近日,来自北京大学、 UCLA、中科院、马里兰大学、斯坦福大学、西湖大学等6个机构的作者合作撰写了一篇关于机器学习在计算流体力学中近期应用的重磅综述。文献首先详细介绍了基础概念、传统方法和基准数据集。在系统地回顾了近五年的论文后,本文为计算流体力学中的前向建模引入了一种新的分类方法:数据驱动的替代模型、物理信息驱动的替代模型和机器学习辅助的数值解决方案。此外,本文还回顾了逆向设计和控制中的最新机器学习方法,并提供了一种新的分类方法。在应用层面,本文梳理了机器学习在空气动力学、燃烧、大气与海洋科学、生物流体、等离子体、符号回归和降阶建模(Reduced order modeling)等关键科学和工程学科中的实际应用。最重要的是,本文探讨了该领域的关键挑战,并提出了克服这些挑战的未来研究方向,如多尺度表示、物理知识编码、科学基础模型和自动科学发现。这篇综述作为快速扩展的AI for Science社区的指南之一,旨在激发研究人员对于推动未来科学领域中的发现的洞察力。
研究领域:AI for Science,机器学习,计算流体力学,替代模型
汪海昕、吴泰霖 | 作者
论文题目:Recent Advances on Machine Learning for Computational Fluid Dynamics: A Survey
论文链接: https://arxiv.org/pdf/2408.12171
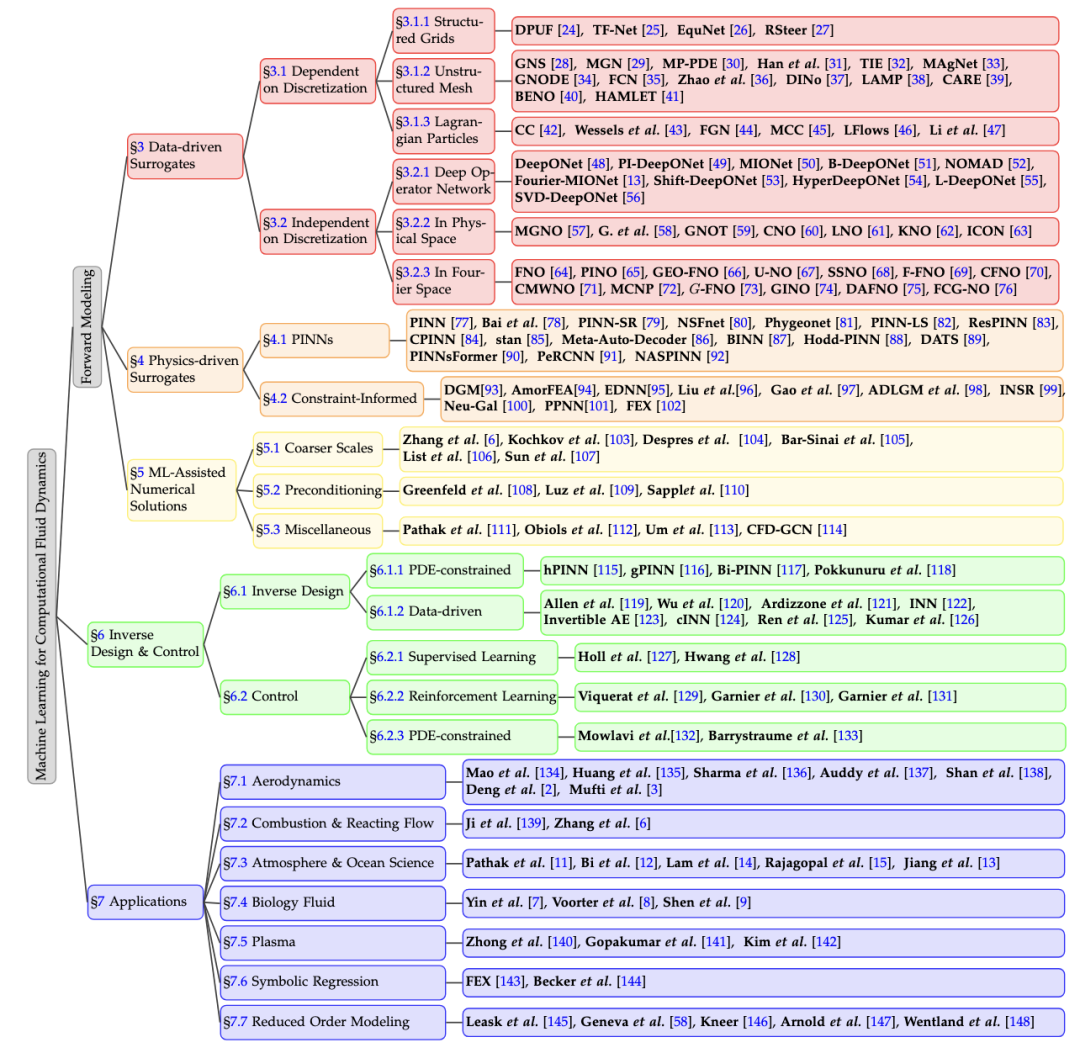
图1. 基于机器学习技术的计算流体动力学方法分类。我们首先研究前向建模方法,包括数据驱动的替代模型、物理信息驱动的替代模型和机器学习辅助方法。此外,我们对逆向问题进行了深入分析。我们还回顾了这些方法在各个领域的实际应用。
