诺贝尔经济学奖与因果推断

导语
2021年10月11日,美国加州大学伯克利分校(UC Berkeley)经济系教授David Card因其对劳动经济学的突出贡献、美国麻省理工学院(MIT)经济系教授Joshua Angrist和美国斯坦福大学(Stanford)经济系教授Guido Imbens因其对因果关系分析的方法论贡献,共同分享了2021年诺贝尔经济学奖。
诺贝尔奖主页上对三位经济学家的评价是:“他们三人为我们提供了有关劳动力市场的新见解,并且展示了从自然实验可以得到什么样的因果关系。他们的方法已经扩展到其他领域并且彻底改变了实证研究。”[1,2]
北京大学贾金柱研究员和博士生邓宇昊深度解读2021年诺贝尔经济学奖与因果推断。

贾金柱 邓宇昊 | 作者
北京大学公共卫生学院生物统计系 | 来源


一、引言
一、引言
社会科学中的许多重大问题都涉及因果关系。比如,移民如何影响工资和就业水平?教育水平如何影响一个人未来的收入?这些问题很难回答,因为我们没有什么可供比较的数据。我们看不到移民人数减少的另一个世界是什么样的,同样也不知道如果一个人没有继续学业将会发生什么。
发现因果关系的金标准是执行随机化实验。但是在社会科学中,人们几乎不可能实施随机化实验。经济科学奖委员会主席说:“Card对社会核心问题的研究以及Angrist和Imbens的方法论贡献表明,自然实验是丰富的知识来源。他们的研究大大提高了我们回答关键因果问题的能力,这对社会大有裨益。”
从20世纪90年代初的一系列论文开始,David Card就开始使用“自然实验”(natural experiment)来分析劳动经济学中的一些核心问题[3-5]。“自然实验”是一种研究设计,其中分析单元与自然、制度或政策变化引起的随机变化一样。这些关于最低工资、移民影响和教育政策的初步研究挑战了传统智慧,也是新实证研究和理论工作迭代过程的起点。在这些愈发深入的经济学研究进程中,David Card是核心贡献者,通过这项工作,我们对劳动力市场的运作有了更深入的了解。
在20世纪90年代初期,Joshua Angrist和Guido Imbens对评估平均处理作用(Average treatment effect, ATE)做出了根本性贡献[6]。特别是,他们分析了个体受处理影响不同的现实情景,其中个体会自我选择是否遵守自然实验产生的处理分配。Angrist和Imbens表明,即使在这种一般情况下,也有可能在一组最小条件下(并且在许多情况下,在经验上是合理的)估计明确的处理作用——局部平均处理作用(Local average treatment effect, LATE)。他们将经济学中常见的工具变量(IV)框架与统计学中常见的因果推断潜在结果(potential outcome)框架相结合。在此框架内,他们澄清了因果设计中的核心识别假设,并提供了一种直接的方式来研究这些假设的敏感性。
