我主要的研究方向是强化学习,强化学习这个词本身表示的是关于行动的智能,今天,它在大语言模型里面已经扮演了比较重要的角色。
那么,强化学习技术,到底是做什么的?它在我们的大语言模型里面主要发挥什么样的功能?
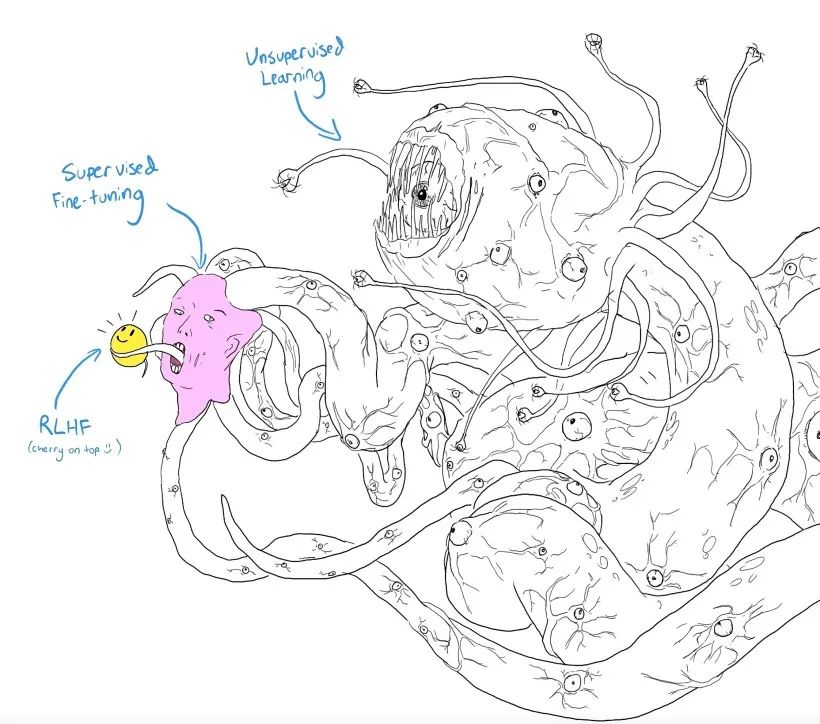
这里有一张图,可以形象地展示一下什么是无监督学习,什么是监督学习,以及语言大模型是如何一步一步的变成我们可以使用的样子。
这张图右半部分看起来张牙舞爪,像一个妖怪,这个东西就是用了无监督学习来获得的,如果我们今天只用这样的技术来训练一个大模型,我们也确实有很大的可能得到一个很惊悚的结果,可能不讲人话,或者胡说八道。
如果我们希望他能讲得更像人话,就要用到下一步的技术——监督学习,从图的左半边来看,它好像具备了一张有点像人脸的图像,但是这样的图像往往依旧不能达到我们的预期,所以在他的舌头上又吐出来一个乖巧的小精灵,小精灵代表一种叫做基于人类反馈的强化学习的技术,也就是图中写的RLHF(Reinforcement Learning from Human Feedback)。
我们希望,计算机的人工智能技术,能够为人类服务,能够帮助人类更好的完成工作,能够和人类比较好地对话。这就涉及到了好几个不同的有关“学习”的技术,这些各种各样的“学习”是什么意思,它们之间有什么区别?特别是,什么是强化学习?它为什么可以让大语言模型变得更好?