尽管经过数十年的研究和工程实践进展,计算流体动力学(Computational Fluid Dynamics,CFD)技术仍面临诸多挑战如计算成本高昂、难以捕获湍流等亚尺度特征,以及数值算法的稳定性问题等。另一方面,机器学习(ML)以其从观测数据中学习模式和动力学的能力而著称,最近已具有可以重塑或增强任何一般科学领域的趋势。将ML技术与大量流体动力学数据结合,为促进CFD领域的发展提供了一种全新的变革性的方法。现有的ML方法在CFD领域应用的综述文章大多存在两个限制:一是只涉及早期的文章,二是缺乏系统性概述。本篇文献是第一篇系统地回顾了基础知识、数据、近期的方法论、应用、挑战和未来方向,并将其整合成一个连贯框架的综述。
本文首先介绍了计算流体动力学的基本概念和背景知识,然后系统回顾了近五年的文献,对前向建模这一预测流体在给定条件下的行为和特性的重要方法分为三个类别,分别是:数据驱动的替代模型(依赖观测数据训练)、物理信息驱动的替代模型(将选定的物理先验融入机器学习建模)和机器学习辅助的数值解决方案(部分替代传统数值求解器,以平衡效率、精度和泛化能力)。此外,本文还介绍了逆向设计和控制问题的设置,这是将CFD应用于实际应用时的两个基本问题。前者优化设计参数,如初始和边界条件,以实现特定设计目标;后者通过施加时变外力控制物理系统以实现特定目标。更重要的是,本文讨论了在关键科学和工程学科中的应用,并讨论了当前最先进技术中的关键挑战、限制以及未来的研究方向。
与现有综述相比本文具有四个特点:1. 聚焦于2020至2024年间最新的论文;2. 首次为CFD领域的前向建模和逆向问题设计的方法引入了系统的全新的分类方法。3. 总结了CFD领域的最新进展,4. 为未来的研究提供指导,有助于物理和机械研究人员及机器学习研究者应用这些知识于实际科学问题。
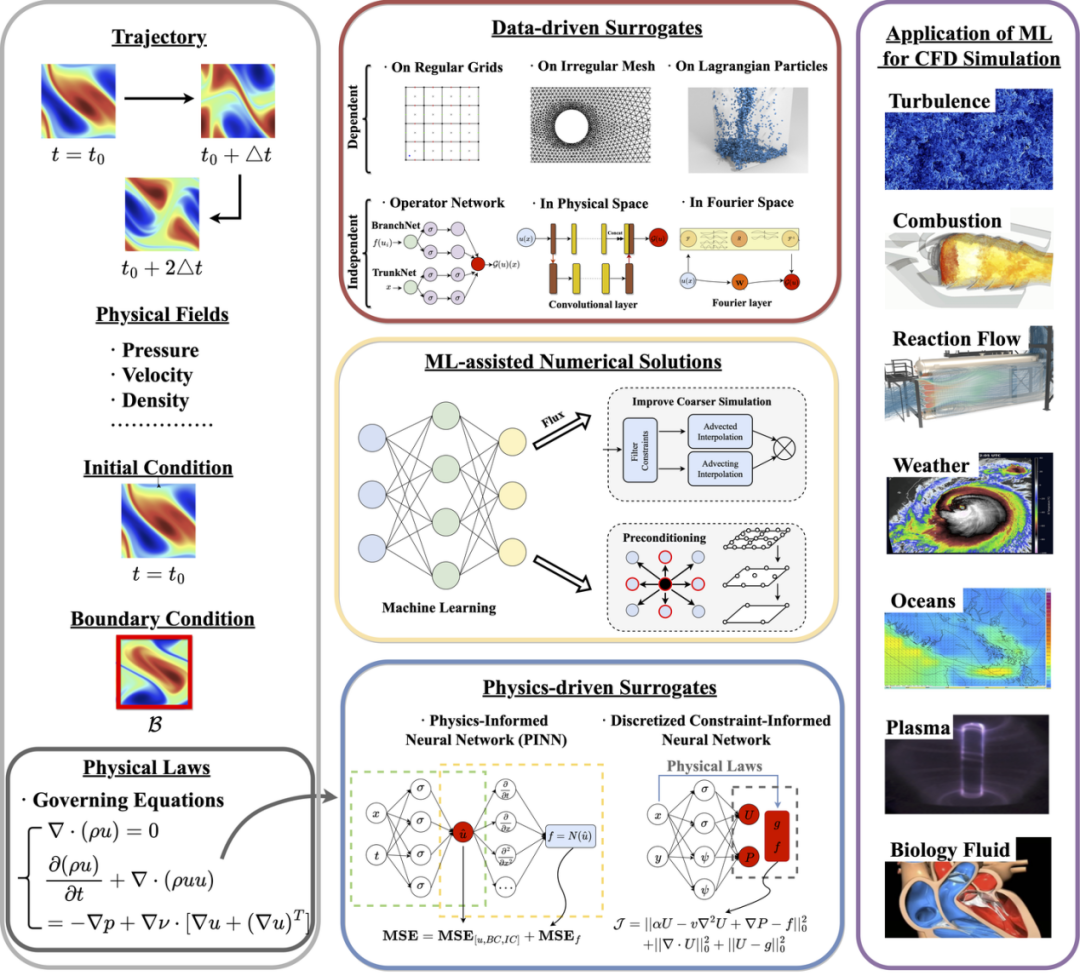
