基于有效信息的因果涌现理论|集智百科

导语
所谓的因果涌现是指对于同一个系统,其宏观的因果效应强度大于微观的现象。而基于有效信息的因果涌现理论是一种最早定量刻画因果涌现现象的理论,该理论由Erik Hoel等人于[1]一文中提出,文章定义了一种因果效应度量指标,即有效信息,并将之用于量化一个马尔科夫动力学的因果性强弱,并在此基础上定义了因果涌现。在这个框架下,因果涌现被定义为伴随着我们对同一个系统的观察尺度从微观过渡到宏观,它的马尔科夫动力学的有效信息度量会提高的现象。其中,宏观动力学可以由对微观动力学的粗粒化操作而得到。通常,针对一个系统的粗粒化方案有很多,而Hoel的因果涌现框架需要找到使宏观动力学有效信息最大的最优粗粒化方法,即,如果经过最优粗粒化的宏观动力学的有效信息大于微观动力学的有效信息,则表明系统发生了因果涌现现象。
集智百科已经对因果涌现,有效信息等推出了精品词条,而本词条将从另一角度出发,重点回顾和拆解Erik早期论文中的实例,并给出了由布尔网络动力学转换为马尔科夫链的TPM的算法思路,可加深对基于有效信息的因果涌现理论的理解。
为了系统梳理因果涌现最新进展,北京师范大学系统科学学院教授、集智俱乐部创始人张江老师领衔发起「因果涌现第六季」读书会,读书会将从2025年3月16日开始,每周日早9:00-11:00,持续时间预计10周左右。每周进行线上会议,与主讲人等社区成员当面交流,之后可以获得视频回放持续学习。诚挚邀请领域内研究者、寻求跨领域融合的研究者加入,共同探讨。
“集智百科精选”是一个长期专栏,持续为大家推送复杂性科学相关的基本概念和资源信息。作为集智俱乐部的开源科学项目,集智百科希望打造复杂性科学领域最全面的百科全书,欢迎对复杂性科学感兴趣、热爱知识整理和分享的朋友加入,文末可以扫码报名加入百科志愿者!

↑↑↑扫码直达百科词条
彭晨 | 作者
目录
2. 基本概念
2.1 有效信息
2.2 粗粒化映射
2.2.1 粗粒化的一般性讨论
2.2.2 基于变量的粗粒化
2.3 因果涌现度量
2.4 因果涌现与因果容量
3. 因果涌现实例
3.1 基于状态空间的粗粒化计算因果涌现实例
3.2 基于变量空间的粗粒化计算因果涌现实例
3.2.1 空间因果涌现
3.2.1.1 提高确定性实例分析
3.2.1.2 抵消简并性实例分析
3.2.2 时间因果涌现
3.2.3 时空因果涌现
3.2.4 变量外部化导致的因果涌现
3.2.4.1 冻结外部化变量
3.2.4.2 黑盒化外部变量
4. 缺陷与争议
5. 由布尔网络动力学转换为马尔科夫链的TPM的代码
1. 历史渊源
1. 历史渊源
首先,因果涌现的基本思想,即通过粗粒化而得到因果效应更强的系统可以追溯到Crutchfield等人的计算力学理论,以及Seth等人提出的格兰杰涌现等理论框架。然而,正式的因果涌现理论的提出则要等到2013年。
这一年,Erik Hoel在美国科学院院刊(PNAS)上发表文章[1],首次使用了有效信息指标用来定量描述涌现现象,并提出了因果涌现理论。其中,有效信息这一指标的提出可以追溯到Giulio Tononi等人在2003年的文章[2]。在这篇文章中,有效信息是作为整合信息论中度量复杂系统信息整合能力的一部分而提出的。2013年,Erik Hoel与Tononi和Albantakis合作将有效信息应用到了因果涌现概念的刻画上。
根据因果涌现理论,一个马尔科夫动力系统中微观状态的转移规则,即微观动力学或微观的因果机制(Causal Mechanism)是已知的。在此基础上,将多个微观状态进行合并,即文中所表述的粗粒化映射,可以得到相应的宏观状态,而微观动力学也被相应地粗粒化为宏观动力学。其中,微观动力学或因果机制是富含所有信息的,宏观动力学或因果机制是随附于(Supervene)微观因果机制的。因果涌现现象被描述为:粗粒化后的宏观动力学的因果效应高于微观动力学的因果效应。其中,因果效应的度量是使用有效信息这一指标完成的。这一指标被定义为干预下的互信息,即将系统上一时刻的状态(即因变量)干预为均匀分布,然后计算上一时刻和下一时刻状态(即动力学的因变量和果变量)之间的互信息大小。这种定义反映了因与果状态被动力学即因果机制约束的强度,也就是因果效应的强度。通过这种干预操作,最终的有效信息仅仅是动力学即因果机制的函数,而与因变量的分布无关。
2017年,Erik Hoel在[3]中引入了信息论中香农定义的“信道容量”(information channel capacity)这一概念,提出动力系统中也存在类似的“因果容量”(Causal Capacity)的概念。
香农发现,信道上的信息传输速率对输入信号概率分布非常敏感,因此选择使系统输入输出互信息最大化的输入分布来定义信道容量,这一定义反映了信道允许可靠传输信息的最大速率。
