文本作为数据技术具有广阔的应用前景,我们能够从收集的大量文本数据中归纳发现对社会科学的理论研究有用的措施。文本是复杂的高维对象,因此,研究人员必须为文本找到更简单、更低维度的表征,以便在科学分析中使用。几乎所有基于文本的因果推理都依赖于文本的潜在表征,但近日发表于 Science Advances 的最新研究表明,从数据中估计这种潜在表征会产生未被认识到的风险。为了解决这些风险,该研究引入一个分离样本的工作流程,用已发现的措施作为干预或结果进行严格的因果推断;并应用它来估计一个移民态度实验和一项官僚反馈研究中的因果效应。本文翻译自 Science Advances 对这篇论文的评论文章。
Dhanya Srudhar, David M. Blei | 作者
郭瑞东 | 译者
邓一雪 | 编辑

论文题目:
How to make causal inferences using texts
https://www.science.org/doi/10.1126/sciadv.abg2652
因果科学关注的是,如何基于一个假设的干预推断其影响 [1-4]。假设我们是临床医生,决定是否使用一种新药来帮助病人从疾病中恢复。为了做出决定,我们要问:如果我们干预并给患者药物,与如果我们干预并阻止他们服用药物,恢复率有什么区别?
因果推断是关于如何分析数据(以评价因果性),例如,患者是否服用药物和他们是否康复之间的关系。为了能够估计因果效应,我们必须对数据收集做出什么假设?如果这些假设成立,什么是分析数据的适当方法?因果推断的根本挑战在于,我们永远无法观察病人服药和不服药时发生了什么。这一关键事实将因果推断与传统统计学区分开来。
在因果推断中,干预和结果通常是简单的变量,比如病人是否服用药物,病人是否康复。但是在社会科学中,许多因果推断问题涉及到语言,而语言是一种相当复杂的变量类型。候选人演讲的内容如何影响选举结果?向某人展示广告会如何影响他们对产品的评价?分析文本数据来回答这类因果问题是 Egami 等人 [5] 的文章中提到的问题。
在这期 Science Advances 杂志上,作者正式阐述了从文本中进行因果推断意味着什么。文本可以是“干预”,比如候选人的演讲,也可以是“结果”,比如开放式调查回复。(第三种情况,即文本混淆了因果推理,是我们自己的一些工作的主题 [6]。)
文本因果推断的主要问题在于,大多数文本数据分析都涉及到编码,这是一种将文档归纳为一组更简单的标签、属性或主题的方法。编码可以作为数据收集的一部分手动生成,例如要求分析人员阅读演讲稿并记录每个人交流的意识形态。编码也可能是使用机器学习方法自动生成的。例如,数据分析师可能会选择一个适当的主题模型 [7] ,以发现不同文本间的潜在主题,然后使用拟合的模型来表征模型遇到的每个文本的主题。
在考虑这个问题时,Egami 等人的一个关键见解是,当我们在一个因果关系的场景下分析文本数据时,感兴趣的推断往往是关于文本的潜在编码。演讲中传达的意识形态如何影响选举结果?看到广告如何影响调查回复中讨论的主题?
