长序列预测 & 时空预测万字长文:一文带你探索多元时间序列预测的研究进展!

导语
邵泽志、王飞等 | 作者
通讯作者:Fei Wang(王飞)、Yongjun Xu(徐勇军)、Xueqi Cheng(程学旗) 作者列表:Zezhi Shao(邵泽志), Fei Wang(王飞), Yongjun Xu(徐勇军), Wei Wei(魏巍), Chengqing Yu(余澄庆), Zhao Zhang(张钊), Di Yao(姚迪), Tao Sun(孙涛), Guangyin Jin(金广垠), Xin Cao(曹欣), Gao Cong(丛高), Christian S.Jensen, Xueqi Cheng(程学旗)
Overview:
最近几年多元时间序列预测非常之火,尤其是 长序列预测 和 时空预测 。
长序列预测从AAAI’21的Informer开始,到后来的Autoformer、FEDformer、DLinear、TimesNet、iTransformer等等等等,火的一塌糊涂。时空预测也是经久不衰,从DCRNN、GWNet,到后来的AGCRN、STEP、D2STGNN,以及最近的BigST、RPMixer,不乏高引论文和最佳论文提名。
然而,随着研究的百花齐放,问题也接踵而至。不同于CV或NLP领域已经形成的统一Backbone和普遍共识, 时间序列预测研究似乎存在较大的分歧 。一方面,不同论文常常得出相反的结论;另一方面,尽管SOTA模型层出不穷,但实际预测效果的提升似乎并不显著。在知乎上,你也可以看到不少相关的质疑与讨论。
为了搞清楚领域目前发展到什么地步了、核心瓶颈是什么、下一步应该做什么,我们做了一些评估。
本文介绍我们最新发表于 TKDE 上的 评测 & 综述 文章: 《Exploring Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis》。本论文系统梳理了多元时间序列预测的 发展脉络,讨论了目前领域内的 争议,通过公平且全面的 评测,剖析了多元时间序列预测取得的 进展。同时,文章也深入探讨了该领域面临的 挑战、核心 瓶颈,以及未来可能的研究 方向。
全篇没什么理论,都是直观的insights和详尽的实验结果,大家可以放心拿去用,也可以自行复现。本文实验基于开源项目 BasicTS 实验。BasicTS旨在提供 公平 、统一、可扩展的时序预测模型的开发和评测。已支持50+ Baseline,囊括经典方法、时空预测方法、长序列预测方法。BasicTS支持 20+ Benchmark,并且支持灵活地 自定义 数据集、损失函数、模型结构等部件。
代码见(如果有用的话,请点个Star吧!):
BasicTS: A Fair and Scalable Time Series Forecasting Benchmark and Toolkit.
代码链接:https://github.com/GestaltCogTeam/BasicTS
论文链接:https://arxiv.org/abs/2310.06119
1. 多元时间序列预测背景
1. 多元时间序列预测背景
多元时间序列包含着一组时间序列,可以被看成一个 的矩阵。时间维度上,每条时间序列可能都有周期性、趋势性等特点;空间维度上,时间序列之间可能存在相互关联。多元时间序列预测,就是基于历史数据 ,预测未来数据 。和 分别是历史数据和未来数据的长度。
下图是一个直观地例子,其中 , 。
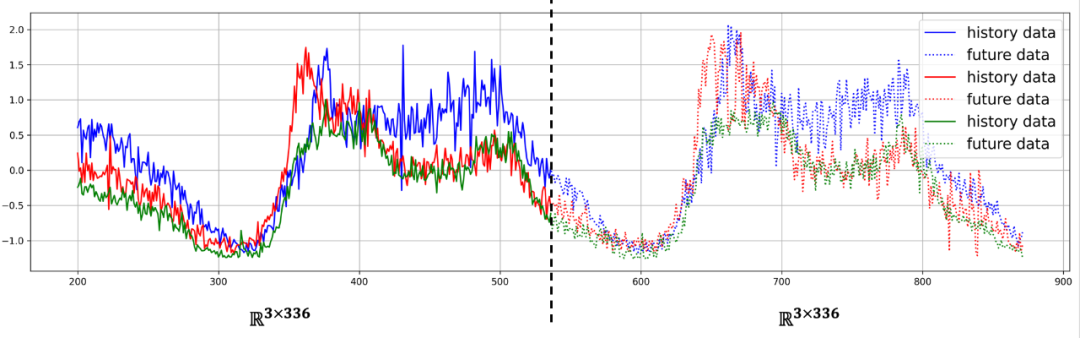
多元时间序列预测
2. 最火的两类任务
——时空预测和长序列预测
2. 最火的两类任务
——时空预测和长序列预测
在多元时间序列预测中,有两个非常热门的任务:长序列预测和时空预测。这两个任务近年来的研究成果颇具突破性。下面,我们来详细探讨这两大任务的发展现状和趋势。