图2. 机器学习用于计算流体动力学仿真的概述。左栏包括模型中使用的各种类型的输入数据,包括物理定律。中间栏包含了用机器学习构建前向模型的三种系统性分类。右栏涉及到各种情境中的应用。
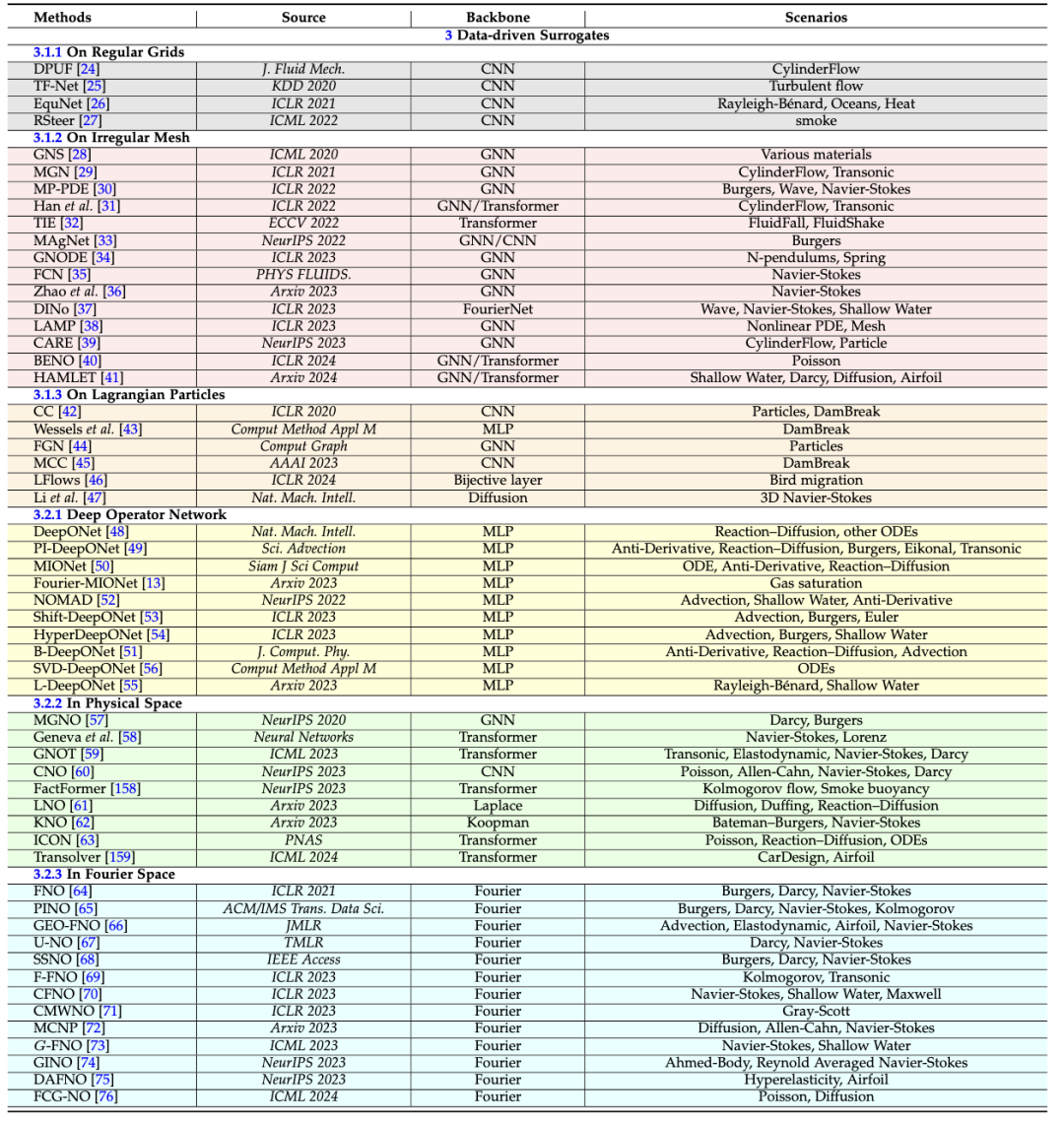
数据驱动的替代模型完全依靠观测数据来训练算法,这些算法能够模拟复杂的流体动力学,且发展迅速。这些模型具有重大影响力,并可以根据其空间离散化的方法进行广泛分类,分为:1)依赖离散化,2)独立于离散化。前者需要将数据域划分为特定的网格、网状或粒子结构,并设计模型架构,而后者不依赖离散化技术,而是直接在连续空间中学习解决方案。其中依赖于离散化的方案可以根据离散化的类型将这些方法分为三类:1)在规则网格上,2)在不规则网格上,3)在拉格朗日粒子上。独立于离散化方法主要是基于神经算子的思想进行函数空间的映射,本文根据实现积分函数近似的不同将现有方法分为:1)深度算子网络,2)物理空间中的方法,3)傅里叶空间中的方法。
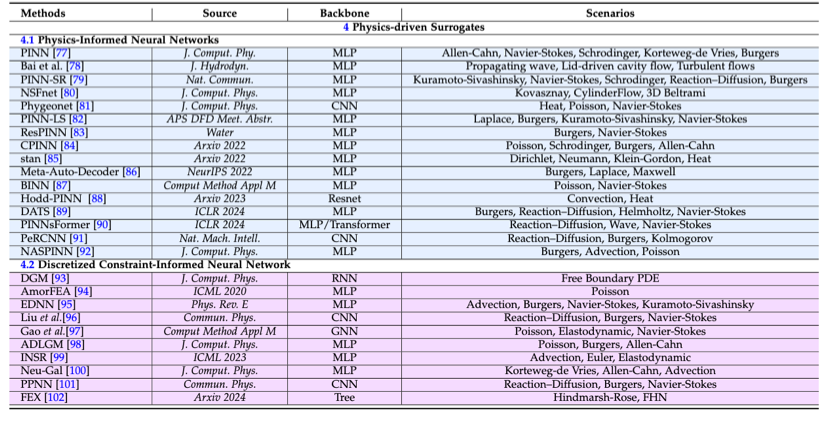
尽管数据驱动模型在计算流体动力学仿真中显示出潜力,但它们也面临挑战,如数据收集的显著成本以及对其泛化能力和鲁棒性的担忧。因此,融入基于物理的先验知识至关重要,可以利用物理定律的力量来增强模型的可靠性和适用性。本文根据嵌入的知识类型将它们分类为:1)物理信息化,2)约束信息化。前者将物理知识转化为神经网络的约束,确保预测遵循已知的物理原则;后者从传统的偏微分方程求解器中汲取灵感,将这些方法整合到神经网络的训练过程中。
尽管在端到端的替代模型建模方面取得了一定的进展,但它们尚未达到现有数值求解器的精确度要求,特别是在长期推演中会出现误差累积显著的现象,以及在训练期间未见工况下泛化性能差。因此,研究人员正在探索机器学习与数值求解器的结合,只替换数值求解器的部分部件以平衡速度、精度和泛化能力。