因此,Egami 等人仔细考虑编码的构造如何与支撑因果推理的假设相互作用。他们的主要观点是:无论你如何编码文本ーー无论是手工编码还是使用算法编码ーー使用数据分割(data splitting)都很重要。为了防止下游因果估计中的基本问题,应该使用与估计因果效应不同的数据子集来构造编码函数。
除了这个重要的标准之外,在选择编码时还需要考虑哪些因素?我们应该在用于因果推理的文本代码中寻找什么?受 Egami 等人开发的框架的启发,我们进一步研究了编码与文本之间的不同关系。这些思维方式为进一步研究文本因果推理提供了新的思路和方法。
在最简单的情况下,文本就是结果。干预导致文本,而文本与编码相关(或导致编码)。在这里,不管编码是什么,关于干预对编码的影响的因果推断是有意义的。尽管如此,并非所有的编码都是平等的ーー有些编码可能会受到干预的影响,有些则不会。一个有趣的研究问题是,如何找到一个编码,使其存在可观察的因果效应。
在 Egami 等人的例子中,数据来自于一个关于移民的开放式调查。干预涉及移民的犯罪历史信息,结果是反馈者认为可能发生在移民身上的事情的文字描述。我们感兴趣的是不同干预(历史)如何影响调查结果的某些方面。一个好的编码可以捕捉到这些方面。
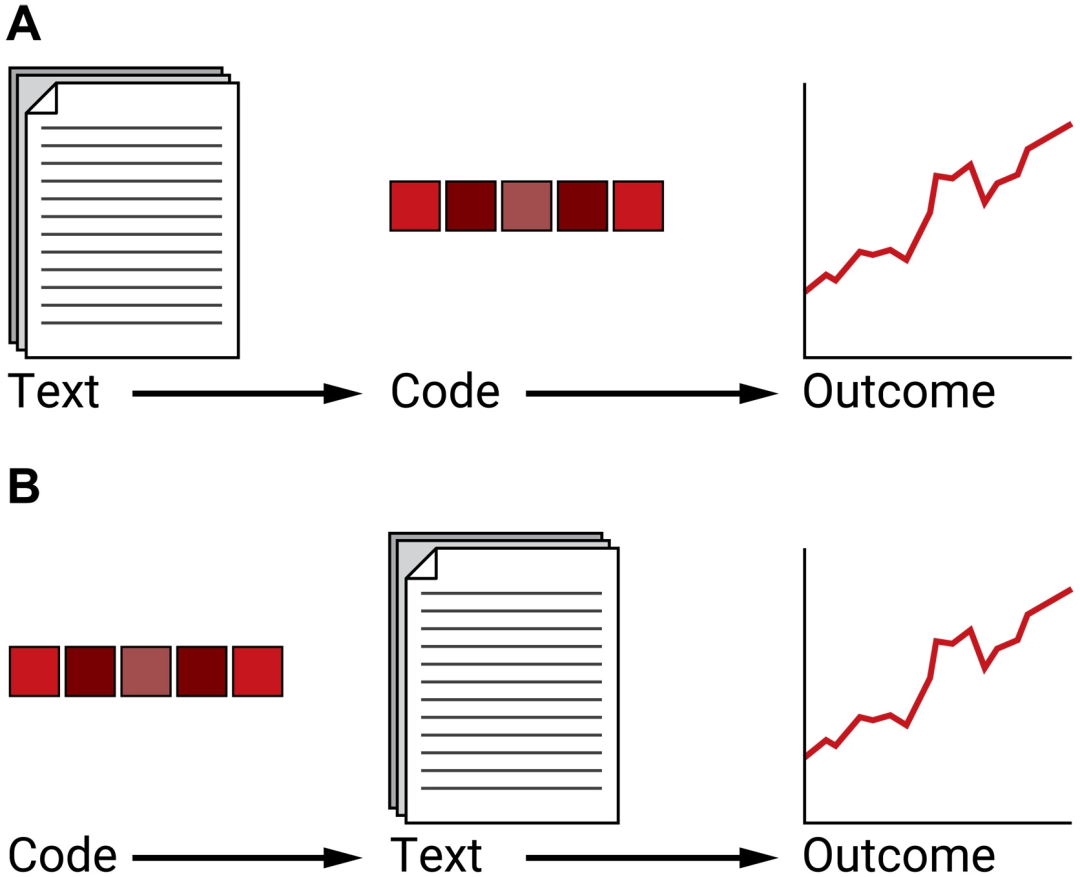
在其他情况下,文本是干预,导致结果的一个可能原因。当文本是干预,有两种涉及编码的方法(图1)。
图1. 编码在涉及文本的因果模型中发挥作用的两种方式。(A) 编码捕捉导致结果的文本; (B) 编码表征影响文本内容的一些方面。| 来源:Austin Fisher, Science Advances.
