福利 | 因果推断会是下一个AI热潮吗?Judea Pearl《因果论》重磅上市!

导语
从“大数据时代和机器学习热潮”到“第二次因果革命”,从以数据为中心到数据理解的转变不仅涉及技术上的转变,还意味着更加深刻的范式转换。
因果关系理论与现有机器学习系统的结合,已经开拓了机器学习领域的新思想和新途径。第二次因果革命即将到来?因果推断会是下一个AI热潮吗?一场席卷各个研究领域的“因果革命”正在发生,涉及领域:统计学、基因学、社会科学、经济学、人口学、医疗健康科学、心理学、计算机科学、人工智能科学。
在大数据时代中需要突破“所有知识都来自数据关联”这一框架,亟需因果关系范式融合领域知识、常识约束的问题研究,Judea Pearl 的《因果论》一书就描述了这样一种体系,介绍了因果关系分析和推断的思想和方法。“因果性的研究经历了一次重要的转变:从一个被神秘面纱笼罩的概念转变为一个具有明确语义和逻辑基础的数学对象。”在下一个十年里,这个框架将与现有的机器学习系统相结合,从而可能引发“第二次因果革命”。本书新版近日重新上市,特此推介。

刘礼、杨矫云、廖军、李廉 | 作者
在研究社会演化和自然变化的规律时,我们发现它们与量子现象有着惊人的相似性:根据现有的数据预测未来的状态时会面对各种各样的可能性,但是当我们观察它们的时候——如果能够被观察——就只能看到一种确定的状态,这个状态被称为历史。
尽管如此,人类从具有思想和意识开始就一直执着地、孜孜不倦地探索自然界各种现象之间的关系,试图从当前的状态预测未来可能发生的事情,并且把这样的关系称为因果关系。即使从现在预测未来有着诸多不确定性,但是我们总是在不断完善和修改对于因果关系的理解和表述,希望预测得更加精确和全面。根据现在的物理学观点,在能够被人类自然感知的世界尺度上,对于绝大多数情况,这种预测是可能的。几千年来,人类的科学研究活动可以归结为不断提高根据现有数据预测未来变化的能力。一部人类的文明史或者科学发展史,就是对于这种因果关系不断发现的历史。到目前为止,绝大多数学科都在做因果关系发现的研究。
在人类所建造的科学大厦中,因果关系成为不可或缺的黏结剂,它把错综复杂和五彩缤纷的各种现象整合得井然有序,富有层次性和逻辑性。从宇宙发生大爆炸的那一刻起,由于温度和压力的原因,必然随之产生大量的基本粒子(夸克),由此继续产生中子、质子等次级粒子,并继而产生原子和分子,然后又在各种复杂的环境条件下,沿着因果路径产生我们人类自身以及人类赖以生存的环境和社会,并且继续产生我们的未来。在因果观的思想下,我们今天的一切都是由大爆炸那一刻确定的,而我们的未来又是由今天的状态决定的(包括统计学足以应付的某些不确定性)。由此一来,所有的事物和现象都是在因果规律的支配下,有次序地演化和发展。如果我们能够把握住这种因果规律,以及宇宙最初的状态参数,就能够把握整个宇宙的发展规律。在这种激动人心的思想的照耀下,人类进行了持之以恒的探索,牛顿定律、麦克斯韦方程、爱因斯坦场方程、哈勃定律等,都是其中闪耀着智慧光芒的产物。借助这些结果,我们脱离了对于自然现象和规律的茫然无知,能够与“上帝”进行对话,从而更好地掌握人类自身的命运。“从天而颂之,孰与制天命而用之。”
从任何角度看,通过因果关系来描述和梳理各种自然与社会现象,真是精妙绝伦的思想,但是对于什么是因果,什么是因果关系,却在很长的一段时间内没有清晰的科学论述。例如,就我们的常识经验而言,因果关系具有必然性和不可或缺的性质,即如果现象A是现象B的原因,当A出现时,B必然出现,同时如果A没有出现,则B也不会出现。但是这两条并不能成为因果关系的定义,例如我们常识上认为感染病菌是发烧的原因,但不是每次感染病菌必然引起发烧,甚至这种概率还是比较低的。同时不感染病菌也不见得不发烧(可能由于其他原因引起发烧),因此感染病菌与发烧之间并不符合上面所说的两个条件,但是在我们的常识里还是认为感染病菌与发烧之间有因果关系,它们也的确具有因果关系。这种常识与科学之间的差别在很多领域都出现过,正是这种差别,促使许多科学家对于因果关系的基本性质和科学定义做了大量研究。
