破解AI黑箱的四重视角:大模型可解释性读书会启动

导语
集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起「大模型可解释性」读书会。本读书会旨在突破大模型“黑箱”困境,尝试从以下四个视角梳理大语言模型可解释性的科学方法论:
自下而上:Transformer circuit 为什么有效?
自上而下:神经网络的精细决策逻辑和性能根因是否可以被严谨、清晰地解释清楚?
背景简介
背景简介
人工神经网络自2012年以来取得了巨大突破,特别是以大模型为代表的新一代人工智能技术。但是,随着深度学习模式的兴起,“端到端”的学习模式逐渐占据主导地位。然而,人们不了解它是如何做到的,只能视之为“黑箱”。因此,人们对AI的改进被限制在堆算力与数据上,也无法完全信任AI。

长远来看,基于数据和算力资源Scaling law的大模型能力的提升会走到尽头。因此,深度学习的研究范式需要从「经验性技术」转换到「科学方法论」。理想情况下,最好我们能从理论上证明“神经网络的精细决策逻辑”可以在数学上被推导和建模。当然,不少学者也从统计物理、复杂科学等视角尝试理解大模型的涌现机制、上下文学习能力及结构与功能的对应关系等。最近,Anthropic公司也尝试拿起「手术刀」,拆解大模型的工作回路,希望能够理解大模型在推理、创作、理解语言等各种能力上的工作回路是什么样的,也引起大家的广泛关注。
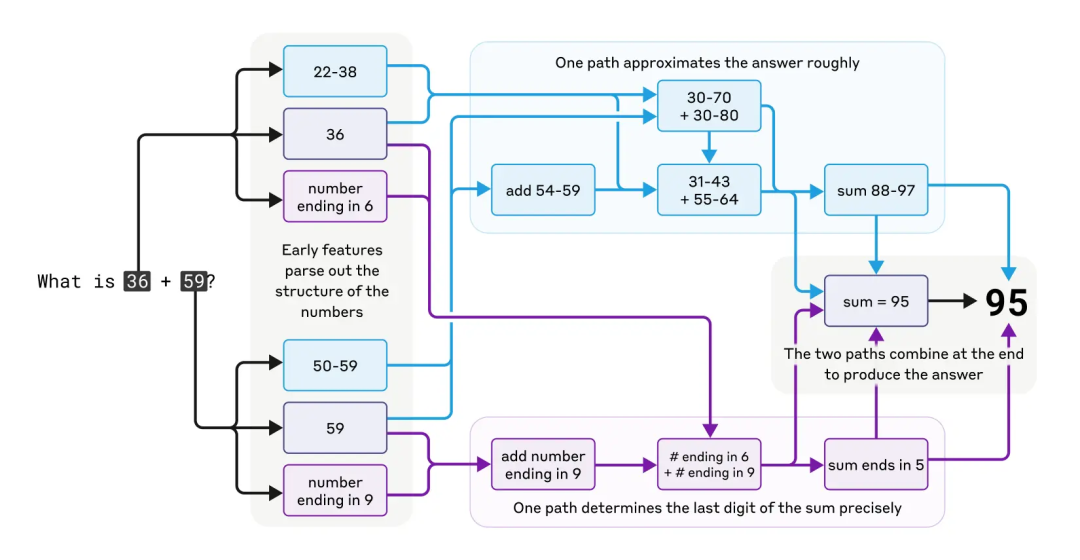
图片来源:https://www.anthropic.com/research/tracing-thoughts-language-model
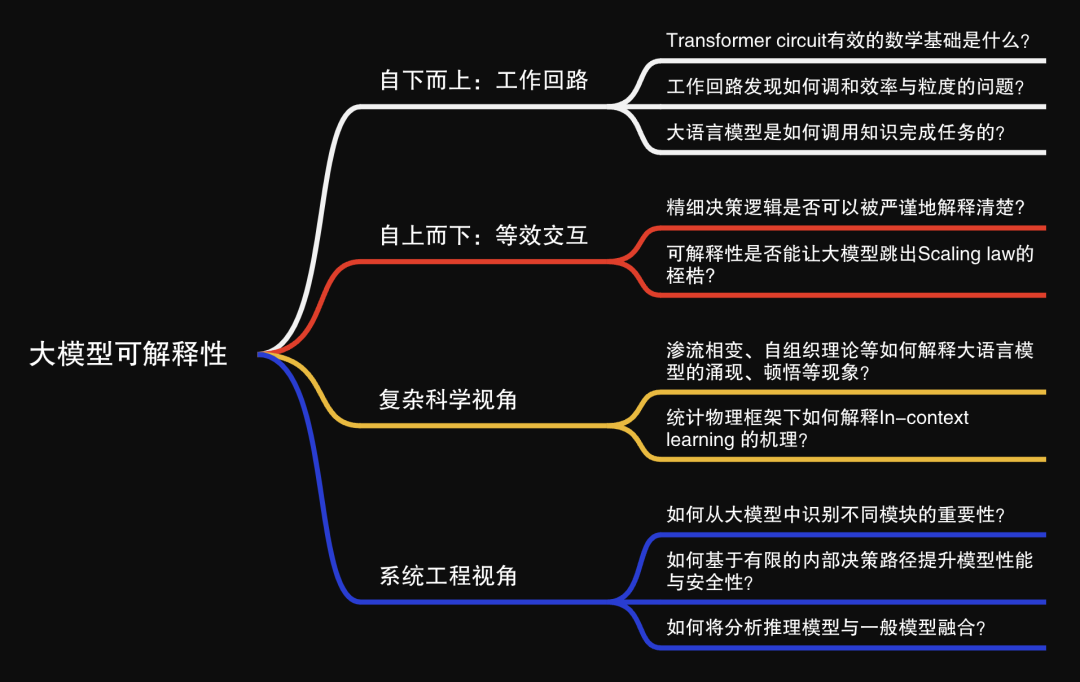
为了更深入的理解大语言模型的可解释性,集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起「大模型可解释性」读书会。读书会尝试回答以下问题:
-
Transformer circuit有效的数学基础是什么?
-
工作回路发现如何调和效率与粒度的问题?
-
大语言模型是如何调用知识完成任务的?
-
神经网络的精细决策逻辑是否可以被严谨地解释清楚?
-
决定神经网络的性能的根因是否可以被清晰的数学建模?
-
渗流相变、自组织理论等如何解释大语言模型的涌现、顿悟等现象?
-
统计物理框架下如何解释In-context learning 的机理?
-
如何从大模型中识别不同模块的重要性?
-
如何基于有限的内部决策路径提升模型性能与安全性?
-
如何将分析推理模型与一般模型融合?
读书会框架
读书会框架
读书会将围绕以下模块展开:
-
自下而上的工作回路视角:从还原论的视角理解大模型的可解释性机制,绘制大模型的工作回路,并反过来理解大模型是怎么工作的。我们将系统梳理包括大语言模型架构中工作回路相关的研究工作,重点关注:1) Transformer circuits 数学基础;2)回路识别与稀疏化方法;
-
自上而下的等效交互视角:从理论层面推导神经网络的精细决策逻辑,解释清楚决定神经网络的性能的根因,将经验性调优转化为可证明的理论体系,突破Scaling law的桎梏;
-
复杂科学视角:从复杂科学、统计物理中的涌现、自组织、分形、渗流相变等理论视角,将大模型看作一个复杂系统,试图理解其在执行任务的过程中表现出的Scaling law,Groking和In context learning等能力;
-
系统工程视角:聚焦模型的基础算法模块、内部决策路径及端到端处理逻辑。通过解析大模型的原子算法(如任务定位、模型解释、调优策略),还原其从输入到输出的每一步 “思考” 过程,实现从算法层面的透明化,从而实现对大模型性能与安全性的有效提升。
发起人团队
发起人团队

张拳石,上海交通大学副教授,博士生导师,入选国家级海外高层次人才引进计划,获ACM China新星奖。2014年获得日本东京大学博士学位,2014—2018年在加州大学洛杉矶分校(UCLA)从事博士后研究,合作导师为朱松纯教授。在神经网络可解释性方向取得了多项具有国际影响力的成果,其研究成果发表在IEEE T-PAMI、ICML、ICLR、CVPR等顶级期刊和会议上,并担任IJCAI可解释性方向Tutorial主讲人及AAAI、CVPR、ICML等会议的分论坛主席。
研究方向:可解释性机器学习,提出等效交互可解释性理论体系。

