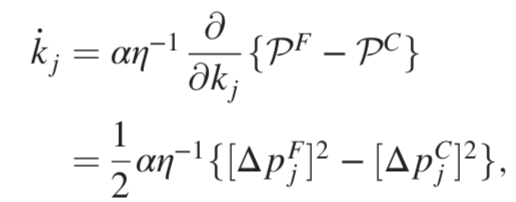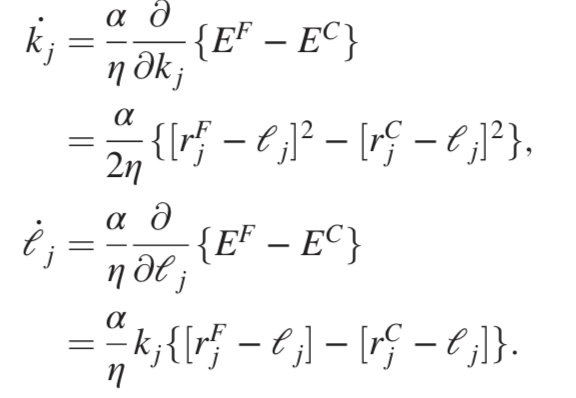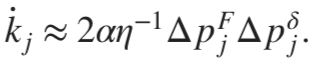材料和机器的设计通常考虑到特定的目标,以便它们对给定的力或约束表现出所需的响应。发表在PRX上的一篇论文中,研究人员探索另一种方法:物理耦合学习(physical coupled learning)。在这种范式中,系统最初并不是为完成任务而设计的,而是在物理上适应所施加的力或约束,以培养执行任务的能力。至关重要的是,研究人员需要通过物理上合理的学习规则来促进耦合学习,这意味着学习只需要本地响应,不需要所需功能的明确信息。研究结果表明,可以为任何物理网络推导出这种局部学习规则,无论该网络是处于平衡状态还是稳态。该文章特别关注两个特定系统:无序流网络和弹性网络(disordered flow networks and elastic networks)。通过将统计学习理论应用于物理世界,研究人员证明了新型智能超材料(smart metamaterials)的合理性。
研究领域:统计物理,监督学习,集体行为,流网络,弹性网络
原文题目:
Supervised Learning in Physical Networks: From Machine Learning to Learning Machines
原文地址:https://journals.aps.org/prx/abstract/10.1103/PhysRevX.11.021045#fulltext
工程材料通常被设计为具有特定的属性或功能的材料[1]。设计过程通常涉及无数次反复试验,在此期间系统会针对所需功能进行反复测试 [2]、修改和再次测试。合理的设计过程从材料组件的详细信息开始,通常使用计算来预测和调整设计。该策略基于学习,学习策略曾经主要限于非物理网络,例如神经网络。有一种方法被称为“全局监督学习”(global supervised learning),在数据分类问题中得到大量应用[3,4]。
全局监督学习最近被用于设计流网络和弹性网络,它们是实际的物理系统,具有所需的特定功能,例如变构(allostery) [5,6]。在这种物理环境中,这种学习方法被称为“调控”(tuning),因为修改学习自由度需要微观层面的外部干预。
相比之下,自然系统(如大脑)使用完全不同的学习框架,通过进化以获得所需的功能,研究人员称之为“局部学习”(local learning)。这种演变是完全自主的,不需要外部人员来评估系统的当前状态,进行后续修改。在局部学习中,网络的某些部分只能根据其附近可用的局部信息进行进化[7]。将这种学习方法应用于物理网络(例如流网络或机械网络)特别有用。