最早亚里士多德提出的“四因说”,认为世间万物的变化都源于“形式因”“质料因”“动力因”和“目的因”四种原因,其中“动力因”即“使被动者运动的事物,或者引起变化者变化的事物”,似乎更贴近现在一般所说的原因。但是“四因说”只是从哲学角度概括了事物变化的原因,并没有给出明确的定义,如何识别原因和结果仍然留给了后人。18世纪的休谟被认为是自亚里士多德以来第一个试图对因果关系进行科学定义的哲学家,他从现象与现象的联系中给出有关因果关系的定义:(1)如果A发生,则B必然发生;(2)如果A不发生,则B也不发生;(3)A在B之前发生。这时我们称A和B是因果关系,A是B的原因,这三点倒是很符合对于因果关系的常识性理解。当然,现在看来这三点仍然没有很好地定义因果关系,因为根据这三点可以推出公鸡打鸣是太阳升起的原因。休谟本人最后也对因果关系持怀疑态度,他说:“关于这一联系的观念,当我们努力去构想它时,甚至连究竟想要知道它的什么内容,都没有一个哪怕是模糊的意识。它只不过是思想中的习惯性联想。”但是他对于因果关系探究所持有的科学态度和方法,却启发和激励了后来的学者。
在后续对于因果关系进行艰苦探索的科学家中,我们必须提及高尔顿(Francis Galton)、费歇尔(Ronald Fisher)、内曼(Jerzy Neyman)、格兰杰(Clive W. Granger)、赖辛巴赫(Hans Reichenbach)、麦基(John Mackie)、鲁宾(Donald B. Rubin)、珀尔(Judea Pearl)等。我们在本书中会与他们相遇,进一步了解他们对于因果关系发展所做的贡献。这里我们要专门提到,在科学的发展历程中,有一些著名的科学家对于因果关系表达了怀疑甚至否定的态度,历史上典型的有皮尔逊和罗素。皮尔逊认为因果关系只是关联关系的一个特例,不值得专门研究,他说:“我认为,高尔顿的工作开拓了比因果关系更为广泛的概念,即相关关系,因果关系只是它的一个特例。”罗素则明确否定因果关系,认为因果关系只是一种哲学上的说法而无实际意义,他说:“所有的哲学家都认为因果是基本的科学基石之一,但令人奇怪的是,在现代科学里,因果这个词从来没有出现。我相信,因果性只是一个过时的文物,就像君主体制一样,保留它只是因为没有坏处。”当代的数据科学家迈尔-舍恩伯格(Mayer-SchÖnberger)在他的影响广泛的《大数据时代》一书中写道:“大数据时代需要放弃对于因果关系的渴求,而只需关注相关关系,也就是说,仅需要知道是什么,而不需要知道为什么。这就推翻了自古以来的惯例,而我们做决定和理解现实的最基本方式也将受到挑战。”这些对于因果关系的看法曾经统治学术界,但是现在已不再是主流思想。但无论如何,这些质疑也是推进因果关系研究的动力之一,同样对于因果关系的发展做出了贡献。
按照现在的主流观点,因果关系在现代科学研究中占有中心地位。被称为“巫师”的美国统计学家西尔弗(N. Silver)说过:“在大数据时代,‘有了这么多信息,谁还需要理论’的说法似乎越来越司空见惯,但对预测来说,这样的态度绝对是错误的,尤其是在像经济那样的领域——那里的数据那么杂乱。有了理论或至少关于其根本原因的某种更深入的思考,统计推理就可靠得多。”珀尔也说过:“今天我的观点已经非常不同,现在我认为因果关系是客观世界的现实性和人类理解这种现实性的基本构件,并且认为概率关系只是因果关系的表面现象,而因果关系才是我们理解世界的基础和推动力。”
从历史上看,真正奠定因果关系在科学研究中的中心地位的是随机对照实验的出现。费歇尔对于随机对照实验(RCT)做出了关键性的贡献,使得RCT成为当前因果发现的黄金标准。借助RCT,物理学、生物学和医学等领域产生了诸多的新发现和新成果。但是对于社会科学或人文科学方面,由于伦理、成本和风险等因素,无法进行这样的实验,这一巨大的障碍在几百年来影响了这些学科的深入发展,以至于物理学在现代实证主义的旗帜下高歌猛进时,许多人文社会科学仍然徘徊在“经验主义”的泥沼之中。
