2023,大模型如何改变自然与社会科学?

导语

一、1.7万篇大模型论文展现的研究趋势
二、AI + Science狂飙突进
三、大模型在社会科学中的应用
四、大模型像人类一样思考
五、总结
一、1.7万篇大模型论文展现的研究趋势
一、1.7万篇大模型论文展现的研究趋势
[1] Topics, Authors, and Networks in Large Language Model Research: Trends from a Survey of 17K arXiv Papers
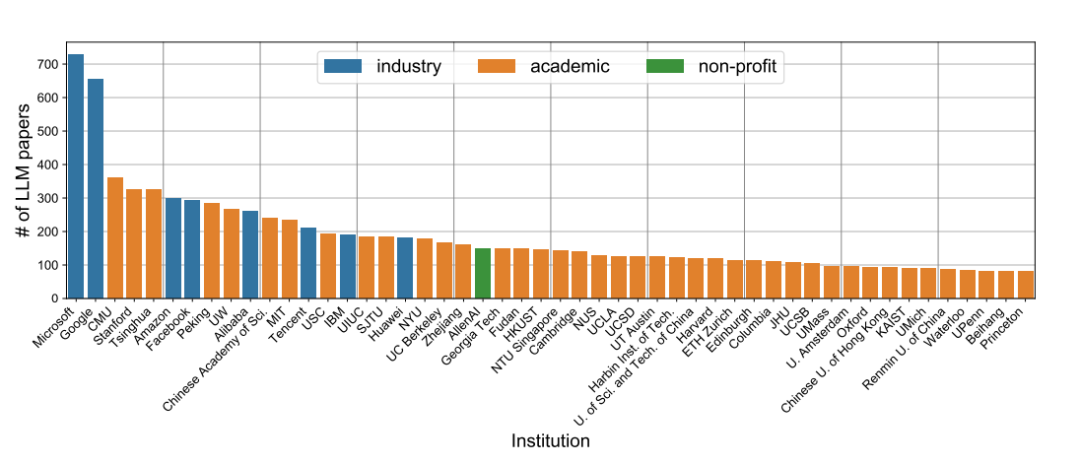
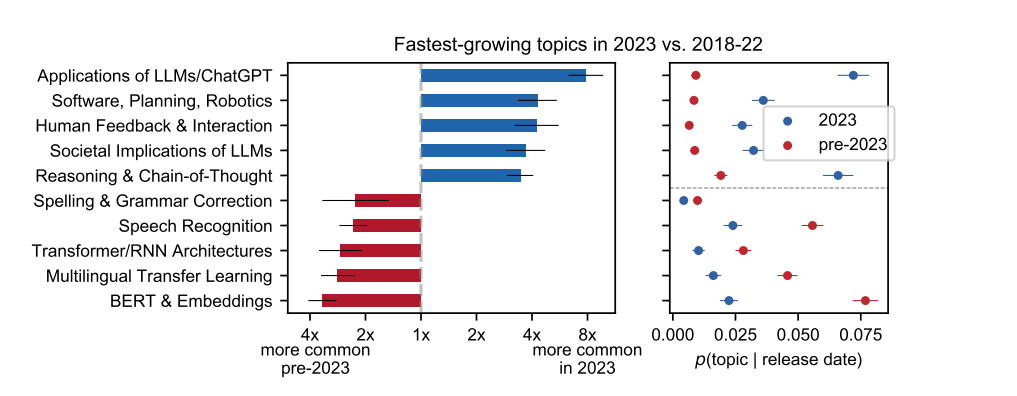
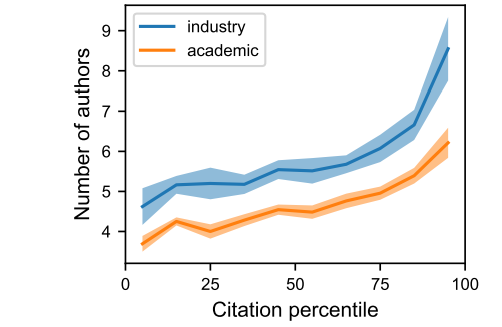
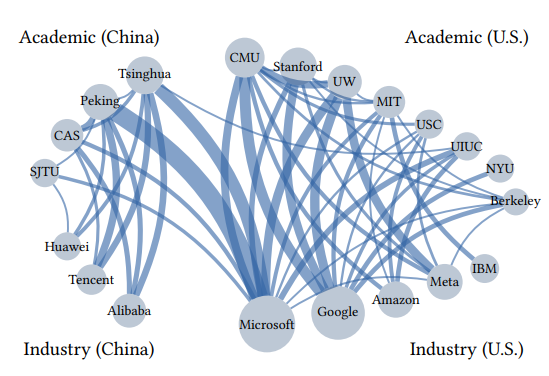
图4:中美大模型论文合作网络,点的大小代表论文发表数量,线的粗细代表合著数量
二、AI + Science 狂飙突进
二、AI + Science 狂飙突进
[2]Boiko, D.A., MacKnight, R., Kline, B. et al. Autonomous chemical research with large language models. Nature 624, 570–578 (2023).