使用全局或局部监督学习实现所需功能的物理网络涉及两组不同的自由度。首先,网络通过最小化相对于其物理自由度的标量函数来响应约束。其次,网络可以调整学习自由度,来学习特定目标对源的响应。学习过程的预期结果是实现“目标”边缘或节点对外部约束的定制响应。
最近,“定向老化”(directed aging)的局部监督学习方法,其中无序系统的时间演化由施加的应力驱动,可用于创建具有所需特性或功能的机械超材料 [9-11]。局部监督学习相对于全局监督学习的巨大优势在于该过程是可扩展的——它可以应用于训练大型系统,而无需手动修改其组成部分 [9]。此外,定向老化不需要微观相互作用的详细信息或操纵(微观)学习自由度的能力[9]。
虽然定向老化方法在训练某些物理网络以实现所需功能方面是成功的,但它们在其他方面却失败了,特别是在高度约束的网络中,例如流网络和高协调机械网络。研究人员提出了一个通用框架,称之为“耦合局部监督学习”,用于物理网络,如流网络和机械网络。这些规则旨在根据局部条件调整学习自由度。因此,它们与全局监督学习一样有可能成功获得所需的响应。
研究人员首先在流网络的背景下讨论耦合学习。以前,研究人员通过最小化全局成本函数,使用全局监督学习对此类网络进行训练,以展示流量变构 [5,6] 的特定功能。具体而言,网络被训练为在目标边缘(或许多目标边缘)上具有所需的压降,以响应跨网络中其他源边缘施加的压降。在这里,研究人员展示了严格的本地学习规则如何类似地训练流网络。
图1:流网络中的耦合学习。(a) 在自由阶段,节点压力受到约束,使得源节点(红色)具有特定的压强值 pS。由于网络中的自然流动过程,目标节点压强 pT 和所有管道上的耗散功率 pj 达到其稳态值。(b) 在钳位阶段(clamped phase),监督者约束目标节点压强,使它们与自由状态相比更接近其期望值。(c) 严格的局部学习规则,即根据其响应修改管道电导,与自由状态和钳位状态之间的耗散功率差异成正比。因此,学习规则耦合了源节点和目标节点的压强。
一个流网络由一组N个标记为μ的节点定义,每个节点带有一个压力值pμ,这些压力是网络的物理自由度。节点由管道j连接,管道j以其电导kj为特征,则总耗散功率为:
研究人员关注局部学习规则,其中每个管道j中的学习自由度kj只能响应与管道j相关的两个节点上的物理变量(压力值)。他们引入了耦合学习的框架,定义了两组关于网络压力值的约束,提出了管道电导值的学习规则:
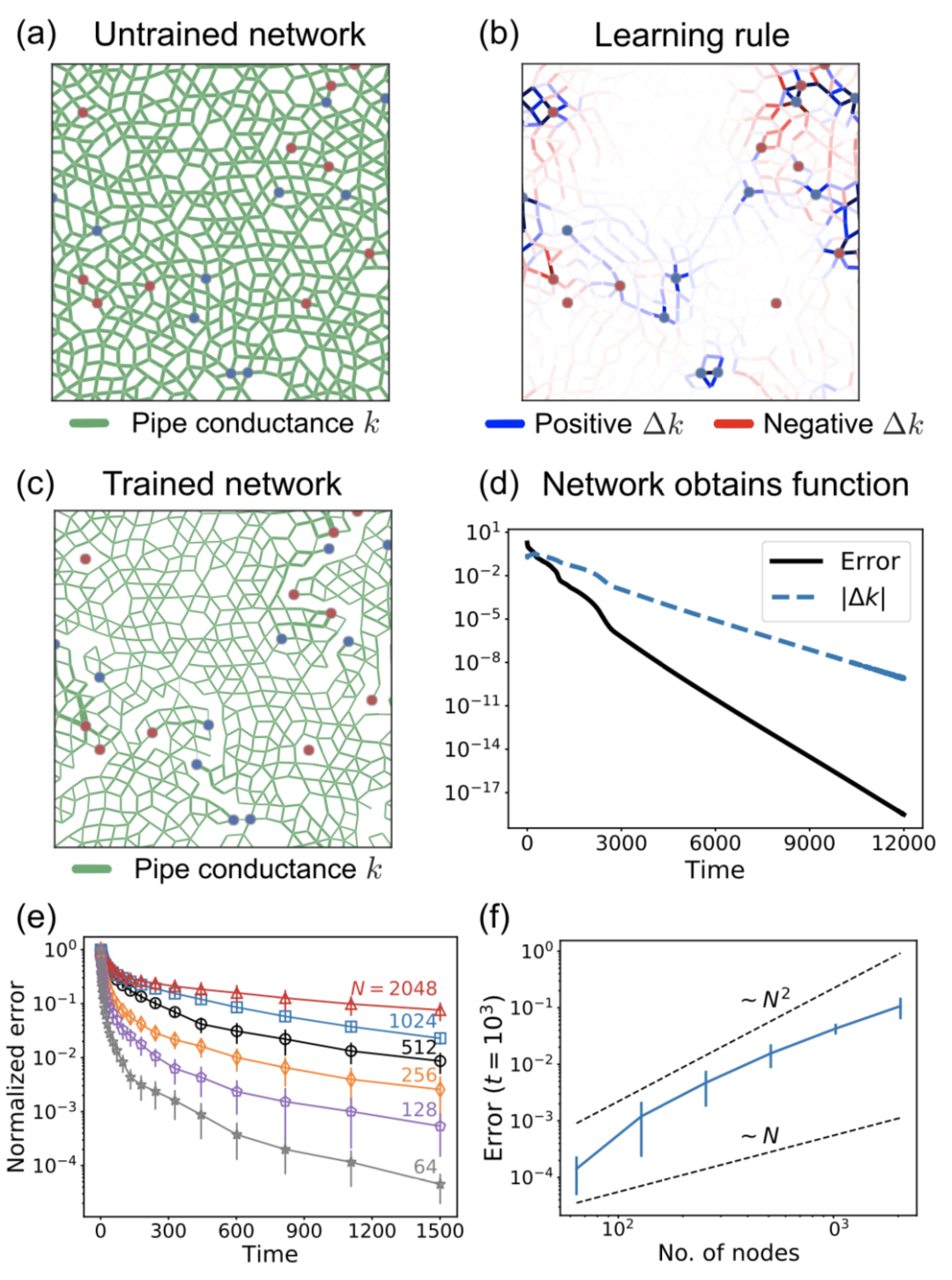