2.1 长序列预测:建模历史,预测未来
目标:长序列预测的核心是通过对长期历史数据的模式进行建模,进而进行长期预测。它主要聚焦于时间维度模式的建模,试图找到时间序列中长期依赖的规律。
-
早期的统计与机器学习方法:最早的长序列预测工作采用了经典的统计方法(如ARIMA、ETS),以及一些机器学习模型(如GBRT、SVR)。但随着数据复杂性的增加,这些方法显得有些过时,逐渐被新的深度学习模型所取代。 -
Transformer时代的到来:2021年,AAAI最佳论文之一的Informer模型横空出世,开启了基于Transformer的时间序列预测时代。这一模型以其优雅的架构和优异的表现引发了学术界的广泛关注,催生了诸如Autoformer、FEDformer、Pyraformer等一系列新模型。这些模型探索了序列注意力、频域增强、金字塔注意力等机制,试图更好地建模时间序列中的长短期依赖。 -
线性模型的逆袭:2023年,一篇名为《Are Transformers Effective for Time Series Forecasting?》的论文引发了轰动。它展示了一个简单的线性模型(没有激活函数!),轻松击败了复杂的Transformer架构。这一结果不仅令人瞠目结舌,也引发了对Transformer在时间序列预测中有效性的深刻反思。 -
Transformer的反击:面对线性模型的挑战,以Transformer为代表的复杂网络阵营也没有坐以待毙。PatchTST、iTransformer、TimesNet等模型迅速被提出,它们通过改进架构或结合其他创新方法,再次展示了Transformer的潜力。(TimesNet尽管不是Transformer,但也是复杂模型创新的代表之一)。
2.2 时空预测:空间与时间的双重挑战
目标:与长序列预测不同,时空预测不仅需要处理时间动态,还要解决序列之间的空间依赖关系。一个典型的应用场景就是交通预测:分析未来交通状况不仅依赖时间维度的数据,还需要捕捉不同传感器之间的空间依赖。
主要研究进展:
-
早期的深度学习方法:早期的时空预测通常使用卷积神经网络(CNN)处理空间信息,并与循环神经网络(RNN)结合,来处理时间维度。这种结合为捕捉时空模式奠定了基础。 -
时空图神经网络的崛起:随着图神经网络(GCN)的发展,时空图神经网络(STGNN)迅速成为主流。STGNN通过预定义的图结构,结合GCN和序列模型来捕捉空间和时间依赖。例如,DCRNN、Graph WaveNet等模型成功将GCN与RNN或门控TCN结合,提升了时空数据的处理效率。 -
自学习图结构:然而,依赖预定义的图结构存在固有问题,图结构可能有偏差或者难以获取。因此,许多研究开始探索如何共同学习图结构并优化STGNN的性能,典型代表如AGCRN、MTGNN、STEP等。 -
非图模型的崛起:尽管STGNN在时空预测中表现优异,但其计算复杂度较高。因此,出现了一些舍弃图结构的创新模型。例如,STNorm通过时空正则化来简化模型,STID则引入了一种简单有效的时空身份附加方法。这些模型在降低计算复杂度的同时,也展现了强大的预测能力。 -
高效STGNN的出现:尽管非图结构模型显示出优越的效率,最近一些高效的STGNN模型也开始崭露头角,例如BigST,声称实现了线性复杂度。这一进展意味着,时空图神经网络有望继续在时空预测领域占据重要地位。
3. 你是否被这些问题困惑过
——领域内存在的争议
3. 你是否被这些问题困惑过
——领域内存在的争议
显然,时序预测领域的发展是“螺旋向上”的。我们对领域内存在的争议做了一些简要的总结,包括技术路线争议以及评估结果争议,来看看你是否也有其中的某些疑问吧!
3.1 技术路线争议:时间维度,Transformer和Linear模型哪种更好?