我们将这些方法分为三个主要类别:1)在更粗糙的分辨率或较少的自由度下实现精确模拟,包括学习离散化方案、通量、封闭建模和简化建模;2)使用学习到的预处理器加速线性系统的解决方案;3)范围广泛的杂项技术,从超分辨率到纠正迭代步骤。
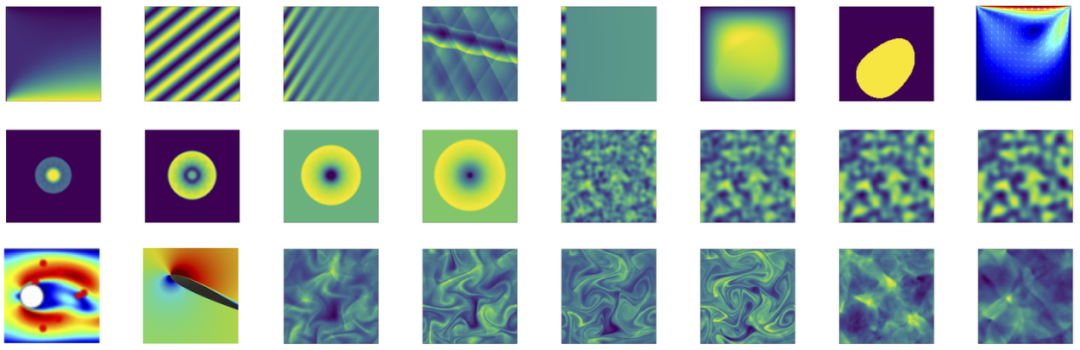
图5. 用于机器学习探索的计算流体力学常用数据集可视化
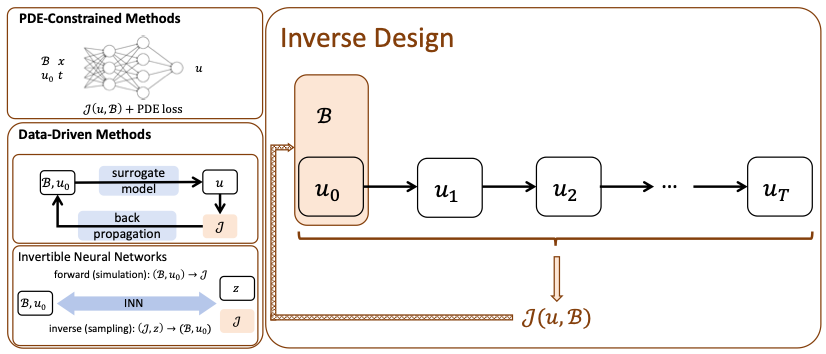
逆向设计问题旨在为物理系统找到一组高维设计参数(例如,边界和初始条件),以优化一组指定的目标和约束。逆向设计问题面临以下挑战:1)它需要对偏微分方程系统进行精确和高效的仿真;2)设计空间通常是高维的,带有复杂的约束;3)在数据驱动的逆向设计任务中,比观测样本更复杂的场景中的泛化能力。随着机器学习在偏微分方程仿真中的迅速进展,近年来机器学习在逆向设计中也日益受到关注。现有工作通常可以分为基于偏微分方程约束的方法和数据驱动的方法。
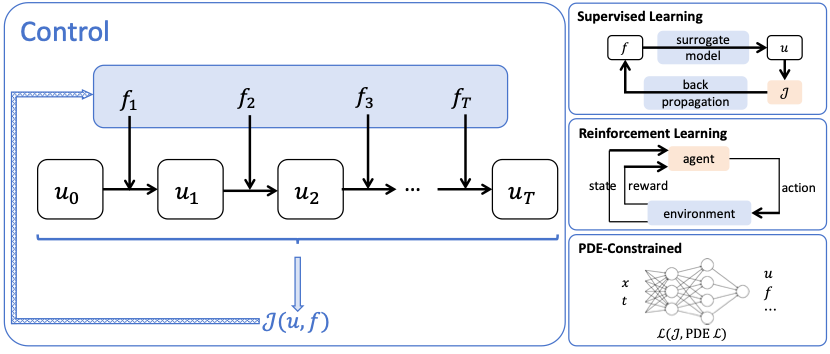
偏微分方程系统的控制问题也是基本问题并具有广泛的应用。控制问题的主要目标是通过施加时变外力来控制一个物理系统以实现特定目标。外力项的时变性增加了这个问题的复杂性,使其比逆向设计更具挑战性。在过去几十年中,用于解决偏微分方程控制问题的广泛使用的传统方法存在一定的缺点,包括高计算成本和有限的适用性。因此,机器学习技术已成为解决这些问题的流行方法。在流体动力学领域,各种特定问题,如减阻、共轭热传递和游泳等,已经通过机器学习技术得到解决。现有工作通常可以分为基于监督学习的方法,基于强化学习的方法和基于偏微分方程约束的方法。
1. 多尺度动力学特征
