2024年诺贝尔物理学奖一经公布即引发了广泛讨论——物理学奖竟被授予机器学习领域。机器学习的发展与物理有何种关系,又会对物理学产生怎样的影响?近期发表于Artificial Intelligence Review 的综述论文 AI meets physics: a comprehensive survey深入探讨了物理学与人工智能发展的相互促进。
本文选取其中 Physics for AI 部分,详细介绍了物理学的四大领域——经典力学、电磁学、统计物理、量子力学——如何启发现代机器学习模型的构建。借此,我们将一窥物理学如何成为机器学习研究的引擎,以及这种跨学科合作如何为我们打开探索未知世界的大门。
朱欣怡 | 编译
孙敬书 | 编辑
华泽林、秦冉 | 审校
Liyuan Lab | 来源
论文来源:Artificial Intelligence Review
论文题目:AI meets physics: a comprehensive survey
论文作者:Licheng Jiao, Xue Song, Chao You, Xu Liu, Lingling Li, Puhua Chen, Xu Tang, Zhixi Feng, Fang Liu, Yuwei Guo, Shuyuan Yang, Yangyang Li, Xiangrong Zhang, Wenping Ma, Shuang Wang, Jing Bai & Biao Hou
论文地址:https://link.springer.com/article/10.1007/s10462-024-10874-4
一、引言
二、受经典力学启发的AI模型
三、受电磁学启发的AI模型
四、受统计物理学启发的AI模型
五、受量子力学启发的AI模型
六、总结
什么是物理学?物理学是原子、湍流、玻璃、洗衣机、自行车、留声机、磁铁吗?一一这些都是偶然的物理发现。物理学的核心思想是,世界是可以理解的,你能够把任何东西拆开,理解其组成部分之间的关系,通过做实验,在此基础上能够定量地理解系统行为。物理学是一种观点——我们生活的这个世界是可理解的。
正是这种对世界可理解性的信念,为人工智能(AI)与物理学的结合提供了坚实的基础。AI的目标是让机器能够执行学习、推理、决策等复杂任务,能够成为我们理解世界的工具(AI for Physics)。同时,物理学的原理,又能成为指导机器学习的宝贵思想(Physics for AI)。
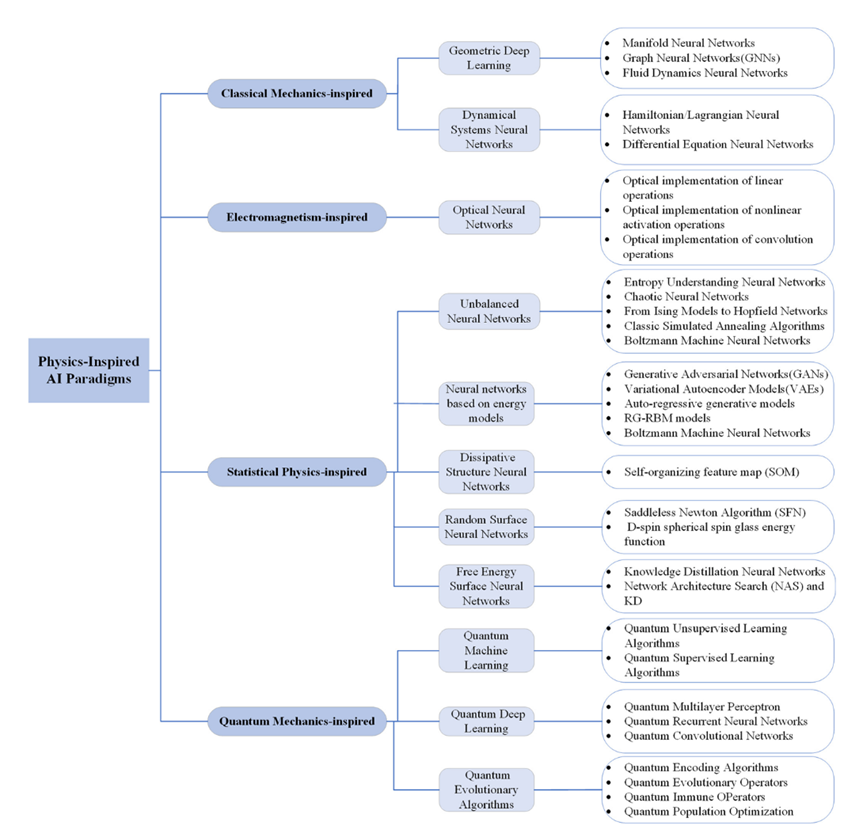
AI meets physics: a comprehensive survey 这篇综述整理了物理学中四大领域(经典力学、电磁学、统计物理、量子力学)的思想如何指导AI模型的构建。文章系统地综述了400多个物理科学思想和物理启发的深度学习AI算法,其框架梗概如图1所示。
经典力学是物理学的基石,它描述了物体在力的作用下的运动规律。在AI领域,经典力学的启发体现在对动态系统的建模上。论文中“Deep neural network paradigms inspired by classical mechanics”部分探讨了经典力学对深度神经网络设计的启发。
由于某些对称性,某个在开始时是正确的事物,在其他任何时候也是正确的。而这不就是守恒定律吗?