这一现象直到20世纪初才开始有所转机,在大量的统计学工作的基础上,人们逐渐认识到,既然人工设计的RCT在许多问题上难以实施,那么为什么不借助自然的力量呢?事实上,我们周围的世界和社会每时每刻都在运动和变化中,这些变化产生了大量数据,这也被看作一种实验,只不过不是人为设计的,而是自然发生的,我们称之为“自然实验”。对照实验和自然实验都会产生大量数据,分别称为“实验数据”与“观察数据”。对照实验和自然实验之间的主要区别是,对照实验可以控制各个因素的取值,因此容易看出其中一个因素对于另一个因素的影响,即所谓因果效应。而自然实验无法实施这样的控制,各个因素之间的相互影响和干扰在所难免,因果效应变得扑朔迷离(在本书中,将这种干扰称为混杂)。由于观察数据数量庞大,处理起来十分复杂,有些要求超过了当时已有的技术能力,因此长期以来人们对于自然实验及其产生的数据缺乏足够的重视。但是随着近些年来人类处理大数据的能力逐步加强,以及机器学习等归纳推断技术的发展,原来横亘在我们面前的这堵墙已经能够跨越了,由此引发了从大数据中发现因果关系的新的研究浪潮。2021年的诺贝尔奖就颁发给了三位在经济学研究中成功应用自然实验数据进行因果发现和分析的科学家(本书中多处提到了他们的工作成果)。
在从自然实验中发现因果关系的征程中,美国数学家内曼于20世纪20年代在实验研究中提出了“潜在结果”的思想,由于研究结果是用波兰文发表的,因此当时并未引起关注。直到20世纪70年代,该思想才被鲁宾再次独立发现,并加以丰富和提升,使之成为当前因果分析的重要模型之一——称为“鲁宾因果模型”或者“潜在结果模型”。其基本内容是,假设因素A和因素B都只有两个状态,为了考察因素A对于因素B的因果效应,在固定其他因素Z的前提下,设置A的两个状态A0、A1,分别计算对于B的状态影响,即计算E(B|A0, Z)=EZ{B(0)}和E(B|A1, Z)=EZ{B(1)},它们的差
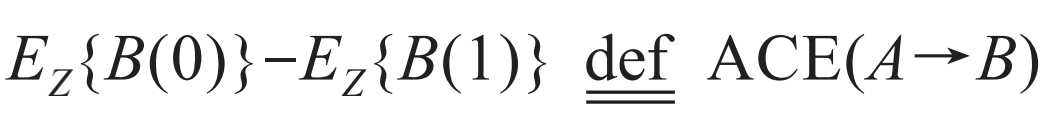
被定义为A对于B的平均因果效应。由于在Z固定的情况下,实际能够观察到的数据要么是A=A0,要么是A=A1,不可能同时观察到两种状态,因此有一个状态是现实中不存在的,是假设的,这个假设状态所引起的B的变化称为“潜在结果”。从历史上看,内曼洞察了自然实验的巨大价值,并且首次尝试用数学语言来描述和定义观察数据中所蕴含的因果关系,比起根据经验和自然语言来定义因果关系,数学语言准确而精细,可以在严格的意义上讨论和比较因果关系,这在因果关系研究中具有划时代的意义。但是数学定义的因果关系总是有些复杂,舍弃了经验因果关系的许多直观的、朴素有效的判别标准,在实际生活中,人们仍然更加愿意使用经验因果关系,而不是数学的因果关系。由追求准确而带来的复杂似乎是不可避免的,但无论如何,由于内曼的天才思想,因果关系得以成为科学的研究对象。当前,如何把经验因果关系纳入数学框架仍然是一个十分具有挑战性的问题,并且受到越来越多的关注。
从20世纪80年代(也许更早一些)开始,珀尔等人利用结构因果图以及do-操作、反事实分析等概念,提出了一种全新的形式化理论,开创了另外一条从观察数据(或者观察数据与实验数据结合)进行因果分析和推断的路线,其中的精彩内容大部分在本书中呈现。新的理论充满了对于因果和因果关系的深邃领悟,将直觉经验、数学描述和形式演算完美结合起来,一层层地揭开了长期以来笼罩在因果关系上的神秘面纱。其中对于各种悖论的解释,以及对于因果效应、反事实推理、隐变量处理、不完美实验、特例原因(或特异原因)等问题的阐述,更加引人入胜。珀尔建立的因果分析与推断框架,数学概念清晰,形式化程度高,易于算法化,在基于算法的各种平台上得到了广泛应用,是当前因果计算领域最重要的理论框架和应用工具。