图2:使用耦合学习训练流网络。(a)未经训练的无序流动网络在所有管道上具有均匀的电导率,如绿色边缘的均匀厚度所示。十个红色和蓝色节点对应于源节点和目标节点,点大小指示源压力 和所需目标压力的大小。(b)在每一步中,电导值都使用等式进行修改。根据自由状态和夹紧状态的流量不同。这个过程是反复应用的。(c)训练后,与(a)中显示的初始网络相比,由绿色边缘的厚度表示的网络电导值发生了很大变化。(d)在网络训练期间,目标节点的压力值接近期望值,如指数收缩误差(黑色实线)所示。当误差较小时达到所需的目标值;每个时间步长 Δk(蓝色虚线)中电导的修改也以指数形式消失。(e) 训练了多个不同大小的网络,并发现所有网络都可以通过耦合学习成功训练。误差线表示初始网络和源和目标选择的变化。在所有情况下,误差呈指数衰减,但较大的网络收敛速度较慢。(f) 选取某个时间,误差随着系统规模的增加而增加。
耦合学习算法能够训练网络,让其表现出所需的响应,并成功地将初始误差降低了几个数量级。
为了证明耦合学习框架的通用性,研究人员将其应用于另一个物理系统:中心力弹簧网络(central-force spring networks)。这里有一组嵌入在d维空间中的N个节点,位于位置{xu}。标记为j的弹簧的能量取决于该弹簧的应变: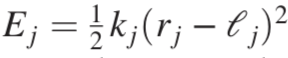 ,总能量为:
,总能量为: 。
除了在网络的边缘而不是节点上定义源和目标边界条件外,弹簧网络的自由和钳位状态与前面的例子类似。应用耦合学习规则来获得两个单独的学习规则,一个用于弹簧常数 kj,另一个用于静止长度 lj:
。
除了在网络的边缘而不是节点上定义源和目标边界条件外,弹簧网络的自由和钳位状态与前面的例子类似。应用耦合学习规则来获得两个单独的学习规则,一个用于弹簧常数 kj,另一个用于静止长度 lj:
图3:通过修改 (a) 弹簧常数或 (b) 静止长度来训练弹簧网络。目标边缘长度的误差显示为黑色圆圈和蓝色方块网络的训练迭代次数的函数。通过耦合学习的训练对于刚度和静止长度自由度都是成功的。
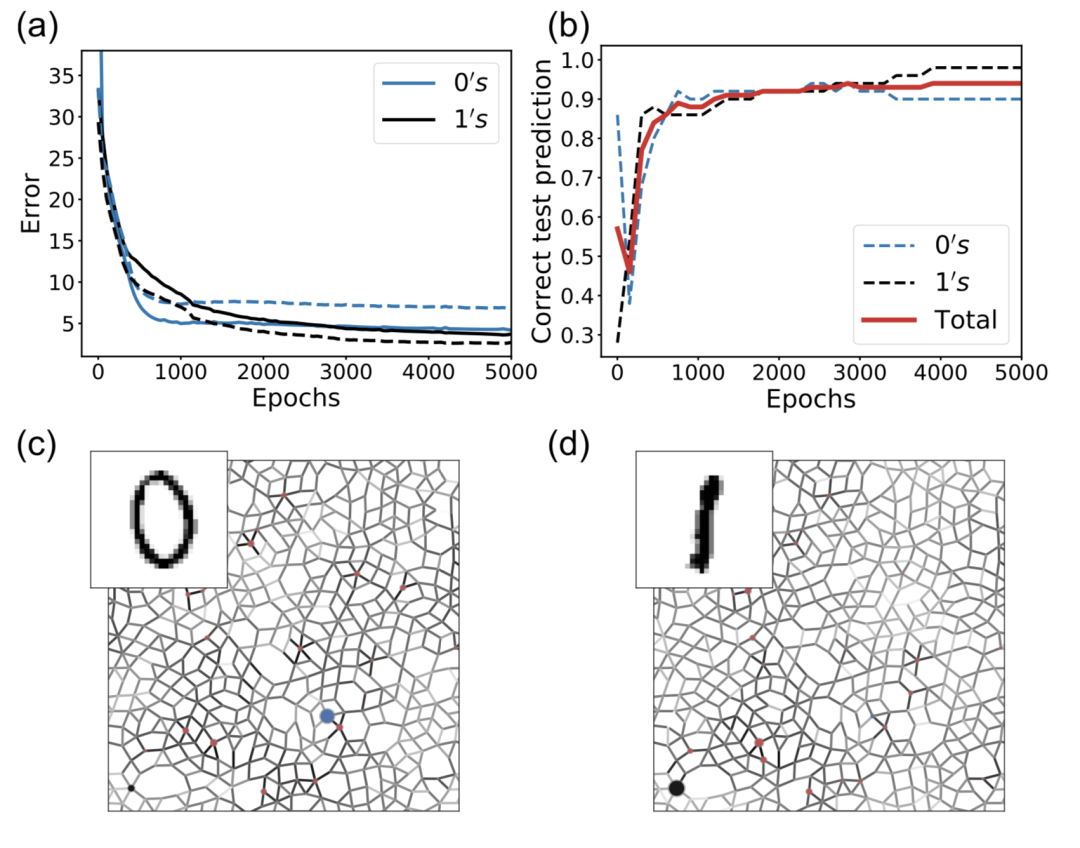
研究人员训练流网络以表现该网络对图像进行分类的能力。在分类中,训练网络在多组输入和输出之间进行映射。为了在使用耦合学习规则的同时编码多个输入-输出图,他们稍微修改了训练过程[28]。每个训练图像提供一个输入,该图像的正确答案是所需的输出。
图4:MNIST数字分类(0和1):(a)数字 0(蓝色)和 1(黑色)的分类误差(成本函数值)的对比,其中每个时期由学习规则的 100 次迭代组成,每次迭代时随机选择不同的训练图像。实线表示训练误差,虚线表示测试误差。(b) 测试图像的预测精度(网络对数字 0 和 1 做出的正确预测的分数)与时期数的关系。总测试准确度以红色显示。(c)(d) 当呈现左上角的图像时网络的响应。