数据科学基础爬虫课程周五收官:多种爬虫对比与总结

导语
大数据时代,爬虫是一个重要的基本技能。想要学会爬虫,需要一个完整的技术体系,并动手实践。为了帮助学生真正学会爬虫,集智学园联合西安交通大学应用数学博士、现为南京审计大学讲师的卢燚老师精心设计了 8 小时系列爬虫课程,用简短的代码、精短的课时,讲解 3 种 Python 爬虫的基本方法,给你一个较为完整的爬虫技术体系。
前七节课系统讲解了requests+BeautifulSoup4、Selenium测试框架和Scrapy框架3种爬虫方法。本次课程为最后一节「几种爬虫写法对比与总结」,不仅从“术”,更从“道”的层面,进行对比分析,帮助学员构建解决实际问题的能力。本课程会面向付费学员直播,如果你对爬虫技术感兴趣,欢迎扫描文中二维码加入课程。


课程简介
课程简介
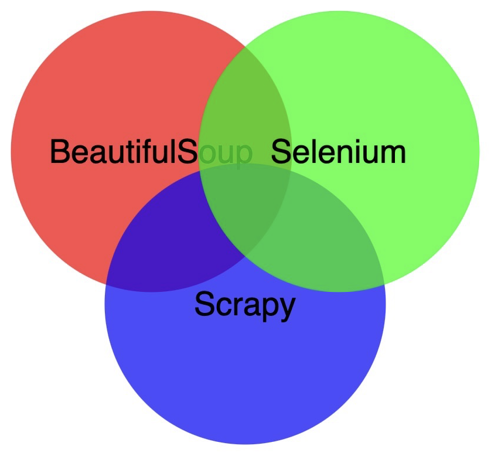
我们在课程里讲了三种爬虫的方法,分别是:
-
requests+BeautifulSoup
-
Selenium框架
-
Scrapy框架
这门课程里,我们学会了如下的知识:
-
爬虫的基本结构:数据提取+爬虫策略
-
CSS选择器(非常重要)
-
HTTP基础
-
Chrome开发者工具/Postman
-
Selenium API
当然,课程并不是无所不包,还有很多话题没有涉及,比如:
-
xpath
-
网站登录
-
破解验证码
-
手机app爬虫
-
网站给开发者提供的官方API的使用
课程大纲
课程大纲
-
三种爬虫写法的对比与总结
-
思考:方法之间可以互补
-
示例:课程学员提供一
-
示例:课程学员提供二
讲师介绍
讲师介绍