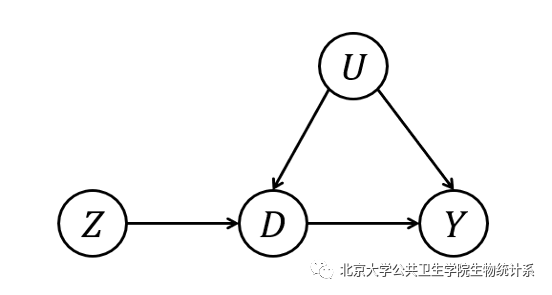
图 工具变量示意图,箭头表示有因果关联
二、什么是工具变量
二、什么是工具变量
为了理解Card研究的经济学问题,我们先简单回顾一下Angrist和Imbens关于局部平均处理作用的工作。该工作建立在潜在结果框架下,该框架最早由Neyman (1923)在随机化实验场景中提出[7],后来Rubin (1974)在观察性数据中也引进了该框架[8]。该框架的核心是如何对处理机制进行描述,即个体如何被分配至处理组或对照组。Neyman采用了随机分配的机制,而Rubin提出了倾向得分的分配机制。虽然工具变量的概念很早就由Wright (1928)提出了[9],但长期以来工具变量的使用一直蕴含于结构方程模型。Angrist和Imbens把工具变量引入到潜在结果框架,将处理的分配机制和工具变量结合在了一起。
下面我们简单概括一下Angrist和Imbens的结论。考虑二值处理,比如完成(或未完成)中学教育。用Di=1代表个体i完成了中学教育,用Di=0代表个体i未完成中学教育。用Yi代表个体i的收入。对于每个个体,他/她有两个潜在结果:Yi(1)和Yi(0)。其个体因果作用是Yi(1)-Yi(0)。但需要注意的是,个体因果作用不可识别,因为一个个体不可能同时接受两个不同的处理,我们无法同时观测到Yi(1)和Yi(0)。人们感兴趣的参数是平均因果作用,即ATE=E[Yi(1)-Yi(0)]。然而,在个体存在异质性和不依从现象时,这个参数也是不可识别的。为了更简洁地表述,下面我们省略角标i。
在研究完成中学教育和收入的关系时,考虑使用出生季度作为工具变量Z。用Z=1代表出生日期在7至12月,Z=0代表出生日期在1至6月。这样选择工具变量是因为,美国的法律规定,公民年满18周岁之后才可以选择退学。因此,1至6月份出生的公民,有更高的概率选择早退学。在潜在结果框架下,每个个体有四个潜在结果Yi(z,d),其中z和d可以取0或1。为了识别平均因果作用或局部平均因果作用,需要引入一些基本的假设。

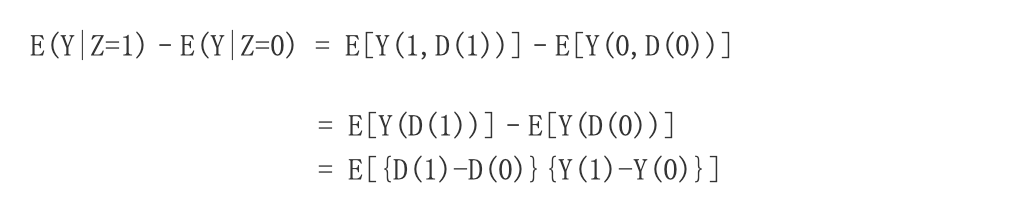
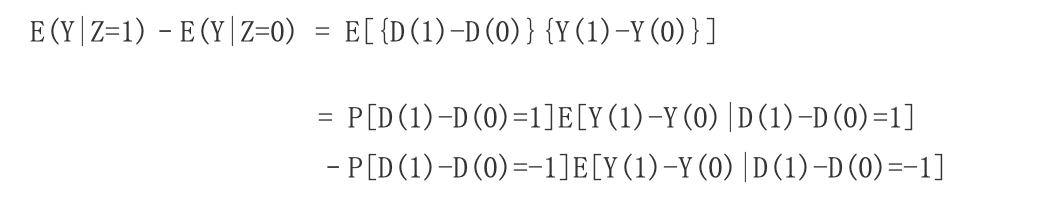
