近日,来自 TAMU、MIT、Stanford、UIUC、NVIDIA 等14个机构的63位作者合作撰写了一篇263页的 AI for Science 重磅综述,详细阐述了 AI 在亚原子(波函数、电子密度),原子(分子、蛋白质、材料、相互作用),以及宏观系统(流体、气候、地下)等不同时空尺度的科学领域应用的关键挑战、学科前沿和开放问题。文章围绕对称性进行了深入而直观的讨论,同时也对可解释性、分布外泛化、大语言模型和不确定性进行了探讨。此外,研究者还创建网站(https://air4.science/)并绘制 AI for Science 的领域地图,提供了分类资源列表,希望能促进领域交流与合作。
集智俱乐部「AI+Science」读书会发起人、西湖大学工学院AI方向助理教授吴泰霖参与撰写了这篇综述。今天的文章是对综述文章的简要介绍(主要基于原论文 Introduction 部分和各章节 Overview),感兴趣的朋友可以进一步阅读原论文,并加入 AI+Science 社区深入交流!
研究领域:AI for Science,AI 可解释性,分布外泛化,大语言模型,对称性与等变性
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
https://arxiv.org/abs/2307.08423
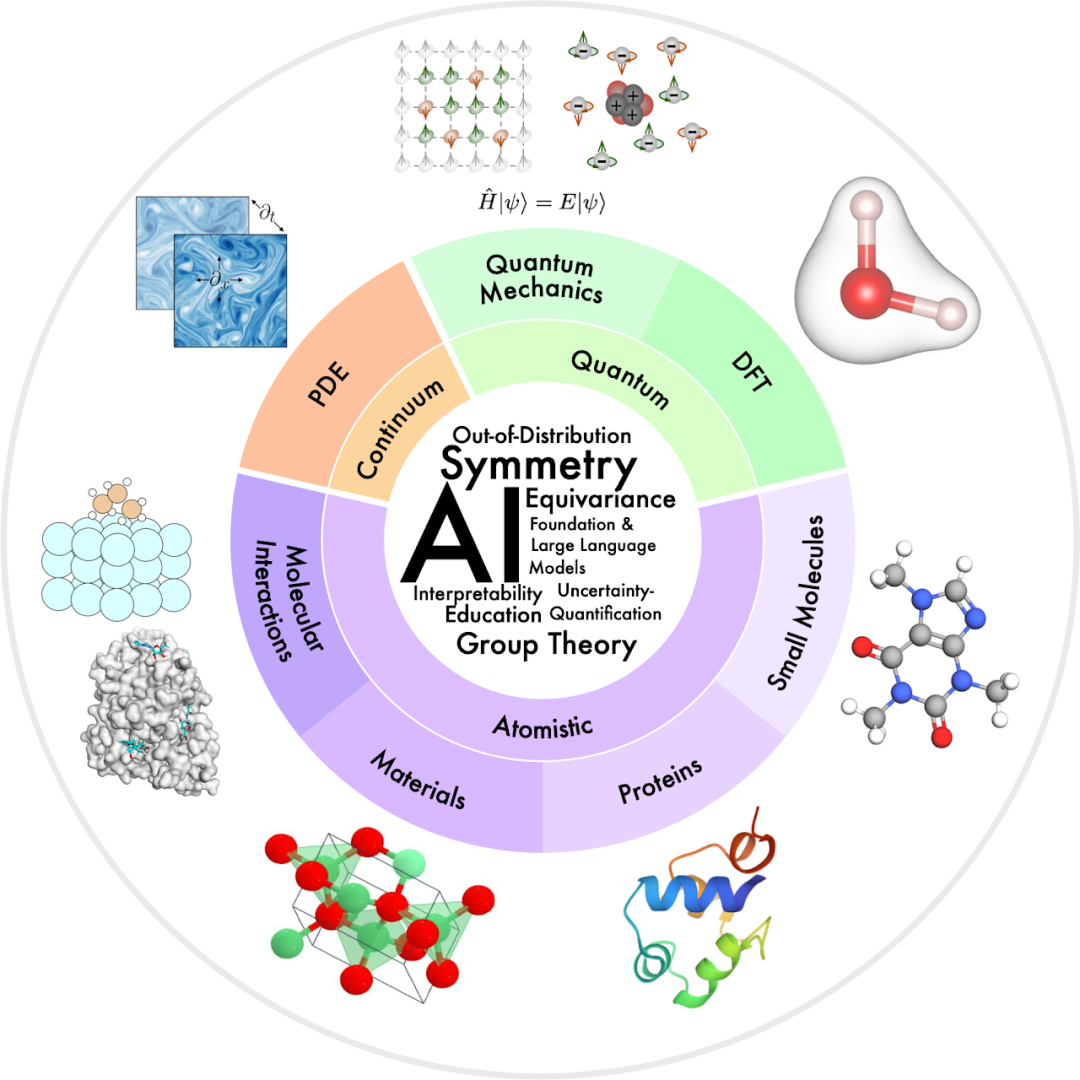
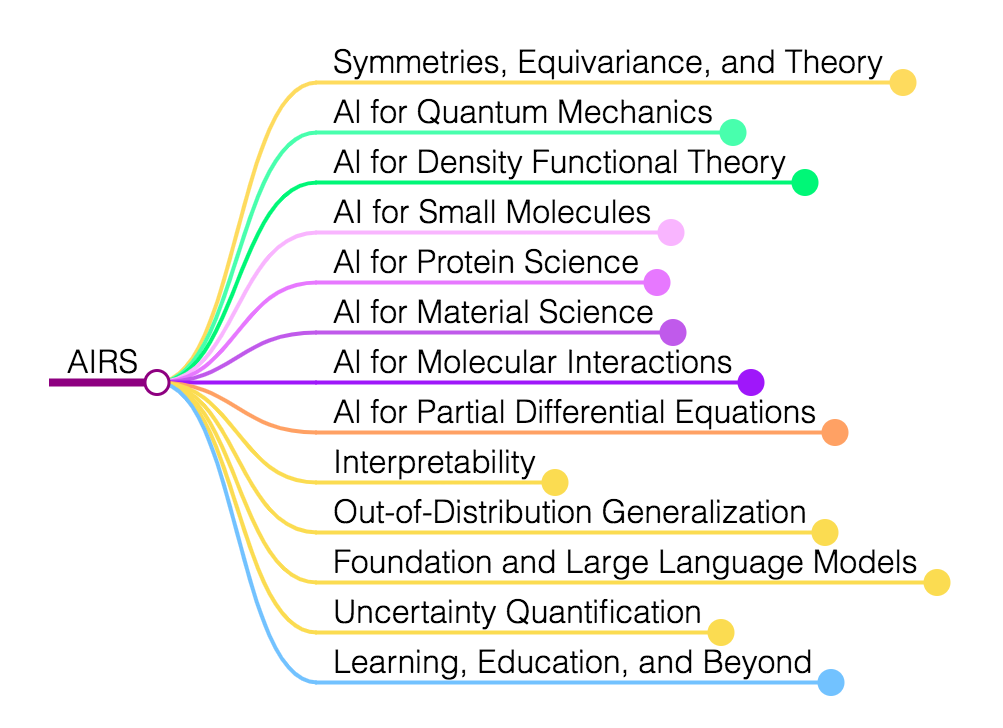
图1. AI for science 研究领域概览。本文主要关注 AI for 量子力学、密度泛函理论(DFT)、小分子、蛋白质、材料、分子相互作用和偏微分方程(PDE)。最外层圆圈中直观地描绘了这些不同的领域,它们按物理世界建模的空间和时间尺度排列为:量子、原子和连续体系。最内部的圆圈中显示了这些研究领域中存在一系列常见的技术挑战,例如对称性、可解释性和分布外泛化等。
数十年的人工智能(AI)研究随着以深度学习为标志的神经网络的复兴达到顶峰。自2012年的 AlexNet 以来,十多年的深入研究使得深度学习领域取得大量突破,包括 ResNet、扩散模型和基于分数的模型、注意力、transformer,以及最近的大语言模型(LLM)和 ChatGPT 等。这些发展使得深度模型的性能不断提高。深度学习与不断增长的计算能力和大规模数据集结合,正成为计算机视觉和自然语言处理等各个领域的主导方法。
