在应对新冠疫情过程中,防控策略及其变化与公众情绪之间形成了复杂的动态关系,而政策调整经常滞后于公众情绪。近日来自新加坡国立大学的研究者,基于疫情期间新加坡社交媒体24万条帖子,提出了数据驱动的公众情绪识别方法,进而能够接近实时地评估舆情对政策的反应。该研究5月在线发表于PNAS,本文是对该研究的解读。
集智俱乐部组织的「计算社会科学读书会」已经启动报名,将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会6月18日开始,持续8-10周,详情见文末。
研究领域:计算社会科学,社交媒体大数据,NLP,机器学习

刘志航 | 作者
梁金 | 审校
邓一雪 | 编辑

论文题目:
Determining containment policy impacts on public sentiment during the pandemic using social media data
https://www.pnas.org/doi/10.1073/pnas.2117292119
自2020年1月以来,全球各国政府一直在使用各种政策工具遏制新冠传播。从封控到各个阶段社会和经济活动缓慢恢复,政府不断设计和实施政策,由此产生不同影响。其中,遏制和封控政策是一种最常见的政策工具,包括了居家令、社交距离要求、关闭学校、工作场所和娱乐场所,以及出行限制等。虽然遏制政策通常能有效减少新冠病毒的传播,但对人们的精神和心理健康会产生重大不利影响,实时评估这些影响对于在快速变化的疫情中进行循证决策很有价值。
通过对社交媒体数据的情绪分析,可以帮助决策者辨别人们的情绪和担忧,从而提高对政策影响的理解。最近发表于PNAS的文章,使用2020年1月至11月期间来自公共 Facebook 群组的约240,000条帖子的高频数据,研究了遏制政策实施后平均每日情绪和公众关注的变化。自然语言处理技术(NLP)能够解析社交媒体上表达的公众情绪和关注的问题,以及它们随政策变化的变化,为新冠疫情防控和治理提供了一种强大、可扩展的实时分析工具。