类似地,在因果性度量中,根据定义,改变粗粒化操作也会改变系统宏观动力学的有效信息,这是因为粗粒化操作在从微观映射到宏观层次的过程中实际改变了动力学,因而发生了因果机制的变化,这是因果涌现现象存在的前提。除了13年提出的粗粒化方式,即通过合并一些变量为宏观变量[1]这一方式以外,作者还提出了另一种粗粒化系统的方式,即将部分变量视为外生变量,例如设置这些变量的取值,让它们一直保持初始状态,或视其为“黑盒”从而随机取值,这样的设置可以提升系统本身的因果效应强度,因此是另一种因果涌现现象。这种方式也可以看作是一种粗粒化操作,这是系统的状态变量随着将一些变量外部化而减少了。那么,因果容量就被定义为一个系统以粗粒化的方式而改变动力学因果效应强度的能力。Erik Hoel还提出一个普遍的原则:系统中可使用的改变干预分布的方式越多,因果容量就越接近信道容量。
2. 基本概念
2. 基本概念
复杂系统在宏观尺度和微观尺度有着不同的刻画和描述,体现为从不同的尺度去看一个复杂系统的时候,会得到完全不同的模式与动力学。当一个系统在宏观尺度能够展现出比它的微观尺度更强的因果效应,我们就称之为发生了因果涌现。
根据Erik Hoel的基于“有效信息”(Effective Information)的理论,如果系统的动力学——即马尔科夫转移矩阵,以及粗粒化策略给定,就可以通过分别计算原马尔科夫矩阵和粗粒化后的马尔科夫矩阵的有效信息(EI),从而判断因果涌现是否发生。
下图是对该理论的一个抽象框架,其中,横坐标表示时间,纵坐标表示尺度(Scale),该框架可以看成是对同一个动力系统在微观和宏观两种尺度上的描述(详细介绍请阅读因果涌现:用因果量化复杂系统中的涌现|集智百科)。
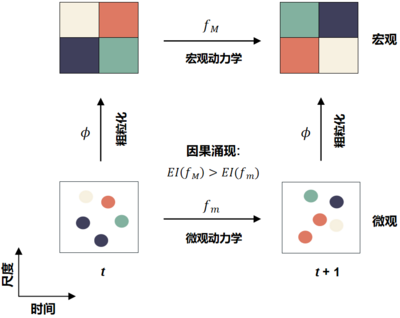
其中,fm 表示微观动力学,fM 表示宏观动力学,宏观的状态和微观的状态通过一个粗粒化函数 ϕ相连。在一个离散状态的马尔科夫动力系统中,fm 和 fM 都是马尔科夫链,对 fm 进行马尔科夫链的粗粒化,就可以得到 fM。EI 是有效信息的度量。由于微观动力学可能具有更大的随机性,这导致微观动力学的因果效应强度比较弱,所以通过粗粒化,就有可能得到一个因果效应更强的宏观动力学。所谓的因果涌现,就是指粗粒化操作使得动力学的有效信息会增加这一现象,并且宏观动力学与微观动力学的有效信息之差被定义为因果涌现强度。
2.1 有效信息
正式进入实例计算前,在此简要回顾一下有效信息的计算(详细介绍可参考全网最全总结!因果涌现核心指标“有效信息”|集智百科):
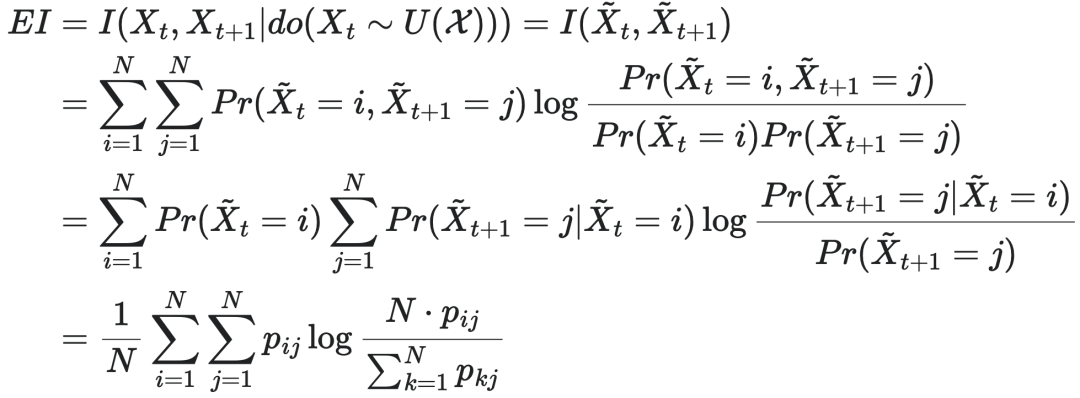
其中 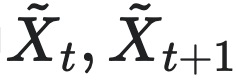 分别为把t时刻的Xt干预为均匀分布后,前后两个时刻的状态,而EI度量的就是在干预操作后,系统前后两个时刻状态之间的互信息。pij为第i个状态转移到第j个状态的转移概率。从这个式子,不难看出,EI仅仅是离散马尔科夫链概率转移矩阵P的函数。进一步,如果马尔科夫链TPM按照行向量形式处理,EI可以写成更加简便的形式
分别为把t时刻的Xt干预为均匀分布后,前后两个时刻的状态,而EI度量的就是在干预操作后,系统前后两个时刻状态之间的互信息。pij为第i个状态转移到第j个状态的转移概率。从这个式子,不难看出,EI仅仅是离散马尔科夫链概率转移矩阵P的函数。进一步,如果马尔科夫链TPM按照行向量形式处理,EI可以写成更加简便的形式 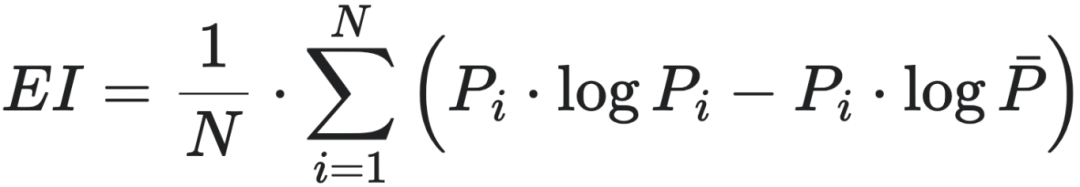 ,其中,Pi是矩阵P的第i个行向量。
,其中,Pi是矩阵P的第i个行向量。
2.2 粗粒化映射
对于一个给定的马尔科夫链χ,它的状态空间为Sm,其中状态数为N,动力学,即转移概率矩阵为fm。
2.2.1 粗粒化的一般性讨论
对马尔科夫概率转移矩阵实施粗粒化的步骤,可分为三步:
1. 对状态空间进行粗粒化ϕ:即一种对微观状态做粗粒化分组的方案ϕ:Sm→SM,其中SM代表宏观态集合,该集合的元素个数为(M≤N)。值得注意的是,这种状态空间的划分方法可以分为基于状态和基于变量这两类。虽然二者本质上是一样的,即基于变量的划分也是对状态划分的一个特例,但基于变量时,属于同一个变量的状态需绑定在一起进行划分,不能分割开。
2. 状态空间的分组ϕ自然诱导了一个状态空间上的状态分布的映射,即:ϕ:P(sm)→P(sM),其中sm∈Sm,sM∈SM为微观或宏观的状态变量,P为概率。
3. 对转移概率矩阵(TPM)进行粗粒化:基于第一步的分组方式,状态合并后的概率转移矩阵也必须发生相应的变化,即需要对整个马尔科夫转移概率矩阵做粗粒化。这实际上定义了一个新的映射Φ:Fm→FM,其中Fm,FM分别为状态空间Sm和SM上定义的所有可能的转移概率矩阵。
2.2.2 基于变量的粗粒化
上述粗粒化的定义是针对状态空间进行的,它是最普适的情况。然而,需要注意的是,在Erik Hoel的2013年原始文章中,作者们的讨论却是从基于变量的粗粒化方案出发的,即对变量空间进行分组、归并(原文使用“grouping分组”来描述这一过程)。这种粗粒化方案又包括:直接针对变量进行的空间粗粒化,和对变量的动力学(即,概率转移矩阵TPM)进行的时间粗粒化,以及将变量“移出”系统的变量外部化操作三种,下面将详细介绍这几种粗粒化是如何进行的。