以Transformer为代表的复杂网络可扩展性强,仍是目前新论文发力的主要方向;然而,以Linear模型为代表的简单网络参数量小、性能也不比最新的Transformer差多少。考虑到两者之间体量的差距,到底哪种模型结构才是最好的解决方案?现有的长序列预测算法的提升看起来好像是比较小,每年都是很多SOTA论文,但精度似乎没有太大的提升?
3.2 技术路线争议:空间维度,如何理解空间依赖,GCN是必须的吗?
在大多数的研究论文中,GCN通常被描绘成了一种能够捕捉时间序列之间”依赖“关系的网络。然而,这种”依赖“是什么,如何理解它,它是否真的就是因果级别的依赖?实现大规模时空预测用非图网络好,还是图网络好?应该什么时候使用GCN,为什么有的时候它好像会起到一些反作用?
除了上述技术路线的争议,我们也发现了一些评测方面存在的争议:不一致的性能表现和具有迷惑性的评价指标。
3.3 评测结果争议:不一致的性能表现
不一致的性能表现是指,同一个模型、同一个数据集,同样的实验设置,在不同论文中的性能差距巨大。以时空预测中的DCRNN和GWNet这两个分别来自于2018和2019年的“老”baseline为例,我们统计了他们在不同论文中的结果,以及我们自己复现的结果。可以看到性能差距十分显著,几乎是SOTA和不Work的区别!
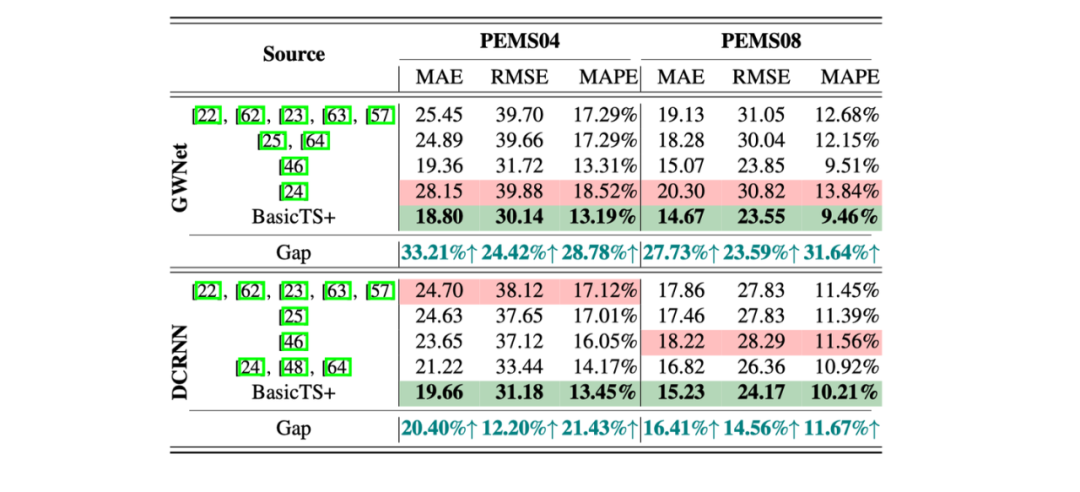
同一个模型、同一个数据集、同样的实验设置,在不同论文中的性能差距是巨大的
3.4 评测结果争议:具有迷惑性的评价指标
具有迷惑性的评价指标是指采用不够全面的评价指标,导致误差看起来非常小。这对于一些新手朋友或者想要单纯用一下时间序列预测算法的人来说,具有一定的迷惑性。以长序列预测为例,相关工作通常在归一化之后的数据上计算MAE、MSE,其误差非常之小,通常只有零点几!然而,当我们把预测结果反归一化回原来的尺度上,并计算MAPE、WAPE等更直观的相对指标的时候,我们发现他们能达到百分之几十!——这几乎是不可用的状态。
更合理的选择是,在报告上述指标的同时,计算MAPE、WAPE等相对误差指标,甚至同时计算反归一化之后的MAE和MSE,可以让读者直观地从数值中理解预测结果的好坏。
需要注意的是,”在归一化之后的数据集上计算MAE、MSE“这个做法本身是正确的:它可以消除由于不同变量单位不同、取值范围不同带来的影响。然而,仅用这一种方式可能是不合理的,这可能会造成误解。更合理的选择是,在报告上述指标的同时,计算MAPE、WAPE等相对误差指标,甚至同时计算反归一化之后的MAE和MSE,可以让读者直观地从数值中理解到预测结果的好坏。
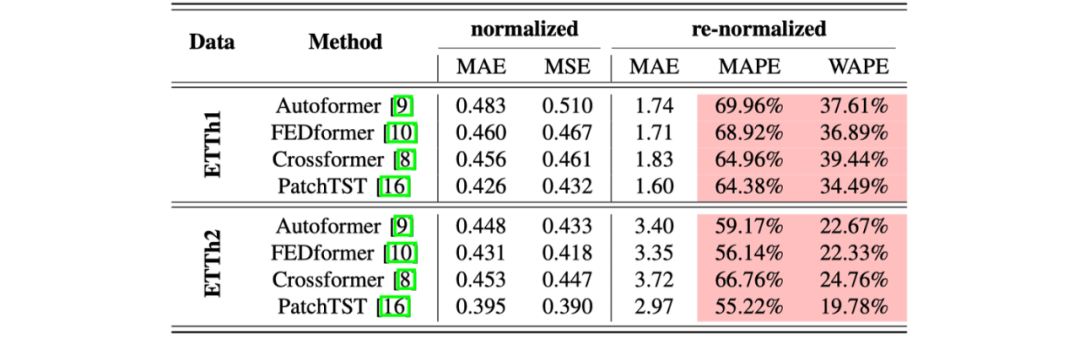
反归一化之后再计算相对误差,可以更直观地体现模型的准确程度
考虑到上述因素,我们不由得有下面的疑问:我们到底在时间序列预测方面走到了哪里了,取得了多少进步?实际落地过程中的核心瓶颈是什么?如果我是工业界的人,我应该如何选择合适的模型结构?如何做出合理的分析?
在本文中,我们将会通过对现有工作的进行全面的基准评估,以及新颖的异质性分析,来解答上述疑问。
4. 全面的基准评估——公平、可扩展的
时序预测模型开发&评测库BasicTS
4. 全面的基准评估——公平、可扩展的
时序预测模型开发&评测库BasicTS
评估的基石是可信、可复现的实验结果。
为了解决不一致的性能表现,我们对现有代码库进行了全面分析,并确定了三个导致不一致性能表现的核心原因:数据处理、训练流程和评估方式。这些方面常常被忽略,但它们对评估结果有着重要影响。
-
数据处理:深度学习模型训练过程中的一个关键步骤是对原始时间序列数据进行归一化。常见的归一化方法包括Min-Max归一化和Z-Score归一化,每种方法对预测性能的影响不同。例如,一些研究使用了Min-Max归一化,而大多数研究通常采用Z-Score归一化。 -