《Nature速递:基于大语言模型的自动化学研究》 [3] Zeming Lin et al.,Evolutionary-scale prediction of atomic-level protein structure with a language model.Science379,1123-1130(2023).DOI:10.1126/science.ade2574 《Science前沿:大语言模型涌现演化信息,加速蛋白质结构预测》 [4] Contrastive learning in protein language space predicts interactions between drugs and protein targets, Proceedings of the National Academy of Sciences (2023). [5] Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering—Example of ChatGPT [6] Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy, arXiv (2023) [7] DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation 《大语言模型做科研的N种可能性:从自主进行科学实验到写综述文章》 《Max Tegmark 组:大模型学习到时间和空间的结构化知识》
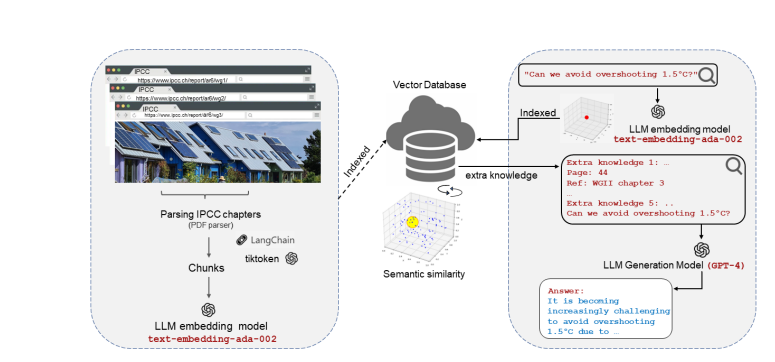