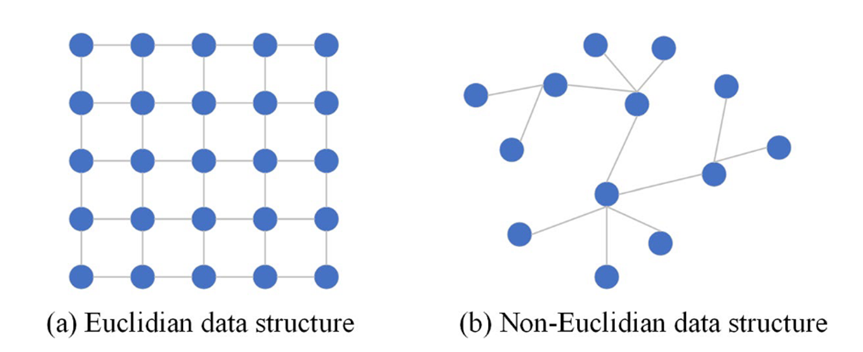
深度学习能够模拟物理世界的对称性(即守恒,表示物理定律在各种变换下的不变性)。卷积神经网络 (Convolutional Neural Networks,CNNs) 的平移不变性、局部性和组合性使其天然地适用于处理图像等欧氏结构数据的任务。然而,世界上仍然存在着复杂的非欧氏数据,几何深度学习 (Geometric Deep Learning,GDL) 应运而生。
本部分介绍了流形神经网络(Manifold Neural Networks,局部欧氏空间)、图神经网络(Graph Neural Networks,非欧氏数据)和流体动力学神经网络(Fluid Dynamics Neural Networks)。
流形是一种具有局部欧氏空间性质的空间,在数学上被用来描述几何形状,例如雷达扫描返回的各种物体表面的空间坐标。
图神经网络能够处理非欧氏数据,如社交网络等网络结构数据。文章具体讨论了图卷积神经网络(GCNs)及其在推荐系统中的应用,以及结合了自然语言处理中的注意力机制的图注意力网络(Graph Attention Networks)。
流体动力学神经网络部分介绍了如何将流体动力学的原理应用于神经网络,以解决流体力学问题。此外,还提到了隐流体力学网络框架(Hidden Fluid Mechanics Network Framework),它通过将流体力学的方程编码到神经网络中,来预测流体物理数据。
动力学分析和神经网络都能表示非线性函数。在神经网络中,各种非线性函数实际上是在各层之间传播的信息波。如果将真实世界中的物理系统用神经网络来表示,将大大提高将这些物理系统应用于人工智能领域进行分析的可能性。神经网络通常需要使用大量数据用来训练,通过最小化实际输出与期望输出值之间的差异,逼近真实值,可以把这一套“黑箱”的神经网络参数看作一个复杂的非线性函数。然而,这种训练方法存在“混沌盲”(Chaos Blindness)的缺点,即AI系统无法对系统中的混沌(或突变)做出响应。
瑞士数学家约翰·伯努利提出的最速下降曲线问题使得变分法成为数学物理中求解极值问题的重要工具。变分原理也称为最小作用量原理,对变分原理的研究导致了经典力学的拉格朗日和哈密顿公式的发展。
哈密顿神经网络和拉格朗日神经网络(Hamiltonian/Lagrangian Neural Networks)受到经典力学中哈密顿和拉格朗日表述的启发。哈密顿表述使用相空间和能量函数来描述系统的状态,而拉格朗日表述则侧重于系统的位置和速度。在深度学习中,有人尝试在哈密顿神经网络中嵌入物理法则,例如守恒定律,以提高模型的预测能力和泛化能力。哈密顿神经网络和拉格朗日神经网络可以用于建模和预测各种动力学系统的行为,包括机械系统、流体动力学系统、天体运动等。通过学习系统的动力学规律,这些网络能够预测系统在未来的状态。在控制理论中,哈密顿神经网络和拉格朗日神经网络可以用来设计和优化控制器,它们可以帮助确定如何通过控制输入来引导系统从一个状态转移到另一个状态,同时遵守物理法则。在优化问题中,哈密顿神经网络和拉格朗日神经网络可以帮助寻找系统的最优控制策略,以最小化能量消耗或最大化系统性能。