珀尔的因果分析理论框架是建立在do-操作基础上的,该理论与RCT有着深刻的联系,它们之间可以互相印证,互相转换。该理论简直可以说是RCT的数字孪生,因此具有坚实的理论基础,也得到了学术界的公认。借助这一理论,我们可以通过观察数据来分析和判断因果效应,从而使得原来一些无法进行实验的学科也引入了因果分析,建立了一套严谨和系统的新的研究方法(严格地说,无论是do-操作理论,还是潜在结果理论,我们计算的都是因果效应,而因果关系是基于因果效应的主观判断)。珀尔提出的,同时也得到学术界认可的人工智能的三个阶梯——观察-干预-反思——都可以在这样的理论框架中展开,因此该理论也为人工智能的发展提供了强大的武器。另一方面,珀尔本人证明了该理论与潜在结果理论是等价的,这样一来,原本从两个不同路线和观点发展起来的因果理论竟然具有内涵同一性和本原一致性。这就进一步肯定了该理论的普适性和可信任性,尽管该理论仍然受到直觉主义者的批评。
现在我们回顾一下珀尔对于因果分析和推断的一些基本观点,这些观点可以在书中看到,但是在这里集中阐述一下很有必要,因为这些观点代表了珀尔关于因果论的基本看法。在阅读本书的过程中,透过错综复杂的数学公式,理解其中的思想是十分必要的,思想性永远是数学的灵魂。珀尔的基本观点包括(但不限于):
1. “因果以及相关的概念(例如随机化、混杂、干预等)不是统计概念。”这是贯穿珀尔因果分析和演算思想的一条基本原理,称为第一原理。用一句简单的话来描述两者的差别,那就是“统计学研究变量与变量之间分布的静态性质,而因果分析研究动态性质”。珀尔多次强调,在统计学中,我们从数据中研究和估算各种分布以及它们的参数,而在因果分析中,我们研究当一个变量的分布发生变化时如何影响其他变量的分布。这里所说的变量的分布变化,即本书中提到的do-操作。do-操作是一种对于数据的主动干预,在传统的统计学中甚至找不到对它的描述,这是珀尔为定义因果关系而创建的一种操作,借助这一概念,可以很好地定义什么是变量之间的因果效应。例如在决策理论中,决策是一种对于现有状态的主动干预,已知当前环境Z,确定拟采取决策X,预测结果Y。这个情况写成数学公式P(Y|do(X), Z),而不是P(Y|X, Z)。前一个公式表示决策前的环境Z,当实施决策X之后,Y的概率。后一个公式表示在决策X与实施后的环境Z共存的情况下,Y的概率,这个共存环境与决策前的环境可能不一样。统计分析是观察,看到了什么(所谓的seeing),并估计会发生什么。因果分析是干预,做了什么(所谓的doing),并预测会发生什么。这就清楚地表明了统计分析与因果分析的不同之处。
2. “在任何因果结论背后一定有某种未经检验的因果假定。”从数据中进行因果分析需要一些事先的假定,以减少变量之间关联的可能数量,揭示出真正的因果关系。从数学角度看,这种假定在数据中往往表现为一些变量之间的独立性,或者条件独立性(甚至任何假定都是如此),例如,“吃药不会改变性别”“未来的状态只与当前状态有关,而与过去的状态无关”等。一般来说,这些假定需要具有合理性,包括所收集的数据支持、常识能够接受、足够简单和直观,可能还有其他一些要求。统计学中的贝叶斯主义也讲先验假设,但并不太看重,只要给定充分多的样本和足够细致的测量,原则上先验假设是可以检验并随之修改的。但是因果分析的假定所需要的数据支持却与数据数量无关,这一点与先验假设有很大的不同。在因果分析中,一个(或一组)合理的假定会推断出相应的因果关系,如果不同意这个假定,自然也就否认因果关系成立。不同的假定会得到不同的因果结论,当然,越是简单和直观的假定,越有可能推出符合实际问题的因果结论。所以,只有数据本身是做不了因果分析的,还需要知道数据生成的过程(即数据的语义),才能做出合理的假定。我们在本书中可以读到一些常用的假定,例如“共因原则”(CCP)、“独立因果机制原则”(ICMP)、“个体处理结果不变假定”(SUTVA)等,这些原则和假定与具体的计算方法一起,组成了因果分析和推断的基础架构。
3. “反事实是在最邻近世界中的替换操作。”根据珀尔的定义,如果在现实世界Z实施了操作do(X=x0),结果是P(Y=yi|do(X=x0), Z),若改为反事实操作do(X=x1),即做了替换操作,则得到的结果应该是P(Y=yi|do(X=x1), Z*)。其中Z*是假设世界,在Z*与Z中,所有不受X影响的变量都取相同的值,Z*称为与Z最邻近的世界。以前也有过各种关于反事实的定义,但是大多数的含义是模糊的或者难以识别的,没有严格区分现实世界与假设世界的异同。例如有些定义将反事实放在另一个更一般的世界中,这可能有违反事实概念的初衷。有些定义用自然语言描述,无法转化为数学公式,从而难以具体计算。而珀尔的定义则语义明确,在很多情况下,易于在计算机上进行运算。更重要的是,该定义与我们的常识较为吻合,有利于与现有的知识体系结合。反事实在日常生活和科学论述中大量出现。尽管珀尔对于反事实的定义仍然是一种约定,但这却是目前关于反事实推断的最清晰、涵盖面最广以及最便于在实际中应用的概念。