训练流程:训练配置包括优化策略和各种训练技巧,而不同的设置对优化有着显著影响。这一方面隐藏着最多的错误。例如,许多研究使用了带掩码的MAE损失函数进行模型训练,这种方法排除了异常值,避免了异常值对正常值预测的不利影响。相反,一些研究却采用了简单的MAE作为优化函数,通常会导致较差的结果。此外,训练技巧的加入,如梯度剪裁和课程学习,也会显著影响性能。然而,这些配置却经常不会在论文中提及。 -
评估方式:虽然评估指标有明确的定义,但它们的实际实现方式在不同研究中可能有所不同,涉及处理异常值和小批量计算等方面。这种差异导致测试结果与实际性能之间存在显著偏差。
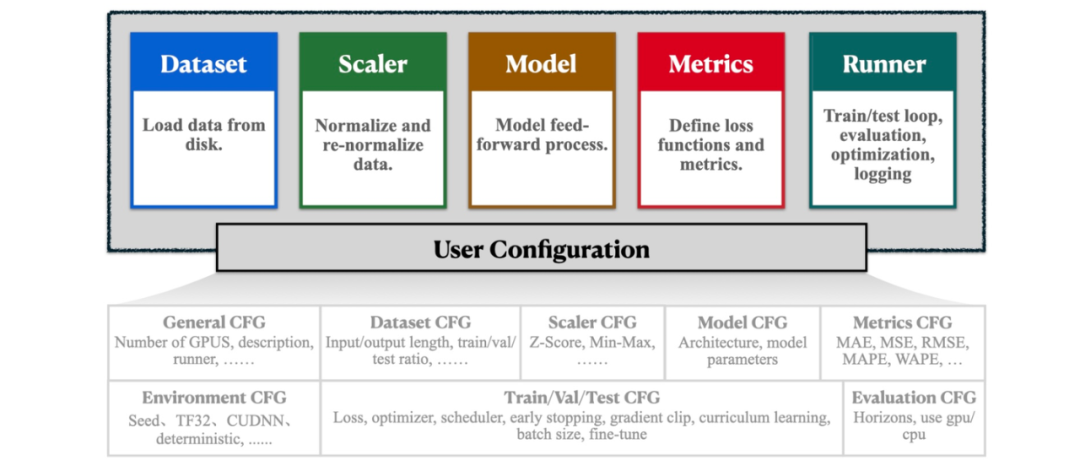
BasicTS的整体设计
为了实现可信的评测,我们提出了一个公平、可扩展的时序预测模型 开发&评测的库,BasicTS。
BasicTS+ 引入了统一的训练管道,主要包括统一的数据加载器、数据缩放器、评估指标、训练流程,从而避免由于非模型结构因素引起的性能差异。具体的实现方式见论文。BasicTS确保其所复现的论文的性能,不弱于原始论文中report的值(如果原始代码没有bug的话)。
此外,BasicTS还提供了许多扩展功能,例如自定义数据集、损失函数、评价指标、日志系统、分布式训练等等,并且兼容多种设备(例如CPU、英伟达GPU、寒武纪MLU,华为昇腾正在适配中)。BasicTS目前支持50多种Baseline、20多个Benchmark,包含了最新流行的大部分算法和数据集,可以一键复现并快速开发。你可以在这里找到BasicTS的上手教程:中文 | 英文 。
在评估指标方面,BasicTS选择在反归一化之后的数据上,计算相对误差(MAE、MAPE)和绝对误差(MAPE、WAPE)两种、四个指标。
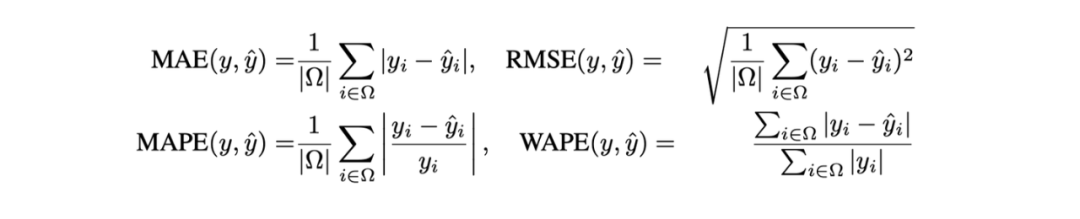
评估指标
BasicTS的建立解决了在评测结果上的争议,为后续的评测奠定了基础。
然而,技术路线上的争议仍然存在。他们因何产生,又如何解释?
5. 异质性分析——被忽略了的核心问题
5. 异质性分析——被忽略了的核心问题
技术路线的争议主要是在探讨模型结构是否有效。
每一篇研究都有非常坚实的证据来证明自己的论据,看起来大家都是对的(也可能都是错的)。但如果抛开模型不谈,有没有可能问题出在数据上,而不是模型?
下面我们聚焦于多变量时间序列(MTS)数据集的异质性,并深入探讨如何用它来解释看似矛盾的实验结果。
首先,MTS数据往往来自于其背后的一个时空系统,例如电力、能源、交通、金融等。由于这些系统特点的差异,采集出的MTS数据往往呈现出完全不同的模式,即异质性。
这和CV或者NLP完全不同,这两者通常共享某些常见的模式,例如ImageNet和CoCo数据集的视觉模式是相似的,不同文本数据集的模式也是相似的,并且这些数据集的模式通常是丰富且封闭的:数据的语义信息通常是固有的,不随未知的外部因素变化。
而时间序列完全相反。一方面,不同数据集(Domain)的数据模式可能完全不同,另一方面,时间序列收到外部未知因素的影响太大。
本文基于数据的时间和空间异质性对数据集进行了分类。我们主张,不同类型的模式意味着不同的核心瓶颈,也就对应着不同的解决方案。
这也意味着特定的技术方法仅适用于某些特定类型的数据。忽视这种数据异质性可能导致看似矛盾的实验结果,并且无法选择正确的技术方法。
5.1 时间维度:分布漂移或许才是核心的挑战
本文根据时间维度的异质性将数据集分为三类:具备稳定模式、显著分布漂移和模式不明确的数据集。我们选取了三个代表性数据集——PEMS03、ETTh2 和 ExchangeRate,进行分析并展示了它们的原始时间序列。此外,我们通过 t-SNE 算法对数据进行降维,并使用核密度估计展示了训练集与测试集的分布:
-