“Neural Network Differential Equation Solvers”部分探讨了如何将神经网络设计成能够求解微分方程的系统,这些系统能够模拟和预测物理世界中的动态行为。这种方法的核心在于将物理法则,如能量守恒和动量守恒,直接嵌入到神经网络的训练过程中,从而确保模型的预测不仅符合数据特征,还遵循物理定律。
常微分方程神经网络和偏微分方程神经网络是这一领域的两个主要方向。常微分方程神经网络专注于求解描述系统状态随时间变化的方程,而偏微分方程神经网络则处理涉及空间变化的方程。这些网络通过学习微分方程的解,能够模拟从流体动力学到结构力学,再到量子化学等一系列复杂的物理过程。
物理信息神经网络(Physics-Informed Neural Networks, PINNs)是这一领域的突出代表。物理信息神经网络通过将微分方程作为约束条件直接嵌入到神经网络的损失函数中,确保了网络预测的物理可行性。这种方法在处理逆问题、预测复杂系统行为以及在数据稀缺的情况下进行建模方面显示出了巨大的潜力。
总的来说,Neural Network Differential Equation Solvers 部分展示了深度学习在求解微分方程方面的潜力,强调了将物理法则整合到神经网络架构中的重要性,以及这种方法在解决实际物理问题中的应用前景。通过这种方式,AI模型能够更好地理解和预测物理世界中的复杂现象,为科学研究和工程设计提供了强大的工具。
这些深度神经网络范式通过模仿经典力学的原理,如能量守恒、动量守恒和对称性,来提高网络模型的泛化能力和可解释性。通过这种方式,物理学不仅为我们提供了理解自然界的框架,还为人工智能的发展提供了新的工具和方法。
电磁学是研究电磁场的产生、传播和相互作用的物理学分支。在人工智能领域,电磁学的原理被用来设计和优化深度神经网络模型,以处理与电磁现象相关的数据和问题。“Deep neural network paradigms inspired by electromagnetics”部分探讨了电磁学对深度神经网络设计的启发。
光学神经网络是利用光学技术,如光学连接技术、光学器件技术等,设计的新型神经网络。这些网络的设计理念是模仿神经网络通过光的特征,如振幅、强度、相位和偏振来携带信息,并利用光的干涉、衍射、传输和反射等原理来实现神经网络及其运算。最早的光学神经网络是光学Hopfield网络,由Demetri Psaltis和Farhat在1985年提出。文章中介绍了光学实现线性操作、非线性激活操作和卷积操作的方法,这些操作是传统神经网络中的关键组成部分。
电磁学的原理在神经网络中的应用不仅限于光学神经网络。例如,电磁场的计算和模拟可以通过深度学习方法来增强,从而提高计算效率和准确性。此外,电磁学中的波动方程和麦克斯韦方程组的解可以通过神经网络来近似,这在天线设计、微波工程和光学成像等领域具有潜在的应用价值。
深度学习模型,尤其是卷积神经网络(CNNs),在图像和信号处理方面表现出色。这些模型可以被训练来识别和处理电磁场中的模式,如电磁波的传播特性、天线的辐射模式等。通过学习这些复杂的电磁现象,深度学习模型能够提供对电磁场行为的深入理解,并在设计和优化电磁系统方面发挥作用。