课程信息
课程信息

给数据相关工作者的爬虫课
每周更新,持续报名中
系列课程大纲
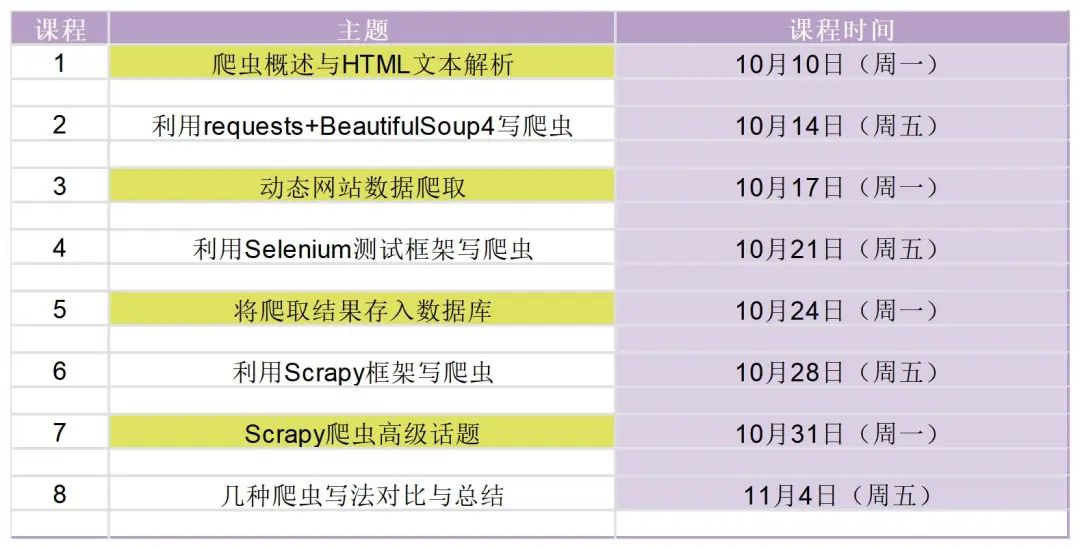
本系列课程分为 8 节,每节课程包括 60 分钟的内容分享与 30 分钟的答疑。
课程目的
本系列系统讲述当前流行的三种爬虫思路,三种思路内容互相补充,基本覆盖大多数爬虫使用场景。帮助你:
-
从零到一,系统建立爬虫技术体系;
-
由易到难,学会三种数据采集思路;
-
课堂内外,即学即用快速上手获取数据。
对学员的基础要求
-
具有一定的python编程基础(使用python3)
-
懂一点算法和网络知识(可选)
课程适用对象
-
算法工程师
-
从事数据相关工作的研究者
-
有编程基础,对爬虫感兴趣的开发人员
课程特色
-
线上直播,示例丰富。
-
只讲基本框架,代码简洁有效
-
代码可拓展,实用性强
-
三种方法互相补充,覆盖大多数爬虫场景
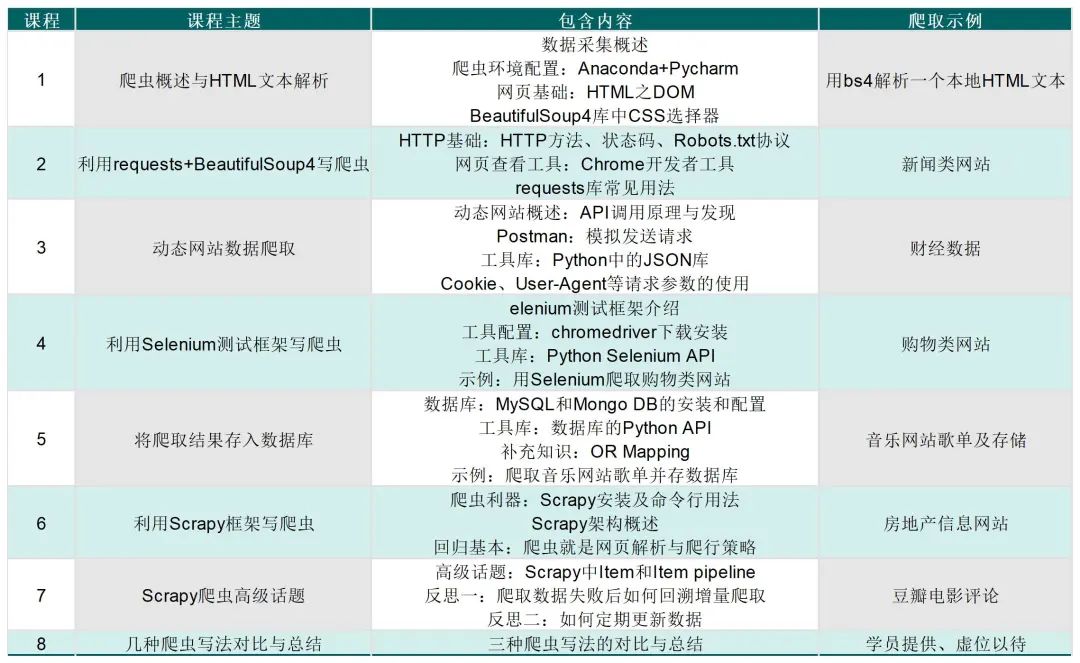
课程内容框架
报名加入课程
课程价格 199元,本课程首节免费,可开发票,还可开学习证明,欢迎扫码了解详情~

第一步:扫码付费
第二步:在课程详情页面,填写“学员信息登记表”
第三步:扫码添加助教微信,入群
往期回顾
微信扫一扫,分享到朋友圈