PEMS03(城市交通流量数据)具备清晰且稳定的周期性模式,符合城市交通的规律性; -
ETTh2(变压器传感器数据)虽然有周期性,但受外部因素影响,周期和均值发生漂移,呈现显著分布变化; -
ExchangeRate(货币汇率数据)几乎没有可辨识的模式,因其受复杂的经济政策和不可预测因素影响。
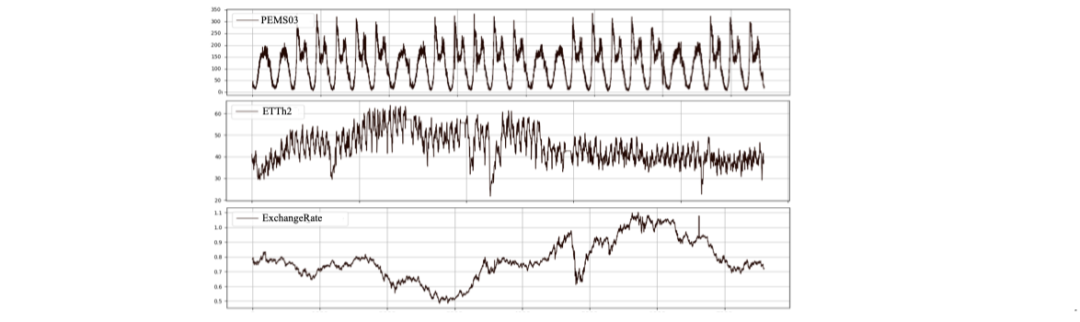
PEMS03、ETTh2、ExchangeRate三个数据集部分数据的可视化
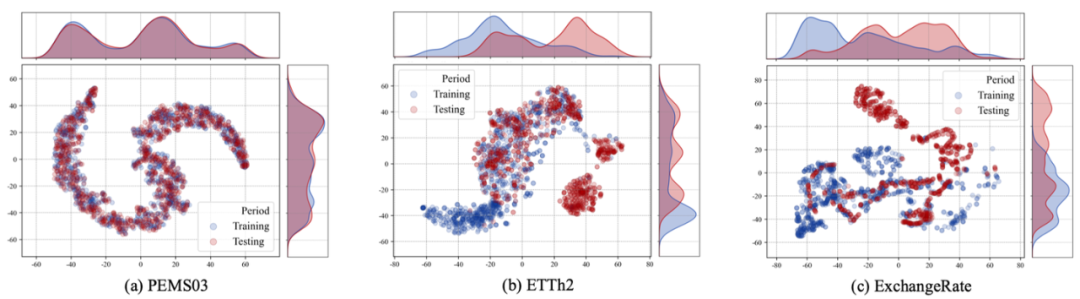
基于t-SNE和核密度估计的数据分布可视化
通过对这些数据集的分布分析,我们发现,PEMS03 的训练集和测试集分布相似,然而 ETTh2 和 ExchangeRate 的分布相对不一致。
这样的异质性可以解释为何常见的先进神经网络(如Transformer模型)与基础网络(如Linear模型)表现出矛盾的结果:Transformer模型虽然强大,但它们往往基于较强的Bias,在存在分布漂移或模式不明确的数据集上容易过拟合。而线性模型因其简单性,虽然欠拟合复杂模式,但在面对这些数据集时却能保持较好的鲁棒性。
因此,我们得出假设:
-
在稳定且周期性强的数据集上,复杂模型(如Transformer)能有效捕捉模式,即Transformer > Linear; -
而在模式不明确或分布漂移明显的数据集上,简单的模型反而可能表现更优,即Linear > Transformer
这提醒我们,选择模型时应考虑数据的本质特征,避免盲目追求复杂性。
5.2 空间维度:所谓的“依赖“或许是数据的不可区分性
相比时间维度,空间依赖关系更难以理解和量化。虽然许多研究通过图卷积网络(GCN)来建模时间序列之间的相互作用,但对空间模式的理解和量化仍然不足。幸运地是,最近的两项研究,ST-Norm 和 STID,提出了一个重要概念——空间不可区分性,揭示了空间依赖的核心问题。
基于这一思路,我们首次设计了量化指标,帮助区分不同类型的多元时间序列(MTS)数据集。我们将数据集分为两类:具有显著空间不可区分性 和 无显著空间不可区分性。
空间不可区分性意味着在某个时刻,历史数据相似但未来数据不同,普通的回归模型(如MLP或更复杂的Transformer)无法通过相似的历史数据准确预测出不同的未来——即不可区分。
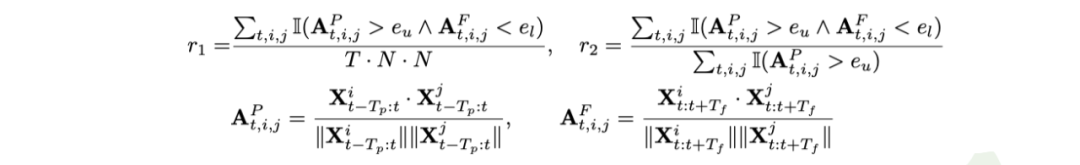
不可区分性的衡量指标
为了量化这一现象,我们提出了两个关键指标: 和 。其中, 衡量不可区分样本在所有样本中的比例,而 则精细衡量不可区分样本在历史相似数据中的比例。
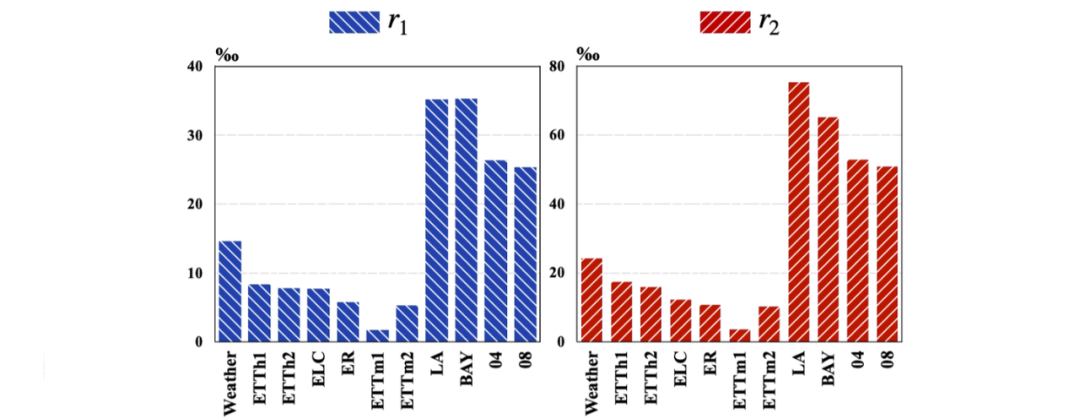
不同数据集中,样本不可区分性的比例
通过计算这两个指标,我们发现了一些有趣的现象:例如,ETT、Electricity、ExchangeRate 和 Weather 数据集的 和 值较低,说明它们的空间不可区分性较弱,空间依赖对预测性能影响不大;METR-LA、PEMS-BAY、PEMS04 和 PEMS08 数据集的 和 值显著更高,表明这些数据集的空间不可区分性较强,空间依赖对于预测至关重要。这些发现为我们提供了启示:
-
对于空间不可区分性弱的数据集,建模空间依赖可能并非必要,甚至可能影响模型性能(如无必要,勿增实体)。 -
对于空间不可区分性强的数据集,解决这一问题就能显著提升预测效果,无论是利用图卷积、正则化、还是时空身份附加。
即,空间依赖的建模效果与数据集的空间不可区分性密切相关,针对不同数据集,应选择合适的空间建模策略。
总结一下,通过异质性分析,我们提出了下面的两个假设:

基于数据异质性的两个假设
6. 如何根据数据特点选择合适的模型?
我们到底取得了多少进展?
6. 如何根据数据特点选择合适的模型?
我们到底取得了多少进展?
