罗家德:社会计算方法论

导语
本文整理自罗家德2021年6月在集智俱乐部的讲座,介绍了社会计算这一领域的起源和研究范围,讨论了社会计算的方法论问题为何重要,以及怎样从方法论出发展开研究和实践。文本有删减调整,查看完整内容请在文末查看获取视频录播地址。
集智俱乐部「社会计算」系列读书会已经启动招募,多位专家牵头,从计算科学与复杂科学等跨学科视角,探讨社会、经济等领域的问题。本文为读书会成员撰稿。读书会为期10-12周,每周四晚举办,详情见文末。

罗家德 | 讲者
张沛、刘培源 | 整理
邓一雪 | 编辑
1. 社会计算概念的起源
1. 社会计算概念的起源
社会计算(Social Computing)最早的是Schuler在1994年的时候发明的名词,我们就把1994年当做Social Computing元年,合理不合理?这该是大家唯一能取得的共识。否则每个人都会用概念往前推,有的可以推到Social Informatics才是开始,有的说Computational Simulation才是开始,甚至推到计算社会学(Computational Sociology)的社会模拟实验,依Castellani的说法那就可以推到1957年了。

九十年代、零零年代社会计算刚开始的时候定义其实跟今天有一点小小的落差,社会计算在那个时候讲的是什么?社交平台、BBS之类的软件,谈的是groupware, social software, mobile social software这些。这些软件沉积了很多大数据,企业家就很喜欢用大数据做各式各样的应用,所以那时候讲的主要都是怎么去发现一些社会需求,不管是社交需求,还是老板的分析需求。所以研究者会设计一些计算,从数据中发现规律,比如买尿片的顾客有相当的概率也会买啤酒。
后来Lugano指出,王飞跃等人强调了社会计算也该加入对社会现象及社会系统动态的研究。