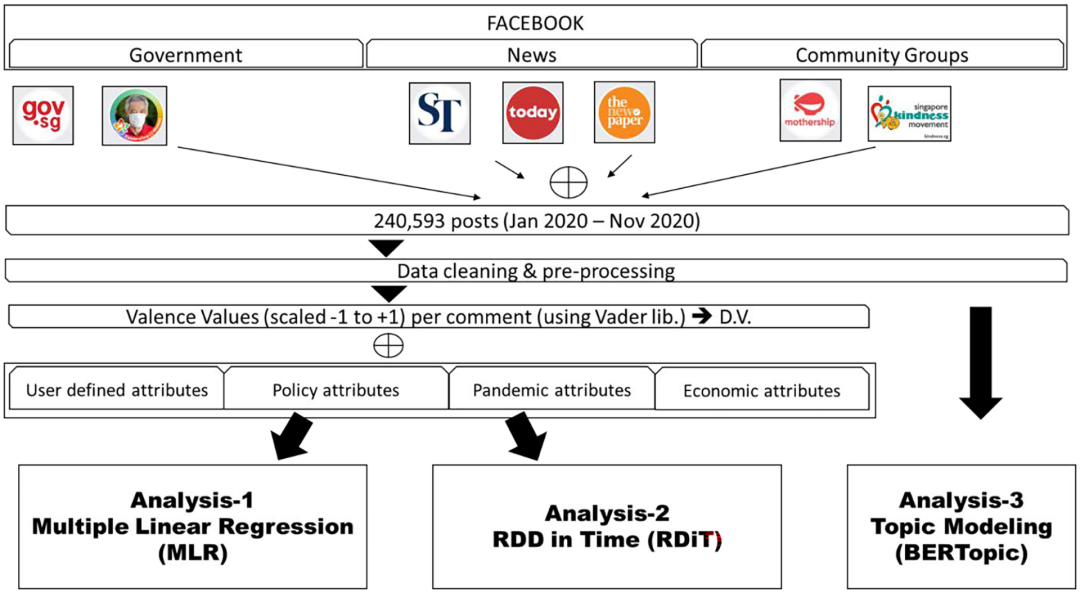
如图1所示,作者收集了新加坡的政府、新闻和社区团体中关注度最高的公共 Facebook 页面的用户帖子,进行文本清理和预处理,然后使用 NLP 工具从文本中计算情绪得分,以获得每日平均公众情绪因变量,自变量是政策施行经过的天数。
图1. 政策影响研究方法:数据收集、清理、预处理和分析。
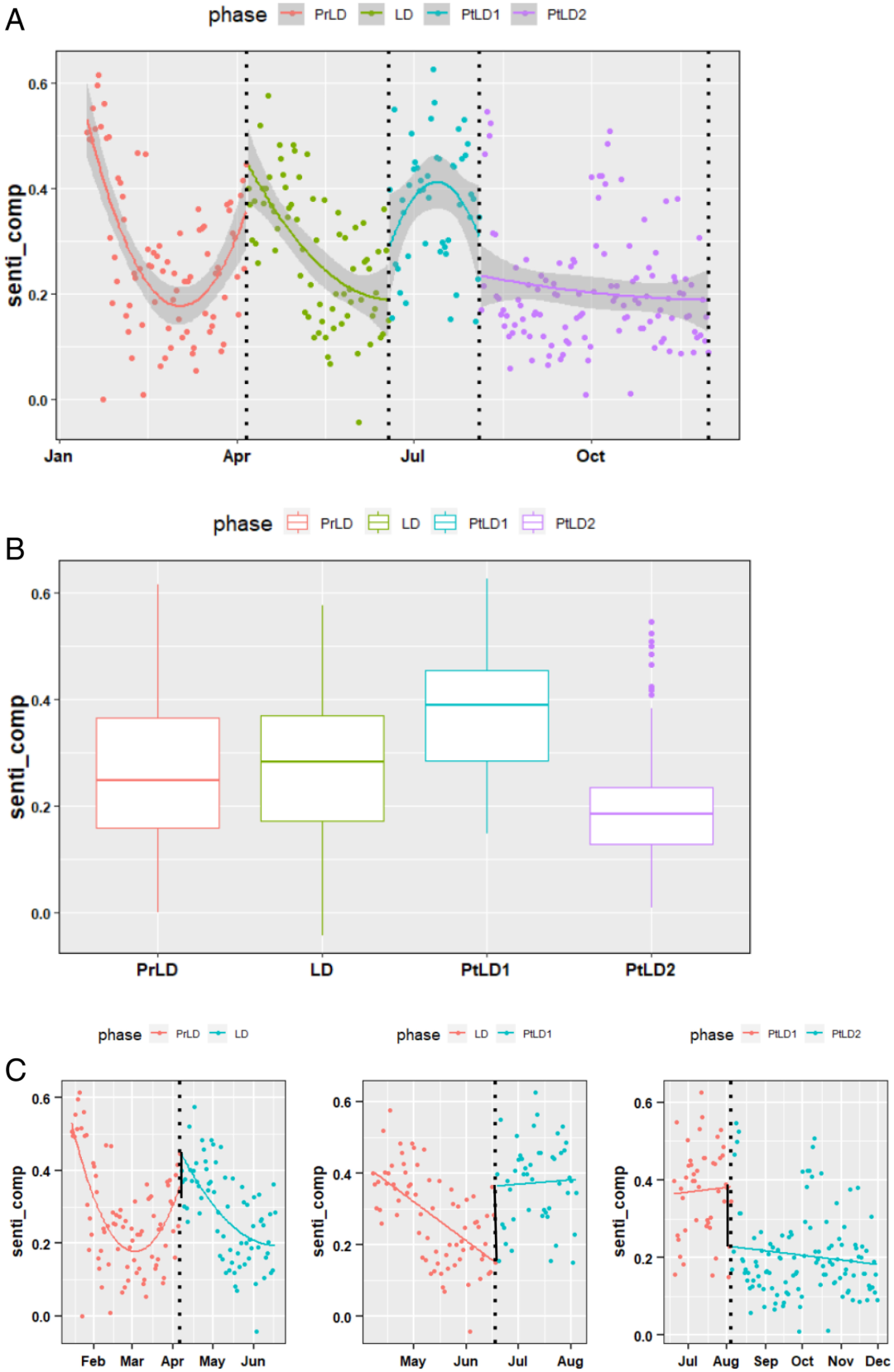
新加坡的疫情防控政策可以分为四个阶段:第一阶段是预封控(PrLD,2020年1月15日至4月6日)。随后是封控(LD) 阶段(2020 年 4 月 7 日至 6 月 1 日),当时办公室、学校、商店和休闲场所都被关闭,只允许提供基本服务。最后是封锁期,分为两个阶段,即最初重新开放时期(PtLD1,2020年6月2日至8月3日)和进一步放宽时期(PtLD2,2020年8月4日至11月30日),允许更大的社交聚会。
考虑可能影响公众情绪的外部因素,作者控制了医疗保健、遏制和封控、经济和其他相关的政策指标,还有每日新病例数、死亡人数和感染率等疫情指标,以及零售指数、消费者价格指数(CPI)、失业率和通货膨胀率等经济指标。通过多元回归(MLR)分析发现,封控阶段与公众情绪呈现负面关系,可能是因为该阶段的出行和公共活动受到限制。但是该阶段收入支持的经济政策和佩戴口罩政策与情绪呈现正向关系,表明公众对政府的经济刺激和口罩健康政策的积极反应。
作者进一步使用断点回归(RDD)分析,以确定每个阶段变化对情绪的因果影响。从图2可以观察到,中值情绪值(senti_comp)随着这些遏制政策措施/阶段而发生变化,并且在每阶段过渡初期出现了明显的不连续值。