随着时代的发展,人工智能的概念也在不断的变化,大家关注的热点也在不断的变化,但是总体来说,我们希望计算机能具备解决我们人类需要用智力才能够解决的问题的能力。
今天的人工智能是一个很庞大的研究领域,存在很多分支,而如今最受瞩目的分支叫做机器学习。机器学习其实并不是人工智能发展初期最蓬勃的一个分支,上世纪60-70年代,人工智能最初发展的时候,大家主要是希望人工智能能够像数学家一样,去自动证明数学题,当时大家认为,如果人工智能可以像数学家一样去证明题目,那一定和数学家一样聪明。但是过了一段时间,人们发现,光能够证明数学题好像用处不大,因为人工智能最大的局限在于知识量不够多,而有大量的工作需要把人类的知识总结出来以后放到计算机里面去,所以人工智能不仅要像一个数学家,还要像一个博物学家,储备更多的知识。
但人们很快发现,把知识放到计算机里面,也是一件很困难的事情,因为它需要我们人类一点点的把知识总结出来。所以,90年代、特别是2000年以后,机器学习迎来了蓬勃发展的时代,它主要就是要解决靠人总结知识的低效问题,机器学习就是让机器自己从原始的数据里面去提炼知识,效率就会高很多。
为了从数据里面提炼知识,我们发展了很多的工具,相应的,我们的时代进入了大数据的时代。在各种各样的传感器的支撑下,我们收集到的数据越来越多,知识带来的价值越来越大,机器学习因此变成一个备受瞩目的研究领域。
机器学习包括三类技术:分别叫监督学习、无监督学习、强化学习。
监督学习的任务是:从有标记的数据中学会这个标记是怎么给出来的。
做一个类比,学生学习的时候,会去看一些题目和给定的标准答案,然后思考这个题目为什么是这样一个答案,把中间的过程补充上去,这样的学习方式就叫做监督学习。
这里的“监督”指的就是我们给出了大量的题目以及对应的答案,希望人工智能能够学到每个题对应什么答案,这就是监督学习要完成的任务。我们今天常用的很多机器学习的应用,比如人脸识别、声音识别、指纹识别,基本上都属于监督学习的范畴。
比如,人脸识别。这里的题目就是我们的人脸,答案就是这个人脸是谁,机器通过补充中间的过程,给出答案。至于这个中间的过程是个什么?今天用的比较多的就是神经网络。
强化学习的目标是要从一个总体的反馈中学习,我们再做一个类比:我们写作文,没有标准答案来告诉你每一个字到底应该是什么,但通常写完作文以后,阅卷老师会给作文打一个分,我们希望通过一次次写作和打分,一次比一次分数高。
我们希望在没有标准答案,但是会有一个评分的情况下,我们的机器也可以自己找到得更高分的写作文的方式。这样的任务就是强化学习的任务。
还有一类任务叫做无监督学习,无监督学习既没有标准答案,也没有评分,可以类比于我们做课外阅读,没有评分的压力,读的越宽泛,我们了解的知识可能就越多,课外阅读没有具体的目的性,阅读的结果,可能是理解了这个书里面的一些人物,也可能是了解了某些语言怎么去表达。
回到大语言模型上来,无监督学习首先要做的是大量的课外阅读——要把互联网上面的能收集到的所有的文字材料、越来越多的图像、视频等多模态信息大量收集、学习,具体学到了什么东西,我们并不完全清楚,所以我们接下来需要通过监督学习,给他出一些有答案的题,根据答案正确与否,进行调整。但是监督学习有一个缺陷,就是我们需要的大量答案来自于人工,效率低、成本高。这时就要用另一种方法——我们来对模型的输出直接给分,希望这个模型自己去学会怎么样提高分数,这就是强化学习。
其实,强化学习是一个从生物学借鉴过来的词,我们训练动物的时候,会不断的强化对动物的训练,这就是这个词本来的意思。其实,生物要能够迅速的适应所处环境,生存下来,强化学习的能力是几乎所有生物的最基本的能力。
比如,我们训练一只狗,希望他能够听得懂我们的指令,训练员手上会拿一个吃的,直到这只狗听到我们的指令做出正确的动作的时候,他才会把吃的给这只狗,这样的过程大概重复不到10次,一只1岁左右的小狗就能够学会听到指令做出对应的动作。因为他很快就发现,他听到指令做出正确的动作就有吃的,这也是动物适应环境的一种能力。
现在,让我们忘掉狗本身,把狗的智能中,一些比较关键的东西抽象出来,给狗改个名字,叫智能体,智能体首先会观测它周围的环境,他可以听见旁边的人说了什么,他可以闻到气味,它也能做出行动。有的时候,它做了动作会发现能拿到吃的,我们管这叫做奖励,这只智能体就在这个环境中去摸索怎么样能够获得奖励,它的任务就是要想办法获得总体上最多的奖励,这就是抽象出来的强化学习的任务。这样的事情如果让计算机来做,实现它的领域就叫做强化学习。
这也是我自己在选择强化学习作为研究方向的时候,最吸引我的一个地方——对强化学习的研究,非常类似于生物在所处环境中所面临的情况,它并不是靠人给它一些有标记的数据,而是要像生物一样去探索环境,找到自己能够活下去的方式的智能。
