为了帮助大家更好地了解因果科学的最新科研进展和资讯,我们因果科学社区团队本周整理了第3期《因果科学周刊》,从 Causality, Causal Inference, Causal AI 三个维度鸟瞰,推送近期因果科学值得关注的论文和资讯信息, 同时我们也将向大家介绍社区正在推进的活动——因果科学与Causal AI读书会第7期中的主要报告内容、观点。
本期作者:沈哲言 龚鹤扬 陈晗曦 袁蕾 陈天豪 禹含 徐培 刘家硕 杨二茶
因果科学社区简介:它是由集智俱乐部、智源社区共同推动,面向因果科学领域的垂直型学术讨论社区,目的是促进因果科学专业人士和兴趣爱好者们的交流和合作,推进因果科学学术、产业生态的建设和落地,孕育新一代因果科学领域的学术专家和产业创新者。
因果科学社区愿景:回答因果问题是各个领域迫切的需求,当前许多不同领域(例如 AI 和统计学)都在使用因果推理,但是他们所使用的语言和模型各不相同,导致这些领域科学家之间沟通交流困难。因此我们希望构建一个社区,通过组织大量学术活动,使得科研人员能够掌握统计学的核心思想,熟练使用当前 AI 各种技术(例如 Pytorch/Pyro 搭建深度概率模型),促进各个领域的研究者交流和思维碰撞,从而让各个领域的因果推理有着共同的范式,甚至是共同的工程实践标准,推动刚刚成型的因果科学快速向前发展。具备因果推理能力的人类紧密协作创造了强大的文明,我们希望在未来社会中,因果推理融入到每个学科,尤其是紧密结合和提升 AI ,期待无数具备攀登因果之梯能力的 Agents (Causal AI) 和人类一起协作,共建下一代的人类文明!
如果您有适当的数学基础和人工智能研究经验,既有科学家的好奇心也有工程师思维,希望参与到”因果革命“中,教会机器因果思维,为因果科学作出贡献,请加入我们微信群:扫描下面社区小助手二维码加入(请备注“因果科学”)👇
本期周报中的论文推荐,将以稳定学习(Stable Learning)为主题,我们按照:基于结构因果模型的方法(Structural causal model based methods)、基于分布鲁棒优化的方法(Distributionally robust optimization based methods)、基于样本加权的方法(Sample re-weighting based methods)这三个类别向大家推荐八篇论文。
这八篇论文的核心主题是如何用因果帮助构建稳健的机器学习预测模型,属于因果机器学习的范畴。
Peters, J., Bühlmann, P., & Meinshausen, N. (2016). Causal inference by using invariant prediction: identification and confidence intervals. Journal of the Royal Statistical Society. Series B: Statistical Methodology, 78(5), 947–1012. https://doi.org/10.1111/rssb.12167
论文标题:Causal inference by using invariant prediction: identification and confidence intervals
摘要:用因果模型和非因果模型做预测的区别是什么?假设我们干预了预测变量或改变了整个环境,因果模型的预测效果,一般来说,在干预和观察数据下同样有效。相反,对于干预后的数据,用非因果模型做预测可能会导致严重的错误。本文提出利用因果模型的预测不变性来进行因果推断的方法:给定不同的实验设定(例如不同的干预),我们记录了对不同设定和干预下在预测准确率上保持不变的模型。因果模型有很高的概率是这个模型集合中的成员。在相当普遍的情况下,这种方法可以保证识别出的因果关系的高置信度。我们以结构方程模型为例进行了更详尽的研究,并提出了充分的假设来保证因果预测变量的可识别性。我们进一步分析了方法在存在模型错估下的鲁棒性和可扩展性。我们研究了方法在各种数据集下的应用,包括大规模的基因扰动数据集。
Pfister, N., Bühlmann, P., & Peters, J. (2018). Invariant Causal Prediction for Sequential Data. Journal of the American Statistical Association. https://doi.org/10.1080/01621459.2018.149140
论文标题:Invariant Causal Prediction for Sequential Data
摘要:我们研究了从d个解释变量的集合(X1, . . . , Xd)中推断目标变量Y的因果预测变量的问题。经典的最小二乘回归使用了所有能够降低Y的方差的预测变量。如果我们仅使用具有因果关系的预测变量,而不是全部的预测变量,我们就会使模型在干预的情况下能够保持一种不变性。大致来说,模型会在不同的环境下或是异质样本的模式下保持不变。更准确的来说,在给定因果预测变量的条件下,Y的条件分布对所有的观测保持不变。近期的研究工作探索了在不同的已知环境下从数据中推断因果关系。我们的研究显示即使没有关于环境或是异质模式的知识,对于时间序列数据(或是任何其他种类的顺序定序数据)来说推断因果关系是可行的。特别地,这会使在多变量的线性时间序列中检测瞬时的因果关系成为可能,这是传统的格兰杰因果检验无法做到的。除了新方法外,我们提供了推断因果预测变量的统计置信界限和渐近检测的结果,并且展示了该方法在宏观经济的货币政策中的应用。