与此同时,2009年 Science 杂志发表了Computational Social Science(计算社会科学)这篇文章,而且到现在这篇文章都很有名。它很短,正是因为很短,而且写得很简单,所以它更像是一个宣言。它不是一篇论文,是宣言,又发在Science上,所以影响力非常大。Computational Social Science 的概念跟2009年绑定在了一起,不是因为它真的来自于这一年,而是因为2009年是它推广开来的标志性时间。此前它大概至少有10来年的发展,才会有这篇宣言出来。所以,社会计算一方面有社会性增强计算科学的一面,到了今天尤其是从人、社交、社会的理解增强人工智能研究,已不限于social ware,而另一方面也包括了计算科学如何增强我们对人、社交与社会、经济、管理的研究。
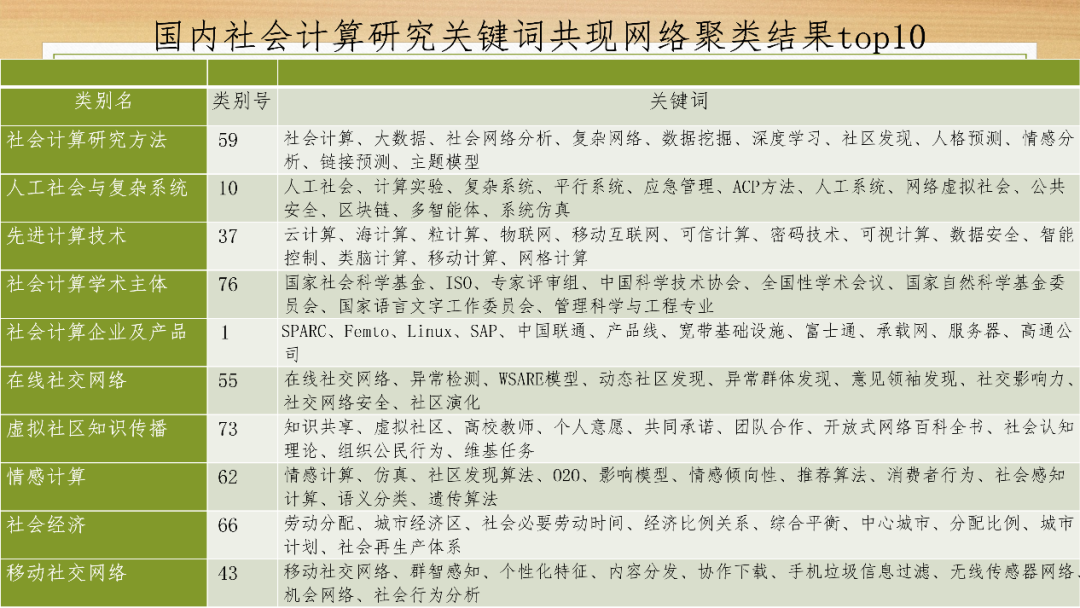
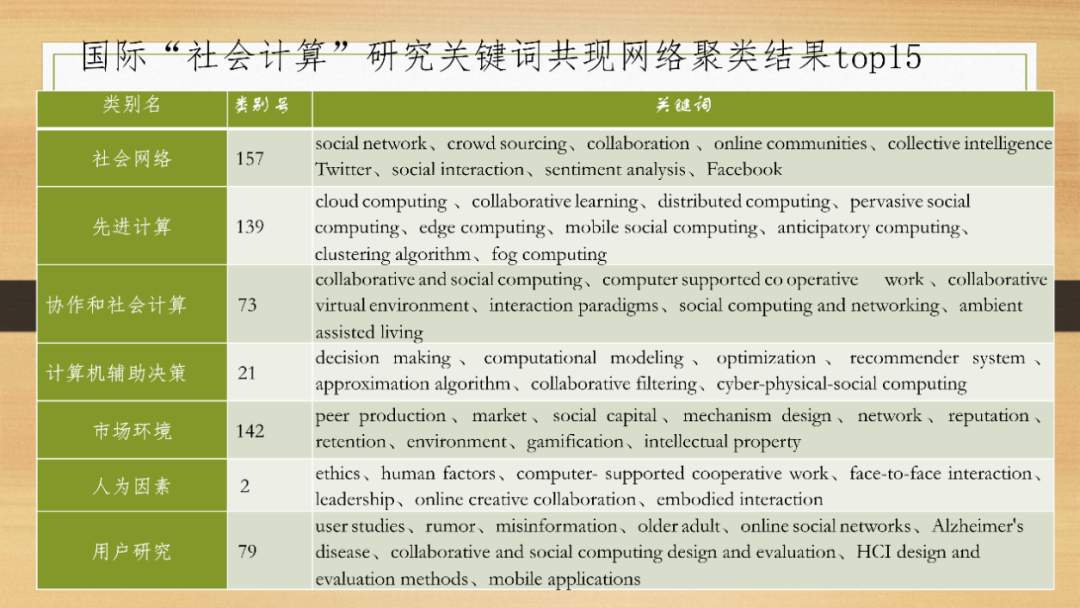
社会计算关注什么呢?浙江大学公共管理学院的黄萃教授,梳理了社会计算相关关键词,结果发现社会计算的概念内涵已经相当广泛,既包括计算的部分,也包括计算社会科学的部分。

为什么我今天谈方法论要从计算科学与社会科学的交互作用谈起?为了社会而有的计算,不管你是为了发展软件,还是发展AI新的技术,都需要知道人、社交与社会的内涵所以从方法论上来讲,它们两者是互补的,互为表里的,此先彼后,此后彼先,循环往复,相互作用的。今天我就从计算如何增强社会研究的这一端讲起。
我们发起了一个英文期刊Journal of Social Computing,编委大概是一半外国人一半中国人,一半文科一半理科组成,关注计算社会科学、复杂社会系统和人机交互等领域的最新研究成果。2020年10月发表了第一期,现在即将要出第三期。

2. 社会计算算什么
2. 社会计算算什么
社会计算最简单概括,就是三种决策与行动加上三张网络。第一个叫做人的行动与决策与人际关系网络。其实这就是Computational Social Science 现在主要在做的工作,这个领域研究最多的主题就是社会网。