每个边缘消耗的功率由边缘颜色的强度表示。而目标节点的压力用蓝色和黑色圆圈标记。当显示0图像时,0目标节点压力高(蓝色圆圈),1目标节点压力低;当显示1图像时,1目标节点压力高(黑色圆圈),0目标节点压力低。实线表示训练误差,虚线表示测试误差。(b) 测试图像的预测精度(网络对数字0和1做出的正确预测的分数)与时期数的关系。总测试准确度以红色显示。(c),(d)当呈现左上角的图像时网络的响应。每个边缘消耗的功率由边缘颜色的强度表示。而目标节点的压力用蓝色和黑色圆圈标记。当显示0图像时,0目标节点压力高(蓝色圆圈),1目标节点压力低;当显示1图像时,1 目标节点压力高(黑色圆圈),0目标节点压力低。
在上一节中,研究人员已经通过计算证明了流网络和机械网络使用耦合学习规则成功地学习了所需的行为。为了让网络在物理环境中自主学习,网络必须能够将耦合学习规则作为其学习自由度。此外,外部操作需要能够根据需要钳制目标节点。对于流体流动网络,耦合学习需要管道电导值与管道内部流动的耦合。
1)近似学习规则(approximate learning rules)
考虑前面描述的流网络。在物理流网络中实现这个学习规则有两个主要问题。首先是方程的学习规则,它对边j的电导的学习规则不仅取决于通过边j的功率,还取决于应用自由边界条件时的功率与应用钳位边界条件时的功率之间的差异。第二个障碍是方程,这要求管道必须能够增加或减少其电导,电导只能在一个方向上改变的管道可能更容易通过实验实现。
我们可以在自由态周围串联扩展钳位功率,以获得学习规则的新表达式:
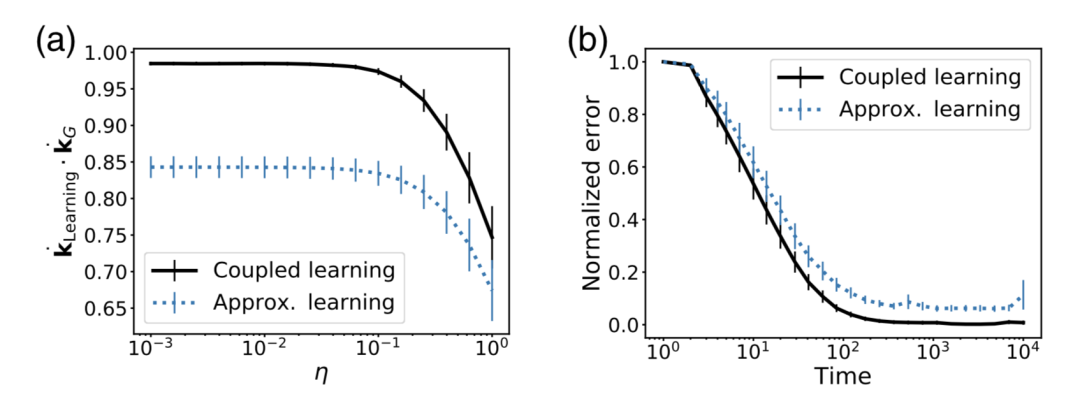
图5:使用近似的、实验可行的学习规则训练流网络。(a)全耦合学习规则和近似学习规则与不同η值的成本函数的梯度进行比较。虽然全耦合学习规则是优越的,但最优调整和近似规则之间仍然存在显着的相关性。(b) 可以在相似的时间尺度上使用完整规则和近似规则来训练网络。与完整规则相比,近似学习规则受到更多限制,通常有更高的错误级别。
网络中存在噪音,在学习中可以适当调整参数以改善训练结果。
图6:使用噪声测量和扩散学习自由度进行学习。(a)当自由或钳位状态测量中存在噪声时,小的微调会阻碍学习。可以通过较大的微调来改善训练结果。(b)学习自由度的漂移会阻碍学习,但可以通过增加学习率α来减轻其影响。
在这项工作中,研究人员采用了耦合学习的准静态极限,因此在计算自由或钳位状态之前,网络首先达到其稳定平衡。换句话说,研究人员探索了学习比物理动力学慢得多的极限 [39]。然而,物理网络需要有限的时间来弛豫到它们的平衡状态。因此,使用小的微调通常无助于加速网络向其平衡状态的物理松弛。
为了强调局部监督学习方法的优势,研究人员将其与全局监督学习进行比较。