[8] Large language models encode clinical knowledge. Nature 620, 172–180 (2023) 《Nature 速递:大语言模型编码临床知识》 [9] chatIPCC: Grounding Conversational AI in Climate Science 《Nature 速递:大模型训练医学全才 AI》
[10] Interpretability at Scale: Identifying Causal Mechanisms in Alpaca 《解释大语言模型:在 Alpaca 中识别因果机制》 《因果推理与大语言模型:开辟因果关系的新前沿》 [11] Mathematical discoveries from program search with large language models. Nature (2023). 《Nature 速递:利用大模型程序搜索产生数学发现》
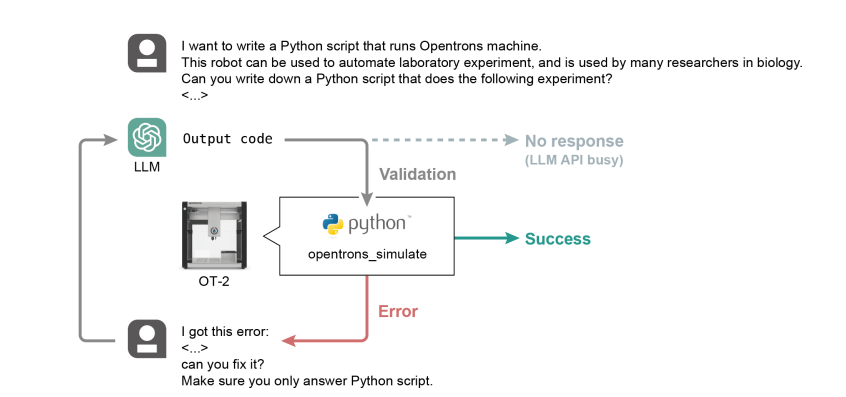
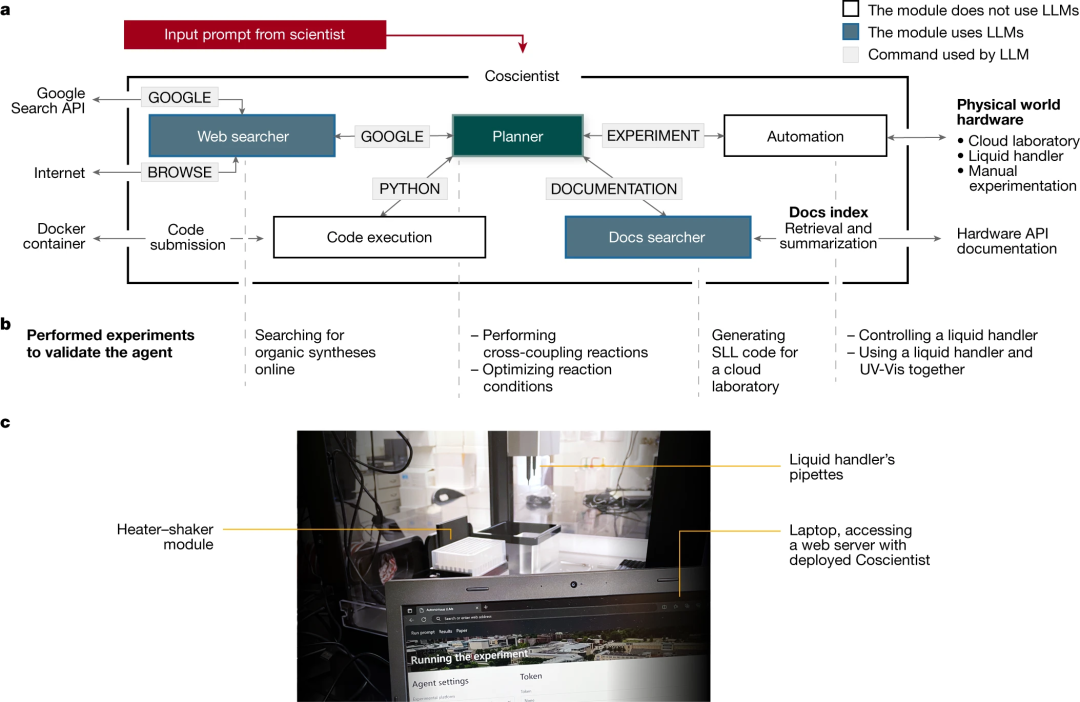
图7:Coscientist的系统架构。将大语言模型与互联网和文档搜索、代码执行和实验自动化等工具相结合。
Nature速递:基于大语言模型的自动化学研究
三、大模型在社会科学中的应用
三、大模型在社会科学中的应用
-
教育领域

[12] Using artificial intelligence to assess personal qualities in college admissions
-
政治科学
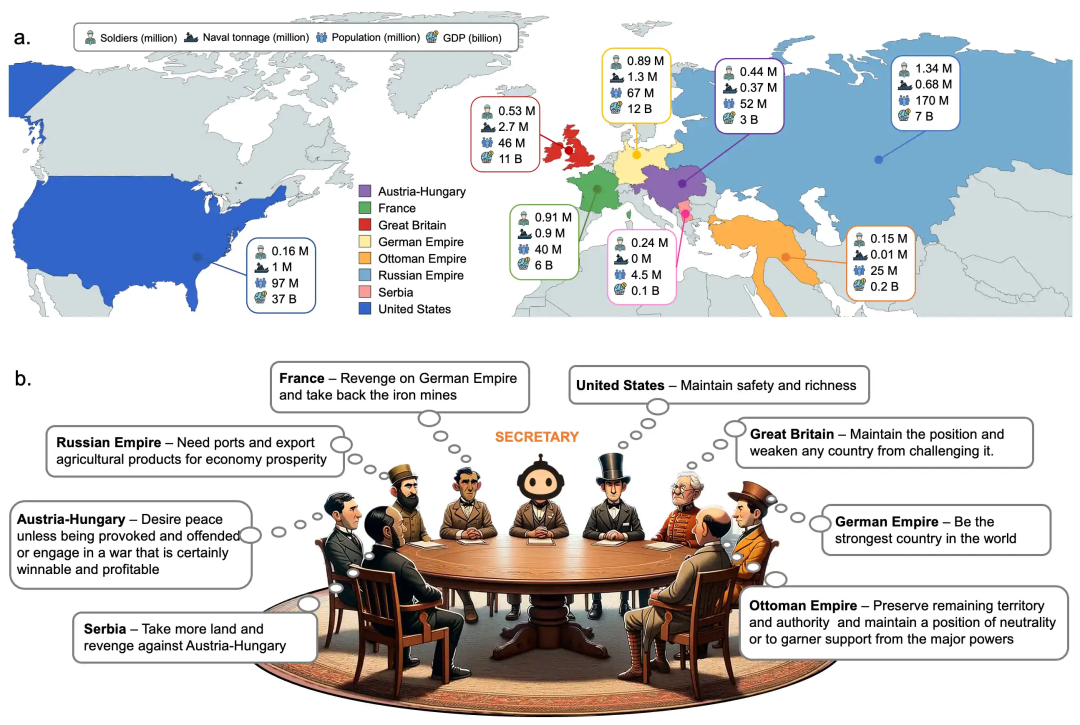