朱迪亚·珀尔是加州大学洛杉矶分校计算机科学和统计学教授,美国国家工程院院士,美国国家科学院院士,IEEE智能系统名人堂第一批10位入选者之一。他被誉为“贝叶斯网络之父”,获得过多项科学荣誉,包括计算机领域的图灵奖、认知科学领域的鲁梅哈特奖、物理学及技术领域的富兰克林奖章以及科学哲学领域的拉卡托斯奖,以奖励他在人工智能领域的基础性贡献。他提出的概率和因果性推理演算法彻底改变了人工智能最初基于规则和逻辑的方向。

现在我们手里的这本书,就是介绍珀尔有关因果和因果关系的研究成果,全面反映了当前对于因果分析和推断的最新认知。本书第1版写于2000年,开创了因果分析和推断的新思想和新方法,一经出版就受到广泛好评,促进了数据科学、人工智能、机器学习、因果分析等领域新的革命,在学术界产生了很大的影响。应广大读者的要求,珀尔又于2009年修订出版了第2版,内容上结合当时因果研究的新发展,做了较大的改动,同时增加了第11章,专门介绍了一些具有普遍性的问题,包括给读者的回应、答复和解释。
本书主要面向统计学、计算机科学、人工智能、哲学、认知科学,以及卫生和社会科学的读者,提供了系统化的因果分析理论和方法。在介绍因果推断基本概念及相关数学内容的基础上,本书使用do-操作很好地定义和解释了因果关系的深刻内涵,对于反事实分析,本书提出了独特的观点,发展了一套逻辑严密、便于计算的方法体系,并在解释一些传统的经典问题(包括一些悖论)上有很好的表现。本书重点讨论了如何从观察数据(观察数据与实验数据的结合,或者数据与知识的组合)中发现因果关系,如何预测行动和决策的影响,如何处理隐变量和未知干扰,如何描述、分析和计算反事实,以及因果分析技术在不完美实验、实际原因、法律责任、特例事件等问题中的应用。
在本书出版之际,我们的想法与珀尔一样,希望能够吸引更多的读者积极参与因果分析和推断的研究,进一步推进即将到来的统计学、计算机科学、人工智能以及相关领域的新的革命。
* 本文节选自译者序。
(目录可上下滑动查看)

第二次因果革命即将到来?因果推断会是下一个AI热潮吗?你怎么看?
课程推荐:集智俱乐部×重庆大学
因果科学暑期学校
本课程主要根据 Judea Pearl 的两本著作 Causal inference in statistics, a primer 和 Causality: model, reasoning, and inference,由这两本著作的翻译团队(刘礼、杨矫云、廖军、李廉)作为主讲老师进行全面讲解,同时邀请国内多位因果学习的专家学者进行特邀专题报告。
课程采用AB课程制,注重理论与实操相融合,基础理论知识与最新研究进展相交叉,全面系统讲授、研讨因果科学相关主题,对当前因果科学与机器学习结合的前沿技术与行业落地实践进行系统性介绍,从而更好地解决经济学、生物医学、互联网、数据分析、人工智能等实际应用问题,为国内教育界、科研界以及企业界输送更多年轻优秀的从事多学科交叉研究的人才。欢迎感兴趣的朋友报名参与。
课程详情与报名方式请参考:
集智俱乐部×重庆大学因果科学暑期学校:基础+前沿+实践一站习得

扫描上方二维码直接报名课程
推荐阅读
-
Erik Hoel:因果涌现理论怎样连通复杂系统的宏观与微观 -
量化涌现:信息论方法识别多变量数据中的因果涌现 -
因果推断在医药图像的应用:数据缺失和数据不匹配 -
大数据因果推断:数据驱动式学习下的因果混淆去偏算法 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,进入课程
微信扫一扫,分享到朋友圈