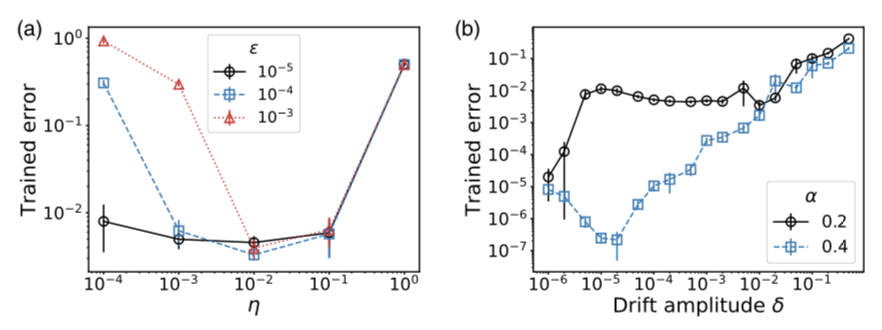
图7:耦合学习规则和全局监督学习的效果对比。(a)流网络中训练轨迹之间的直接比较表明,耦合学习与梯度下降一样成功。(b)训练期间耦合学习和调整(梯度下降)的修改向量Δk的点积经历了波动,但仍然很高。(c)在训练开始时,对于具有1(红色三角形)、3(蓝色菱形)和 10(黑色十字)目标节点。对于η≪1,这两种方法预测的结果非常相似。(d)耦合学习产生的结果作为目标节点数量的函数。(e)(f)非线性弹性网络中耦合学习和梯度下降的归一化预测之间的点积。我们发现在使用刚度和静止长度自由度 的弹性网络训练期间,耦合学习和梯度下降在很大程度上是一致的。
在这项工作中,研究人员引入了耦合学习,并将其应用于两类物理系统,即流网络和机械弹簧网络。与成本函数优化等更传统的技术相比,这种监督学习规则的优势在于它们在物理上是合理的。至少原则上,耦合学习可以在现实的材料和网络中实现,使它们能够获取外部信号并自主学习。
这种学习机器不仅本身很有趣,而且与通过优化成本函数设计的物理系统相比,可能具有重要的优势。首先,由于该过程涉及对局部应力的局部响应,因此该方法具有可扩展性——不同规模(不同节点数量)的网络中的训练步骤将花费大致相同的时间。相比之下,计算集体成本函数的梯度所需的时间随着系统规模的增加而迅速增加。
其次,原位训练系统的能力意味着不需要知道网络几何形状或拓扑结构,甚至不需要任何关于物理或学习自由度的信息。这对于实验系统特别有价值,实验系统不必对完整的微观细节进行表征,也可以训练模型。
第三,只要网络可以执行学习规则,使用者就不需要操纵单个边以获得所需的学习自由度值(例如,流网络的边电导)。因此,使用角色可以由最终用户担任。用户可以为他们所需的任务训练网络,而不是专业算法设计师。
有人可能会问,物理网络是否可以与计算神经网络竞争。研究人员的目标不是超越神经网络。相反,他们的目标是设计能够自主适应任务的物理网络,它能够在没有计算机的情况下被推广到不同输入的物理系统中。
[1] D. Norman, The Design of Everyday Things, Revised and Expanded Edition (Basic Books, New York, NY, 2013).
[2] S. H. Thomke, Managing Experimentation in the Design of New Products, Manage. Sci. 44, 743 (1998).