总的来说,“Deep neural network paradigms inspired by electromagnetics” 部分展示了电磁学原理如何启发深度神经网络模型的设计和应用。通过将电磁学的概念和方法融入到深度学习中,我们可以开发出能够处理复杂电磁现象的强大工具,这些工具在通信、雷达、医疗成像和许多其他领域都有着广泛的应用前景。这些深度神经网络范式通过模仿电磁学的原理,如波动传播、干涉和衍射,来提高网络模型的泛化能力和可解释性。
统计物理的研究对象是由大量粒子(或大量自由度)构成的宏观系统,目的是研究这些系统与热现象有关的宏观性质。不过与热力学的研究方法不同的是,热力学是从若干经验定律出发,通过数学上的逻辑演绎方法,最终导出系统的宏观性质;而统计物理则是从单个粒子的力学运动规律出发,加上统计的假设,最终来获得系统的宏观性质。统计物理是微观与宏观的桥梁,它提供了研究物质世界宏观性质的一个强有力的理论工具。在机器学习中,统计物理的思想常被用来设计处理具有随机性的模型,统计物理学中的许多概念(比如熵、混沌)和一些经典物理模型(比如伊辛模型)常被借鉴到机器学习中。
统计物理通常包含平衡态统计物理与非平衡态统计物理:前者只涉及所有宏观性质与时间无关的行为,而后者则涉及系统的时间演化行为。有趣的是,系统如何从非平衡向平衡演化,为什么所有系统都达到统计意义上的相同平衡态而与它们各自的动力学无关,以及是否真的与动力学无关等问题,至今仍是有待进一步研究的问题,其中包含深刻的物理和哲学问题。
统计物理学中的熵概念,最初是热力学的一个基本概念,描述了系统的“内在混乱程度”。我们常常听到的熵增原理就是在说:宇宙中的事物有自发变得更加混乱的趋势。1877年,玻尔兹曼提出了熵的物理解释:可以认为是所有可能的微观状态的等概率统计平均——这是系统的一种宏观物理属性。随着香农将统计物理学中熵的概念推广到通信领域,提出信息熵——用来衡量信息的不确定性或信息量,熵的普遍意义变得更加明显了。
在深度学习中,模型接收信息的速度是固定的,因此加快学习进度的唯一方法是减少学习目标中冗余信息的数量。所谓“去粗存精”,就是深度学习模型中的最小熵原理,可以理解为“去除不必要的学习成本”。
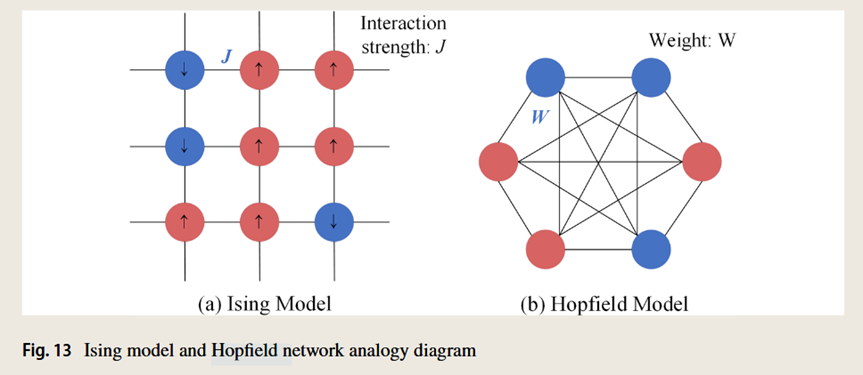
伊辛模型(Ising model)是统计物理中最重要的模型之一,它通过描述粒子的自旋状态来研究物质的磁性行为。对于伊辛模型,如果所有自旋方向相同,则系统的哈密顿量处于最小值。1982年,Hopfield受伊辛模型的启发,提出了Hopfield神经网络。Hopfield网络通过模拟神经元之间的相互作用来存储和回忆信息——它可以解决一大类模式识别问题,也可以给出一类组合优化问题的近似解。
Hopfield利用能量函数的思想形成了一种新的计算方法,阐明了神经网络与动力学之间的关系。他利用非线性动力学方法研究了这种神经网络的特性,并建立了神经网络的稳定性判据。而且,他指出信息是存储在网络的各个神经元之间的连接上,形成了所谓的Hopfield网络。