John Duchi, Hongseok Namkoong.(2020) Learning Models with Uniform Performance via Distributionally Robust Optimization. Forthcoming at Annals of Statistics. http://arxiv.org/abs/1810.08750
论文标题:Learning Models with Uniform Performance via Distributionally Robust Optimization
摘要:统计学和机器学习的一个共同目标是学习出能够很好地应对分布偏移的模型,这种分布变化可能因为潜在的具有异质性的子群体、未知的协变量变化或未建模的时间效应等导致的。我们提出并分析了一种分布鲁棒随机优化框架 (Distributionally Robust Optimization, DRO),此框架学习的模型在数据分布的扰动下具有有良好的性能。我们给出了此问题的一个凸优化形式,并提供了收敛性保证。我们证明了在有限样本下极大极小化优化的上下界,表明维持分布上的鲁棒性有时需要牺牲收敛速度。通过完全指定极限分布从而使得置信区间可以被计算,我们对于学习参数的极限给出了理论保证。在实际任务中,包括对未知子群体进行泛化、细粒度识别和提供良好的尾部性能,分布鲁棒方法通常表现出更好的性能。
Shen, Z., Cui, P., Kuang, K., Li, B., & Chen, P. (2018). Causally regularized learning with agnostic data selection bias. In ACMMM. https://doi.org/10.1145/3240508.3240577
论文标题:Causally regularized learning with agnostic data selection bias
摘要:此前大多的机器学习算法都是基于独立同分布假设的。然而这个假设过于理想,在真实场景中由于训练数据和测试数据的选择偏差的存在,这个假设往往不成立。甚至,在大多场景下,训练模型的时候,测试数据是不可获得的,这使得迁移学习这样的传统方法不可行,因为迁移学习需要测试分布的先验知识。因此,如何应对未知的选择偏差、学习更鲁棒的模型,对于学术研究和实际应用都至关重要。在本篇论文中,在假设变量之间的因果关系跨环境不变的情况下,我们将因果的技巧融入了预测模型中,提出了因果正则逻辑回归(CRLR)算法,同时实现全局混淆变量平衡与加权逻辑回归。全局混淆变量平衡有助于因果关系特征的识别,这些特征对预测变量的因果效应是跨环境不变的,然后再对这些有因果关系的变量做逻辑回归,从而得到一个对选择偏差很鲁棒的预测模型。为了验证CRLR算法的有效性,我们在模拟数据和真实数据上都做了实验,实验结果清楚地表明我们的CRLR算法比最先进的方法的效果更好,并且我们的方法的可解释性可以通过特征可视化体现出来。
Shen, Z., Cui, P., Zhang, T., & Kuang, K. (2020). Stable Learning via Sample Reweighting. In AAAI. Retrieved from www.aaai.org
论文标题:Stable Learning via Sample Reweighting
摘要:我们考虑带模型误判偏差的线性模型的学习问题。在这种情况下,变量之间的共线性可能会增加参数估计的误差,而在训练集和测试集不同的情况下,这会导致预测结果的不稳定。 在这篇论文中,我们从理论上分析了这个重要的问题,并提出了一种样本重加权的方法,来减小输入变量之间的共线性。我们的方法可以被看作是一种数据预处理,用来改进design matrix,这个方法可以和任何一种标准的学习算法结合起来做参数估计和变量选择。 模拟数据和真实数据的实验都表明了我们的方法的有效性,在不同分布的数据上可以获得更稳定的预测效果。
Yue He, Zheyan Shen, Peng Cui. Towards Non-I.I.D. Image Classification: A Dataset and Baselines. Pattern Recognition, 2020
论文标题:Image Classification: A Dataset and Baselines
摘要:训练与测试数据间的独立同分布假设是大量图像分类算法的基础。这条性质在实践中很难被保证,因为非独立同分布情况是普遍的,导致这些模型的性能是不稳定的。然而过去的文献表明,非独立同分布的图像分类问题很少被研究。一个关键的原因是缺乏设计精良的数据集来支撑相关研究。本文中,我们构建了一个非独立同分布图像数据集(NICO),我们利用先验信息来构造非独立同分布性质。同其它数据集相比,扩展分析表明NICO有足够的灵活性来支持不同的非独立同分布情况。同时,我们用卷积网络结构提出了一个针对非独立同分布图像分类任务的基线模型,其中测试数据的分布是未知的且不同于训练数据。实验结果表明NICO可以很好的支持卷积模型从零开始训练,批次平衡模块可以帮助卷积网络在非独立同分布设定下表现得更好。
Kuang K, Xiong R, Cui P, et al. Stable Prediction with Model Misspecification and Agnostic Distribution Shift[C]//AAAI. 2020: 4485-4492.
