预训练语言模型如何学习事实性知识?兼论一种因果干预的评估方法

导语
近年来,对预训练语言模型(Pre-trained Language Model, PLM)捕获的事实性知识进行研究成为一种趋势。许多研究显示,PLM 能够在完形填空形式的事实相关问题,如“但丁出生在[MASK]”中,填补缺失的事实词。然而,PLM 如何正确地生成结果仍然是一个谜:依靠有效的线索还是捷径模式?华为诺亚方舟实验室语音语义团队与推荐搜索团队的一项最新研究成果,试图通过一种因果启发的预训练语言模型分析方法来回答这个问题。
研究领域:因果推断,自然语言处理

李少博、李小光、董振华 | 作者
邓一雪 | 编辑

论文题目:
How Pre-trained Language Models Capture Factual Knowledge? A Causal-Inspired Analysis
论文链接: https://arxiv.org/abs/2203.16747
华为诺亚方舟实验室语音语义团队与推荐搜索团队的最新研究成果:因果启发的预训练语言模型分析方法,被2022年ACL Finding录用接收。该研究通过因果干预的方法,分析预训练语言模型能否学习到事实性知识,以及学习过程的内部机理,这是华为第一次将因果推断技术应用于自然语言处理领域的研究,也是我们研究如何构建面向因果关系建模的预训练语言模型的第一步。
Mask Language Modeling(MLM)在被广泛应用于Pre-trained Language Model(PLM)中后,大家一直在积极开展对MLM这一任务的分析。其中LAMA探测了在经由MLM方式的训练后,PLM能否捕获一定量的事实性知识。LAMA要求PLM回答完形填空形式的事实相关问题,例如“电影《普罗米修斯》的导演是[MASK]”,若PLM能够成功地将[MASK]替换为与事实相符的内容“雷德利·斯科特”,则认为PLM成功地捕获了这一条事实性知识。通过构造大量的完形填空式问题,LAMA可以根据PLM回答的正确率,定量地估计PLM所捕获事实性知识数量。
通过LAMA形式的探测,人们发现PLM可以通过在MLM样本上的预训练,来捕获一定数量的事实性知识。这进一步引发了人们对“PLM是如何记住这些事实性知识的?”这一问题的好奇。对此,本文从以下两个方面对这一问题进行了探究:
-
问题1:PLM依赖哪些模式来捕获事实性知识?
-
问题2:PLM所使用的模式是否是有效的?
针对问题1,我们探测了在预训练过程中,上下文中不同类型的词汇对于缺失词汇预测的因果效应,量化展示了PLM在恢复[MASK]时所依赖的模式。针对问题2,我们计算了在捕获事实性知识时,对于不同类型的词汇的依赖大小与LAMA形式的探测表现之间的相关关系。图1展示了上述两部分探测过程。

1. PLM依赖哪些模式来捕获事实性知识?
1. PLM依赖哪些模式来捕获事实性知识?
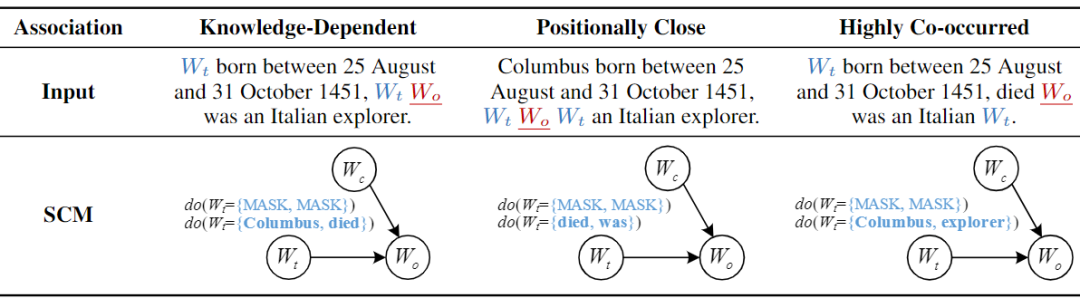
根据与缺失词的关系,我们将上下文中的词划分为三类,分别是与缺失词知识相关的词、缺失词附近的词,以及与缺失词共现频率较高的词,如图2所示。