将脑神经网络与统计物理中的伊辛模型进行对比,将磁自旋的向上和向下两个方向视为神经元的激活和抑制两种状态,将磁自旋的相互作用视为神经元的突触权重值,这种类比为大量的物理理论和许多物理学家进入神经网络领域铺平了道路。
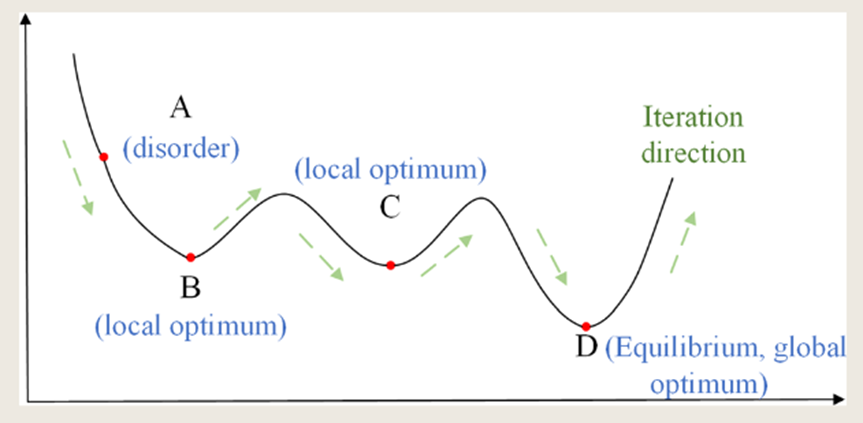
物理退火过程:首先物体处于非晶态,然后将固体加热到足够高的水平使其无序化,然后缓慢冷却,退火到晶体(平衡态)。
1983年,Metropolis等人首先提出了模拟退火算法,Kirkpatrick 等人将其应用到组合优化中,利用物理中固体物质的退火过程与一般优化问题的相似性,提出了经典的模拟退火算法:从某一初始温度开始,随着温度的不断降低,结合Metropolis准则(以一定概率概率接受新的状态)的概率突变特性,在解空间中进行搜索,以概率1停留在最优解(图5)。
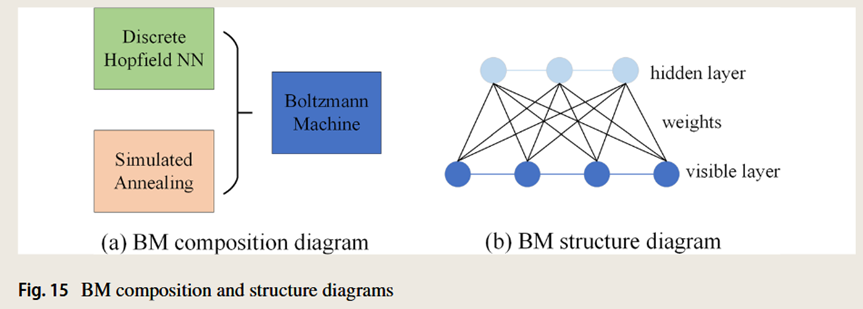
1985年,Hinton提出了玻尔兹曼机(Boltzmann Machine,BM),玻尔兹曼机在物理学中常被称为逆伊辛模型。它在神经元的状态变化中引入统计概率,网络的平衡态服从玻尔兹曼分布,网络运行机制基于一种模拟退火算法(图6),是一种很好的全局最优搜索方法,在一定范围内被广泛应用。
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是玻尔兹曼机的一种,其神经元之间表现出特定的结构和相互作用模式。RBM的目标是以最大化观测数据的似然概率的方式调整其网络参数。通过学习可见单元和隐藏单元之间连接的权重和偏置,RBM旨在捕获和表示数据中存在的潜在模式和依赖关系。通过迭代学习过程,RBM调整其参数以提高生成观测数据的可能性,从而增强其建模和生成相似数据实例的能力。
在物理学中,能量是系统状态的一个核心概念,它与系统的行为和变化密切相关。系统的稳定状态实际上代表了其对应的势能最低的状态。将这个思想迁移到深度学习中,可以构造出神经网络处于稳态时能量函数的定义。在神经网络中,能量的概念被用来分析和优化网络的损失函数,通过寻找能量最小化的状态来训练网络,提高网络的性能和泛化能力。
我们耳熟能详的一些神经网络其实都是基于能量模型来设计的,如生成对抗网络(GANs)、变分自编码器(Variational Autoencoder, VAE)、自回归模型(Autoregressive Models)等等。
GANs通过引入一个生成器网络和一个判别器网络的对抗过程,生成器网络试图生成与真实数据相似的数据,而判别器网络则试图区分真实数据和生成数据。这个过程中的“能量”最小化对应于生成数据的质量和真实性。
VAE是一种利用概率生成模型的深度学习框架,它通过最小化输入数据和生成数据之间的自由能差异来学习数据的有效表示。VAE模型中的自由能包含了数据的生成概率和先验知识的结合,从而能够生成新的数据样本。
自回归模型是一类通过明确定义数据点之间的依赖关系来建模数据分布的神经网络。这些模型通过序列的方式逐步生成数据,每一步的生成都依赖于前一步或多步的输出,从而捕捉数据中的复杂结构。在自回归模型中,每个数据点的概率分布是其之前数据点的函数,这种依赖关系可以被看作是一种“能量”关系,通过训练自回归模型来最大化似然函数,从而生成与真实数据分布相匹配的新数据样本。