知道了强化学习要做什么,接下来我们要把它实现,这叫做算法。
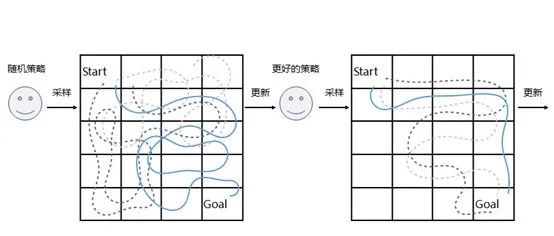
今天可能有成千上万种强化学习的算法,但是基本上它们的原理都是——试错。学习中,我们会犯错,会从错误中学习,我们就像那只狗一样,一开始可能在环境里面会乱动,做出各种各样的行动,这叫做对环境的探索。在各种各样的行动中,有的行动可能一直得不到奖励,但是有的行动能够让我们达成目的,获得奖励信号。对比这些行动,我们很快做出反应——我应该向好的那些行动靠拢,我们更新了自己大脑中的想法,再进一步的行动,又会发现在我更新过的行动里面有一些可以变得更好,我不断的这样更新下去,最终就学会了我们怎么样在这个环境中做出最好的反应。当然,这个过程很复杂,远没有我说的这么简单,实际上要把这个过程完全实现,需要用数学将其中的每一个步骤都描述出来,然后在计算机里面实现。
追溯强化学习的发展历史,在比较久远的过去,我们的计算条件、数据条件都很有限,所以强化学习的发展相对来说比较滞后。
强化学习一直在挑战人类的各种能力,首先就表现在各种棋类和牌类上。1992年,在一个叫西洋陆战棋的游戏上面,强化学习取得了和人类的专家相当的水平。2014年,deep Q-network将神经网络和强化学习相结合,让强化学习的智能体有了神经网络来作为它的观察世界和思考的主要模型,随后的2016年,AlphaGo在围棋上第一次击败了人类的围棋世界冠军,这里面用到的主要技术就是强化学习技术。
相比于2016年版本的AlphaGo里面使用了大量的人工编码和人工数据,2018年推出的Alphazero,强化学习算法里对于人工编码的依赖就越来越少,而且完全抛弃了人工的数据,完全让智能体自己从头来学。很快它也能学会,不仅会学围棋,还可以学其他棋。2019年,在目前最复杂的游戏之一——星际争霸上,AlphaStar达到了人类前1%的专家的水平。
今天,强化学习的能力变得越来越强,可能用一个算法或模型去解决很多不同的游戏,这越来越接近于今天所谓的大模型的思路。
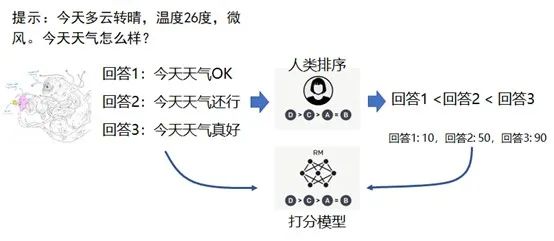
回到我们的语言模型上面来,强化学习是怎么让我们的语言模型变得更好呢?其实在语言模型里,对于一个提问,可以产生各种不同的回答。比如,我们问“今天天气怎么样”,他可能有不同的回答,我们对这些回答给一个人类的排序和打分,对于回答一可能只给10分,回答二给50分,回答三给90分。于是,从答案和得分中,计算机可以得到一个打分的模型,然后,它就可以替代人类进行排序。
再比如刚才我们讲的写作文这件事情,计算机可以写作文,然后得到一个打分,只不过这里的打分是由打分模型从人类的数据里面来学会的,这样,我们就可以把这个语言模型当成是智能体,它的每一个行动、每一个词,不断的往外输出,同时我们会对它说出这个句子进行一个打分,用强化学习的技术,就会使得它自己去找什么样的输出,会令得分尽可能的高。
这样的做法就使得基于GPT的模型基础上发展出了“chat”这么一个用来和人聊天的技术。这样一个和人聊天的系统,它主要关心的是聊天的时候,讲的话要讲的好,不要讲出错误的话出来。所以它的最后一个环节是用强化学习,让它尽可能的输出得分高的一个语言。
今天,强化学习在语言模型里面正在发挥越来越重要的作用,除了让人来给模型的输出打分以外,大模型其实自己也会给自己的输出来做一个评分。当我们把评分替换成模型自己评分以后,它开始自我进化了——自己对自己的输出来评分,然后自己调整自己的输出,使得它的评分逐渐增加,这样,大模型可以不断的进化。
除此之外,我们其实更希望未来人工智能的技术能够服务于我们的生活和生产,最好的服务就是它能够真正的行动起来,所以说,人工智能的行动能力,其实也是强化学习的主要要解决的问题之一。
强化学习并不是一个已经发展完善的领域,它其实还有很多问题需要解决。比如,我们刚才说到的训练一只狗的过程,大概只需要10次左右的训练,但是我们今天训练一个模型可能需要上千万次、甚至上亿次的训练,效率远远比动物的学习效率要低。怎么去解决这些问题?这也是摆在我们科研人员面前,未来需要解决的问题。
本文内容整理来自“墨子沙龙 X 2023年科技节”(2023年5月20日),以下是报告回放。
俞扬,南京大学人工智能学院教授,主要从事机器学习、强化学习的研究工作,工作获4项国际论文奖励和3项国际算法竞赛冠军。入选国家青年人才计划、IEEE AI’s 10 to Watch,获CCF-IEEE青年科学家奖,首届亚太数据挖掘“青年成就奖”,并受邀在国际人工智能联合大会 IJCAI 2018上作“青年亮点报告”。