这篇论文对研究者过去多年持续探索的 AI for science 的研究领域进行了综述,根据系统所在的物理世界的空间和时间尺度,来组织不同的 AI for science 领域。这项工作提供了一个全面的分类体系,以对称性、等变性和群论这些数学和物理原理为基础,深入探讨了七个具体的科学领域,并讨论了多个领域存在的共同技术挑战。这使得对整个 AI for science 领域进行全面而有结构的探索成为可能。
本文在连续的空间和时间尺度中探索 AI 和各个科学学科的交叉点。这个框架容纳了各种各样的领域和问题,并通过它们独特的对称性和共同技术挑战统一起来。对称性是自然科学的结构所固有的,受数学和物理定律支配,在各个科学领域的许多模式中都有体现。这种跨学科视角为我们提供了一个新透镜,透过它我们可以用 AI 方法解决和研究复杂的科学问题。
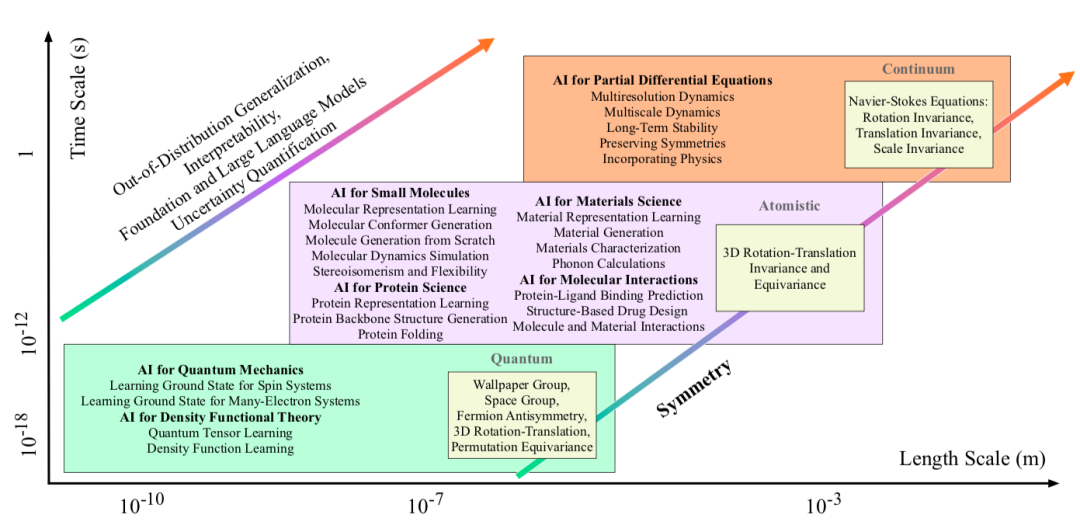
图2. 科学领域的时间和空间尺度。量子物理的空间尺度通常在原子和亚原子级别(10-12~10-9米);密度泛函理论(DFT)处理分子中的多体电子相互作用,尺度范围为 10-10~10-8 米;分子动力学模拟在更大的尺度上运行(10-9~10-6 米);偏微分方程(PDE)被用于研究连续介质系统的行为,尺度范围从流体动力学中的微米到气候动力学中的千米(10-6~103米)。本文将这些领域聚类为量子、原子和连续介质体系。
量子力学研究最小长度尺度上的物理现象,使用波函数描述量子系统的完整动力学。而波函数通过求解薛定谔方程得到,其中的计算具有指数复杂度。本文提供了技术综述,介绍如何设计先进的深度学习方法来有效地学习神经波函数,探讨量子多体问题的求解,包括:学习量子自旋系统基态,和学习多电子系统基态。
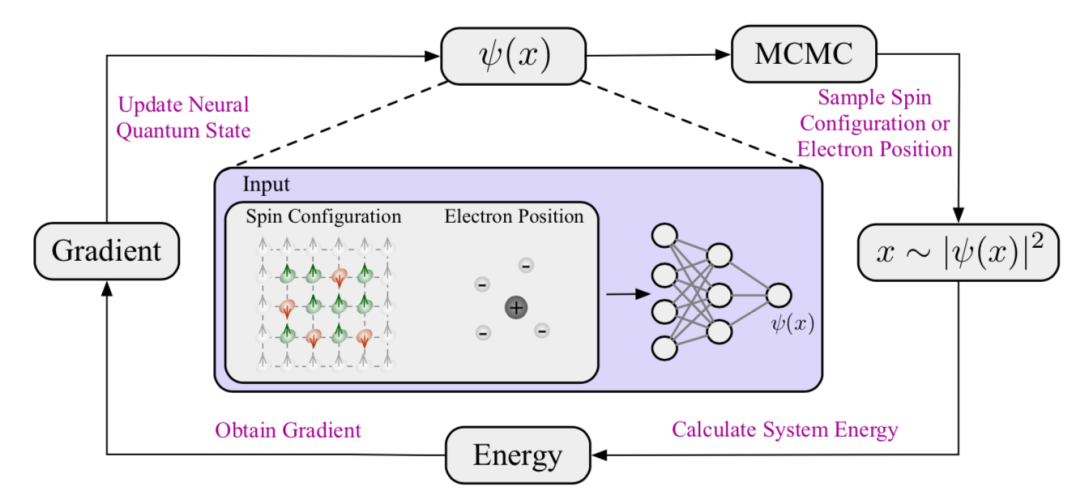
图3. 变分蒙特卡洛(VMC)的流程。神经量子态以自旋构型或电子位置作为输入,输出波函数值。在VMC中,根据波函数确定的概率分布,使用马尔可夫链蒙特卡洛(MCMC)采样自旋构型或电子位置;然后根据这些采样计算能量,并通过能量梯度更新神经量子态。