1.空间粗粒化:针对微观变量进行分组归并,将原状态空间进行粗粒化映射得到合并后的变量的状态空间。以两个布尔变量为例,这两个变量共有四种微观态Sm={00,01,10,11},首先将这两个微观变量归并为一个宏观变量,再对变量状态空间按照M:[00,01,10]=off, [11]=on的规则归并,最终保持宏观变量的布尔属性。粗粒化的结果是一个宏观变量,对应两个宏观态SM={on,off}。
2.时间粗粒化:粗粒化针对的不再是微观变量,而是微观动力学,即归并两个接续时间步的微观动力学,从而重新定义马尔科夫动力学。在这种操作中,首先需要扩充变量的状态空间,使得任意两步接续的状态打包在一起作为一个微观变量,其次再考虑这个新微观变量的粗粒化形成宏观变量,最后考虑这个宏观变量的动力学。例如,一个系统下一时刻的微观态不仅依赖当前时刻的状态,还依赖于前一个时间步的状态,这种情况通常称为二阶马尔科夫性质。这种性质下,可以将两个微观动力学时间步粗粒化为一个宏观时间步,可以得到时间粗粒化后的宏观系统(详细讨论见下面时间因果涌现实例部分)。
3.变量外部化:这种方法不涉及状态的合并,而是试图将系统中的部分变量移出考虑的范畴,从而减少变量的数量,形成一个新的待考察的内部系统。Erik Hoel在2017年的文章中称此类变量为外生变量(exogenous element),并提出了两种具体处理外部化变量的方式:一种方式称为将外生变量“冻结”,即将其设定为特定的状态,该变量在后续变化中将一直保持该初始状态,不影响系统中其他变量;另一种是将外生变量设为“黑箱”(black boxing),允许其随机变化,但是具体变化情况和对系统的影响都无法查看(不在最后模型的考虑范围内)。变量外部化方式是通过减少系统的状态变量的方式,达到了和一般的将变量归并分组的粗粒化方式一样的效果,即让系统总的状态空间减小,且可能导致EI增大。
通常,我们可以有很多方式对一个系统的微观动力学进行粗粒化。我们可以通过粗粒化后得到的宏观动力学的有效信息来衡量不同粗粒化方案的优劣,有效信息最大的宏观动力学,对应的粗粒化方案被认为是最优的。在Erik Hoel的因果涌现理论中,因果涌现是定义在最优粗粒化方案上的,即最优粗粒化方案下的动力学的有效信息增加了,即发生了因果涌现。注:Erik Hoel论文中的因果涌现实例,都是最优粗粒化方案的结果,即对应的宏观TPM有效信息是最大化的。
同时,值得指出的是,并不是任意的粗粒化方案都是良定义的。所谓的良定义是指,我们要求粗粒化后的TPM仍然是一个合法的TPM,而且粗粒化后的宏观动力学应该与微观动力学保持一致性——即先进行演化操作然后粗粒化和先进行粗粒化操作再演化应该得到一致的宏观态分布。通过最大化粗粒化后的TPM的有效信息这一方案,并不一定满足宏观TPM仍然是良定义的,因此,关于马尔科夫链粗粒化的方法存在着较大的争议。详见论文[4]以及因果涌现词条。更详细具体的描述,请参考马尔科夫链的粗粒化。
2.3 因果涌现度量
基于有效信息的定义,我们可以量化系统粗粒化前后因果效应的变化值,并用此变化值来度量因果涌现的强度。
因此,一个马尔科夫动力系统的因果涌现指标CE可以被定义为:
CE=EI(fM)−EI(fm)
这里fm为微观态的马尔科夫概率转移矩阵,维度为:N×N,N为微观态数;而fM为对fm做粗粒化操作之后得到的宏观态的马尔科夫概率转移矩阵,维度为M×M,其中M<N为宏观态数。
如果计算得出的CE>0,则称该系统发生了因果涌现,否则没有发生。有时,我们也会根据归一化的EI来计算因果涌现度量,消除系统尺寸的影响,即定义:
ce=Eff(fM)−Eff(fm)
这里Eff(f)≡EI/log2N定义为动力学f的有效性,N为f中的状态数。
因此,因果涌现的度量可以拆解出两种效应:1.系统动力学的有效性(Eff)的提升 ΔIEff;2.状态空间的尺度效应 ΔISize。即我们有:CE=ΔIEff+ΔISize
其中,
ΔIEff=(Eff(fM)−Eff(fm))⋅log2M=ce⋅log2M
为由系统动力学的有效性提升而引发的因果涌现效应,其中M为宏观状态数。
以及:
ΔISize=Eff(fm)⋅(log2M−log2N)
即由系统的状态空间的减小而引发的因果涌现效应。
由于粗粒化的过程带来状态空间减小,所以ΔISize总是为负;若要CE>0,即因果涌现发生,那么ΔIEff必须为正值,且粗粒化带来的有效性提升幅度要超过状态空间缩减所导致的EI减小的幅度。
2.4 因果涌现与因果容量
Erik Hoel还提出因果涌现理论与Claude Shannon的信息论之间的联系[3]。信息论中信息传输需要经过信道,信道由两个变量X和Y组成,分别为信道的输入和输出。对于任意的X和Y的取值x,y,我们可以定义一个转移概率p(y|x),且满足:p(y|x)≥0,以及对于每个x,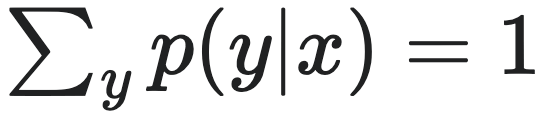 。因此,由所有X和Y的取值,我们可以定义一个信道矩阵(即TPM)。信道的性质显然由该TPM决定。