自组织理论是指当开放系统达到远离平衡态的非线性区域时,一旦系统的某一参数达到某一阈值,系统就可以通过波动发生突变,从无序到有序,产生化学振荡等自组织现象。
1989年,Kohonen 教授提出自组织特征映射 (Self-organizing feature map,SOM)。自组织映射是一种无监督学习的神经网络,它能够将高维数据映射到低维空间中,同时保持数据的拓扑结构。SOM的灵感来自于统计物理学中的自组织现象,其中系统通过内部相互作用自发形成有序结构。
耗散结构神经网络模仿了非平衡态统计物理学中的耗散结构,这些网络能够在远离平衡态的条件下,通过外部能量输入和内部耗散过程,自发地形成有序结构。这种网络在处理非线性动态系统时表现出色,例如在模式识别和时间序列预测中的应用。
机器学习早期的研究很大程度上受限于凸优化理论的条件——局部最优即是全局最优。在处理非凸曲面时,高误差局部极小值的存在会影响梯度下降的动态性,从而影响优化算法的整体性能。
随机表面神经网络(Random Surface Neural Networks)是一类模仿物理中随机表面概念的深度学习模型,它们在设计上受到统计物理学中随机表面模型的启发。在物理学中,随机表面通常指的是具有随机粗糙度的表面,这种表面可以用一系列随机的高低起伏来描述。类似地,在机器学习中,随机表面模型被用来描述和处理数据的复杂性和多样性。这些模型可以捕捉数据中的随机波动和不确定性,从而提高模型对数据的适应能力。
随机表面神经网络通过在网络的权重和激活函数中引入随机性,来模拟物理随机表面的统计特性。这种方法可以帮助网络更好地处理输入数据的不确定性,提高网络对新数据的泛化能力。统计物理学中的随机矩阵理论被用来分析神经网络的损失函数曲面。通过这种方法,研究者可以更好地理解神经网络在训练过程中的动态行为,以及如何优化网络的权重以避免陷入局部最小值。随机表面神经网络能够处理和模拟复杂数据的不确定性和随机性,特别是在处理高维数据时表现出色。
对于神经网络来说,模型越大,层数越深,学习能力就越强。为了从大量冗余数据中提取特征,卷积神经网络往往需要过多的参数和较大的模型进行训练。
知识蒸馏是一种模型压缩和加速技术,它通过从大型的、预训练的模型(教师模型)中提取知识,并将其转移到一个更小、更简单的模型(学生模型)中,从而使学生模型能够在保持相似性能的同时,减少计算资源和存储空间的需求。
知识蒸馏被广泛应用于计算机视觉、自然语言处理和语音识别等领域。例如,在自然语言处理中,知识蒸馏可以用来创建轻量级的BERT模型,如DistilBERT,它在保持与原始BERT模型相似的性能的同时,显著减少了模型的大小和计算需求。
量子算法是一类在量子计算模型上运行的算法。通过借鉴量子力学的基本特性,如量子叠加或量子纠缠,提出了量子算法。相比于传统算法,量子力学在计算复杂度上有了大幅度的降低,甚至可以达到指数级的降低。
量子机器学习(Quantum Machine Learning, QML)结合了量子计算的速度和机器学习的学习能力。通过模拟量子力学的基本原理,如叠加态和纠缠态,QML在处理数据时展现出了传统算法无法比拟的潜力。例如,量子k-means算法、量子主成分分析、量子线性判别分析、量子k -近邻、量子支持向量机和量子决策树分类器等算法,利用量子态的特性来提高计算效率。