参看 AI+Science 读书会罗迪关于 AI for 量子科学的分享:
深度生成模型探索量子科学
https://pattern.swarma.org/study_group_issue/477
密度泛函理论(Density Functional Theory,DFT)和从头计算量子化学(ab initio quantum chemistry)方法是在实践中广泛应用的第一性原理方法,用于计算分子和材料的电子结构和物理性质。然而,这些方法在计算上仍然昂贵,限制了在小型系统(约1000个原子)中的使用。本文介绍了用于准确预测量子张量的深度学习方法,这反过来可用于推导许多其他物理和化学性质,包括分子和固体的电子、机械、光学、磁性和催化性质;此外综述了机器学习方法用于密度泛函学习的最新进展。
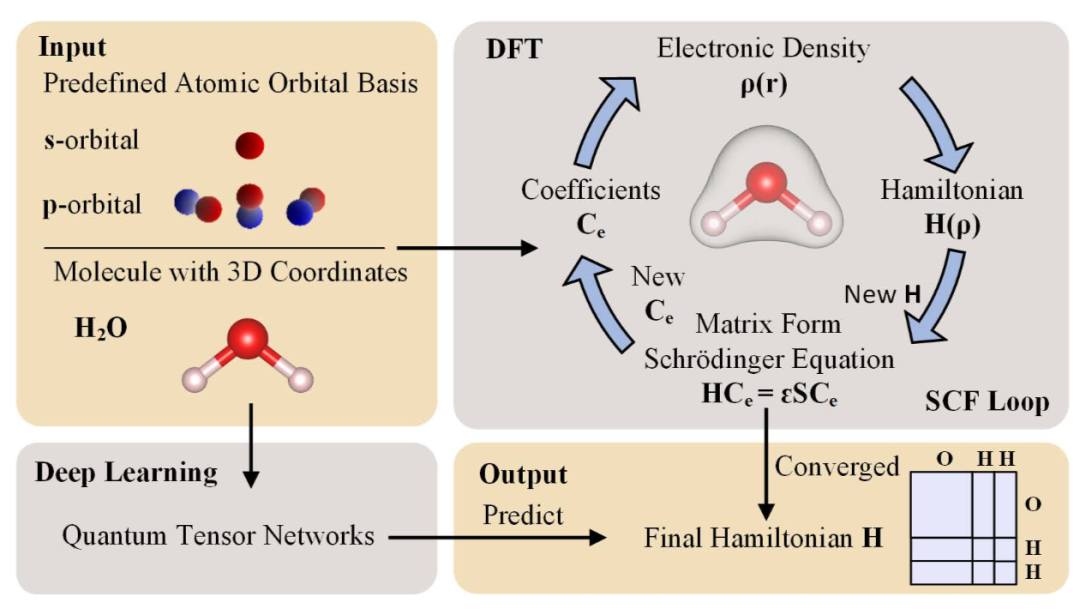
图4. DFT 计算和深度学习方法获取哈密顿矩阵的流程。DFT 计算使用与分子及其坐标相关的预定义原子轨道基底,通过在自洽场(SCF)循环中迭代优化哈密顿矩阵,直到达到总能量极小值/最小值的收敛。深度学习方法直接使用量子张量网络预测最终的哈密顿矩阵,以原子类型和坐标作为输入,消除了迭代优化过程,从而加速了 DFT 计算。
小分子,也被称为微分子,通常有几十到几百个原子,相对于蛋白质、核酸等具有复杂结构的大分子而言,在许多化学和生物过程中起着重要的调节和信号作用。例如,90% 获批准的药物都是小分子,它们可以与目标大分子(如蛋白质)相互作用,改变靶标的活性或功能。将机器学习方法用于小分子学习,可以为分子预测和生成任务开发更准确、有效的方法。本文深入介绍了分子学习的几个关键任务,包括:分子表征学习、分子构象生成、从头生成分子、分子动力学模拟,以及立体异构和构象灵活性的表征学习。
参看“AI+Science 读书会”中付襄介绍分子动力学模拟的内容:
https://pattern.swarma.org/study_group_issue/484
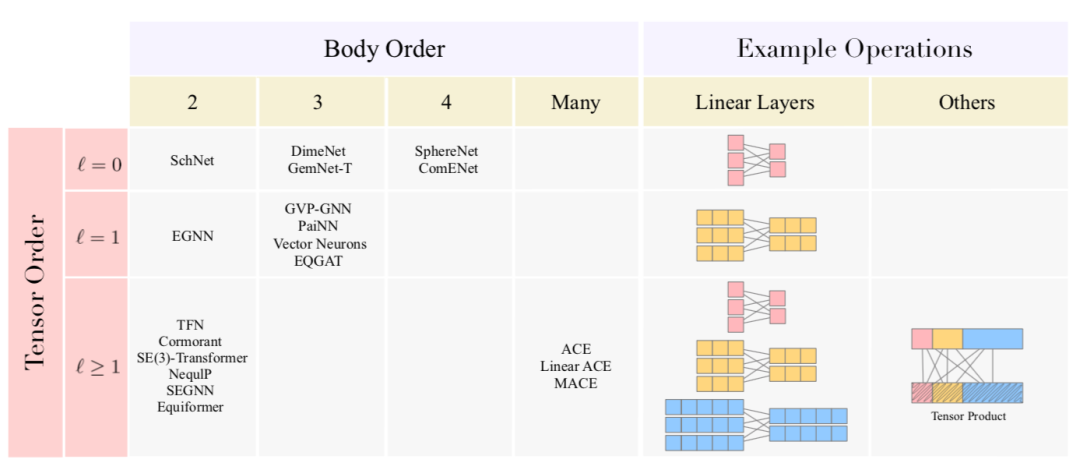
