Nature:新冠流行难预测,超级计算机和气象学家来帮忙


一个“失败”的新冠传播模型
在一群计算机科学家耗时数月审核了一个最具影响力的流行病传播模型 CovidSim 后,他们认为:如果希望对新冠流行趋势的预测更加可靠,流行病学家可以尝试使用气候模型。
伦敦帝国理工学院开发了流行病预测模型 CovidSim。在说服英美政府为降低死亡人数而制定的封锁政策中,CovidSim 模型给出的预测结果起到了一定的推进作用。然而,其可靠性却也一直受到怀疑。
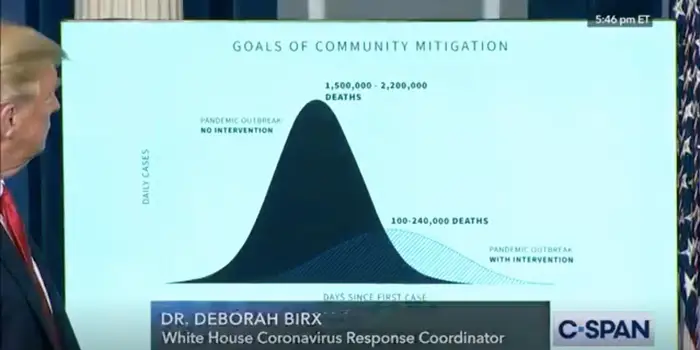
2020年3月31日,特朗普查看CovidSim模型的预测图
CovidSim模型的早期预测显示,如果各国政府不采取行动,英国最多将有50万人死亡,美国最多将有220万人死亡。这一度成为英美两国政府决策的重要参考。
近日,受伦敦皇家学会委托的研究员使用超级计算机,对CovidSim进行了深入研究。这项研究结果于11月发布于预印本平台 Research Square 。
论文题目:
Model uncertainty and decision making: Predicting the Impact of COVID-19 Using the CovidSim Epidemiological Code
论文地址:
https://www.researchsquare.com/article/rs-82122/v3
领导该课题的伦敦大学学院化学家兼计算机科学家 Peter Coveney 表示,他们的研究表明,CovidSim 对输入数值微小变化的敏感程度被人们忽略了,因此预测结果高估了封锁政策能减少的死亡人数。

论文通讯作者 Peter Coveney
Coveney 不愿批评由流行病学家 Neil Ferguson 领导的帝国理工学院研究团队。毕竟,Coveney 赞同这个团队做出了最好的预测工作。Coveney 表示,CovidSim 的确表明,如果什么措施都不做确实会造成严重的后果。但流行病学家应该对“集成”模型(’ensemble’ models)的模拟效果进行压力测试。
类似于机器学习中的多个模型相结合的集成学习(Ensemble Learning)概念,“集成”模型也包含着数千个不同版本的小模型。这些模型运行在不同的输入条件和假设中,以应对不同的概率的场景。从天气预报到分子动力学,在计算量很大的领域中,这种概率混合方法都很常见。
Coveney 的团队已经为 CovidSim 做到了这一点。其研究结果表明:如果该模型作为一个整体“集成”,运行后得到的一系列可能的死亡人数,其平均值是原来预测结果的两倍——并且更接近实际数值。
Coveney 说:“虽然 CovidSim 被捧为最复杂的流行病学模型,但与真正复杂的超级计算应用程序相比,它就像一个玩具。”英国皇家学会大流行建模快速援助(Royal Society’s Rapid Assistance in Modelling the Pandemic,RAMP)倡议的一部分就是基于 Coveney 所做的性能检查。
超级计算机捕捉复杂参数变化
Coveney 团队使用了位于波兹南超级计算和网络中心的 Eagle 超级计算机对CovidSim 进行了6000次独立的运行测试。每次测试都有一组独特的参数。这些参数表示了流行病的一些特征:包括病毒的传染性和致命性、人们在各种环境中潜在的接触者数量以及居家工作等政策的执行情况等。在三月份帝国理工的团队做出预测的时候,这些参数依然依赖于推测:其中一些来自关于病毒本身的初步数据,另一些则是基于对过往流感等传染性疾病的经验。
预测疾病传播的模型通常会依赖于数百个参数——这就会引入不确定性。发起建立 RAMP 的人群中就有一种隐忧:流行病预测模型的参数多到有点夸张,预测出来的结果恐怕可靠性不足。
他的团队从 CovidSim 代码中发现了940个参数,其中对结果影响非常大的有19个。而且,不同的预测结果中三分之二的差异其实是由三个参数造成的:在出现症状且具有传染性之前的潜伏期长度、社交隔离的执行情况以及感染者的隔离期。
研究表明,这些参数的微小变化可能会对模型的输出产生巨大的非线性影响。例如,数千次模拟测试中的大多数结果表明,在封锁政策下,英国的死亡人数远远高于帝国理工的初步预测——在某些情况下,甚至高出5-6倍。平均死亡人数也是帝国理工预测人数的2倍。
在一个模拟的情景中,假设英国每周有60人需要住院接受重症监护,那么三月份的报告预测英国共计将有8700人死亡。Coveney小组得出的结果表明,这一数字平均约为15,000人;在某些情况下,甚至可能超过40,000人。很难将这些预测与英国新冠肺炎死亡的实际数字进行比较,因为封锁政策开始的时间比任何模型假设的结果都晚了一周,那时已经有大量的感染者在传播疾病了。
Coveney 表示,帝国理工的团队做错了——他们正确地运行了模拟,但是不知道如何从模型中得出包含概率的混合结果。这意味需要做另一番计算。Coveney 也认为,不应将该模型作为一个整体“集成”运行其得到的结果用来决策是否改变防疫政策。但是英国爱丁堡大学的流行病学家和数据科学家 Rowland Kao 指出,政府应当比较、综合多种预测模型的结果。如果基于单一的模型来做决策,就太草率了。
引入气候模型和贝叶斯工具
帝国理工团队的领导者 Ferguson 认同了 Coveney 的大部分意见。但他也表示:“只不过,在三月份我们尚无能力进行这样的模拟测试。”Ferguson 同时表示,帝国理工团队已经对模型进行了很大的改进,现在模型已经可以得到包含概率的混合结果了。例如,他们现在使用贝叶斯概率来表示 CovidSim 输入的不确定性。这种做法在一些流行病学模型中很常见,例如口蹄疫。
还有一个更简单模型的预测结果被用来建议英国政府本月应重新执行封锁政策。这种模型比CovidSim更灵活:“基于不确定性方面的考量,如果我们可以一周多次运行模拟程序,实时拟合数据要容易多了。”Ferguson 表示。
Coveney 表示,“这样听上去就像是在做正确的改进,且与我们的预测结果也一致了。”
Ferguson 表示,技术方案的选择通常取决于对计算能力的权衡。“如果你想一板一眼正确地描述所有的不确定性,用一个计算难度较小的模型会更加容易。”
英国牛津大学的气候物理学家 Tim Palmer 认为,使用贝叶斯工具是进步的做法。Tim 率先在天气预报中使用了集成建模。但也只有通过在最强大的计算机上运行的集成建模技术,我们才能得到最可靠的流行病预测。在政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC)的协调下,这些新技术提高了气候预测模型的可靠性。
Palmer 也表示,流行病模型预测也需要类似IPCC的机构,我们需要某些国际间合作的设施,我们可以在这样的设施中开发流行病模型。情况紧急,这件事的推进将会很仓促,但是我们需要某种国际组织来综合全世界的流行病学模型进行预测。
作者:Leo 审校:赵雨亭 编辑:邓一雪
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧!
👇点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