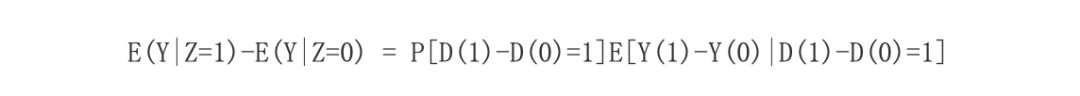
三、实证研究
三、实证研究
(1)完成中学教育对收入的影响
有研究表明,受教育程度和一个人的收入有正向相关关系,如图1所示[10]。
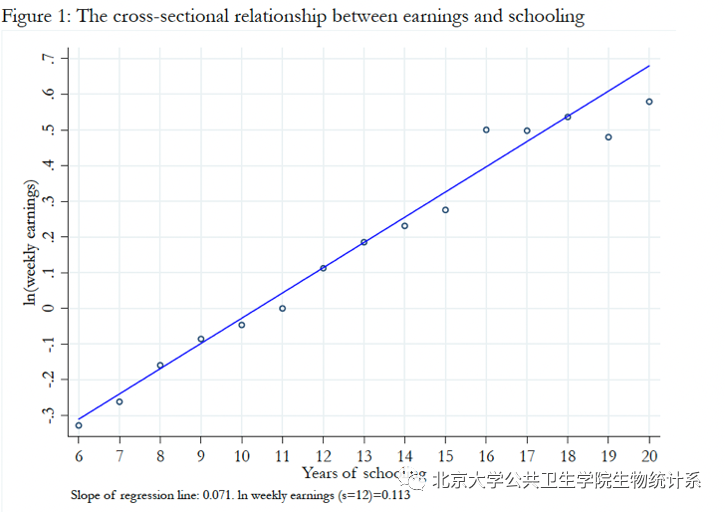
图1:收入和受教育程度。横轴:受教育年限;纵轴:周收入的对数。
但是这种相关关系是否是因果关系?为研究这一问题,Joshua Angrist和Alan Krueger (1991) 注意到生日会影响一个人的受教育年限,但是生日不会直接影响一个人的收入。因此,他们选用生日作为工具变量,研究完成中学教育对收入的影响。下图2展示了出生日期对受教育年限的影响:
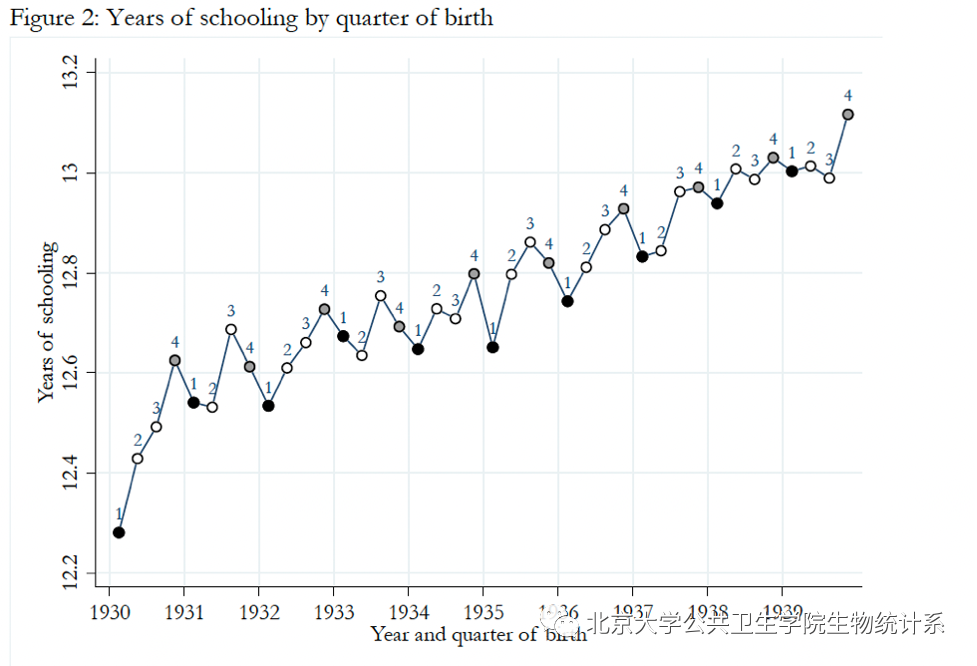
图2:按出生季度划分的受教育年限。横轴:出生年和季度;纵轴:受教育年限。
图中黑色的点代表生日在第一季度,灰色的点代表生日在第四季度。图2表明,受教育年限和出生日期之间存在很强的相关性。下面的图3展示了收入和出生日期之间的关系:
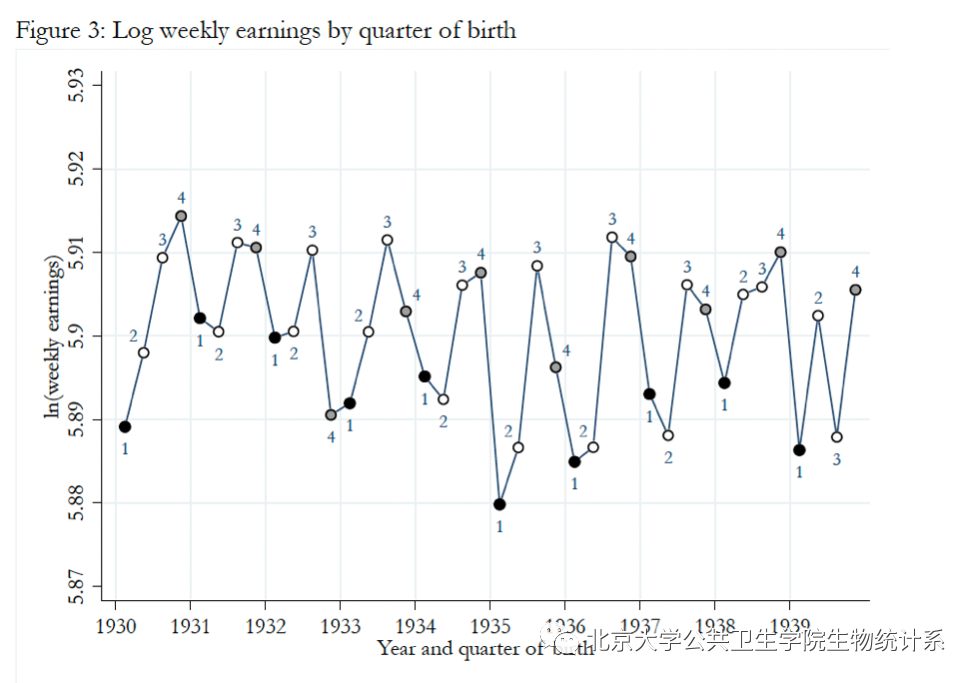
图3:按出生季度划分的收入水平。横轴:出生年和季度;纵轴:周收入的对数。
利用工具变量和潜在结果框架,可以估计出受教育对收入的因果作用大小,为教育政策的制定提供数据支撑。
(2)移民对劳动力市场的影响
在许多国家,移民政策都是一个受广泛讨论的政策。其中一个受广泛关注的原因就是,移民的输入可能会减少国内劳动力的就业机会,并且降低工人的工资。但是,移民的影响是多方面的,研究移民的影响是非常具有挑战性的工作。Joseph Altonji和David Card (1991)注意到移民通常会和老移民住在一起[11]。因此,他们把是否和老移民住在一起这个模式当作工具变量,研究移民对劳动力市场的影响。他们的研究发现移民对当地工资有显著的负面影响,但是对就业没有显著影响。
四、国内因果推断的研究
四、国内因果推断的研究
国内在因果推断方面的研究近些年也如火如荼,特别是周晓华教授加入北京大学后,国内因果推断的力量不断增强。周晓华教授曾和Imbens合作,在工具变量的研究方面取得过重要成果。北京大学的耿直教授及其团队也长期从事因果推断的研究,取得了许多国际前沿的结果。