图5. 现有的分子表征学习方法概述。可以根据特征的张量阶(tensor order,指特征的维度)和 GNN 层的体阶(body order,指 GNN 层的输入和输出维度)对现有方法进行分类,这是用于构建强大的三维 GNN的两个关键设计选择。
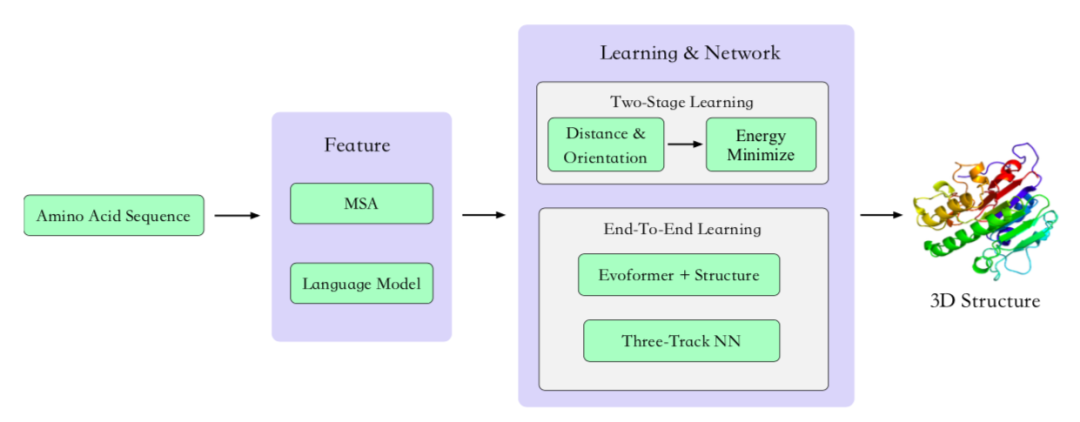
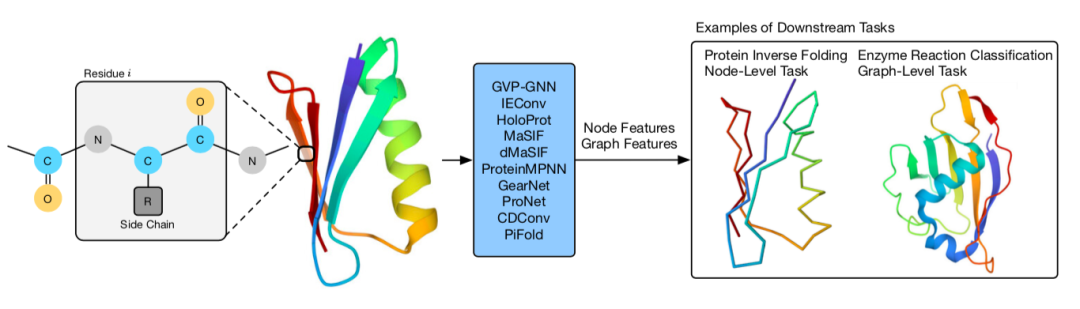
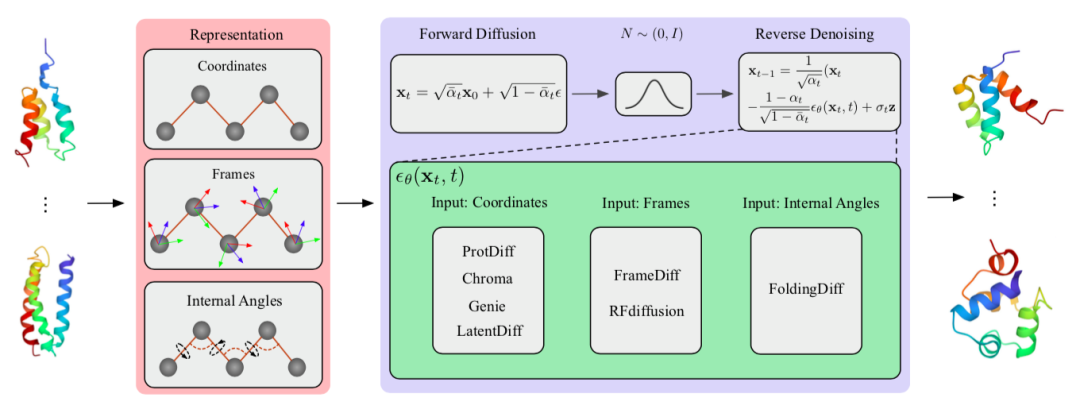
蛋白质是由一条或多条氨基酸链组成的大分子。人们普遍认为,氨基酸序列决定蛋白质结构,而蛋白质结构又决定蛋白质功能。蛋白质承担着大部分生物功能,包括结构、催化、生殖、代谢和运输等。最近,机器学习方法在蛋白质结构预测方面取得了重要进展,而图神经网络、扩散模型、三维几何模型等机器学习方法则加速了新蛋白质的发现。这项工作综述了AI 用于蛋白质科学的三个主题:蛋白质结构预测,蛋白质表征学习,蛋白质骨架生成。
图6.(上左)蛋白质结构预测算法总结。(上右)蛋白质表征学习。(下)扩散模型用于蛋白质生成。
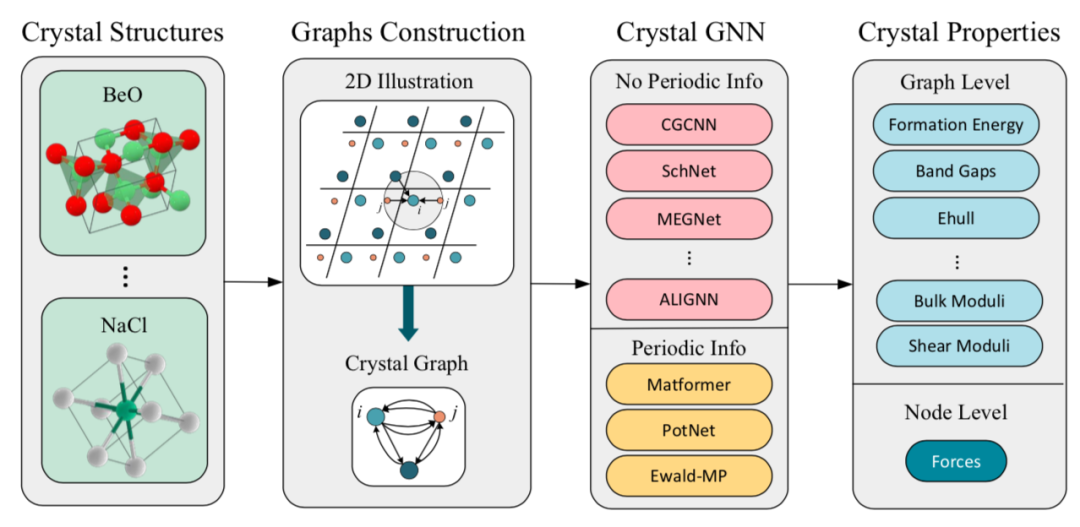
材料科学研究材料的加工、结构、性质和性能之间的关系。从原子尺度到微观和连续尺度,材料的内在结构通过与外界刺激/环境的相互作用,决定其量子、电子、催化、机械、光学、磁性和其他性质。最近,机器学习方法已经被开发用于预测晶体材料的性质并设计新颖的晶体结构。本文对晶体材料的性质预测和结构生成做了技术综述,包括两个基础任务:材料表征学习和材料生成问题;和三个进阶主题:有序晶体材料表征、无序晶体材料表征和声子计算。
图7. 材料表征学习过程。首先非晶态材料转化为晶体图表征,随后作为晶体图消息传递神经网络的输入;然后模型被训练以准确预测晶体的性质。
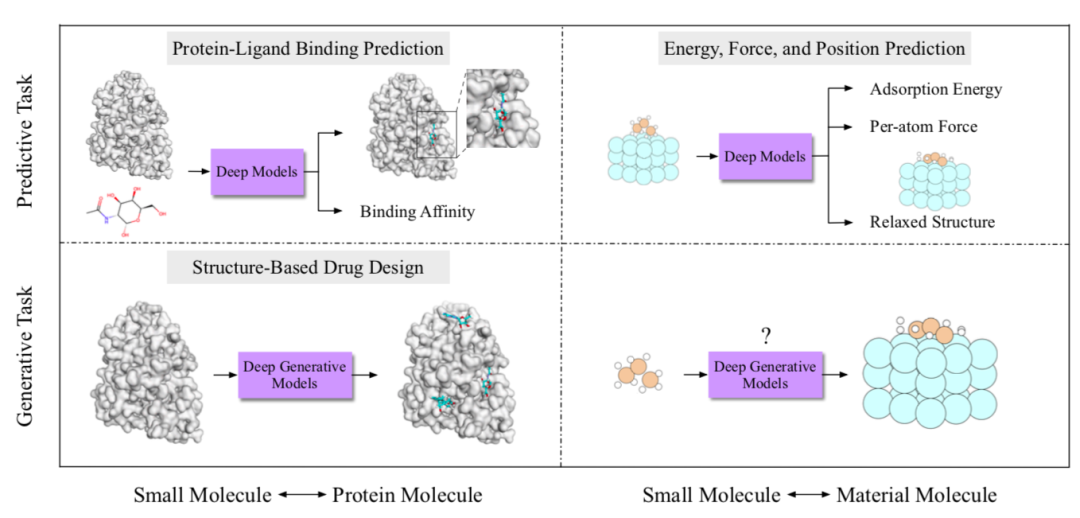
分子相互作用研究分子如何相互作用以执行许多物理和生物功能。机器学习的最新进展激发了对各种分子相互作用的建模,例如配体-受体相互作用、分子-材料相互作用。本文对这些进展进行了深入和全面的回顾,重点关注小分子、蛋白质或材料的相互作用。
图8. 分子相互作用研究概览。对于分子-蛋白质相互作用、分子-材料相互作用,将已有任务分为预测任务和生成任务。