6.1 时间维度:分布漂移确实是核心的挑战
为了验证上述假设1,我们在两组、四个数据集上做了实验:
-
PEMS04、PEMS08:具备清晰、稳定的模式 -
ETTh2、ETTm2:具备显著的分布漂移
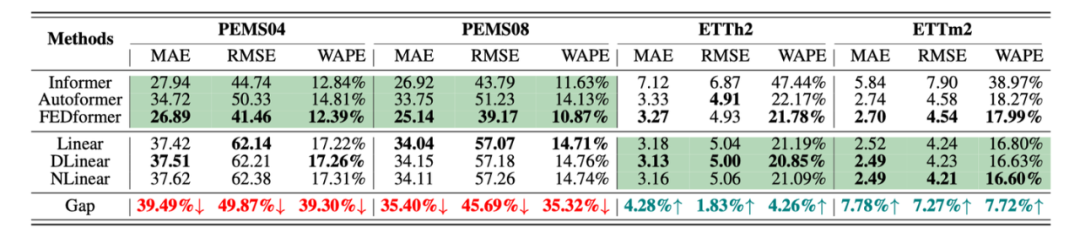
Transformer v.s. Linear on Heterogeneous MTS Datasets.
如上表所示,显然不同的模型在不同性质的数据集上模式的表现完全不同。
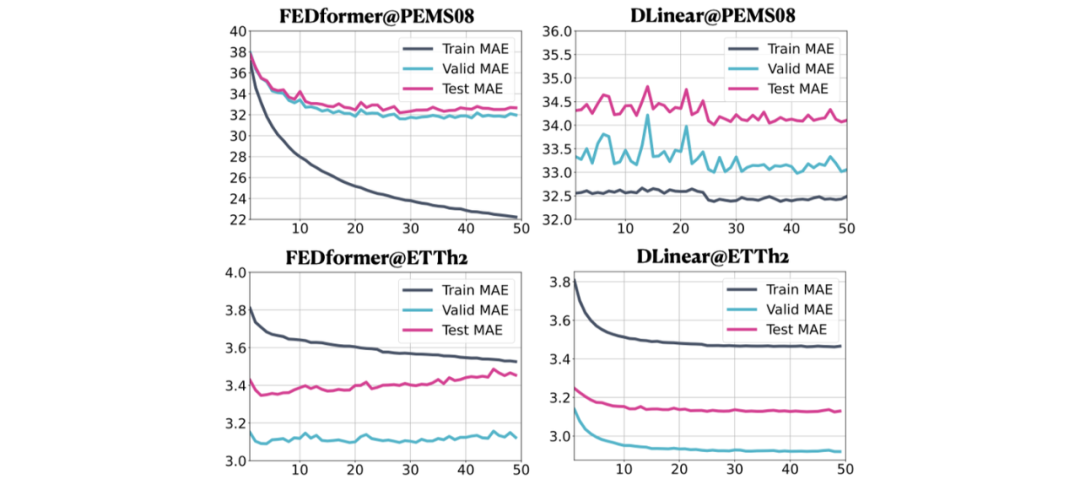
FEDformer、DLinear分别在PEMS08、ETTh2上的损失变化曲线
Tensorboard中损失指标的变化也应证了我们的结论:在PEMS08上,FEDformer表现正常,而DLinear出现了欠拟合问题;在ETTh2上,DLinear表现正常,而FEDformer则出现了严重的过拟合。
6.2 空间维度:样本的不可区分性是重要议题
同理,为了验证假设2,我们也在另外两组、四个数据集上做了实验:
-
LA、BAY:具备显著的空间样本不可区分性 -
ER、ETTm1:不具备显著的样本不可区分性
我们选择了STID、AGCRN两个用不同方式建模空间依赖的模型,并将其空间依赖建模模块删除,得到了STID* 和 ACGRN*。实验结果如下所示:
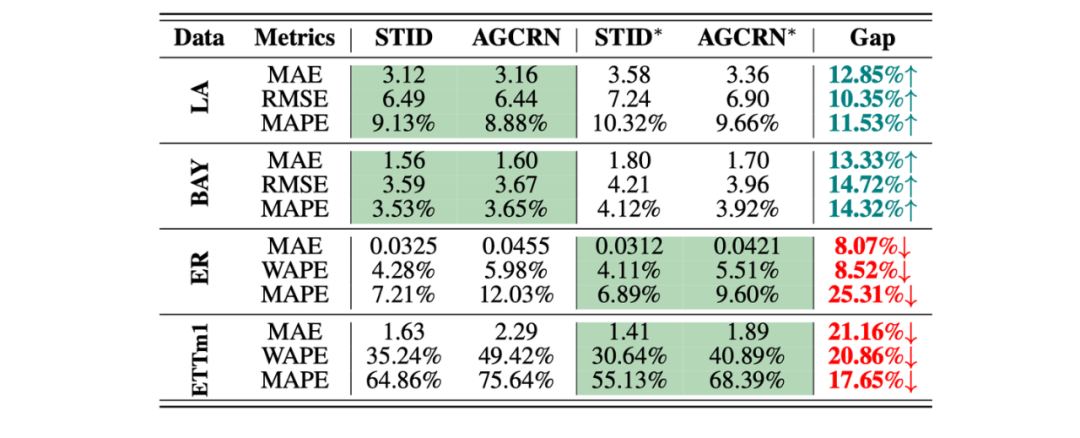
空间建模的有效性
显然,空间不可区分性就是所谓的“空间依赖”的本质之一。在具备该特点的数据集上,使用任意的“空间依赖”建模手段,都会提升性能。但在不具备该特点的数据集上,简单地使用上述模型会引起性能的下降。此时,需要更精细地挖掘变量之间的关联。
6.3 给定数据集,如何选择和设计一个MTS预测模型?