局部平均处理作用(LATE)不仅在经济领域有着重要的贡献,在流行病学、公共卫生领域也有着重要的应用。周晓华教授等学者注意到,大多数医学研究人员都接受了“随机实验是评估干预措施因果关系的金标准”这一准则,例如,评估旨在改善提供服务、组织、质量、筹资和医疗保健结果的干预措施。但是,实际上,由于各种原因,可能会发生许多违反随机方案的行为,或者没有完全遵守方案规定的试验,同时还可能会发生合并问题,例如因死亡而被截断或使用急救药物。在这种被破坏的随机实验中,常规的估计方法不再完全有效。
周晓华及其团队在这一领域的工作集中在三种违反理想随机方案的行为上:非依从性、被死亡截断、缺失数据。周晓华及其团队已针对这些主题发表了15篇以上的统计论文,这些论文发表在顶级统计期刊上,例如Journal of American Statistical Association(JASA),Journal of Royal Statistical Society Series B(JRSSB)和Biometrika。以下是重要结果的介绍。
(1)非依从性和缺失数据
随机临床试验对于弄清因果关系和因果作用的有效估计很重要。但是,当受试者是患者时,经常会出现非依从性和结局缺失的问题。现有的统计推断方法通常会忽略此类问题,从而导致有偏的估计。周晓华教授和他的前博士生(Taylor and Zhou, 2011, Biostatistics)解决了具有交叉非依从性的随机临床试验问题(例如干预和对照受试者接受新疗法)以及结局缺失的问题,并提出了一种新的多重填补方法[12]。在处理非依从性问题时,多重填补方法相对于现有方法具有多个优点:首先,与极大似然法不同,即使没有单调性和排他性约束的假设,它也可以处理非依从性和缺失结局。其次,在对数据进行多重填补后,可以通过针对完全数据的标准方法来解决非依从性和缺失数据的问题。最后,多重填补方法只需要三到五个填补,估计结果就会非常有效。
周晓华教授、耿直教授及周教授的前博士后研究员(Chen, Geng and Zhou, 2009, Biometrics)解决了随机临床试验具有非依从性和不可忽略缺失时参数的可识别性问题[13]。他们证明了在不可忽略的不同类型的缺失数据下(即缺失机制依赖于结局),当满足某些条件时,感兴趣的因果参数是可识别的。他们还推导出了参数的极大似然估计和矩估计,并在有限样本中分析了它们的性质。由于本文的重要性,它已被Biometrics选为讨论文章。