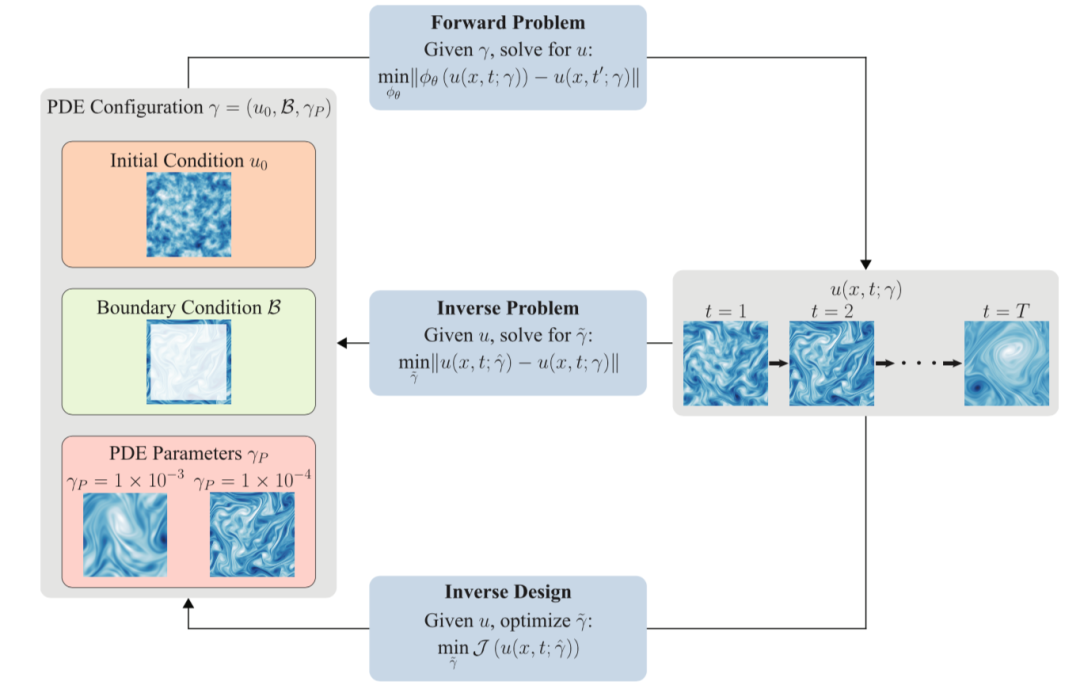
连续介质力学(Continuum Mechanics)用偏微分方程(PDE)对宏观尺度上随时间和空间演化的物理过程进行建模,包括流体流动、热传导和电磁波等。然而,使用传统求解方法解决偏微分方程存在一些限制,包括效率低、难以进行分布外泛化和多分辨率分析。本文综述了近期用于解决这些限制的代理模型的深度学习方法,包括前向问题以及逆向问题和逆向设计。
图9. (左)多尺度动力学。许多系统展示出从局部到全局尺度的相互作用部分的动力学。比如湍流流动具有一系列衰减到最小尺度的层级涡旋。构建具有多尺度处理机制的机器学习模型对于高保真度模拟至关重要。这些机制在每个尺度上聚合信息,以更新每个格点的潜在表征。这里是一个按顺序在每个尺度上执行聚合和更新机制的可视化。(右)前向问题、逆向问题和逆向设计的说明和比较。
除了各个科学领域特有的挑战,AI for science 的多个领域还存在一些共同的技术挑战。本文提出了四个常见的技术挑战:分布外泛化,可解释性,基于自监督学习的基础模型,和不确定性量化。AI 和机器学习领域早已认识到这些挑战,但在 AI for science 背景下,由于数据和任务的独特特点,这些挑战变得更加重要。
科学的目标是理解物理世界的规律。AI for science 的目标是(1)设计能够准确建模物理世界的模型,以及(2)解释模型以验证或发现物理规律。因此,可解释性对于 AI for science 至关重要。
例如,几何深度学习(Geometric deep learning,GDL)模型在量子、分子、材料和蛋白质科学等领域展现出巨大潜力。然而大多数几何深度学习模型缺乏可解释性,通常被视为黑盒,为了评估模型结果的科学合理性,实现可解释性非常重要。本文探讨了将可解释人工智能(explainable artificial intelligence,XAI)与模型相结合以提高可解释性。XAI 旨在追踪模型的输入如何决定输出,来增加预测的可信度;还可以测试模型预测是否符合物理定律,从而有助于提高现有几何深度学习模型的质量。对模型的精确解释技术可以为领域专家提供对模型学习到的底层机制的深入洞察,帮助从模型中获得知识可以指导未来的研究方向。