[3] S. B. Kotsiantis, I. Zaharakis, and P. Pintelas, Supervised Machine Learning: A Review of Classification Techniques, Emerg. Artif. Intell. Appl. Comput. Eng. 160, 3 (2007), https://datajobs.com/data-science-repo/Supervised-Learning-[SB-Kotsiantis].pdf.
[4] P. Mehta, M. Bukov, C.-H. Wang, A. G. R. Day, C. Richardson, C. K. Fisher, and D. J. Schwab, A High-Bias, Low-Variance Introduction to Machine Learning for Phys- icists, Phys. Rep. 810, 1 (2019).
[5] J. W. Rocks, N. Pashine, I. Bischofberger, C. P. Goodrich, A.J. Liu, and S.R. Nagel, Designing Allostery-Inspired Response in Mechanical Networks, Proc. Natl. Acad. Sci. U.S.A. 114, 2520 (2017).
[6] J. W. Rocks, H. Ronellenfitsch, A. J. Liu, S. R. Nagel, and E. Katifori, Limits of Multifunctionality in Tunable Networks, Proc. Natl. Acad. Sci. U.S.A. 116, 2506 (2019).
[7] B. A. Richards and T. P. Lillicrap, Dendritic Solutions to the Credit Assignment Problem, Curr. Opin. Neurobiol. 54, 28 (2019).
[8] J. W. Rocks, A. J. Liu, and E. Katifori, Revealing Structure- Function Relationships in Functional Flow Networks via Persistent Homology, Phys. Rev. Research 2, 033234 (2020).
[9] N. Pashine, D. Hexner, A. J. Liu, and S. R. Nagel, Directed Aging, Memory, and Natures Greed, Sci. Adv. 5, eaax4215 (2019).