首先,编码可以捕捉到导致结果的文本的一些方面,如图1A所示。例如,贷款申请人在申请贷款时会写一份声明,我们会记录他们是否收到资金。编码可以表征应用程序中贷款人员批准或拒绝申请时所依赖的所有信息。(使用主题模型的相关数据的关联分析可以参考 [8]。)在 Egami 等人的例子中,政治候选人的传记影响着他们的受欢迎程度。编码方程能将候选人的传记简化为与选民是否支持候选人有因果关系的特征。
当编码沟通文本和结果的关系时,因果推断可以揭示在候选人传记中应该包含哪些内容以获得选民支持,或在贷款申请中应该包含哪些内容来获得贷款。好的编码可以捕捉可能会影响结果的那些文本方面。理解这些编码ーー如何找到它们,以及我们必须对它们做些什么假设ーー在[9]中有所讨论。
在文本作为干预的第二个范例中,编码直接影响文本的写作方式,文本则因果地影响结果,如图1B所示。例如,一个候选人有某种政治意识形态,它会影响候选人演讲的语言,而演讲影响候选人是否当选。因果推理可以向候选人建议,如何调整他们的意识形态立场以影响投票行为。
当编码产生文本时,一个好的编码会从候选人演讲的内容中推断出他心中的意识形态。在这个意义上,在产生文本之前,编码是“可操作的”(例如,候选人可以选择他们的意识形态)。如何形成这样的编码,即使是手工编码,也是一个困难的问题,因为理想的编码会捕获文本作者的意图。
如果我们想通过算法,例如使用主题模型来推断编码,该怎么做?非监督机器学习方法虽然通常能够产生可解释的表征,但不一定能够恢复这样的“可操作”编码。如何指导非监督的方法提取这样的因果变量,与因果表征学习这一新领域 [10] 相关。发展语言数据的因果表征学习是一个很有前景的研究方向。
Egami 等人的工作通过展示如何从文本数据(其中文本可以是结果或干预)中量化估计因果关系,推进文本分析和因果推断这一交叉学科。他们的论文以及越来越多关于从文本中进行因果推理的文献中发展的方法,可以帮助社会科学家和其他研究人员从文本数据中进行新类型的因果推理。
1 J. Pearl, Causality (Cambridge Univ. Press, ed. 2, 2009).
2 G. Imbens, D. Rubin, Causal Inference in Statistics, Social and Biomedical Sciences: An Introduction (Cambridge Univ. Press, 2015).
3 S. Morgan, C. Winship, Counterfactuals and Causal Inference (Cambridge University Press, ed. 2, 2015).
4 M. Hernan, J. Robins, Causal Inference: What If? (Chapman & Hall/CRC, 2020).
5 N. Egami, C. Fong, J. Grimmer, M. Roberts, B. Stewart, How to make causal inferences using texts. Sci. Adv. 8, eabg2652 (2022).
6 V. Veitch, D. Sridhar, D. Blei, Uncertainty in Artificial Intelligence (Proceedings of Machine Learning Research, 2020).
7 M. E. Roberts, B. M. Stewart, D. Tingley, C. Lucas, J. Leder-Luis, S. K. Gadarian, B. Albertson, D. G. Rand, Structural topic models for open-ended survey responses. Am. J. Polit. Sci. 58, 1064–1082 (2014).
8 O. Netzer, A. Lemaire, M. Herzenstein, When words sweat: Identifying signals for loan default in the text of loan applications. J. Market. Res. 56, 960–980 (2019).
9 C. Fong, J. Grimmer, Causal inference with latent treatments. Am. J. Polit. Sci. 10.1111/ajps.12649 (2022).
10 B. Schölkopf, F. Locatello, S. Bauer, N. Ke, N. Kalchbrenner, A. Goyal, Y. Bengio, Towards causal representation learning. arXiv:2102.11107 (2021).
本文翻译自 Science Advances 评论文章。
原文题目:Causal inference from text: A commentary
原文链接:https://www.science.org/doi/10.1126/sciadv.ade6585
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书会直播已结束,欢迎加入因果科学社区,回看第三季直播,加入讨论。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动