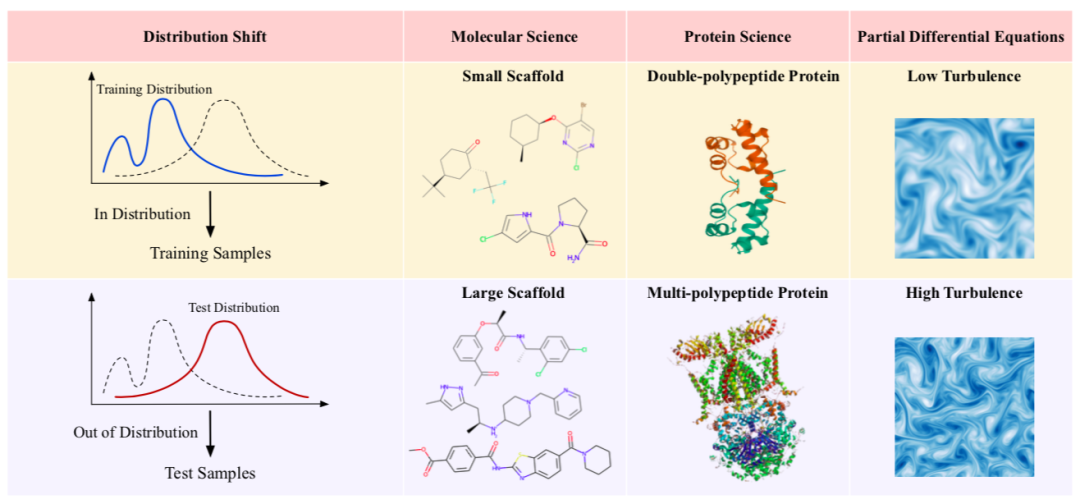
传统的机器学习方法假设训练数据和测试数据遵循相同的分布,然而在现实中,训练数据和测试数据之间可能存在不同的分布偏移,这就需要识别能够进行分布外泛化的因果关系。这个问题与多个领域都有关联,包括迁移学习、领域适应、领域泛化、因果、不变学习等。分布外泛化对于科学模拟尤为重要,因为这样可以避免为每个不同的设置生成训练数据,此外也可以提高科学发现模型的任务表现和泛化能力。
图10. AI for science 领域的分布外泛化问题。科学领域的分布外泛化问题普遍存在。在分子科学中,不同的分子大小和骨架是分布偏移的主要来源。在蛋白质科学中,三维蛋白质结构的复杂性,以及蛋白质构成和折叠的潜在变化的广泛性,使得泛化到不同分布成为艰巨的挑战。对于偏微分方程,在时间演化建模中从高粘度泛化到低粘度是一项困难的任务,因为低粘度会导致更多的湍流流动,产生更多的混沌动力学,让建模充满挑战。
深度模型的监督学习通常需要大量标记数据,然而对于科学发现,获取标记数据可能面临特殊的挑战,例如需要专业领域知识、高昂的计算或实验成本,或者物理限制等因素。当标记的训练数据不容易获取时,进行无监督学习或少样本学习的能力变得重要。这些困难催生了一个新兴的研究领域——自监督学习(self-supervised learning,SSL)。自监督学习技术使得深度模型能够利用无标签数据,并学习现实数据的先验知识,例如物理规律和对称性,而无需依赖大量标记的数据集。
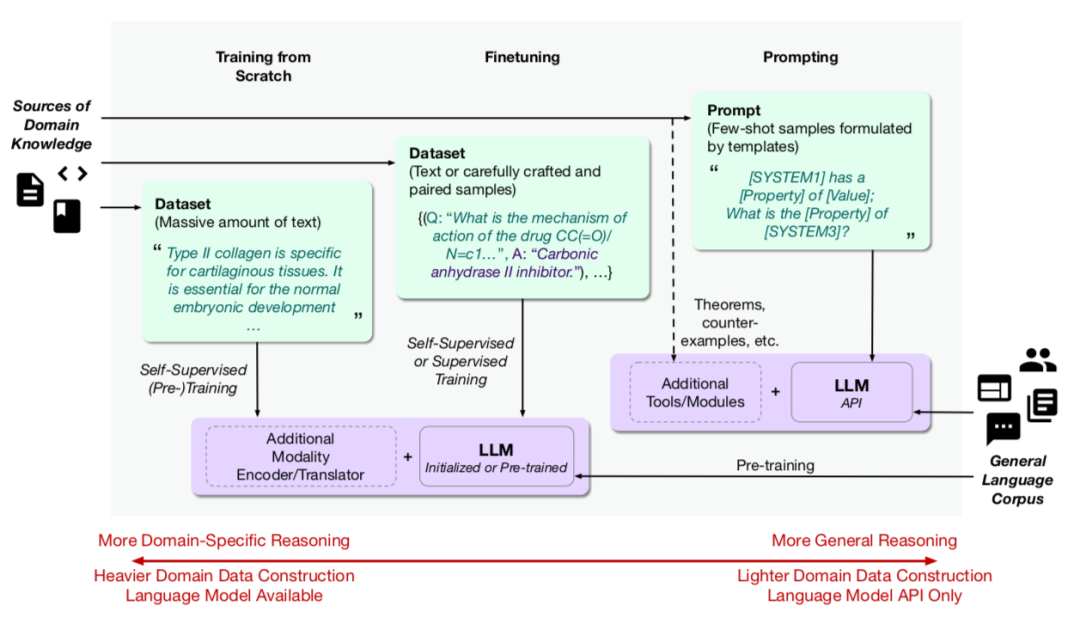
基础模型(Foundation Models)基于自监督学习,将这种利用无任务标签数据的思想推向极致。基础模型通常是在自监督或可泛化监督下进行预训练的大规模模型,允许在少样本或零样本的方式下执行各种下游任务。而最近以 GPT-4 为代表的大语言模型(Large Language Models,LLMs)是迄今为止最通用和强大的基础模型,归功于文本数据中包含的无标签的丰富监督。大语言模型还能够实现更灵活的知识捕获和迁移,这归功于它在包括物理学、计算机科学、化学、生物学、医学等科学领域中具有强大的知识获取和推理能力。