沈旭,阿里云-飞天实验室高级算法专家,大模型可解释性负责人。博士毕业于中国科学技术大学。曾获浙江省科技进步一等奖,在ICLR/ICML/NeurIPS/ACL/CVPR/ECCV/ICCV等国际顶会上发表论文40余篇,google scholar引用1900余次。
研究方向:聚焦大模型的内在机理和运行机制,重点探索模型可解释性等核心问题,并致力于将大语言模型技术应用在国际大型赛事、主权大模型等关键场景。

肖达,人工智能公司彩云科技联合创始人、首席科学家、北京邮电大学网络空间安全学院讲师。
研究方向:主要负责深度神经网络模型和算法的研发用于彩云天气、彩云小译、彩云小梦等产品。

杨明哲,北京师范大学系统科学学院硕士生,张江老师因果涌现研究小组成员。
研究方向:因果涌现、复杂系统自动建模。

姚云志,浙江大学计算机科学与技术学院在读博士生,导师为陈华钧教授与张宁豫教授。现在是加州大学洛杉矶分校的访问研究学者,与Nanyun Peng教授一起工作。
研究方向:自然语言处理的机器学习,特别关注支撑大型语言模型 (LLM) 的知识机制。研究 LLM 如何获取、存储和利用知识进行推理,以及不同架构和模式的模型之间的交互方式。目标是开发简洁而精确的模型编辑方法。
报名参与读书会
报名参与读书会
运行模式
从2025年6月19日开始,每周四晚 19:30-21:30,持续时间预计10周左右,按读书会框架设计,每周进行线上会议,与主讲人等社区成员当面交流,会后可以获得视频回放持续学习。
报名方式
第一步:微信扫码填写报名信息。

扫码报名(可开发票)
第二步:填写信息后,付费报名。如需用支付宝支付,请在PC端进入读书会页面报名支付:
https://pattern.swarma.org/study_group/63
第三步:添加运营负责人微信,拉入对应主题的读书会社区(微信群)。
PS:为确保专业性和讨论的聚焦,本读书会谢绝脱离读书会主题和复杂科学问题本身的空泛的哲学和思辨式讨论;如果出现讨论内容不符合要求、经提醒无效者,会被移除群聊并对未参与部分退费。
加入社区后可以获得的资源:
完整权限,包括线上问答、录播回看、资料共享、社群交流、信息同步、共创任务获取积分等。
参与共创任务获取积分,共建学术社区:
读书会采用共学共研机制,成员通过内容共创获积分(字幕修改、读书会笔记、论文速递、公众号文章、集智百科、论文解读等共创任务),积分符合条件即可退费。发起人和主讲人同样遵循此机制,无额外金钱激励。

PS:具体参与方式可以加入读书会后查看对应的共创任务列表,领取任务,与运营负责人沟通详情,上述规则的最终解释权归集智俱乐部所有。
读书会阅读材料
读书会阅读材料
阅读材料较长,为了更好的阅读体验,建议您前往集智斑图沉浸式阅读,并可收藏感兴趣的论文。