。因此,由所有X和Y的取值,我们可以定义一个信道矩阵(即TPM)。信道的性质显然由该TPM决定。
同样,对于一个马尔科夫动力学的前后两个状态是受限于动力学的,这种因果关系关系也是固定不变的。信道和动力学都可以用转移概率矩阵所描述。因此,一个动力学也可以被看作是一个通信信道。
而以上提到的因果涌现都建立在将初始分布do干预成均匀分布的情况下,即干预分布的熵最大。回顾有效信息的计算公式:
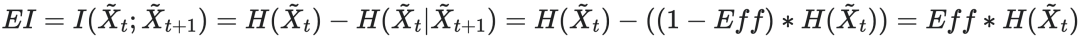
其中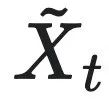 和
和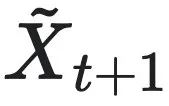 是干预后的因果变量,Eff为动力学的有效性。由公式可以看出EI的大小与干预的概率分布的熵有关。
是干预后的因果变量,Eff为动力学的有效性。由公式可以看出EI的大小与干预的概率分布的熵有关。
Claude Shannon在信息论中提出信道具有一定的容量。信道容量是指信道以最具信息性和可靠性的方式将输入转化为输出的能力,信道中信息传输的速率对输入概率分布 p(X) 的变化非常敏感。信道容量 (C) 定义为使互信息达到最大值的输入变量分布,这也是信道能够可靠传输信息的最大速率:
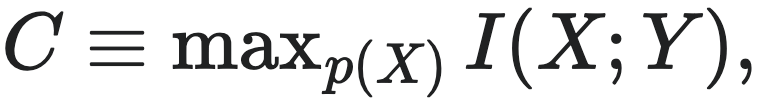
其中I(X;Y)是输入和输出之间的互信息。
相应的,因果涌现理论揭示了系统存在一种类似的因果容量(Causal Capacity, CC),因为粗粒化操作本质上可以看作是对输入干预分布的改变,因果容量就是指系统以最具信息性和最有效的方式将干预转化为效果的能力,定义为:
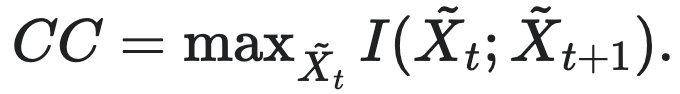
同上有效信息计算中,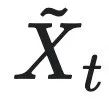 和
和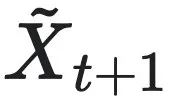 是经过粗粒化干预后的因果变量,CC对应的是最有效的干预下,因果变量之间互信息的最大值。
是经过粗粒化干预后的因果变量,CC对应的是最有效的干预下,因果变量之间互信息的最大值。
3. 因果涌现实例
3. 因果涌现实例
3.1 基于状态空间的粗粒化计算因果涌现实例
一个简单的基于系统状态空间计算因果涌现的实例如下:一条离散的马尔科夫链χ,共有4个可能的状态Sm={0,1,2,3},状态转移概率矩阵Pm如下所示:
马尔科夫链示例

在这个例子中,微观态的转移概率矩阵Pm是一个4*4的矩阵,其中前三个状态彼此以1/3的概率相互转移,这导致该转移矩阵具有较小的确定性,因此EI也较小,为0.81。
然而,当我们进行如下粗粒化:也就是把前三个状态合并为一个状态a,而最后一个状态转变为一个宏观态b。这样所有的原本三个微观态彼此之间的转移就变成了宏观态a到a内部的转移了。然后,相应再计算得到转移概率矩阵PM,它的EI为1。可以证明,这一粗粒化方案就是最优的粗粒化方案。
在这个例子中,我们可以计算它的因果涌现度量为:
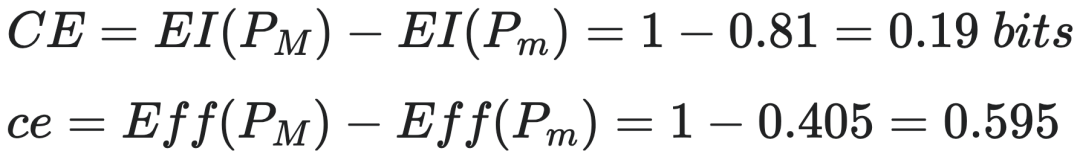
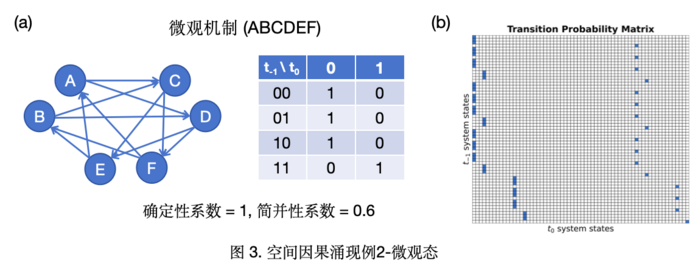
即存在着0.19比特的因果涌现,或用有效性度量得到因果涌现的大小为0.595。
3.2 基于变量空间的粗粒化计算因果涌现实例
下面,我们从变量的角度,分别给出了空间、时间和时空角度的布尔网络马尔科夫链系统因果涌现的实例。我们将从微观动力学、粗粒化映射和宏观动力学三个方面进行描述和分析。
在下面的讨论中,Xm表示微观变量的集合;XM表示宏观变量的集合。微观变量的取值集合为{0,1},即都是布尔值变量,我们用拉丁字母{A,B,C…}来表示,宏观变量则用希腊字母,,{α,β,γ..}表示。每个微观变量的状态标记为{0,1},宏观变量的状态标记为,{“on”,“off”}或,{“bursting”,“quiet”}。微观态对应的转移概率矩阵(TPM)为Pm,宏观态对应的转移概率矩阵(TPM)为PM。
注:下面涉及到的TPM行列对应的系统状态排列,均按照以下python代码生成,其中num_nodes是网络中布尔变量的个数。

3.2.1 空间因果涌现
所谓的空间因果涌现,是指对系统的粗粒化方案是基于对同一时刻的状态空间进行划分作为基础的粗粒化方案,并且该粗粒化最终导致了因果涌现的发生。
根据前文,因果涌现量化指标可以拆分为确定性和简并性两项。接下来,我们对由确定性和由简并性主导的因果涌现分别给出一个实例,介绍空间因果涌现。
3.2.1.1 提高确定性实例分析
由于有效信息包括了确定性和简并性,因此二者任意一个的提高都可能导致因果涌现发生。首先,我们考虑确定性的提升导致的因果涌现现象。