大语言模型在科学领域最令人兴奋的一个应用是生成建模。虽然幻觉(hallucination)是许多大语言模型用例中常见的问题,但对于发现新药物、材料和研究思路来说,这反而成为一种优势。到目前为止,由自监督学习驱动的基础模型和大语言模型,是解决标签获取困难并使 AI 应用于更广泛科学问题的最有前景的方向之一。本文探讨了基础模型和大语言模型如何加速 AI for science。
图11. 将大语言模型应用于科学领域的三种范式。(1)一种方法是构建由大量科学领域的文本组成的数据集,并以自监督的方式从头开始训练大语言模型。训练好的模型可以直接使用,或进一步微调以用于特定任务。(2)另一种方法是使用较少量的科学领域文本数据,以自监督的方式或配对样本的监督方式,对预训练的通用大语言模型进行微调。(3)对于具有 API 访问权限的专有大语言模型,可以通过使用精心设计的模板进行提示来训练模型,这里领域知识作为提示中的少样本、或者作为具有附加工具或模块的显式知识提供。
参看 AI+Science 读书会张坤老师团队和多位学者关于因果科学、科学发现与大模型的讨论:
重磅圆桌:因果推理、科学发现与大模型
https://pattern.swarma.org/study_group_issue/460
刘子鸣等人关于大语言模型和 AI for science 的讨论:
Science for LLM and LLM for Science
https://pattern.swarma.org/study_group_issue/446
不确定性量化(Uncertainty Quantification,UQ)研究面对数据和模型的不确定性,如何确保鲁棒的决策,这是 AI for science 的关键部分。不确定性量化在应用数学、计算和信息科学的各个方向进行了研究,包括科学计算、统计建模、机器学习等。本文提供了科学发现背景下不确定性量化的最新综述。
AI 的进步为加速科学发现、推动创新和解决各个领域的复杂问题提供了巨大潜力。然而,要充分发挥这种潜力,我们面临着教育、人才培养和公众参与等方面的新挑战。本文汇总了AI 和科学各个领域的现有资源,并就如何更好地促进 AI 与科学和教育的融合提供了观点。
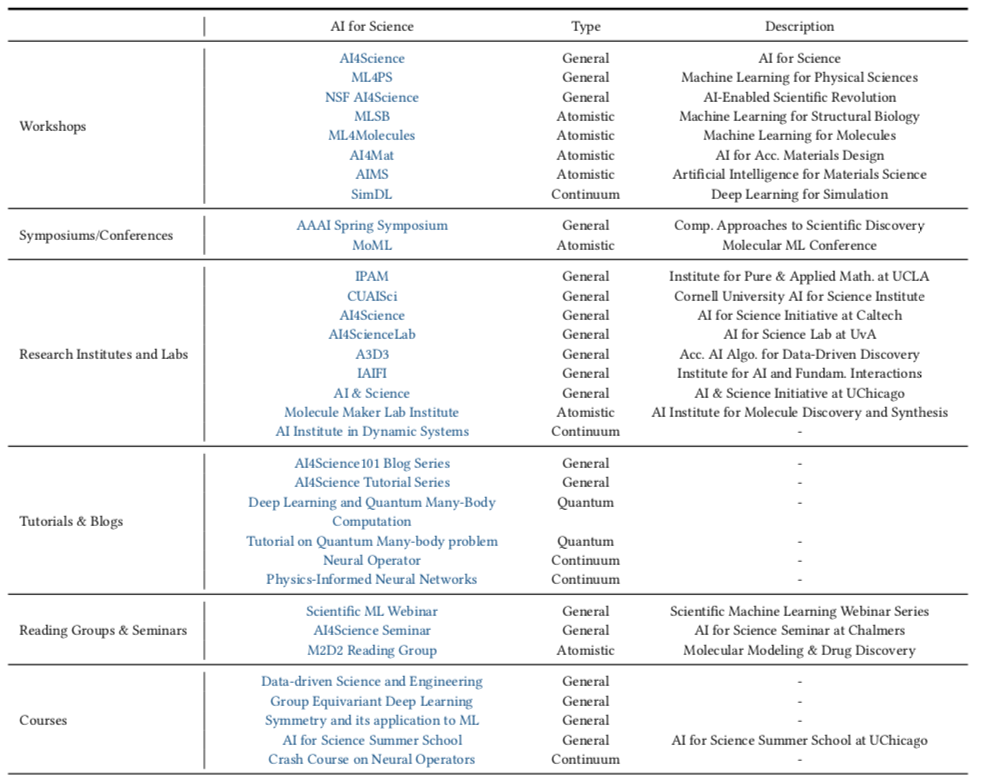