第二个是人工智能的「决策」与物联网loT。这里举一个汉服的例子。现在汉服流行什么?汉服有什么最新的设计形式?大家在言谈中表达的更喜欢汉成帝时候的服装,还是汉哀帝时候的服装?看到汉服圈子里大家在讨论这些问题,商家就能立刻来做一些相应的设计,这可能是未来十年内就会发生的场景。
在这个场景中间,AI普及的趋势和电脑普及的趋势是一样的。上世纪40年代刚刚有电脑的时候,只有英美的国防部才有。到60年代,终于有IBM360、370,有一些美国的大公司有。而到了现在,一个快递小哥恐怕都要两台以上电脑(智能手机)。AI在不久之前还只是阿里、腾讯等汇集算法和数据的公司有,而5年10年之后,我们每个人都会有。三五十年之后,每个人手上都有很多AI的应用在我们的智能设备中,就像现在几十个几百个APP在自己手上。
社会计算算什么的第三个是人机交互与人机共构网络。比如说,很多公司里头特别喜欢雇佣清华北大学生,雇来每一个人都是龙,但是凑成一个团队就是猫团队。但是你可能找一些普通高校进来的,结果做成一个团队却是高效团队。这其实是众愚成智还是众智成愚的问题。
这是社会计算和组织行为学都在做的研究:怎么形成一个高效团队,怎么形成一个创新型团队,机器在里头怎么扮演角色,人在里头这样扮演什么角色?人和人之间的关系网络会形成什么样的一个结构网络,最后一群人机互构成网络,一群人机如何协作?如何集体创新?最后形成一个什么样的形态,能够产生1+1>2、N个1加起来大于N的效果?
一方面这是群体决策,是群体智慧群体性的展现。另一方面这又是一个动态演化的过程,1+1>2就包含1+1在一起和它们的网络结构的共同演化,形成所谓的涌现现象,涌现出新智慧、新知识。复杂科学研究的就是这样演化、自组织涌现的系统现象。
看上图黄萃教授作的国际上social computing的主要研究议题,正好可以分成这三类。
3. 社会计算:从方法到方法论
3. 社会计算:从方法到方法论
在做研究的时候,有一种方法就是怎么样把无结构的电子印记数据,转化成将来能用的数据,这就叫做结构化过程。如果你要用Python去写针对自己需求的程序,比如像我的一个朋友唐锡晋教授团队,他们在做舆论极化研究的时候就不会用百度Senta这样的套装软件,而是把一个人回答问题的理性的程度分成10层。他们会重新定义理性程度,然后来看这个人在争论转基因时,是理性的还是不理性的?又比如,图像识别是方法,声音识别是方法,多模态识别也是方法,但只有方法不够,更重要的是解决问题,例如如何用联邦学习算法,竟然可以不侵犯人家隐私去把两笔大数据给整合了。这些都是把无结构电子印迹数据转成能为我们所用的数据的方法。
还有一类方法,就是用这些数据解决我们面对议题的方法,如作预测模型可以用SVM、 随机森林,作聚类、排序可以用的双曲空间,把预测模型的「黑箱」拆出重要解释变量可以用Interpretable AI,如SHAP,作因果模型验证可以作logistic regression,作动态系统模型用ABM、MBM等等。
方法论就是如何组织这些型型色色的方法,共同解决一个研究的问题。
文科有道无术,理科有术无道
国内现在的情况是文理交融得还不太够,真正能够做到文理交融的非常少。经常出现的现象是我找一个工科的学生来一起做研究,他们的问题是手上十八般武艺,方法一大堆,你又会电钻,又会锯子,又会刨子,你可以帮我盖一栋房子么?他却跟我说房子是什么?然后开始跟他讲,你还需要读一个建筑学,跟你讲房子是什么,房子的蓝图要怎么画,蓝图变成房子的过程你要做些什么事。
文科就是特别喜欢做社会性研究的,但往往方法很弱。这不只是学生的问题,很多老师都是一样,他没有处理过大数据,却到处在讲大数据的未来、大数据对社会的影响、大数据怎么改变学术研究。手上一个工具都没有,去跟你讲空中楼阁。或者方法很弱,用的就是一些套装软件,用爬虫爬一些数据,再用Word2Vec, 百度Senta一套,这就好像手上只有个榔头,所以看任何问题,就只好把它描述成钉子。
这是我看到社会计算或者计算社会科学的研究中大概最严重的两个问题。
一个研究是怎么做出来的,它不会是一笔资料出来的,你要整合各种资料。处理资料的技术,而且还不止一个技术,好几个技术要进来,也不是一个方法就完成了。所以你一定十八般武艺都要会。方法学会后,你一定要知道它到底是在那个房子中间的哪一个阶段使用、怎么去定位。这就是方法论的价值。
你怎么样要把这些方法综合起来,最后解决一个我们真正关心的问题,这就叫方法论。
社会计算包括两个面向,一个面向是计算技术怎么被社会性给增强。社会计算的第二个面向,是计算技术怎么去帮助做Social Study和Social Dynamic,社会动态研究和社会研究是因为大数据资料的成熟以及计算技术发展到今天才可以去做一些东西。