图2. 从Facebook帖子中计算得出的随时间(经过的天数)情绪值变化曲线。
新加坡2020年4月7日实施的封控政策使平均每日情绪增加了0.1个单位,这表明人们对该政策的反应是积极的。然后,在2020年6月2日部分解除锁定后,平均情绪值再次显著上升0.2个单位。但在8月4日之后,尽管限制进一步放宽,情绪值却显著下降0.15个单位,这似乎是违反直觉的。这可能是由于对失业的担忧、对感染的持续恐惧以及当时对外出就餐的限制所导致。因此,为了进一步分析这种变化的原因,需要使用自然语言处理技术对不同阶段的公众关注点进行主题归因。
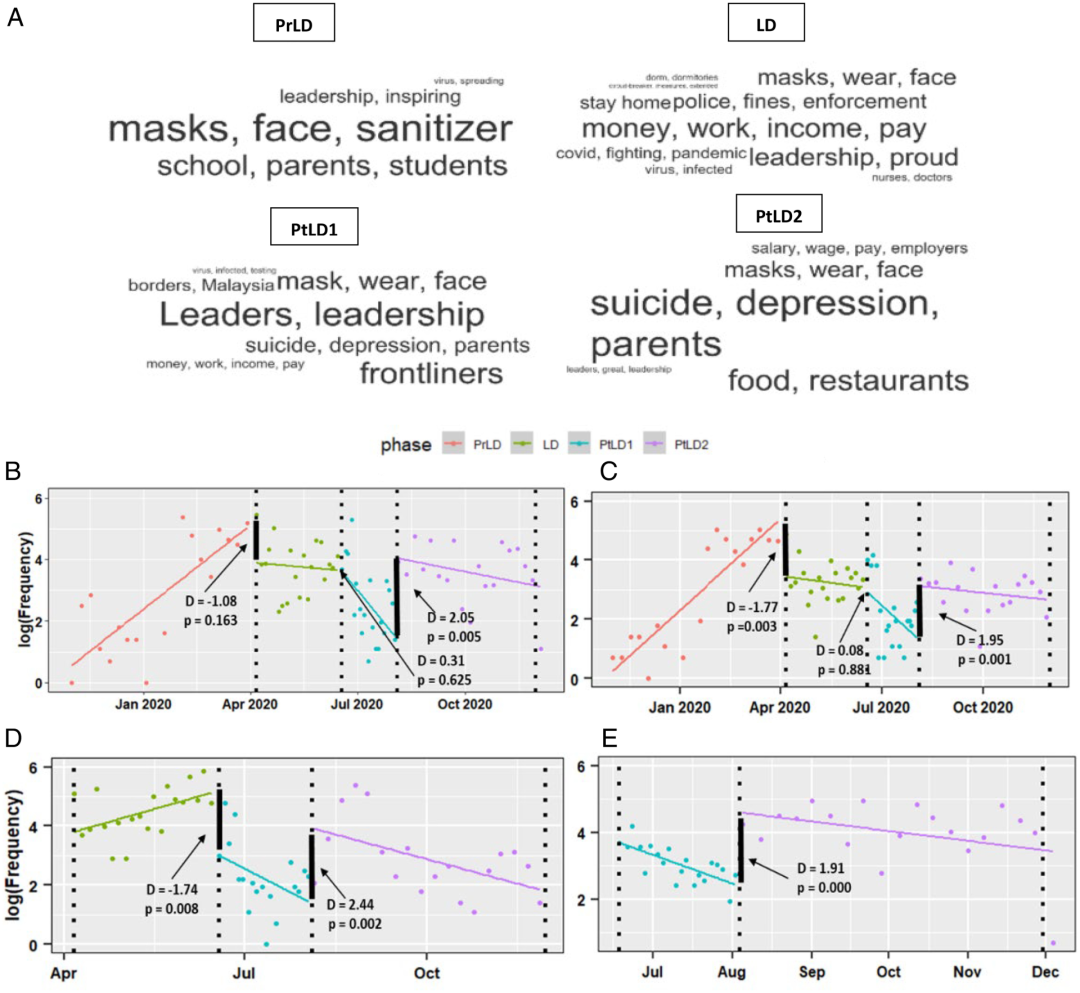
使用自然语言处理中的双向编码器表示模型(BERT),作者归纳了不同阶段公众的突出关注点。首先,病毒感染和戴口罩是贯穿四个阶段的话题(图3B、C)。在预封控阶段,人们关注的主题主要是口罩短缺和学校关闭问题;但在封控阶段,人们首要关心的问题是工资和工作问题(图3D)。这种担忧首先在这一阶段浮出水面,然后在最初重新开放时下降了1.7个单位,但在进一步放宽时期再次上升了2.4个单位,这可能是造成这一阶段情绪显著下降的原因。这种担忧反映了人们对失业的恐惧,以及在受疫情影响的经济中无法找到新工作的恐惧。
图3. 使用 BERTopic 模型进行主题建模。(A)不同阶段的主题,按主题频率大小进行词云可视化。(B)口罩担忧的变化(需要戴口罩和口罩短缺)。(C)病毒感染担忧的变化(包括害怕感染 COVID-19 病毒和接种疫苗)。(D)工资和工作担忧的变化(包括担心失去工作和在 新冠大流行期间难以找到新工作)是封控期间的主要话题。(E)自杀和抑郁的话题,这是封控之后出现的话题。