图12. AI for Science 学习资源汇总(详情请参考原论文 Table 35)
AI for Science 是一个新兴且快速发展的研究领域。为了对这项工作进行持续更新,研究者们创建了一个在线门户网站(https://air4.science/),包含 AI for Science 领域的思维导图,涵盖了上述各个领域的分类结构,用户可以此作为全面概览在其中导航,探索各个领域的新主题和重大进展。本文还附带了一个软件库和基准测试:AIRS: AI Research for Science(https://github.com/divelab/AIRS/)。
图13. 用户可以访问研究者创建的网站:https://air4.science/,探索 AI for Science 的各个领域。
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合西湖大学工学院AI方向助理教授吴泰霖、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣,共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
集智学园最新AI课程,
张江教授亲授:第三代人工智能技术基础
——从可微分编程到因果推理
自1956年“人工智能”诞生于达特茅斯会议以来,已经经历了从早期的以符号推理为主体的第一代人工智能,和以深度神经网络、机器学习为主体的第二代人工智能。ChatGPT的横空出世、生成式AI的普及、AI for Science等新领域的突破,标志着第三代人工智能的呼之欲出。可微分编程、神经微分方程、自监督学习、生成式模型、Transformer、基于图网络的学习与推理、因果表征与因果推断,基于世界模型的强化学习……,所有这些脱胎于前两代人工智能的技术要素很有可能将构成第三代人工智能的理论与技术的基础。
本课程试图系统梳理从机器学习到大语言模型,从图神经网络到因果推理等一系列可能成为第三代人工智能基础的技术要素,为研究者或学生在生成式AI、大模型、AI for Science等相关领域的学习和研究工作奠定基础。
https://campus.swarma.org/course/5084?from=wechat
推荐阅读