社会计算方法论的核心问题
社会计算的方法论核心是什么?既然你要研究社会问题,而Social Study又和大数据与计算技术高度相关,你势必会把你的资料、你的算法和社会现象的预测、解释及理论整合起来。
当你想了解什么是社会,如何用社会研究增强计算技术时,只有预测模型是不够的,对你而言,一定会更好奇的是,买奶粉的还会买啤酒,预测好准,但有没有办法推论?这个现象在中国存不存在?这个现象美国城市存在美国郊区存不存在?那个时代存在,今天还存不存在?不管是数据挖掘出来的是最佳的预测因素(predictors)、行为模式(behavioral patterns)还是预测模型,都是一次探索性的研究,挖掘得到的发现不就是止于此,还该有如下的研究步骤:
-
探索性研究:发现或预测模型(findings or prediction model) 诠释 (interpretation or interpretable AI) 提出解释并与现有理论对话 提出命题(Propositions,可能辅以定性研究)
-
验证性研究:命题构想 从理论演绎 (可能辅以定性研究) 提出假设 (Hypothesis) 研究设计(解释模型指定、变量指定、参数指定以及资料指定) 验证解释模型
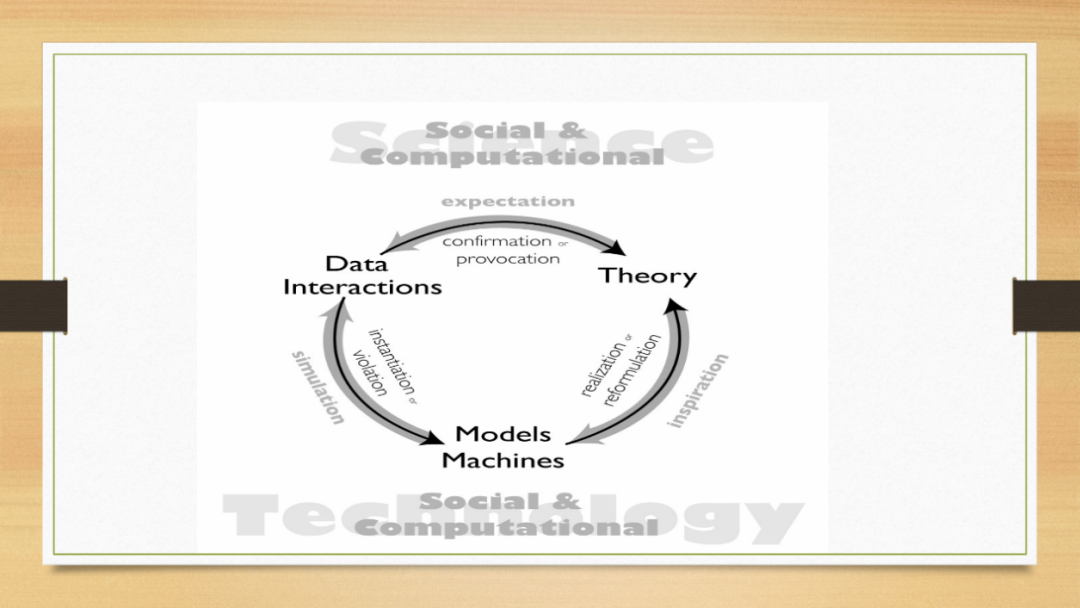
社会计算研究要避免三无
4. 社会计算应用:如何战略性地使用大数据?
4. 社会计算应用:如何战略性地使用大数据?


社会计算系列读书会启动招募
随着大数据的持续积累和数字技术的迭代,社会计算(social computing)这一交叉领域正快速兴起,社交网络分析、自然语言处理、机器学习、系统动力学、多主体建模等技术在这一领域碰撞融合,逐渐挖掘出信息时代社会行为的深层规律。
集智俱乐部以「社会计算」为主题,组织为期10-12周的读书会,多位专家牵头,研读经典和前沿文献,交流激发科研灵感。读书会由王硕老师发起,专家顾问团包括孟小峰、罗家德、王晓、吕鹏、王静远、李勇等多位老师。

详情以及报名方式见:
融合计算科学、社会科学与复杂科学:社会计算系列读书会启动招募
推荐阅读
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