微观态与微观动力学:系统由四个布尔变量组成Xm={A,B,C,D} 组成(如图1)。其中,变量A和B一组,变量C和D一组,其中一个组中的每个变量t+1时刻的状态由另一组两个变量t时刻的状态决定。
在这个例子中,系统的动力学最原始的表达为一种微观变量的因果机制(如图1中的中间的表格),由每个单独变量的因果机制,我们便可以展开得到整个系统的动力学,即因果机制。
-
首先,对于单独任意一个变量(图1(a)中的节点),它的微观机制可以被看做一个带噪声的AND门操作。图1(a)中的表格可以被解读为:假设t时刻CD = {00}的条件下,则t+1时刻,A和B每个变量有0.7的条件概率为0,0.3的条件概率为1。 -
其次,由单个变量的微观机制,我们可以进一步得到AB联合变量的动力学机制,即在给定C、D变量的取值条件下,A,B变量的联合状态总共可能有以下四种:{00},{01},{10},{11},每种联合状态的条件概率由A和B单独状态所对应的条件概率的乘积得到。所以这四种联合状态的条件概率分别对应为0.49(0.7×0.7),0.21(0.7×0.3),0.21(0.3×0.7),0.09(0.3×0.3),且满足概率之和为1的归一化条件。类似地,我们可以考虑在CD={01,10,11}条件下,AB联合变量的条件概率。 -
进一步,我们也可以对称地得到在A和B在t时刻的取值为AB={00,01,10,11}的条件下,CD联合变量分别取00,01,10,11的条件概率。 -
然后,将所有这些t时刻的状态综合在一起,我们便可以得到在ABCD四变量形成的联合状态下(总共有24=16种可能性,即16个微观态),ABCD在t+1取16种可能状态值的条件概率(因为在给定t时刻状态的条件下,ABCD的取值彼此独立,因此联合变量ABCD的条件概率取值可以将上述每一个条件概率乘到一起得到),从而得到微观态的16 × 16的概率转移矩阵 Pm——即微观动力学(如图1(b)所示)。 -
最后,根据EI的公式可以计算得到有效信息EI(Pm)=Det(Pm)−Deg(Pm)=1.35−0.20=1.15 bits,Eff(Pm)=EI(Pm)/logN=1.15/4=0.29,其中Det表示确定度,Deg表示简并度。
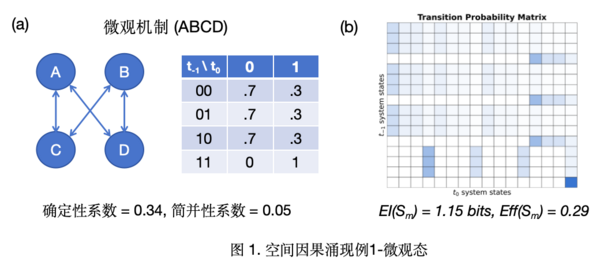
粗粒化映射:Hoel等人给出的具体的粗粒化方案为:将微观变量集合Xm={ABCD}归并为两个宏观变量,即XM=α,β,其中α=AB,β=CD。并且,α,β的取值集合为:{“off” ,”on”}。同时,我们可以定义微观变量取值到宏观变量取值的对应规则,如图2(a)中的映射所示。
宏观动力学:粗粒化后,系统现在由2个宏观变量组成,每个宏观变量有2个态,所以共有22=4个宏观态。根据系统微观态的TPM和粗粒化映射规则,我们可以得到一个衍生的宏观态的机制(如图2(a)中表格所示),或等价的一个 4 × 4 的概率转移矩阵(TPM,如图2(b)所示):PM。粗粒化后,宏观态的概率转移矩阵规模减小,但是状态间的转移规律更明确。宏观动力学EI(PM)=Det(PM)−Deg(PM)=1.56−0.01=1.55 bits,Eff(PM)=0.78,高于微观动力学的EI(Pm)=1.15 bits。因此,因果涌现度量CE=EI(PM)−EI(Pm)=0.40 bits,宏观动力学的因果性优于微观动力学,因果涌现发生。
本例中,在宏观动力学的有效性ΔIEff的增益主要来自于减少噪声干扰,即确定性提高(归一化后:Det(Pm)=0.34; Det(PM)=0.78),少部分来源于简并性减少(归一化后:Deg(Pm)=0.05; Deg(PM)=0.006)。
3.2.1.2 抵消简并性实例分析
让EI提高的第二种方式就是减小简并性,因此第二个例子即来自简并性的减小导致的因果涌现。
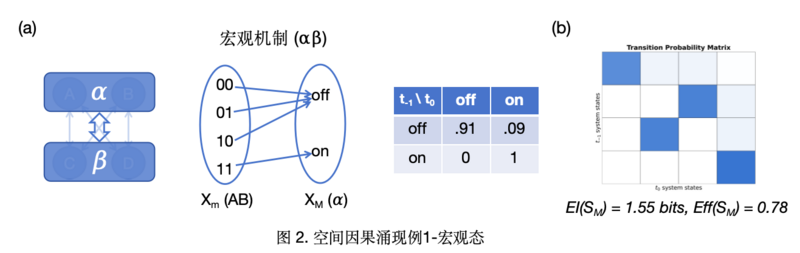
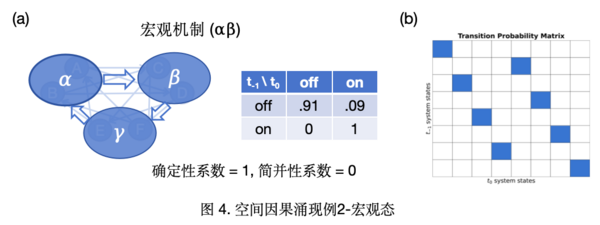
微观动力学:在这个例子中,原始的系统(微观态)中有6个布尔变量Xm={ABCDEF}(如图3(a)所示),其中A、B接受E和F的输入,C、D接受A和B的输入,E、F接受C和D输入。响应机制为确定性AND门,对应完全确定性(变量根据输入转移至完全确定的状态)和高简并度(输入00,01,10转移至相同状态)。微观态的概率转移矩阵可以按照上述例子的方法计算,如下图所示。由于前一时刻的很多状态会转移至下一时刻的相同状态,因此系统的简并性较高。根据有效信息计算,可以得到EI(Pm)=2.43 bits,Eff(Pm)=0.4。
粗粒化映射:同上例,根据微观机制的分组,接受相同输入的变量可以被分为同一组,因此可以分为3个宏观变量。根据机制的同类性,{[00,01,10], [11]}可归并为宏观变量状态{“off” ,”on”},输入宏观变量状态为”off“时,宏观变量响应也为”off“,反之亦然。确定性AND门映射为宏观COPY操作,即粗粒化后的宏观变量完全复制输入变量的状态。