论文标题:Stable Prediction with Model Misspecification and Agnostic Distribution Shift
摘要:对于许多机器学习算法,需要两个主要假设来保证性能。一是测试数据与训练数据来自同一分布,二是要正确指定模型。然而,在实际应用中,关于测试数据和底层真实模型的先验知识通常是很少的。在存在模型错估的情况下,训练数据和测试数据之间的未知分布变化会导致参数估计的不准确和未知测试数据预测的不稳定性。为了解决这些问题,我们提出了一种新的去相关加权回归 (Decorrelated Weighting Regression, DWR) 算法,该算法联合优化了变量去相关正则器和加权回归模型。变量去相关正则器为每个样本估计权重,使得变量在加权训练数据上去相关。然后,将这些权重应用于加权回归中,提高对各变量影响估计的准确度,从而有助于提高对未知测试数据预测的稳定性。大量的实验结果表明,我们的DWR算法可以于存在模型错估和未知分布变化的情况下,显著地提高参数估计的准确性和预测的稳定性。
Kuang K, Li B, Cui P, et al. Stable Prediction via Leveraging Seed Variable[J]. arXiv preprint arXiv:2006.05076, 2020.
论文标题:Stable Prediction via Leveraging Seed Variable
摘要:在本文中,我们研究在未知的测试数据下做稳定预测的问题,在该问题中,测试数据集的分布是不可知的并且可能完全不同于训练数据集。在这种情况下,用过去的机器学习方法可能得到的是在训练数据中由非因果的预测变量导致的虚假关联。这些虚假关联会随着数据的变化而变化,导致了跨数据集预测的不稳定性。通过假定在不同的数据集中因果效应变量和目标变量的关系保持不变,我们提出了一种基于条件独立性测试的算法,以便在存在一个先验的种子变量时划分出这些原因变量,并且在稳定预测时使用这些原因变量。通过假定因果变量和非因果变量之间的独立性,我们表明,无论是在理论还是实验上,我们的算法都能精准的将因果变量和非因果变量区分开来,以用于跨数据集的稳定预测。大量的仿真和真实实验证明,我们的算法相比于现在的稳定学习算法实现了最优的效果。
这里,我们向大家推荐清华大学计算机系长聘副教授、智源青年科学家崔鹏团队的NICO数据集。NICO数据集是一个新型的具有跨数据集泛化性指标的数据集。该数据集的发布旨在引起大家对新型数据集的更多关注,并促进对人工智能内在学习机制的研究。NICO数据集建立的初衷是吸引更多机器学习的研究者关注智能认知的本质机理。这样的机理将更接近人类智慧的习惯(比如因果),因此具备跨环境的稳定性和鲁棒性。
那么,它相比传统数据集有什么优势?如何支持因果研究?目前绝大部分的数据集都是基于独立同分布的实验场景设定,并没有考虑到数据本身的特性,也没有更多因果关系可言,这对于模型的泛化帮助甚微。区别于传统数据集,NICO的图像样本除了主体类别标签,还有唯一的上下文信息描述主体的属性或者背景,通过在训练环境和测试环境中以不同比例组合不同的(主体对象,上下文)单元,可以灵活方便地构造数据环境模拟不同的Non-I.I.D.场景,支持对智能认知的本质机理的研究。NICO数据集通过构造有数据分布偏差的训练和测试集,支持因果的研究。比如NICO可以在训练环境和测试环境组合不同的(主体对象,上下文)单元。
关于NICO的详细细节(包括下载地址等),请参见NICO的官方网站:http://nico.thumedialab.com
Schölkopf, B. (2019). Causality For Machine Learning. CoRR. Retrieved from https://arxiv.org/pdf/1911.10500.pdf