https://pattern.swarma.org/article/348?from=wechat
读书会阅读清单
自下而上:工作回路视角
图片来源:https://www.anthropic.com/news(Tracing the thoughts of a large language model)
数学基础
1.提出一种数学框架,将Transformer模型(如Claude)的计算过程分解为可解释的电路元件(如注意力头、前馈网络层),通过线性代数工具量化各元件对输出的贡献。
Elhage, Nelson, et al. “A mathematical framework for transformer circuits.” Transformer Circuits Thread 1.1 (2021): 12.
回路发现
1.类比生物系统的进化与适应性,分析大语言模型(LLM)中神经结构的“功能分化”现象。
Lindsey, Jack, et al. “On the biology of a large language model.” Transformer Circuits Thread (2025).
2.开发自动化电路追踪技术,通过干预实验和梯度分析,绘制LLM内部特定任务(如问答、逻辑推理)的动态计算子图。
Ameisen, Emmanuel, et al. “Circuit tracing: Revealing computational graphs in language models.” Transformer Circuits Thread (2025).
3.该论文通过逆向工程方法,在GPT-2 small模型中识别出一个专门负责间接宾语识别的神经回路,揭示了语言模型处理语法关系的模块化机制,但效率较低。
Wang, Kevin, et al. “Interpretability in the wild: a circuit for indirect object identification in gpt-2 small.” arXiv preprint arXiv:2211.00593 (2022).
4.效率更高的回路发现方法,把transformer看作图,通过计算梯度评估图中边的重要性转化为稀疏图,同样也能做任务
Hanna, Michael, Sandro Pezzelle, and Yonatan Belinkov. “Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms.” arXiv preprint arXiv:2403.17806 (2024).
5.回路发现方法,与Anthropic相关,对于回路的可解释性更高(粒度更细),在原始模型上在训练一个模型解决效率的问题
Dunefsky, Jacob, Philippe Chlenski, and Neel Nanda. “Transcoders find interpretable llm feature circuits.” arXiv preprint arXiv:2406.11944 (2024)
知识调用
1.揭示了Transformer模型通过特定注意力头和前馈网络的动态协作机制实现事实知识检索,提出知识以键值对形式存储于FFN中并通过注意力匹配激活的核心观点。
Lv, Ang, et al. “Interpreting key mechanisms of factual recall in transformer-based language models.” arXiv preprint arXiv:2403.19521 (2024).
2.定义了预训练Transformer中稀疏且模块化的”知识回路”结构,证明不同事实依赖特定子网络路径,并可通过编辑电路参数实现知识的定向修改。
Yao, Yunzhi, et al. “Knowledge circuits in pretrained transformers.” arXiv preprint arXiv:2405.17969 (2024).
自上而下:等效交互视角
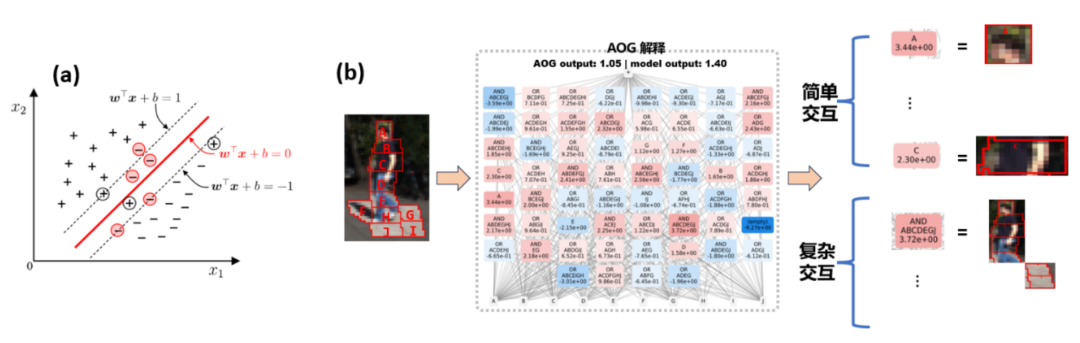
什么才是解释性领域的第一性原理?张拳石团队认为需要在一个新的理论体系中,提出大量公理性要求,得出一个可以精确、严谨解释神经网络内在机理的理论才叫第一性原理。他们从0到1搭建了「等效交互可解释性理论体系」,从三个角度来解释神经网络的内在机理。
首先是语义解释的理论基础。张拳石团队找到了在大部分应用中神经网络都可以满足的面向遮挡鲁棒性的三个常见条件,并且数学证明了满足这三个条件的神经网络决策逻辑可以被写成符号化的交互概念。
1.证明神经网络精细决策逻辑可以严格解释为符号化等效交互概念
Qihan Ren, Jiayang Gao, Wen Shen, and Quanshi Zhang. Where We Have Arrived in Proving the Emergence of Sparse Interaction Primitives in DNNs. In ICLR, 2024.
https://zhuanlan.zhihu.com/p/693747946