多尺度建模的挑战在于准确捕捉从微观分子运动到宏观流动行为的不同尺度之间的相互作用,这一过程受限于有限的高保真数据和计算资源。幸运的是,机器学习在弥合由有限的高保真数据可用性造成的差距方面起到了关键作用。这一挑战还因多尺度系统的内在复杂性而加剧,不同尺度的现象可能以非线性且常常不可预测的方式相互影响。例如,微观分子动力学可以显著影响流体流动中的宏观属性,如粘度和湍流。
未来方向:开发无缝结合数据驱动方法和传统物理基础模拟的混合模型,提升其在不同尺度和情景下的泛化能力。迁移学习技术的持续改进也将发挥关键作用,使模型能够利用相关问题和数据集的知识,以提高在有限高保真数据下的性能。此外,探索新型架构将进一步提升捕捉跨尺度复杂相互作用的能力。这些架构可以通过更复杂的汇聚和聚合策略以及改进的可解释性得到增强,确保学习模型遵循已知的物理定律。另外,计算硬件的进步,如使用专用处理器和分布式计算框架,将使执行更复杂和大规模的模拟成为可能。
2. 物理知识编码
另一个主要挑战是有效地将控制流体动力学的基本物理定律从多种来源明确地整合到一个连贯的高维非线性框架中。明确整合物理知识与物理信息神经网络不同,前者直接将物理定律和约束整合到模型中,而物理信息神经网络则将这些定律嵌入到神经网络的损失函数中以指导学习过程。
未来方向:未来有意义的研究方向包括开发更多新颖的隐式网络架构。这些架构应该被设计为无缝嵌入物理知识。此外,结合流形学习和图关系学习技术的机器学习可以帮助提取潜在的物理关系和定律。这种方法旨在增强机器学习模型理解和整合复杂物理系统的能力,从而导致更准确的预测。
3. 多物理学习 & 科学基础模型
科学机器学习的一个主要目标是开发能够泛化并超越训练数据的方法。替代模型通常只在其训练的工作条件或几何形状下表现良好。具体来说,物理信息神经网络通常只解决单一实例的偏微分方程,而神经算子只能泛化到特定的参数化偏微分方程族。同样,如封闭建模等机器学习辅助方法,其性能往往受到训练时工作条件或墙面形状的限制。