宏观动力学:宏观态的概率转移矩阵如图4(b)所示,可得到宏观动力学EI(PM)=3 bits,Eff(PM)=1,CE=EI(PM)−EI(Pm)=0.57 bits,因果涌现发生。进一步拆解分析可知,微观和宏观机制都是完全确定性的,但粗粒化后宏观简并性明显减小 ΔDeg=−0.6,对应图中不同行的状态下一时刻转移至不同宏观态。在本实例中,粗粒化映射消除了系统的简并性,因此这是一种简并性主导的因果涌现。
3.2.2 时间因果涌现
如果我们将接续多个时刻的状态合并到一起形成一个联合状态,将(tx) 个微观时间步粗粒化为(Tx)个宏观时间步,从而得到衍生的多个时间步合并的新的高阶马尔科夫动力学,则我们可以定义对时间进行粗粒化映射而导致的涌现现象。
下面对一个时间因果涌现实例进行分析:
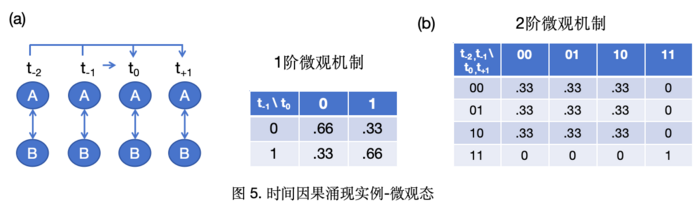
微观动力学:系统有A和B两个变量,每个变量t和t+1的状态由另一变量t−2和t−1时刻的状态决定,即遵循二阶马尔可夫机制(图5(a))。具体的状态决定机制如图5中间的表格所示,当B前两时刻(t−2,t−1)状态为{11}时,A当前和后一时刻(t,t+1)状态可确定为{11};当B前两时刻状态为其余三种情况{00,01,10},A当前和后一时刻状态会以等概率出现这三种情况中的一种。基于一个微观时间步分析,得到 [EI(Sm)=0.16 bits;Eff(Sm)=0.03],因果相互作用较弱,因为忽略了系统二阶性质。计算这个二阶马尔科夫链的 EI(Sm)=1.38 bits,Eff(Sm)=0.34。
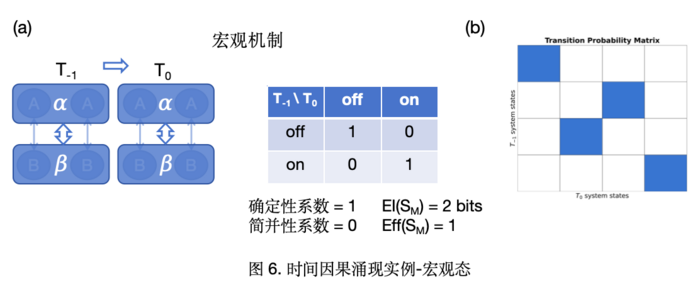
粗粒化映射:根据二阶马尔科夫性质,将微观态的时间步分组为宏观状态α=At,At+1和β=Bt,Bt+111t+1(图6(a));同空间因果涌现实例,图5(b)概率转移矩阵中状态间明显的界限,可以将{[00,01,10],[11]}分别映射为{“off”,”on”}两个宏观状态。
宏观动力学:对二阶马尔科夫过程进行粗粒化后得到的宏观机制如图6(b)所示,此时机制为完全确定和非简并的,即宏观时间尺度下 EI(PM)=2 bits,Eff(PM)=1, CE=EI(PM)−EI(Pm)=0.62 bits,因而因果涌现发生。
3.2.3 时空因果涌现
因果涌现现象还可以基于对空间、时间同时进行粗粒化而产生,下面给出一个时空同时粗粒化得到因果涌现的例子。
如图7所示(描述神经元的发放状态如何由其它神经元决定[5]),系统中一共有9个微观态变量,分别记为A~I,它们都是布尔型变量,并彼此之间都相互影响,具体的影响机制描述为:
微观动力学:
-
动力学机制:所有微观变量也遵循二阶马尔可夫机制,整合前两个时间步(t-2和t-1)的变量状态,得到后两个时间步(t0, t+1)的变量状态。所有微观变量自发活动(0/1),1为发放状态,每个变量具有非均匀的自发放概率:p(A/D/G)=0.45;p(B/E/H)=0.5;p(C/F/I)=0.55。 -
变量分组:所有变量被划分为三组:ABC,DEF,GHI,每个变量都接收组内(也包含该变量自身)和组间变量的输入。在每组内,如果两个时间步内组内输入之和为0,则接下来的两个时间步所有变量保持为0。然而,如果在两个时间步中,另外有一组(或者两组)变量提供的组间输入之和为6,且该组内输入之和不为0时,则在接下来的两个时间步中,自发放概率提高为0.5;否则,还是遵循自发活动的发放概率。
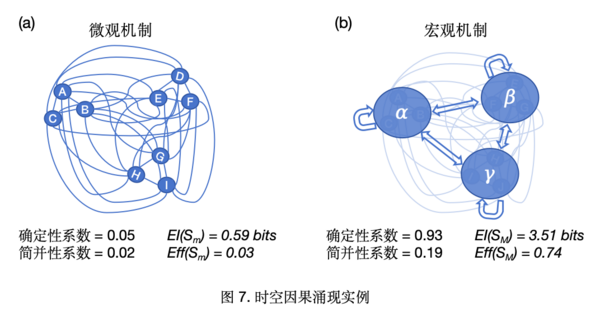
可以计算得到:微观动力学对应的 EI(Pm)=0.59 bits;Eff(Pm)=0.033。
粗粒化映射:根据二阶马尔科夫性质,将两个微观时间步长整合为一个宏观时间步长,这便对应为时间粗粒化映射;进一步,根据动力学中的分组机制,三组变量在空间上映射可以被划分为三个宏观变量(如图6(b)所示),这便对应为空间粗粒化映射。从上述组机制中可以看出,一组变量的状态全为0和全为1会影响发放概率,这两种情况之外,每个微观变量都遵循自发活动;因此,每个宏观变量所对应的微观变量可以归并出三种状态:全为0的状态(这对应的宏观态为抑制态)、全为1的状态(这对应为宏观的爆发态),以及介于二者之间的所有状态(这对应为宏观的感受态)。
宏观动力学:时空粗粒化后的宏观动力学具有比微观动力学更高的EI(PM)=3.51 bits,和Eff(PM)=0.74,CE=2.92 bits,因果涌现发生。粗粒化过后系统确定性的增加,增加程度远超过简并性的增加。
注:本实例可对应真实神经元活动上的解释。神经元可以理解为图中的微观变量,而粗粒化后的宏观变量可理解为神经元组成的“微柱”(minicolumn),对应有三种状态:“抑制态”,微柱中神经元均在t时刻静默,对应组内神经元状态全为0;“感受态”,部分神经元在t时刻放电,对应部分为1;“爆发态”:所有神经元均在t时刻放电,对应全为1。宏观的因果相互作用可以解释为,如果一个宏观“微柱”处于“抑制态”,那么只有接收到一次其他微柱的”爆发“式发放才能转换到“感受态”,极小可能转换为“爆发态”;否则,它将一直保持“抑制态”。
