,并探索了在生物网络、脑网络、机器学习等跨学科领域的应用。此次因果涌现读书会第五季将追踪因果涌现领域的前沿进展,展示集智社区成员的原创性工作,希望探讨因果涌现理论、复杂系统的低秩表示理论、本征微观态理论之间的相通之处,对复杂系统的涌现现象有更深刻的理解。读书会已完结,现在报名可加入社群并解锁回放视频权限。
推荐阅读
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