当研究人员无法将患者随机分配到治疗组和对照组时,通常会使用激励设计。在激励设计中,医生随机地激励患者接受治疗(比如激励患者打疫苗),而不是直接安排患者接受治疗。尽管激励设计在许多情况下是最佳的,但随机激励设计存在一个重要困难——非依从性,即接受激励的患者可以自行放弃治疗。周晓华教授及其合作者建议使用工具变量方法将意向治疗效果与因果作用联系起来,并使用贝叶斯方法进行推断和敏感性分析。在群组激励设计中,随机化反映在群组(例如医生)的级别中,而依从性的分布则反映在群组中个体(例如患者)的级别中。周晓华教授和他的同事(Hirano, Imbens, Rubin and Zhou, 2000, Biostatistics;Frangakis, Rubin, and Zhou, 2002, Biostatistics)提出了重要的新方法和理论,用于分析非群组和群组激励设计中的因果作用[14,15]。由于该方法的重要性,Hirano、Imbens、Rubin和周晓华教授获得了国际贝叶斯统计学会的Mitshell奖,而他们2002年的文章被Biostatistics选为讨论文章,其中一名讨论者是皇家学会会员和世界上最有影响力的统计学家之一D.R.Cox。在对本文的讨论中,Cox提到该文章 “清楚地解决了一个重要问题”。
观察性数据的一大问题是存在未观测到的混杂变量,但同时我们有机会收集到大量协变量。利用高维协变量和观察性数据,在不存在强可忽略性假设的情况下,周晓华教授和合作者提出了异质局部治疗效应的新估计和推断方法,这项研究成果发表在JRSSB上[16]。针对两阶段广义线性模型,给出了非凸目标函数下的Lasso估计,并提出了一种协变量特异治疗效果置信区间的构造方法,这种方法同时纠正了由于两个阶段的高维估计而产生的偏差。
(2)被死亡截断
在多臂随机临床试验中,研究人员通常对治疗效果感兴趣。但是,在实践中,感兴趣的结局变量可能会“被死亡截断”,这意味着感兴趣的结局只有在死亡这一中间结局变量没有发生时才可能被观察到且有意义。换句话说,只能观察到“幸存者”。在这种情况下,感兴趣的治疗效果参数是“永久幸存者”平均因果效应(Survivor average causal effect, SACE)。周晓华教授和他的前博士研究生(Wang, Richardson and Zhou, 2017, JRSSB)创造性地为多臂临床试验中的SACE分析提出了一个全新的框架,而无需较强的可识别性假设[17]。他们在国际上率先提出了三组以上和被死亡截断的多臂随机临床试验的统计方法。此外,他们开发了新的推断方法以检验整体治疗效果,证明了该方法在大样本下的收敛性,并改进了该方法在大样本下的统计理论。
在另一篇论文中(Wang, Richardson and Zhou, 2017, Biometrika),他们还提出了一种在非参数和半参数模型中识别SACE因果参数的方法[18]。他们证明了在部分正则假设下SACE是可识别的。该模型适用于结局为二元或连续变量的情形。同时,他们提出了在违反部分假设的情况下减少估计偏差的统计方法和理论。