3.2.4 变量外部化导致的因果涌现
在Hoel的2017年的文章[3]中,他定义了另外一种变量粗粒化的方式,这就是将系统中的某些变量外部化(Marginalization),即将其视为系统的外部变量。这样,当计算EI的时候,do干预操作便不会影响这些外部变量,从而也可能导致EI增加的可能性,即外部化导致的因果涌现现象。
3.2.4.1 冻结外部化变量
外部化变量通常包括两种方式,即“冻结”外部化变量方式,如下图:
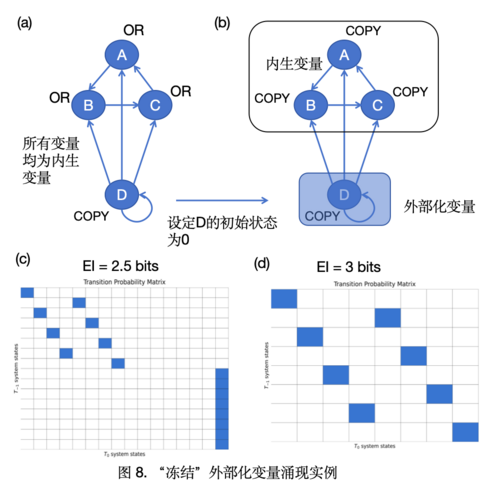
图中的每个变量仍然都是布尔型的变量,且我们将图中的变量D视为一个外部变量,即我们考察的系统为A、B、C三个变量。假设在粗粒化之前,系统的微观动力学机制为:被“冻结”的变量D的输入仅来自于自身,且为COPY机制,故系统变化过程中变量D将一直保持初始的状态不变。另外,A接受D和C的输入,响应方式为OR门,变量B,C的状态变化方式与A同理。由此,不难看出D的动力学变化模式独立于另外三个变量。
接下来,粗粒化方案则体现为将D变量“冻结”,而将A,B,C视作我们考察的系统(即重新定义系统边界)。而在动力学的粗粒化上,所谓的“冻结”操作可以被看作是改变这些变量分布的一种干预操作,即将D的初始状态干预为0,其它三个变量干预为均匀分布。而由于A、B、C三个变量在微观动力学中都是接受两个变量输入的,其中一个输入D被固定为了0,所以,A,B,C三个变量的状态更新就完全取决于另一个输入变量,而与D无关了。因此,粗粒化后,这三个变量的OR机制变为了COPY机制。
3.2.4.2 黑盒化外部变量
另一种方式则是“黑盒化”外部变量,如下图:
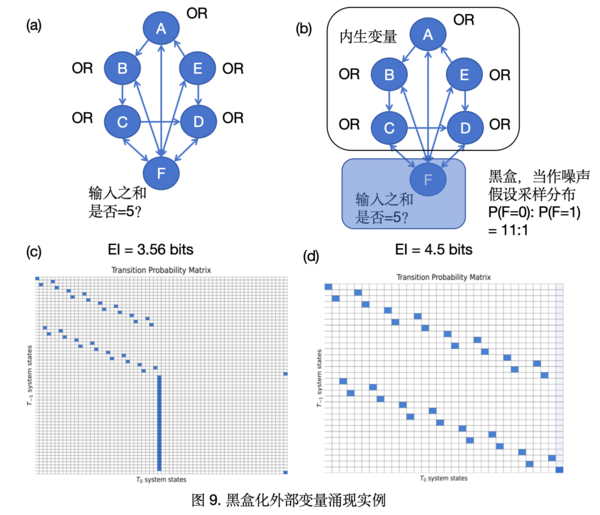
其中,A,B,C,D,E五个变量的微观动力学与上例相同,而“黑盒”外部化变量F则与前面例子不同,不同之处在于,变量F接受来自另外五个变量的输入,并且它的响应方式为逻辑判断“五个输入加和是否等于5”,也就是只有A,B,C,D,E同时为1的时候,F才转移至1。
在所有变量都是内生变量时,所有状态都发生的是确定性转移,因为机制是完全确定的。在将变量D做黑盒化处理后,相当于我们不再关注它的变化了。举例来说,假设采样发现F取0和1的概率为是11:1(可人为设定,但要注意取0的概率远大于1),当{ABCDE}的状态为{01011}时,那么下一时刻,有11/12的概率继续保持{01011}(对应当前黑盒D的状态为0),而有1/12的概率转移至{11111}(对应当前黑盒的D状态为1)。相比于原系统,黑盒化F后的五变量系统的转移不再是确定性的,F的变化仅视作系统的噪声。从原TPM得到黑盒化后的TPM,需要将转移概率对黑盒变量的概率做边际化(marginalize),在新的TPM中不再出现F的状态,可参考如下三步操作:
(1)行向量处理:a. 将F=0和1的行向量乘以对应概率,即11/12和1/12;b. 对应ABCDE状态相同的行向量两两相加,例如{ABCDEF} = {110001} 和 {ABCDEF} = {110000}相加合并,得到的即为{ABCDE} = {11000}下一时刻向各状态转移的概率情况,操作后的TPM行数量减半;
(2)列向量处理:同上步骤b,对应ABCDE状态相同的列向量两两相加,完成后列数量也减半;
(3)归一化:行归一化新TPM,得到{ABCDE}各状态之间的转移概率矩阵。
4. 缺陷与争议
4. 缺陷与争议
根据前面的讨论我们不难发现,不同的粗粒化方案会导致不同的宏观动力学,从而导致它的有效信息不同,因此,最终的因果涌现量化结果会依赖于给定的粗粒化策略。Hoel等人虽然试图通过最优粗粒化(即让宏观动力学的有效信息最大)以消除这种粗粒化对因果涌现最终结果的影响,并针对每个具体的情景,给出了具体的最优粗粒化的方案,但是他们并没有深入探讨马尔科夫链的粗粒化;特别是针对于基于状态的因果涌现讨论中,给出的粗粒化只是针对状态空间进行归并,归并后具体应该如何对概率转移矩阵进行操作则并未提及。状态归并本身也有一定的前提条件需要满足,比如状态分类是否满足马尔科夫链的成块性?粗粒化操作和动力学演化操作是否满足可交换性?文章都没有涉及这些问题的探讨,只停留用比较直觉方法进行概率归并,因此该理论难以指导人们在其他系统中的使用。详细严谨的粗粒化介绍详见马尔科夫链的粗粒化。
此外,在状态、变量较少,且转移概率矩阵有明显的规律可循时,我们可以相对容易地定义粗粒化策略并识别因果涌现。但面对情况复杂的实际系统时,例如生物系统,从可观测数据中辨别系统是否发生因果涌现是一个更为重要的问题。为此,Rosas等人提出基于信息分解的因果涌现理论,张江等人提出的基于奇异值分解的因果涌现理论以及张江等人还提出了一些自动识别涌现的神经网络计算方法,例如神经信息压缩方法NIS和基于此的改进方法NIS+,有兴趣的读者可以进一步查阅相关词条。
