因果推理与稳定学习:基于种子变量的稳定学习框架

导语
赋能模型针对分布外数据稳定泛化的能力已经成为了工业界和学界共同关注的热点问题。因果推理在稳定学习这一核心问题中起着重要作用,其主旨思想是通过寻找直接影响预测结果的因果变量来实现跨域稳定的不变预测。浙江大学计算机学院况琨老师课题小组结合最新研究工作,介绍因果指导的稳定机器学习。本文针对成对变量解耦式的机器学习,总结了目前稳定学习的进展和不足之处,并结合先验因果结构,提出了基于种子变量的稳定学习框架。
研究领域:因果推理,机器学习

浩天 | 作者
邓一雪 | 编辑
1. 分布变化下的医疗诊断
1. 分布变化下的医疗诊断
在美国,模型设计者需要根据医院数据来预测癌症患者的生存率。由于条件限制,很难拿到所有医院的数据。假设拿到了位于曼哈顿某一个高档医院的数据来训练网络,可能会发现在该医院中病人的收入越高,病人的幸存率也会越高:因为收入高的病人得到的治疗和能支付起的药物可能更好。基于这样的模型做预测时,如果未来的要预测的病人同样是来自该医院的患者,模型可能会得到很准确的预测结果。但是如果未来要预测的数据集来自大学校医院(比如美国的校医院,对患者给予的救治不由收入决定),此时模型的预测效果很可能不好。
这驱使我们提出疑问:当现实数据不能够达到公开基准数据的质量、不能够包括所有可能的潜在分布的时候,如何面向所有潜在测试群体的预测任务,设计泛化预测能力强的模型?
2. 机器学习的分布外泛化问题
2. 机器学习的分布外泛化问题
(1)机器学习中的分布外泛化性需求
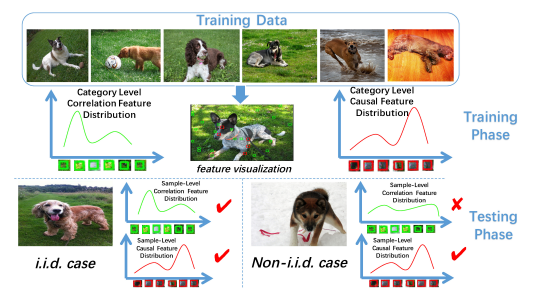
目前的统计机器学习方法要求从同一个分布中随机抽样得到训练数据和测试数据,即训练数据和测试数据的概率分布相同。在这一假设下,传统理论已经说明了许多现有的机器学习模型的泛化性能可以随着模型容量的增加而得到保障。然而,在真实场景下,独立同分布假设过于理想,我们实际上并不能保证训练数据和测试数据一定符合某种分布。
在开发学习模块的过程中,我们会使用某种训练数据,但是当我们将开发好的模块应用到各种实际场景下时,实际输入数据的分布可能相较于训练数据存在系统性的偏移,如图1所示。当测试数据分布与训练数据分布有系统性偏移时,模型的性能可能降至非常低的水平。
事实上,机器学习模型的部署中测试数据往往是不可见的,这使得现有的迁移学习方法无法使用,进而模型在未知的测试环境下性能无法保证,进而模型本身的部署价值受到影响。因此,我们需要考虑机器学习模型在分布外泛化下的预测问题,当模型被部署到未知的、可能带有分布漂移的测试环境下时,我们需要保证模型具有较好的、稳定的预测性能[1][2]。
3. 基于协变量平衡的稳定学习
3. 基于协变量平衡的稳定学习
基于因果效应估计中,将干预变量和混杂变量独立的重加权技术,[1] 提出了因果正则项,其主要思想是学习一个样本权重,用它对样本做重加权,使得重加权之后的变量之间相互独立,以此帮助我们评估单个变量对结果变量的因果关系,并且在理论上可以证明这样的样本权重是存在的。以浅层模型为例,其损失函数是基于潜在得分逆加权的平均因果效应估计框架设计的:


