什么是邻接表 | 集智百科

“集智百科精选”是一个长期专栏,持续为大家推送复杂性科学相关的基本概念和资源信息。作为集智俱乐部的开源科学项目,集智百科希望打造复杂性科学领域最全面的百科全书,欢迎对复杂性科学感兴趣、热爱知识整理和分享的朋友加入!
本文是对集智百科中“邻接表”词条的摘录,参考资料及相关词条请参阅百科词条原文。
本词条由集智俱乐部众包生产,难免存在纰漏和问题,欢迎大家留言反馈或者前往对应的百科词条页面进行修改,一经修改,可以获得对应的积分奖励噢!
目录
一、什么是邻接表?
二、实现
三、操作
四、权衡
五、数据结构
六、相关资源推荐
七、集智百科词条志愿者招募

邻接表:https://wiki.swarma.org/index.php?title=邻接表
1. 什么是邻接表?
在图论和计算机科学中,邻接表 Adjacency List 是用来表示有限图的无序表的集合。每个列表描述图中一个顶点的邻域集。这是计算机程序中常用的几种图形表示法之一。
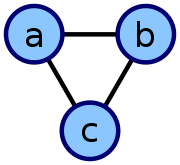
此无向循环图可以用三个无序列表来描述:{a,b},{a,c},{b,c}
2. 实现
图的邻接表表示法将图中的每个顶点与其邻接顶点或边的集合关联起来。这个基本思想有许多变体,在如何实现顶点和集合之间的关联,如何实现集合,以及是否包括顶点和边还是只包括顶点作为第一类对象,以及什么类型的对象被用来表示顶点和边的细节上都有所不同。

Guido van Rossum建议的实现方式是使用哈希表 hash table将图中的每个顶点与相邻顶点的数组数据结构联系起来。在这种表示方式中,一个顶点可以由任何可哈希的对象表示,没有明确地将边表示为对象。
Cormen等人提出了一种用索引号来表示顶点的实现方法。他们的表示方法是使用一个按顶点数索引的数组,其中每个顶点的数组单元格指向该顶点的相邻顶点的单链表 singly linked list。在这种表示方式中,单链表的节点可以解释为边对象;然而,它们并不存储关于每条边的完整信息(它们只存储边的两个端点中的一个) ,在无向图 Undirected Graph 中,每条边有两个不同的链表节点(边的两个端点中的每个端点的列表中都有一个)。
Goodrich和Tamassia提出的面向对象入射列表结构有特殊的顶点对象和边缘对象类。每个顶点对象都有一个实例变量,指向一个集合对象,该集合对象列出了邻近的边缘对象。反过来,每个边缘对象又指向其端点的两个顶点对象。这种表示方式邻接表比直接列出相邻顶点的版本使用更多的内存,但是显示边对象的存在操作可以允许它在存储额外的关于边的信息方面有额外的灵活性。
3. 操作
接表数据结构执行的主要操作是列出给定顶点的邻居列表。使用上面详细说明的任何表示方式,都可以在每个邻居的固定时间内执行。换句话说,列出一个顶点 v 所有邻居的总时间与 v 的度 Degree 成正比。
也可以使用邻接列表来测试两个指定顶点之间是否存在边,但效率不高。在一个邻接表中,每个顶点的邻域都是不排序的,通过对该顶点的邻域进行顺序搜索 sequential search,可以按照给定两个顶点的最小阶数按时间比例进行边的存在性测试。如果邻域被表示为一个排序数组,则可以使用二分搜索法 binary search,时间与次数的对数成正比。
4. 权衡
邻接表的主要替代方法是邻接矩阵 Adjacency Matrix,该矩阵的行和列按顶点索引,其单元格包含一个布尔值,该值指示与单元格的行和列对应的顶点之间是否存在边。
对于稀疏图 Sparse Graph (大多数顶点对不是由边连接的图),邻接表比邻接矩阵(存储为二维数组)更节省空间:邻接表的空间使用与图中的边和顶点的数量成正比,而对于以这种方式存储的邻接矩阵,其空间与顶点数的平方成正比。然而,通过使用由顶点对索引的哈希表而不是数组,可以更有效地存储邻接矩阵的空间,从而匹配邻接表的线性空间使用。
邻接表和邻接矩阵之间的另一个显著区别是它们执行操作的效率。在邻接表中,每个顶点的邻居可以有效地列出,在时间上与顶点的程度成正比。在邻接矩阵中,这个操作需要的时间与图中顶点的数量成正比,而顶点的数量可能明显高于度。此外,邻接矩阵允许测试两个顶点是否在固定的时间内彼此相邻;邻接表支持这一操作的速度较慢。
5. 数据结构
邻接表和邻接矩阵之间的另一个显著区别是它们执行操作的效率。在邻接表中,每个顶点的邻居可以有效地列出,在时间上与顶点的程度成正比。在邻接矩阵中,这个操作需要的时间与图中顶点的数量成正比,而顶点的数量可能明显高于度。此外,邻接矩阵允许测试两个顶点是否在固定的时间内彼此相邻;邻接表支持这一操作的速度较慢。
作为一种数据结构,邻接表的主要替代是邻接矩阵。因为邻接矩阵中的每个项只需要一个位,它可以用一种非常紧凑的方式表示,只占用字节的连续空间,其中是图的顶点数。除了避免浪费空间之外,这种紧凑性还支持局部引用 locality of reference。
用稀疏邻接矩阵表示邻接表时,将占用更少的空间。这是因为它能避免为不存在的边分配任何空间。在一台32位计算机上,如果使用原始的数组结构实现邻接表,那么对于一个无向图来说,它大约需要占用字节的存储空间,其中表示边的个数。每条边都将会在两个邻接表中重复出现,并分别占用4字节空间。
注意到一个无向简单图最多可以有 条边(允许循环),我们可以让
条边(允许循环),我们可以让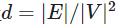 表示该图的密度。然后,当
表示该图的密度。然后,当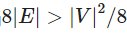 时,
时,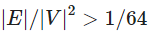 ,即
,即 ,邻接表表示比邻接矩阵表示占用更多的空间。因此,图必须足够稀疏,才适合使用邻接表表示。
,邻接表表示比邻接矩阵表示占用更多的空间。因此,图必须足够稀疏,才适合使用邻接表表示。
除了空间上的权衡,不同的数据结构也有着不同的操作。在邻接表中找到与给定顶点相邻的所有顶点就像读取邻接表一样简单。对于邻接矩阵,必须扫描整行,这需要花费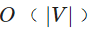 的时间。给定的两个顶点之间是否有边可以用邻接矩阵一次确定,并且运行时间与邻接列表中两个顶点的最小度数成正比。
的时间。给定的两个顶点之间是否有边可以用邻接矩阵一次确定,并且运行时间与邻接列表中两个顶点的最小度数成正比。
6. 相关资源推荐
课程推荐
本课程中,我们有幸邀请了汪小帆、赵海兴、许小可、史定华、陈清华、张江、狄增如、陈关荣、樊瑛、刘宗华这十个来自六大不同高校、在网络科学领域耕耘许久的教授作为导师,依据教材框架,各有侧重地为我们共同勾勒出整个学科的美丽图景,展示这个学科的迷人魅力,指引这个学科的灿烂未来。
我们将颠覆传统老师通篇主讲的课堂模式,用一种前所未有的集智课堂形式来解惑答疑,帮助大家完成从散点思维到网络思维,直至网络科学思维的跃升。
课程推荐:巴拉巴西网络科学https://campus.swarma.org/course/1754
积分充值活动
集智的课程视频关注复杂系统和人工智能等跨学科前沿领域,在复杂系统建模、图神经网络、网络科学、计算社会科学、因果科学等领域有大量全网独家内容。
我们特推出积分充值活动,本次活动持续至2月11日。积分可以用于购买集智学园站内课程、参与集智俱乐部读书会。现在充值集智学园积分(∫),可获赠额外积分和复杂性科学知识卡片。