其次是寻找性能背后可证明、可验证的根因。将神经网络泛化性和鲁棒性等终极性能性能指标拆分成具体少数细节逻辑。他们证明:等效交互的复杂度可以直接决定神经网络的鲁棒性/迁移性,决定神经网络的表征能力。
2.从神农尝百草到精炼与萃取:论神经网络对抗迁移性
Xin Wang, Jie Ren, Shuyun Lin, Xiangming Zhu, Yisen Wang, Quanshi Zhang, “A Unified Approach to Interpreting and Boosting Adversarial Transferability” in ICLR 2021
https://zhuanlan.zhihu.com/p/369883667
3.神经网络的博弈交互解释性(六):从博弈交互层面解释对抗鲁棒性
Jie Ren*, Die Zhang*, Yisen Wang*, Lu Chen, Zhanpeng Zhou, Yiting Chen, Xu Cheng, Xin Wang, Meng Zhou, Jie Shi, and Quanshi Zhang (Correspondence), “A Unified Game-Theoretic Interpretation of Adversarial Robustness” in Neurips 2021
https://zhuanlan.zhihu.com/p/361686461
4.可解释性:神经网络对交互概念表达能力的解析分析
Dongrui Liu, Huiqi Deng, Xu Cheng, Qihan Ren, Kangrui Wang, and Quanshi Zhang, “Towards the Difficulty for a Deep Neural Network to Learn Concepts of Different Complexities” in NeurIPS 2023
https://zhuanlan.zhihu.com/p/704760363
5.发现并证明神经网络表征瓶颈
Discovering and Explaining the Representation Bottleneck of DNNs,Huiqi Deng*, Qihan Ren*, Hao Zhang, andQuanshi Zhang (Correspondence), ICLR (Oral), 2022
https://zhuanlan.zhihu.com/p/468569001
最后需要对深度学习算法在工程上统一。他们证明了14种不同的输入重要性归因算法的计算本质在数学上都可以统一写成成对交互作用的再分配形式,还提出了12种提升对抗性迁移的算法,证明了所有提升对抗性迁移算法的一个公共机理是降低对抗扰动之间的交互效用,实现了对神经网络可解释性方向大部分工程性算法的理论凝练。
6.神经网络可解释性:正本清源,论统一14种输入重要性归因算法
Deng et al. “Understanding and Unifying Fourteen Attribution Methods with Taylor Interactions” in arXiv:2303.01506
https://zhuanlan.zhihu.com/p/610774894
7.敢问深度学习路在何方,从统一12种提升对抗迁移性的算法说起
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferabilityhttps://arxiv.org/abs/2207.11694
https://zhuanlan.zhihu.com/p/546433296
沿着上述理论框架,张拳石老师团队希望精确解释神经网络训练过程中泛化性的变化规律。
8.论文发现深度神经网络(DNN)学习交互特征存在两阶段动态过程,即第一阶段抑制中高阶交互、学习低阶交互以提升泛化能力,第二阶段逐步学习高阶交互导致过拟合,该现象与训练 – 测试损失差距的变化时序一致,揭示了 DNN 从欠拟合到过拟合的起始机制。
Two-Phase Dynamics of Interactions Explains the Starting Point of a DNN Learning Over-Fitted Features https://arxiv.org/html/2405.10262v1
9.论文通过数学证明揭示了深度神经网络(DNN)学习交互特征的两阶段动态机制:初始阶段抑制中高阶交互以学习低阶泛化特征,第二阶段逐步引入高阶交互导致过拟合,该理论与训练 – 测试损失差距的变化一致,并通过多任务实验验证了其普适性。
Ren, Qihan, et al. “Towards the dynamics of a DNN learning symbolic interactions.” Advances in Neural Information Processing Systems 37 (2024): 50653-50688.
https://proceedings.neurips.cc/paper_files/paper/2024/file/5aa96d1caa0d0b99d534b67df06be2ff-Paper-Conference.pdf
复杂科学视角