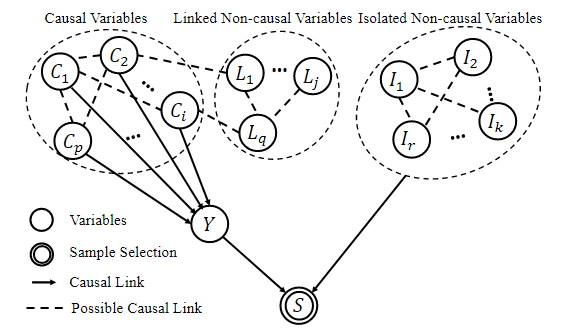
4. 基于因果结构和种子变量的稳定学习
4. 基于因果结构和种子变量的稳定学习

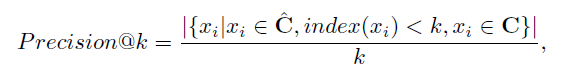
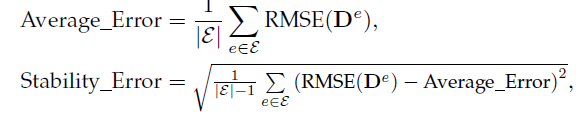
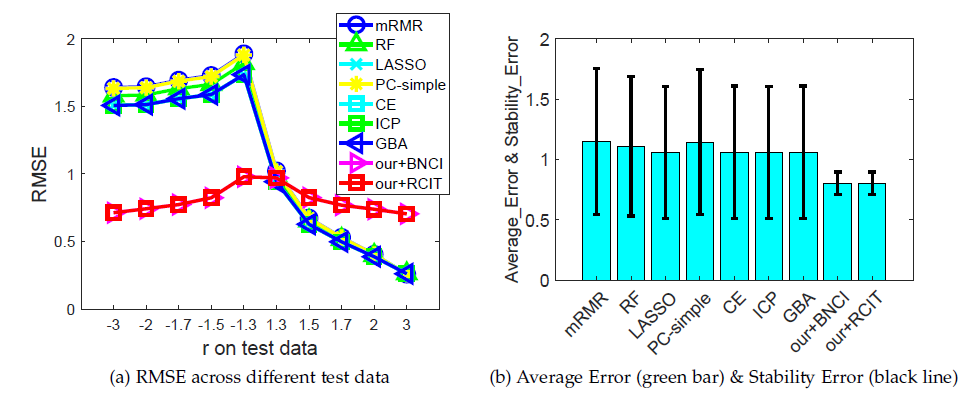
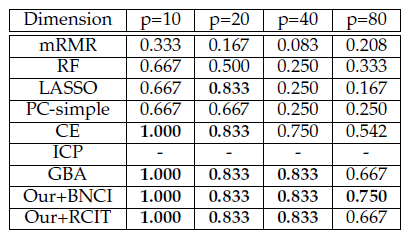
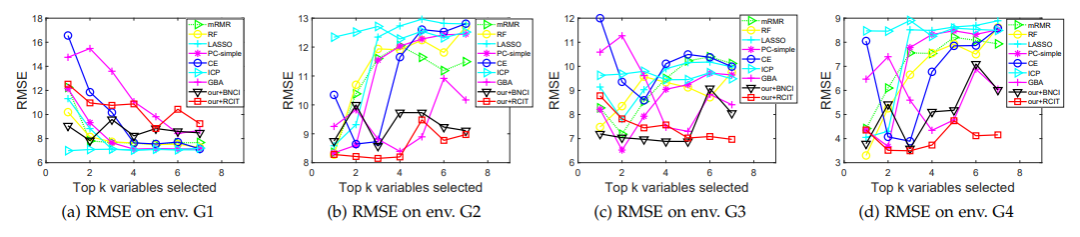
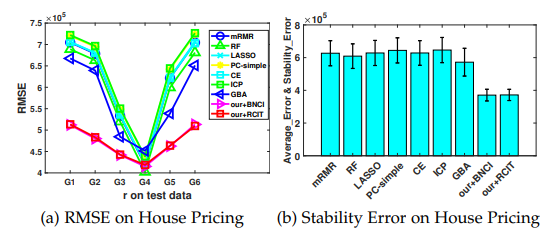
5. 展望与总结
5. 展望与总结
[1] Kun Kuang, Peng Cui, Susan Athey, Ruoxuan Xiong and Bo Li. Stable Prediction across Unknown Environments. In SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2018.
[2] Zheyan Shen, Peng Cui, Kun Kuang* and Bo Li. Causally Regularized Learning on Data with Agnostic Bias. In ACM Multimedia (MM), 2018.
[3] Kun Kuang, Ruoxuan Xiong, Peng Cui, Susan Athey, and Bo Li. Stable Prediction with Model Misspecification and Agnostic Distribution Shift, In AAAI Conference on Artificial Intelligence (AAAI), 2020.
[4] M. Scutari, “Learning bayesian networks with the bnlearn r package,” arXiv preprint arXiv:0908.3817, 2009
[5] E. V. Strobl, K. Zhang, and S. Visweswaran, “Approximate kernelbased conditional independence tests for fast non-parametric causal discovery,” Journal of Causal Inference, vol. 7, no. 1, 2019
因果科学千人社区欢迎加入
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书会详情及参与方式见文末,欢迎从事相关研究或对因果科学感兴趣的朋友参与。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
因果科学算法、框架、数据集汇总 -
大数据因果推断:数据驱动式学习下的因果混淆去偏算法 -
前沿算法:如何利用群论进行深度学习下的因果特征解耦 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