[13] War and Peace (WarAgent): Large Language Model-based Multi-Agent Simulation of World Wars
-
经济领域
[14] Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models
-
新闻传播
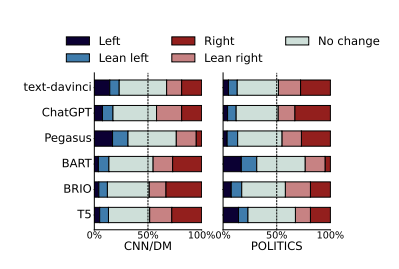
[15] Adapting Fake News Detection to the Era of Large Language Models [16] What Constitutes a Faithful Summary? Preserving Author Perspectives in News Summarization
-
社会科学
《AI学习600万人生活事件序列,预测人类生活轨迹》
-
学术发表
[17] Can large language models provide useful feedback on research papers? A large-scale empirical analysis
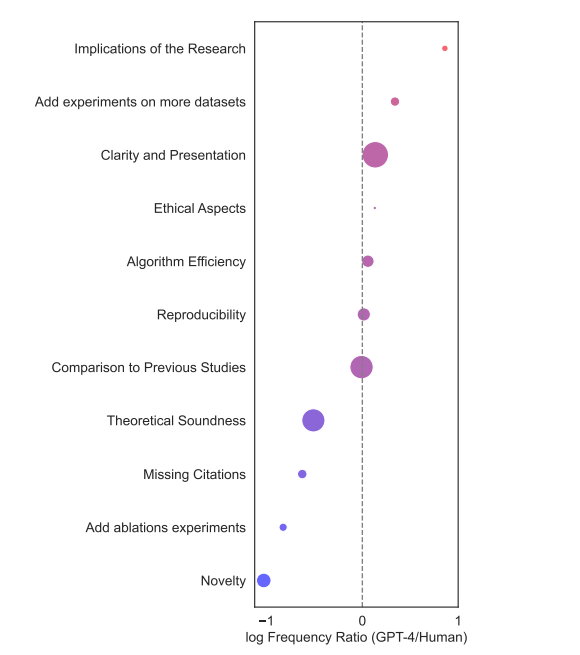
图11:GPT和人类在论文评审时关键领域的相对差异,可以看出人类关注论文的新颖性,而大模型更关注表述是否清晰
[18] Psychological factors underlying attitudes toward AI tools. Nat Hum Behav 7, 1845–1854 (2023).