图片来源:https://www.santafe.edu/research/projects/artificial-intelligence-foundations-frontiers(Cyborg (Illustration: Runran/flickr))
相变现象与相关理论
1.用渗流模型解释大语言模型的涌现现象,把大语言模型的涌现和二分图上的渗流相变联系在了一起。(复杂网络的渗流相变)
Lubana, E. S., Kawaguchi, K., Dick, R. P., & Tanaka, H. (2024). A Percolation Model of Emergence: Analyzing Transformers Trained on a Formal Language (arXiv:2408.12578). arXiv. https://doi.org/10.48550/arXiv.2408.12578
2.用一种统一的视角来理解大语言模型的顿悟、双降和涌现现象。它提出这三种现象来自于,记忆和泛化两种路径在大语言模型内部的竞争,使得模型处在不同的相,以及相与相之间的切换。(一套机制解释grok双下降 涌现)
Huang, Y., Hu, S., Han, X., Liu, Z., & Sun, M. (2024). Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition (arXiv:2402.15175). arXiv. https://doi.org/10.48550/arXiv.2402.15175
自组织理论
1.这篇文章通过提出“神经元多重分形分析(NeuroMFA)”,用神经元之间动态互作的多尺度复杂性来解释和度量大语言模型中的涌现现象,从神经元自组织的角度揭示了模型在训练过程中由简单局部互作逐步产生复杂智能行为的内在机制。(自组织)
Xiao, X., Ping, H., Zhou, C., Cao, D., Li, Y., Zhou, Y.-Z., Li, S., Kanakaris, N., & Bogdan, P. (2025). Neuron-based Multifractal Analysis of Neuron Interaction Dynamics in Large Models (arXiv:2402.09099). arXiv.https://doi.org/10.48550/arXiv.2402.09099
2.强调结构和功能的关系,从复杂系统自组织的角度理解大模型的小型综述文章
Teehan, Ryan, et al. “Emergent structures and training dynamics in large language models.” Proceedings of BigScience Episode# 5–Workshop on Challenges & Perspectives in Creating Large Language Models. 2022.
自旋玻璃理论
1.通过自旋玻璃理论框架,对大型语言模型(LLMs)中的上下文学习(ICL)机制提出了新的理论解释。将ICL中语言模型的动态行为映射到自旋玻璃系统的能量景观,其中输入提示(prompt)相当于外部磁场,模型参数对应自旋状态,而上下文信息的作用类似于磁畴间的相互作用。
Li, Y., Bai, R., & Huang, H. (2025). Spin glass model of in-context learning (arXiv:2408.02288). arXiv. https://doi.org/10.48550/arXiv.2408.02288
系统工程视角