由布尔网络动力学转换为马尔科夫链的TPM的代码
在Hoel的原始论文[1]中,所有的微观动力学都是针对布尔网络中的每个变量(即节点)定义其微观动力学机制完成的。而为了计算布尔网络的有效信息和因果涌现度量,我们必须要将这种微观动力学机制转变为系统整体的概率转移矩阵(即TPM)。因此,这里的一个关键问题是,如何将一个定义在局部变量上的动力学机制,转变为一个全局的TPM。这里给出一种一般性的算法:
输入:有向图形式的布尔网络G(包括N个节点、连边),节点动力学机制(即,单个节点对父节点输入的响应机制);输出:布尔网络G全局概率转移矩阵P
1. 生成布尔网络的状态空间,共有状态数2N个,N为网络中的节点数
2. 初始化全局概率转移矩阵P,大小为2N∗2N,Pij为第i个全局状态转移到第j个全局状态的转移概率
3. 遍历当前时刻每个全局状态i,遍历下一时刻每个全局状态j,计算i->j的转移概率Pij
1)遍历每个节点n,获取它的父节点及其状态
2)获取j中节点n下一时刻状态next_state,根据上一步获取的父节点状态,应用该节点的动力学机制,计算n转移至next_state的概率p(n)
3)各节点到下一时刻状态转移概率是相互独立的,因此全局状态i转移至j的概率是所有节点p(n)的乘积,即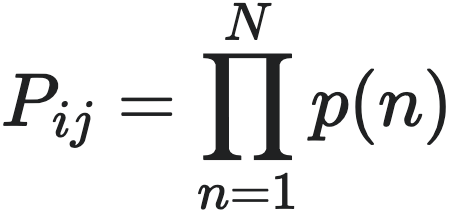
4)重复上述过程,计算所有Pij,i,j∈{1,2,3,…,2N}。
4. 行归一化P,完成由局部节点机制到全局概率转移矩阵的转换
以下给出空间因果涌现中带噪声的AND门实例的python实现代码:



本词条由集智俱乐部众包生产,难免存在纰漏和问题,欢迎大家留言反馈或者前往对应的百科词条页面进行修改,一经修改,可以获得对应的积分奖励噢!
加入我们
我们需要的帮助
编写新的集智百科词条,涵盖复杂系统、人工智能等多个领域
更新和完善现有词条,确保信息的准确性和时效性
我们希望你具备
良好的写作能力,能够清晰、简洁地表达复杂的概念
对某一领域有深入了解或浓厚兴趣
具备基本的网络搜索和信息整理能力
有责任心和团队合作精神,愿意为知识共享贡献力量

参考文献
[1]Hoel, E.P., Albantakis, L. and Tononi, G. Quantifying causal emergence shows that macro can beat micro[J]. Proceedings of the National Academy of Sciences, 2013, 110(49), 19790-19795.
[2]Tononi, G.; Sporns, O. (2003). “Measuring information integration”. BMC Neuroscience. 4 (31).
[3]Hoel, E.P. When the map is better than the territory[J]. Entropy, 2017, 19(5), p.188.
[4]Eberhardt, F., & Lee, L. L. (2022). Causal emergence: When distortions in a map obscure the territory. Philosophies, 7(2), 30.
[5]Buxhoeveden, D. P., & Casanova, M. F. (2002). The minicolumn hypothesis in neuroscience. Brain, 125(5), 935-951.

因果涌现读书会第六季
在霓虹灯的闪烁、蚁群的精密协作、人类意识的诞生中,隐藏着微观与宏观之间深刻的因果关联——这些看似简单的个体行为,如何跨越尺度,涌现出令人惊叹的复杂现象?因果涌现理论为我们揭示了答案:复杂系统的宏观特征无法通过微观元素的简单叠加解释,而是源于多尺度动态交互中涌现的因果结构。从奇异值分解(SVD)驱动的动态可逆性分析,到因果抽象与信息分解的量化工具,研究者们正逐步构建起一套跨越数学、物理与信息科学的理论框架,试图解码复杂系统的“涌现密码”。
为了系统梳理因果涌现最新进展,北京师范大学系统科学学院教授、集智俱乐部创始人张江老师领衔发起「因果涌现第六季」读书会,组织对本话题感兴趣的朋友,深入研读相关文献,激发科研灵感。
读书会将从2025年3月16日开始,每周日早9:00-11:00,持续时间预计10周左右。每周进行线上会议,与主讲人等社区成员当面交流,之后可以获得视频回放持续学习。诚挚邀请领域内研究者、寻求跨领域融合的研究者加入,共同探讨。
推荐阅读
6. 加入集智,玩转复杂,共创斑图!集智俱乐部线下志愿者招募
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