扫码充值
积分充值规则:扫描二维码充值 300 元,得 33000 ∫,赠送 2 副限量版复杂性科学知识卡充值 500 元,得 55000 ∫,赠送 4 副限量版复杂性科学知识卡充值 1000 元,得 110000 ∫,赠送 10 副限量版复杂性科学知识卡

复杂性科学知识卡(扑克)2.0版
7. 百科项目志愿者招募
作为集智百科项目团队的成员,本文内容由思无涯咿呀咿呀参与贡献。我们也为每位作者和志愿者准备了专属简介和个人集智百科主页,更多信息可以访问其集智百科个人主页。
以上内容都是我们做这项目的起点,作为来自不同学科和领域的志愿者,我们建立起一个有效的百科团队,分配有审校、翻译、编辑、宣传等工作。我们秉持:知识从我而来,问题到我为止的信念,认真负责编撰每一个词条。
在这里从复杂性知识出发与伙伴同行,同时我们希望有更多志愿者加入这个团队,使百科词条内容得到扩充,并为每位志愿者提供相应奖励与资源,建立个人主页与贡献记录,使其能够继续探索复杂世界。
如果你有意参与更加系统精细的分工,扫描二维码填写报名表,我们期待你的加入! 集智百科报名表
集智百科报名表
来源:集智百科编辑:曾祥轩
推荐阅读什么是人工社会?| 集智百科
什么是自组织 | 集智百科
什么是元胞自动机?| 集智百科
什么是李雅普诺夫函数 | 集智百科
什么是非线性系统 | 集智百科
加入集智,一起复杂!
点击“阅读原文”,阅读邻接表相关内容与文献
微信扫一扫,分享到朋友圈