基于上述发现,我们就可以有在目前的技术框架下,选择和设计MTS预测模型的路线图。
-
给定一个MTS数据集,检查它在时间维度上是否具备清晰、稳定的模式 -
模型结构:采用一些“弱偏”模型,例如Linear、MLP、原生的Transformer -
动态分布漂移建模:在这种情况下,建模动态的数据分布是更重要的选择,例如采用迁移学习、持续学习等方式。 -
特征工程:获取更多的信息,比如文本、图像、事件数据,来辅助做出更好的预测。 -
不确定性估计:不强求准确预测,而是采用更实用的概率预测、区间预测 -
假如是:使用一些序列模型+空间依赖建模方法,例如STGNN、STNorm、STID等 -
假如否:使用序列模型即可,例如CNN、RNN、Transformer等 -
假如是:检查它在空间维度上是否具备显著地样本不可区分性。 -
假如否(很不幸,现实场景下大多会走到这个分支):
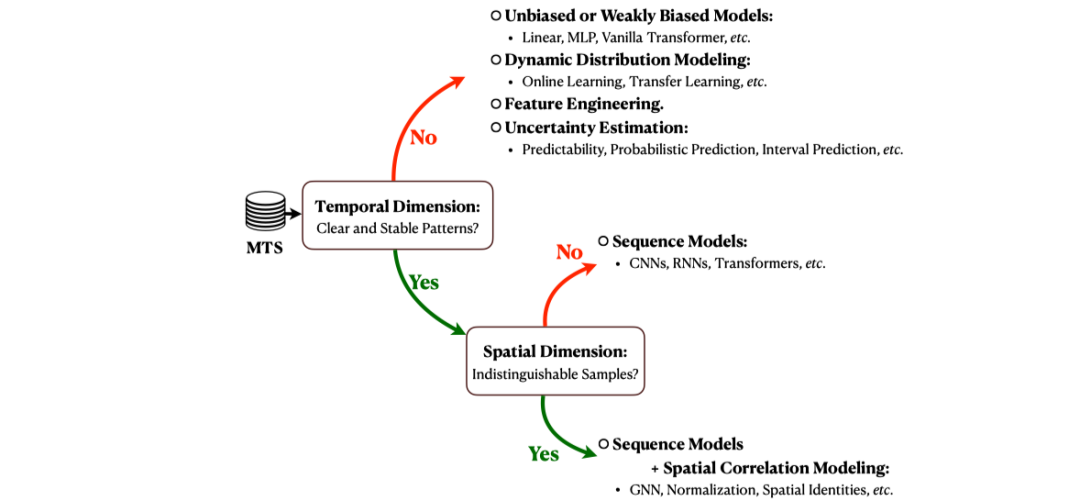
设计和选择MTS模型的路线图
另外,为了更好地理解我们目前去的了多少进展,我们集中做了一波评测。可以看到的是,无论是时空预测还是长序列预测,其实SOTA之间的差距并不是特别的明显。
时空预测的STID、长序列预测的LTSF,这两个模型其实性能已经不错了。他们很适合作为一个backbone,来检验其他工作是否有效——因为他们已经是最简单的模型了。一个复杂的模型应当显著地超越他们,或者有其他的闪光点,或许才能cover住复杂度带来的负面影响。
另外,不同数据集的特点显然是完全不同的,这些工作很难被放在一起比较。如果您是做时空预测(或者长序列预测)的,但审稿人非让您对比长序列预测(或者时空预测)的工作,现在您就可以用本文为依据进行回应了~
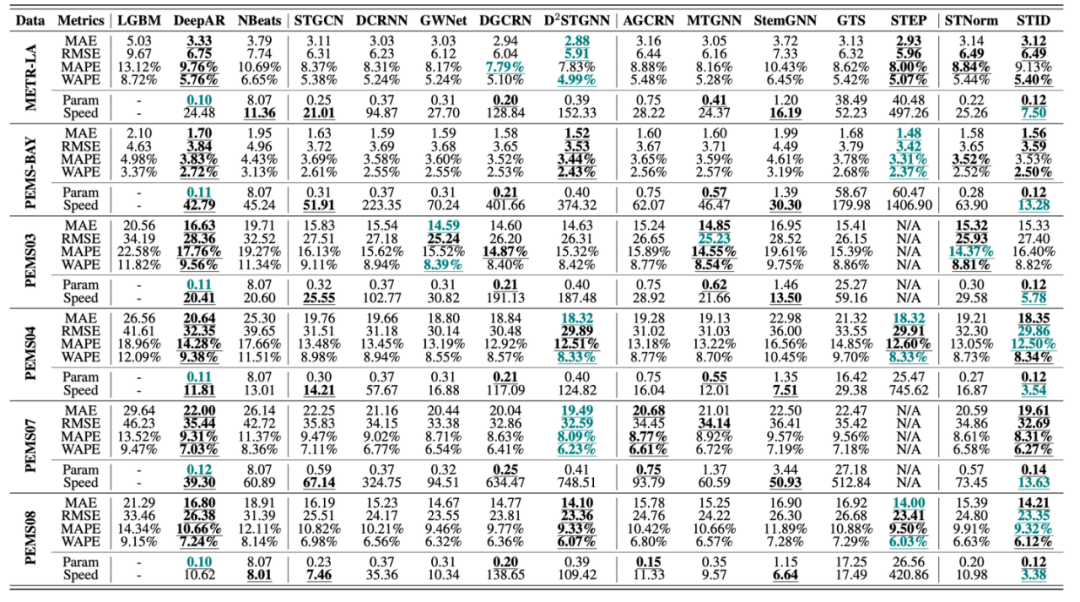
在METR-LA、PEMS-BAY、PEMS03、PEMS04、PEMS07、PEMS08上的时空预测结果
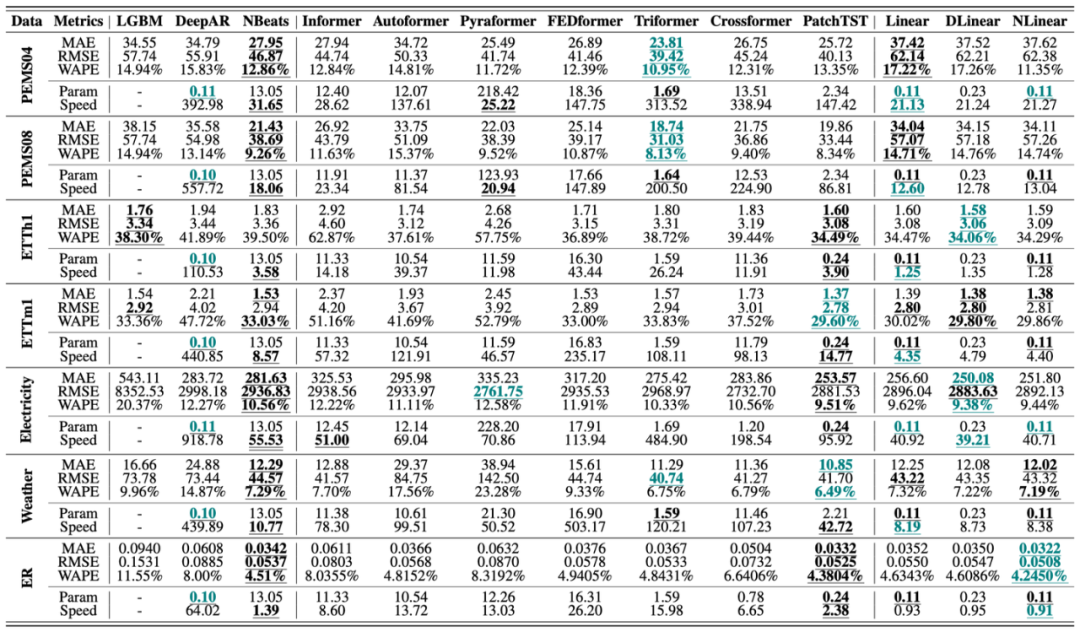
在PEMS04、PEMS08、ETTh1、ETTm1、Electricity、Weather、ER数据集上的长序列预测结果
7. 开放讨论:时间序列预测的困境
以及有价值的研究方向
7. 开放讨论:时间序列预测的困境
以及有价值的研究方向
7.1 时序预测的悖论和核心瓶颈:
显然,时间序列预测(无论是长序列还是时空预测)已经陷入了一定程度的“内卷”。其中很大原因在于时间序列数据本身的特性。笔者一直认为,时间序列预测存在一个悖论:那些可预测的时间序列往往具备稳定、清晰的模式,这种情况下,使用一些简单的方法即可实现良好的预测效果,并不需要复杂的模型。而对于那些不具备清晰、稳定模式的时间序列,即便设计出复杂的模型,效果也未必显著,反而容易因数据的分布漂移导致过拟合。
因此,真正具有挑战性、且值得深入研究的部分在于时间序列的分布漂移。分布漂移通常由外部因素引发,这意味着时间序列数据并不完全由历史数据决定,未来的变化往往依赖于许多未知的外部协变量。每个应用领域(Domain)中的外部因素各不相同,增加了预测的难度和不确定性。
7.2 有价值的研究方向
上述发现并不是对时序预测的悲观评价,恰恰相反,它们揭示了这个领域尚有许多值得探索的方向,且已有许多前沿研究正在快速发展(大佬们太卷了)。以下是笔者认为目前较有前景的几大趋势:
-
数据处理的趋势:由于模型复杂性并不是预测效果的核心瓶颈,普通的时序预测设置下,SOTA模型趋向于简化结构。相比复杂的网络,研究重点转向对数据的合理分解与变换,甚至采用一些简单、朴素的方法,找到数据中“不漂移”的部分,从而实现更稳健的预测性能。例如,SSCNN、FOIL.