推荐大家阅读德国Bernhard Schölkopf 教授的观点。由Judea Pearl开创的图形化因果推理起源于人工智能(AI)的研究。在很长的一段时间里,它与机器学习领域几乎没有联系。本文讨论了在哪些方面应该(或已经)建立连接,同时介绍了一些关键概念。Bernhard Schölkopf 认为,机器学习和人工智能的难点开放问题与因果关系有内在的联系,并解释了该领域如何开始理解这些问题。
【内容标签】Causal AI 综述,因果机器学习
2020年11月8日晚8点,因果科学与Casual AI读书会第七期——“因果推理与稳定学习”如期进行,清华大学计算机系在读博士生沈哲言 、刘家硕作了精彩分享。
Part 1: Causal Inference and Stable Learning
1. Causal Inference and Its Implication for Learning
2. Learning Stability and Robustness
3. Theory and Algorithms for Stable Learning
4. Applications and Benchmarks
在常见的机器学习问题中,我们会使用一个基于训练数据集估计的模型来预测未来的结果值。当测试数据和训练数据来自同一分布时,许多学习算法都被证明是有效的。然而,在给定的训练数据分布上性能最好的模型通常会吸收和拟合一些特征之间微妙的统计关系——虚假关联,当模型被应用于分布不同于训练数据的测试数据时,这些利用虚假关联的模型可能更容易出现预测错误。如何开发出对数据变化具有稳定性和鲁棒性的学习模型对于学术研究以及那些对于风险比较敏感的实际应用都是至关重要的。
在这次分享中,我们会把因果分析的思想引入到传统的机器学习设定当中,探讨如何利用好这一经典的统计分析工具来解决更为复杂的机器学习实际问题;同时,我们也会拓宽传统机器学习的评价标准,引入稳定学习这一概念来刻画一个模型的综合性能,并结合因果的技术提出一些有效的算法。
Part2: Causality and Its Connection to Robust Machine Learning (论文解读)
本次分享主要包含对于因果稳定预测和分布鲁棒优化两个方面经典论文的分享和解读,并通过一定的形式化建立起因果发现和鲁棒机器学习之间的桥梁,提供一个更加统一的视角来看待因果和机器学习。
J.Peters et al. Causal inference by using invariant prediction: identification and confidence intervals
H.Namkoong et al. Stochastic Gradient Methods for Distributionally Robust Optimization with f-Divergences
大数据时代的下一场变革——因果革命正在酝酿之中,通过融合因果推理和机器学习而构建出来的Causal AI系统,有望奠定强人工智能的基石。
集智俱乐部联合北京智源人工智能研究院,邀请了一批对因果科学与Causal AI感兴趣的研究者,开展为期2-3个月的系列线上读书会,研读经典和前沿论文,并尝试集体撰写一部书籍。如果你也从事相关的研究、应用工作,欢迎报名,参与读书会的讨论!
时间:9月20日起,每周日晚19:00-21:00,持续约2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
了解读书会具体规则、报名读书会请点击下方文章:
目前读书会已经有超过130余人的海内外高校科研院所的一线科研工作者以及互联网一线从业人员参与,如果你也对这个主题感兴趣,就快加入我们吧!
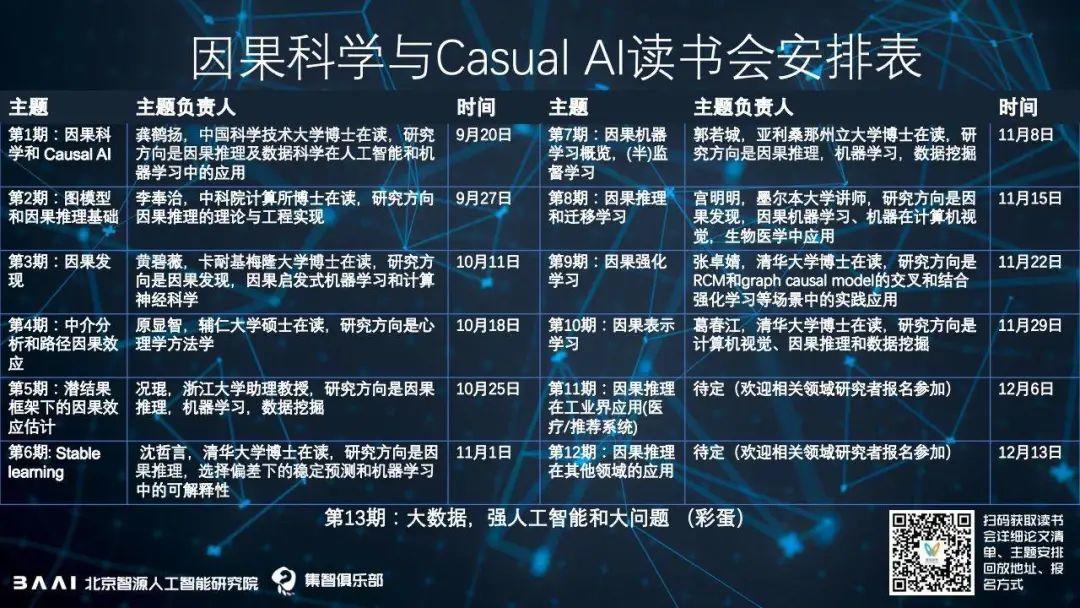
图注:针对读书会的主题,由发起人龚鹤扬设置好了内容框架,每个主题下有一个负责人来负责维护组织相关内容,目前已经定好的如图所示,欢迎对主题感兴趣的联系相关负责人,以及来认领相关主题。

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!