出人意料的是,在政府宣布重新放开政策后,出现了自杀和抑郁的话题,这可能表明人们对疫情的严重程度/持续时间以及接下来会发生什么感到焦虑和沮丧。在最终进一步放开阶段,对抑郁症的担忧进一步增加了1.91个单位(图3E)。这样的增长说明人们可能需要政策制定者提供更多心理咨询、信息和保证,以了解接下来会发生什么。
值得注意的是,在这四个阶段中,领导力、自豪感和钦佩性的话题都很突出。总体而言,公众对政府领导层的看法是积极的,对领导层对疫情的处理表示钦佩。新加坡因其有效的流行病管理政策和低死亡率而获得全球认可,这可能会进一步加强公众自豪感。
总而言之,通过计算社会科学相关方法,能够确定不同政策阶段突出的公众关注点,并计算出跨阶段边界关注点的重大变化。这种公众情绪实时分析技术能够为政策制定者提供在存在多个协变量的情况下,其遏制政策影响的丰富信息,有助于政策修订以改善公众情绪,并在未来实施类似政策。
这种方法的一个直接实际优势是,当政府机构开始看到负面公众情绪或担忧水平上升时,在限制性遏制和关闭政策不可避免的情况下,政府机构可以计划适当的干预措施,如对小企业提供资金支持,对公众提供心理咨询等。
值得注意的是,社交媒体上反映的情绪可能无法完全代表人群。新加坡的高互联网普及率(88.5%)和 Facebook 等社交媒体的广泛使用(82%)一定程度上缓解了这个问题。但对于无法使用社交媒体发声的农民、外来劳工以及老人等边缘群体,这种技术是有偏的。因此,需要结合其他数据来源进行补充,才能完善出一种以人为本、数据驱动和基于证据的方法,用于微调现有政策并在未来实施类似政策。
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
新一季【计算社会科学读书会】由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动
点击“阅读原文”,报名读书会