这样一来,第一个问题被具体化为:PLM在恢复被Masked的事实性词汇时,是更多的依赖于与缺失的词知识相关的词,还是更多的依赖于与缺失词位置相近的词,或是与缺失词共现频率高的词?我们使用Wikipedia构建了的大量的MLM样本,对样本上下文中的词进行扰动并观察PLM预测结果的变化,并得出了经验性的结论:在预测缺失的事实性词汇时,PLM对缺失词附近的词的依赖性最大,其次是对共现频率高的词有较强的依赖,对知识相关的词的依赖则最少。为了方便表述,我们将“与缺失词具有一定的关联关系的上下文词,对缺失词预测的影响”简称为PLM对这一关联(Association)的依赖,与缺失词具有相同关联关系的上下文词,对缺失词的预测影响的平均值,表示了PLM对这一关联的依赖,我们定义了知识相关、附近、高共现三种关联。
表1 PLM在捕获事实性知识时,对上下文中与缺失词具有不同关联的词的依赖情况。
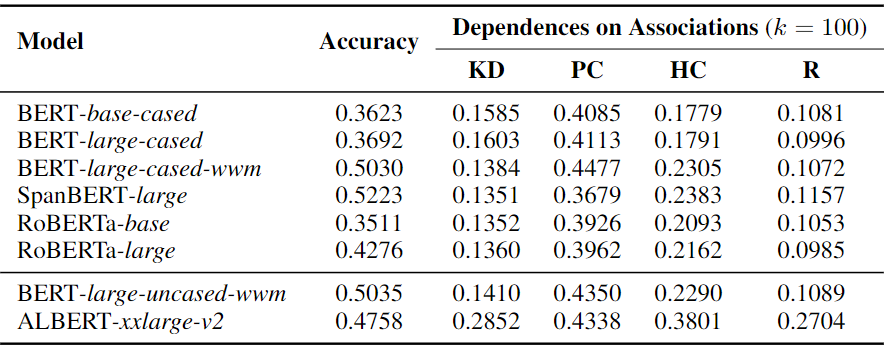
从表1中列举了PLM对不同关联的依赖大小(Dependences on Associations),以及恢复缺失词的准确率(Accuracy),可以看出,尽管不同的PLM预测缺失的事实性词汇的准确率有所差异,但在对关联的依赖上的趋势是一致的,即对附近上下文的依赖(PC)大于对共现上下文的依赖(HC),最小的则是对知识相关上下文(KD)的依赖。R表示PLM对上下文中随机词的依赖。
对依赖大小的估计可以通过将PLM预测缺失词的过程形式化为结构化因果模型(Structured Causal Model,SCM)来实现的,如图3所示。Wo表示缺失词,Wt表示上下文中与Wo具有特定关联的词,Wc表示除Wo和Wt之外的其他词。为了探测Wt对Wo的因果效应大小,我们对Wt进行扰动后,测量Wo预测值的变化。
2. PLM所使用的模式是否有效?
2. PLM所使用的模式是否有效?
现在我们知道,PLM更多依赖于附近的词而非知识相关的词。那么这一依赖是好是坏呢?这同样需要一些定量的证据。为此,对于每一条事实性知识,我们使用LAMA形式的prompts来探测PLM是否成功地将其捕获,作为该条知识的探测性能。根据之前我们得到的,PLM在捕获这条知识时对不同种类的关联(Association)的依赖大小,计算对不同关联的依赖大小与探测性能之间的相关关系。使用这种方法,我们可以得知:在捕获事实性知识时,若PLM对上下文中某一类词的依赖更强,是否有益于事实性知识的捕获,探测结果如图4所示。
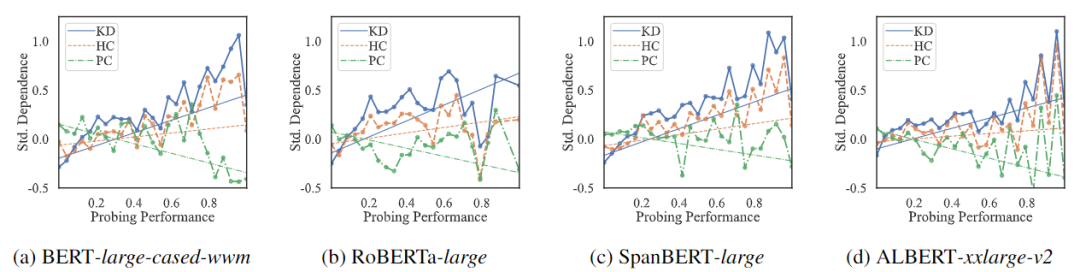