SSCNN: [NeurIPS‘24] Parsimony or Capability? Decomposition Delivers Both in Long-term Time Series Forecasting
FOIL: [ICML’24]Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant Learning
-
模型发展的趋势:受自然语言处理(NLP)大模型的影响,时序大模型正成为一个热门方向。通过扩展数据规模和模型规模,时序大模型能够更深入地理解历史数据的波动,从而提供更准确的预测,甚至零样本预测。然而,与NLP大模型相比,时序大模型的训练成本和效率仍需提高,推理速度相对较慢。例如,Chronos、UniTS、MOIRAI等模型在这一领域表现出色。此外,多模态融合的尝试也令人瞩目,尤其是时间序列和NLP、CV的碰撞,如VisionTS与TimeLLM,展示了极具潜力的效果。
Chronos: Chronos: Learning the Language of Time Series
UNITS: [NeurIPS‘24] UNITS: A Unified Multi-Task Time Series Model
MOIRAI: [ICML’24]Unified Training of Universal Time Series Forecasting Transformers
VisionTS: VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
Time-LLM: [ICLR‘24]Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
-
策略创新的趋势:一些研究通过引入分布漂移检测机制,使模型能够在在线环境下自动适应漂移,从而提高模型的有效性。例如,Saleforce的Chenghao Liu老师开发的SOLID框架就是这类创新工作的代表之一。
SOLID: [KDD’24]Calibration of Time-Series Forecasting: Detecting and Adapting Context-Driven Distribution Shift
-
因果关系挖掘:虽然目前许多使用图神经网络(GNN)的研究试图捕捉变量之间的因果关系,但大多仍停留在解决数据层面的不可区分性问题上。实现真正的因果关系挖掘,是一个非常有吸引力且极具潜力的研究方向。
8. 总结
8. 总结
总的来说,在本研究中,我们针对多元时间序列(MTS)预测领域中实验结果不一致以及技术方向选择困难的问题进行了分析,揭示了实际取得的进展。
首先,我们引入了一个新的基准框架——BasicTS,该框架旨在实现MTS预测解决方案的公平和合理的比较。通过采用统一的训练流程,BasicTS解决了性能不一致的问题,并提供了更为合理的评估程序。
其次,我们深入探讨了MTS数据集的异质性。在时间维度上,我们根据数据集是否呈现出清晰稳定的模式、显著的分布漂移或不明确的模式进行分类;在空间维度上,我们设计了衡量空间依赖性的指标,将数据集划分为具有显著空间不可区分性和不具有显著空间不可区分性两类。
我们结论是,许多先前研究得出的结论仅适用于某些特定类型的数据,将这些结论泛化会导致研究人员得出适得其反的推论。
此外,借助BasicTS及其相关的MTS数据集,我们对当前流行的解决方案进行了广泛的分析与比较。这些研究成果为MTS预测领域的进展提供了宝贵的见解,帮助研究人员选择合适的解决方案或数据集,并得出更可靠的结论。
时序时空大模型读书会
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