一般而言,量子机器学习算法有以下3个步骤:
( 1 )量子态制备。利用量子计算的高度并行性,必须将原始数据转换为量子比特的形式,使数据具有量子特性;
( 2 )量子算法处理。量子计算机不再是冯·诺依曼机的一部分,其操作单元与传统计算机完全不同,因此需要将传统算法进行量子化,移植到量子计算机中。
( 3 )量子测量操作。结果以量子态的形式输出,其本身以概率的形式存在。通过量子测量,量子叠加波包坍缩到经典态,以提取量子态中包含的信息,用于后续的信息处理。
与量子机器学习类似,量子深度学习(Quantum Deep Learning, QDL)允许深度学习算法利用量子力学的基本性质。量子深度学习使用量子计算代替传统的冯·诺依曼机计算,使深度学习算法实现了量子化,达到了显著提高算法并行性和降低计算复杂度的目的。
量子神经网络使用比特和量子门来构建和训练模型,从而实现对数据的高效处理。例如,量子多层感知器、量子卷积神经网络、量子递归神经网络。
演化算法是基于达尔文的自然选择理论和孟德尔的遗传变异理论构建的一种随机搜索算法,它模拟了生物进化中的繁殖、变异、竞争和选择。
量子演化算法(Quantum Evolutionary Algorithms)是一类模仿生物进化过程的优化算法,它们在量子层面上进行操作,使得个体可以同时包含多个状态的信息,得到更加丰富的种群,大大提高了算法的并行性和收敛速度。这些算法在搜索和优化问题上展现出了巨大的潜力,尤其是在处理高维空间中的全局优化问题时。
物理学与AI的结合,不仅仅是科学与技术的简单叠加,而是一场深刻的范式转变。通过将物理学的深刻见解融入到AI模型中,我们不仅能够更好地理解和预测自然界的现象,还能够设计出更加智能、高效的AI系统。随着研究的深入,我们有理由相信,物理学与AI的结合将为我们打开一扇通往未知世界的大门。
统计物理学不仅能解释热学现象,还能帮助我们理解从微观粒子到宏观宇宙的各个层级如何联系起来,复杂现象如何涌现。它通过研究大量粒子的集体行为,成功地将微观世界的随机性与宏观世界的确定性联系起来,为我们理解自然界提供了强大的工具,也为机器学习和人工智能领域的发展提供了重要推动力。
集智俱乐部联合纽约州立大学石溪分校教授汪劲、德累斯顿系统生物学中心博士后研究员梁师翎、香港浸会大学助理教授唐乾元,共同发起「非平衡统计物理」读书会,关注非平衡统计物理的前沿理论进展、生命和热力学、统计物理与机器学习交叉三个大的主题方向,涵盖热机优化问题、涨落相关的热力学、反常热力学现象、信息视角下的热力学、生命系统的景观和流理论、活性物质、生命系统、种群动力学、机器学习和人工智能等前沿话题。读书会计划从11月19日开始,每周二晚19:00-21:00进行。我们诚挚邀请相关领域的研究者分享的工作,也欢迎大家一起参与讨论交流!
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 10:00-12:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会