(3)替代指标悖论
耿直教授及其团队还研究了因果作用的悖论,即X对变量Y有正的因果作用,Y对Z也有正的因果作用,那么X对Z可能有负的因果作用,该成果发表于JRSSB(Geng, Chen and Jia, 2007, JRSSB)[19]。原文主要研究替代指标悖论,该研究同样适用于工具变量的因果作用估计悖论中。目前的工具变量研究依赖于模型假设,如线性、单调性等。在一般的条件下,也会出现因果作用的悖论。
(4)精准医疗
精准医疗与因果推断有着密切的关系。精准医疗旨在根据患者的特征,选择恰当的治疗方案,达到治疗收益的最大化。但是,同一位患者一次只能接受一种治疗,我们无法同时观察到患者接受不同治疗的结果。用因果推断的语言说,设X表示患者的协变量,Z为治疗方案,可以取Z=0或1,用Y(z)表示患者接受治疗z后的潜在结果。精准医疗却需要根据协变量特异因果作用E[Y(1)-Y(0)|X]选择相应的治疗方案。具体而言,假设潜在结果数值越大表示患者收益越大,那么如果上面的协变量特异因果作用大于0,就选择Z=1,否则选择Z=0。这样,我们可以从理论上把精准医疗转化为因果推断问题。
在最优个性化治疗规则的因果作用估计方面,周晓华教授和他的同事首次提出使用生物标志物调整效应曲线(BATE)、协变量特征的治疗效果曲线(CSTE)来表示给定生物标志物水平下的条件平均处理效应,并为每个病人选择最优治疗方案,同时严格证明了新提出统计方法的数学性质。针对治疗结果为二分类变量时,周晓华和他的同事提出采用B样条方法估计CSTE 曲线,并推导出该方法的大样本数学性质,相关成果发表在JASA上[20]。
5. 展望
因果推断是一个重要的研究领域[21]。许多科学研究的终极目标是区分相关和因果。人工智能、机器学习的快速发展也为因果推断提供了许多挑战和机遇。希望有更多的研究人员加入因果推断的研究,提出因果发现的新方法和新理论。
参考文献
(参考文献可上下滑动查看)
因果科学读书会第三季启动
因果科学读书会第三季启动
读书会大纲一览:
Donald Rubin:Essential Concepts of causal inference
因果推断在观察性研究中的应用(续):ANALYSIS
因果与公平性和可解释性
「深入理论学习」

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