未来方向:一个有前景的未来方向是设计网络以同时处理不同的复杂几何形状。这需要一个能够处理异质数据的网络,以及大量高质量(真实和合成)的训练数据。此外,虽然预训练的大型语言模型不直接适用于科学计算任务,但整合它们庞大的预训练知识库将是有益的,尤其是在数据稀缺的情况下。此外,配备可扩展训练策略的小型语言模型可以提供一种有效且高效的方法。
现有的所有应用的成功,极大地依赖于训练数据集的规模和覆盖范围。这在多物理模型中尤其如此,这一点通过大型语言模型中出现的效应得到了证明。与在线上容易获得的文本或视觉数据不同,CFD数据像许多科学领域一样,因复杂的系统参数组合而具有大量样本且涵盖多种不同模型,并通常需要高昂的成本才能获得。这种组合为生成足够大且多样化的数据集带来了重大挑战。在前面的章节中,我们提到了整合对称性和物理知识以减少对训练数据集大小的依赖。然而,自动且高效地指导机器学习模型生成数据仍然面临挑战。
未来方向:自动化实验已成为自动数据生成和科学发现的未来希望。通过利用训练好的替代模型(验证器),自动化实验训练另一个机器学习模型来提出实验(提议者),这些实验可以由验证器高效筛选,只保留成功率高的实验。真实实验或高保真模拟仅在筛选过的实验上进行。所获得的结果逐步丰富数据集并重新训练机器学习模型,以突出显示成功率更高的实验方向。这一流程倾向于自动化和扩大传统实验的规模,并已在材料科学、超材料、蛋白质结构、机器人技术等领域得到应用。在CFD及相关领域,类似的工作也具有很大的潜力。
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会已完结,现在报名可加入社群并解锁回放视频权限。

6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会