[10] D. Hexner, N. Pashine, A. J. Liu, and S. R. Nagel, Effect of Directed Aging on Nonlinear Elasticity and Memory Formation in a Material, Phys. Rev. Research 2, 043231 (2020).
[11] D. Hexner, A. J. Liu, and S. R. Nagel, Periodic Training of Creeping Solids, Proc. Natl. Acad. Sci. U.S.A. 117, 31690 (2020).
[12] H. Ronellenfitsch and E. Katifori, Global Optimization, Local Adaptation, and the Role of Growth in Distribution Networks, Phys. Rev. Lett. 117, 138301 (2016).
[13] M. Stern, C. Arinze, L. Perez, S. E. Palmer, and A. Murugan, Supervised Learning through Physical Changes in a Mechanical System, Proc. Natl. Acad. Sci. U.S.A. 117, 14843 (2020).
[14] M. Stern, V. Jayaram, and A. Murugan, Shaping the Topology of Folding Pathways in Mechanical Systems, Nat. Commun. 9, 4303 (2018).
[15] J.R. Movellan, Contrastive Hebbian Learning in the Continuous Hopfield Model, Connectionist Models (Elsev- ier, Amsterdam, 1991), pp. 10–17.
[16] P. Baldi and P. Sadowski, A Theory of Local Learning, the Learning Channel, and the Optimality of Backpropagation, Neural Netw. 83, 51 (2016).
[17] Y. Bengio and A. Fischer, Early Inference in Energy-Based Models Approximates Back-Propagation, arXiv:1510.02777.
[18] B. Scellier and Y. Bengio, Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation, Front. Comput. Neurosci. 11, 24 (2017).
[19] S. Bartunov, A. Santoro, B. Richards, L. Marris, G. E. Hinton, and T. Lillicrap, Assessing the Scalability of Biologically- Motivated Deep Learning Algorithms and Architectures, in Proceedings of the 32nd Conference on Advances in Neural Information Processing Systems, Montreal, 2018 (Curran
Associates Inc., Red Hook, NY, 2018), pp. 9368–9378.
[20] J. Z. Kim, Z. Lu, S. H. Strogatz, and D. S. Bassett, Con- formational Control of Mechanical Networks, Nat. Phys. 15, 714 (2019).
[21] M. Ruiz-García, A.J. Liu, and E. Katifori, Tuning and Jamming Reduced to Their Minima, Phys. Rev. E 100, 052608 (2019).
[22] J. Kendall, R. Pantone, K. Manickavasagam, Y. Bengio, and B. Scellier, Training End-to-End Analog Neural Networks with Equilibrium Propagation, arXiv:2006.01981.
[23] A. Laborieux, M. Ernoult, B. Scellier, Y. Bengio, J. Grollier, and D. Querlioz, Scaling Equilibrium Propagation to Deep ConvNets by Drastically Reducing Its Gradient Estimator
[24] G. Thimm and E. Fiesler, High-Order and Multilayer Perceptron Initialization, IEEE Trans. Neural Networks 8, 349 (1997).
[25] J. Y. F. Yam and T. W. S. Chow, A Weight Initialization Method for Improving Training Speed in Feedforward Neural Network, Neurocomputing;Variable Star Bulletin 30, 219 (2000).
[26] C. P. Goodrich, A. J. Liu, and S. R. Nagel, The Principle of Independent Bond-Level Response: Tuning by Pruning to Exploit Disorder for Global Behavior, Phys. Rev. Lett. 114, 225501 (2015).
[27] N. Pashine, Local Rules for Fabricating Allosteric Net- works, arXiv:2101.06793.
[28] L. Bottou, Stochastic Learning, Lecture Notes in Computer Science (Springer, Berlin, 2003), pp. 146–168.
[29] Y. LeCun, C. Cortes, and C. J. Burges, The MNIST Data- base of Handwritten Digits, http://yann.lecun.com/exdb/ mnist, 2010.
[30] S. L. Soo and S. K. Tung, Deposition and Entrainment in Pipe Flow of a Suspension, Powder Technol. 6, 283 (1972).
[31] W. S. J. Uijttewaal and R. V. A. Oliemans, Particle Dispersion and Deposition in Direct Numerical and Large Eddy Simu- lations of Vertical Pipe Flows, Phys. Fluids 8, 2590 (1996).