四、大模型像人类一样思考
四、大模型像人类一样思考
《ChatGPT 为啥那么牛?语言模型足够大就会涌现出新能力》
-
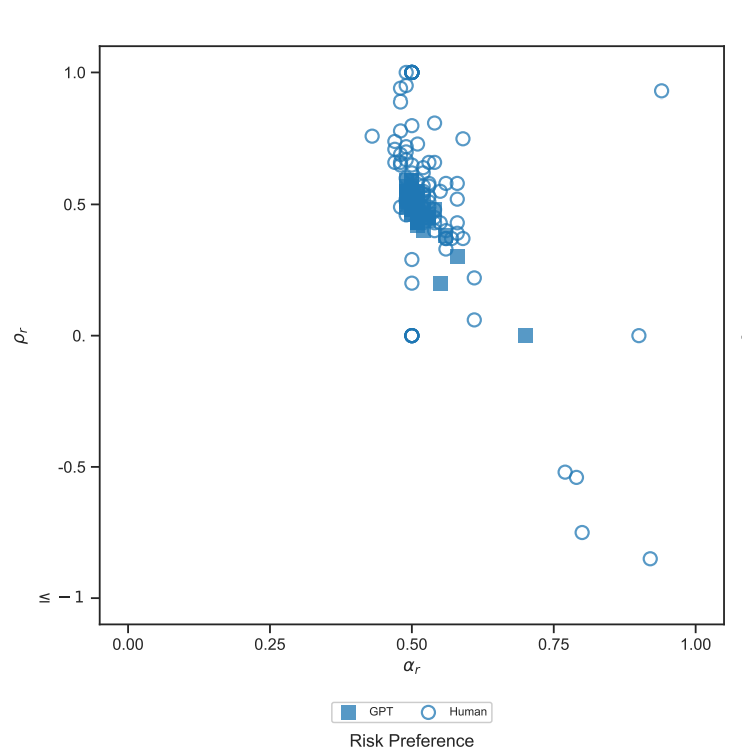
具有经济理性
[19] The emergence of economic rationality of GPT
-
博弈行为
[20] Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis

-
AI Agent 社交互动
[21] Emergence of Scale free Networks in Social Interactions among Large Language Models 《前沿进展:大模型agent的社交互动涌现出无标度网络》 《多主体智能综述:社会互动启发的人工智能进化》
-
偏见与道德观念
[22] Gender stereotypes embedded in natural language are stronger in more economically developed and individualistic countries. https://academic.oup.com/pnasnexus/article/2/11/pgad355/7429364
[23] Assessing LLMs for Moral Value Pluralism
-
价值对齐
[24] SoulChat: Improving LLMs’ Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations [25] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt [26] Learning and Forgetting Unsafe Examples in Large Language Models
数字世界中的大模型Agent:机遇与风险 万字长文详解:大模型时代AI价值对齐的问题、对策和展望 集智×安远AI :OpenAI风波背后,如何&谁来确保AGI安全? 人机共生的大模型伦理与价值观挑战|集智俱乐部20周年AIS²年会
五、总结
五、总结
[27] Mitchell M, Krakauer D C. The debate over understanding in AI’s large language models[J]. PNAS, 2023 《圣塔菲学者:AI 大语言模型真的理解人类语言吗?》
[28] Emergent analogical reasoning in large language models. Nature Human Behaviour, 2023
大模型与AI+Science读书会



推荐阅读
微信扫一扫,分享到朋友圈