我们可以发现,对知识词的依赖,与事实性知识的探测性能成正相关;对附近词的依赖大小与探测性能负相关;对共现词的依赖于探测性能之间的相关关系则不明显。我们可以将其理解为,PLM在捕获某一条事实性知识时更多的依赖于事实性相关的词汇,则PLM对于该条知识的捕获的越好;反之,若PLM在捕获某一条事实性知识时若更多依赖于附近的词,则对这条知识的捕获则会越差。在探测中,对事实相关的依赖较为高效和有益,而对于附近的词的依赖则是低效或有害的。
结合问题1中的结论,PLM在捕获实时性知识时更多的依赖于附近的词而非知识相关的词,与上面的观察结果相结合,我们可以总结出:PLM在捕获事实性知识时,正在较多的依赖于附近的词这一较为低效的模式,PLM捕获事实性知识的方式并不高明。
3. 一些探讨
3. 一些探讨
PLM能否作为Knowledge Base(KB)?在KB中,知识是通过三元组形式组织的,我们可以通过三元组匹配的方式,来准确地找到缺失的知识,例如根据(subject=电影《普罗米修斯》,predicate=导演),可以准确地得到缺失的object“雷德利·斯科特”。在我们对问题1的探讨中,我们发现PLM并未主要依赖类似方式来捕获知识,而是更多利用附近的词或高共现频率的词。这可能导致PLM无法像KB一样精确的捕获事实类知识,例如,PLM很可能因为另外的演员“劳米·拉佩斯”与“电影《普罗米修斯》”在语料中的共现频率非常高,而在探测过程中错误的将该演员的名字输出。通过基于随机的MLM训练得到PLM所捕获的上下文词之间的关系,很可能与任务所期望的关系之间相差很远,对于在大规模语料上训练完成后,PLM所展现出一些的出乎意料的强大能力,或许我们还需更多角度的探索和分析。
模型应当如何应对上下文中的扰动?当输入发生变化时,模型的预测也会发生相应的改变,那么预测的改变是否是合理的?许多对抗样本方面的研究向我们展示,很多模型对于输入中的噪声是非常敏感的。在本文中,我们展示了PLM在预测缺失的事实性词汇时,对上下文中知识相关词的扰动时较为不敏感的,而对附近的词的依赖非常敏感,而这一不敏感和敏感恰恰对于目前事实知识探测这一任务非常不利。那么,如何让PLM模型掌握对任务有利的输入与输出结果之间的映射关系,强化输入中某一部分特征对于输出的因果效应,这也许是一个非常有趣的问题。
因果科学读书会第三季
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
从推理走向感觉:PNAS研究揭示社交媒体时代的集体语言理性衰落 -
识别时变因果关系:新工具应对因果度量的维数灾难和非平稳性挑战 -
自上而下因果关系特刊:物理、生物、社会中的因果涌现 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