[32] J. Jin, S. Chen, and J. Zhang, UV Aging Behaviour of Ethylene-Vinyl Acetate Copolymers (EVA) with Different Vinyl Acetate Contents, Polymer Degradation Stability 95, 725 (2010).
[33] A. Boubakri, N. Haddar, K. Elleuch, and Y. Bienvenu, Impact of Aging Conditions on Mechanical Properties of Thermoplastic Polyurethane, Mater. Des. 31, 4194 (2010).
[34] A. Holtmaat and K. Svoboda, Experience-Dependent Struc- tural Synaptic Plasticity in the Mammalian Brain, Nat. Rev.
Neurosci. 10, 647 (2009).
[35] N. Yasumatsu, M. Matsuzaki, T. Miyazaki, J. Noguchi, and H. Kasai, Principles of Long-Term Dynamics of Dendritic Spines, J. Neurosci. 28, 13592 (2008).
[36] D. D. Stettler, H. Yamahachi, W. Li, W. Denk, and C. D. Gilbert, Axons and Synaptic Boutons Are Highly Dynamic in Adult Visual Cortex, Neuron 49, 877 (2006).
[37] D. Ratna and J. Karger-Kocsis, Recent Advances in Shape Memory Polymers and Composites: A Review, J. Mater. Sci. 43, 254 (2008).
[38] I. K. Kuder, A. F. Arrieta, W. E. Raither, and P. Ermanni, Variable Stiffness Material and Structural Concepts for Morphing Applications, Prog. Aerosp. Sci. 63, 33 (2013).
[39] M. Ernoult, J. Grollier, D. Querlioz, Y. Bengio, and B. Scellier, Updates of Equilibrium Prop Match Gradients of Backprop through Time in an RNN with Static Input, Adv. Neural Inf.Process.Syst.32,7081(2019),https://proceedings.neurips.cc/paper/2019/file/67974233917cea0e42a49a2fb7eb4cf4-Paper.pdf.
[40] S. Fancher and E. Katifori, Tradeoffs between Energy Efficiency and Mechanical Response in Fluid Flow Networks, arXiv:2102.13197.
[41] B. A. Richards, T. P. Lillicrap, P. Beaudoin, Y. Bengio, R. Bogacz, A. Christensen, C. Clopath, R.P. Costa, A. de Berker, S. Ganguli et al., A Deep Learning Framework for Neuroscience, Nat. Neurosci. 22, 1761 (2019).
[42] M. J. Cipolla, The Cerebral Circulation, Integrated Systems Physiology: From Molecule to Function, 1st ed. (Morgan & Claypool Life Sciences, San Rafael, CA, 2009), pp. 1–59.
[43] Yu.-R. Gao, S. E. Greene, and P. J. Drew, Mechanical Restriction of Intracortical Vessel Dilation by Brain Tissue Sculpts the Hemodynamic Response, NeuroImage 115, 162 (2015).
[44] A. Y. Ng and M. I. Jordan, On Discriminative vs. Generative Classifiers: A Comparison of Logistic Regression and Naive Bayes, Advances in Neural Information Processing Systems (MIT press (Bradford Book), Cambridge, MA, 2002), pp. 841–848.
[45] T. Jebara, Machine Learning: Discriminative and Gener- ative (Springer Science & Business Media, Berlin, 2012), Vol. 755.
[46] C. Parisien, C. H. Anderson, and C. Eliasmith, Solving the Problem of Negative Synaptic Weights in Cortical Models, Neural Comput. 20, 1473 (2008).
[47] M. Hu, J. P. Strachan, Z. Li, E. M. Grafals, N. Davila, C. Graves, S. Lam, N. Ge, J. J. Yang, and R. S. Williams, Dot-Product Engine for Neuromorphic Computing: Pro- gramming 1T1M Crossbar to Accelerate Matrix-Vector Multiplication, in Proceedings of the 53nd ACM/EDAC/ IEEE Design Automation Conference (DAC), 2016 (IEEE, New York, 2016), pp. 1–6.
[48] Z. Wang, C. Li, W. Song, M. Rao, D. Belkin, Y. Li, P. Yan, H. Jiang, P. Lin, M. Hu et al., Reinforcement Learning with Analogue Memristor Arrays, National electronics review 2, 115 (2019).
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

点击“阅读原文”,追踪复杂科学顶刊论文