图片来源:https://www.anthropic.com/news/core-views-on-ai-safety
模块重要性划分
1.通过因果干预和路径修补技术,在GPT-2 small中识别并验证了26个注意力头组成的稀疏电路,用于间接宾语识别任务。(回路发现中也有这篇文章)
Wang, Kevin, et al. “Interpretability in the wild: a circuit for indirect object identification in gpt-2 small.” arXiv preprint arXiv:2211.00593 (2022).
2.提出基于因果中介分析的方法,揭示性别偏见在Transformer模型中的稀疏性和协同性,定位关键神经元和注意力头。
Vig, Jesse, et al. “Causal mediation analysis for interpreting neural nlp: The case of gender bias.” arXiv preprint arXiv:2004.12265 (2020).
3.提出基于梯度的“归因修补”技术,高效近似激活修补,用于大规模模型中定位关键模块(如注意力头)。
Nanda, Neel. “Attribution patching: Activation patching at industrial scale.” URL: https://www. neelnanda. io/mechanistic-interpretability/attribution-patching (2023).
4.发现ICL中标签词作为信息锚点,浅层语义信息聚合到标签词表征,最终影响预测。
Wang, Lean, et al. “Label words are anchors: An information flow perspective for understanding in-context learning.” arXiv preprint arXiv:2305.14160 (2023).
5.发现LLMs中少量关键注意力头(<5%)和MLP层在算术计算中起核心作用,选择性微调可提升数学能力。
Zhang, Wei, et al. “Interpreting and improving large language models in arithmetic calculation.” arXiv preprint arXiv:2409.01659 (2024).
6.通过规模化方法从Claude 3中提取可解释的稀疏特征,揭示模型内部模块的语义分工。
Templeton, Adly. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Anthropic, 2024.
7.提出SAEBench,一个评估稀疏自编码器(SAEs)在语言模型可解释性中性能的综合基准,涵盖无监督指标和下游任务。
Karvonen, Adam, et al. “SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability.” arXiv preprint arXiv:2503.09532 (2025).
8.通过定位和编辑GPT中与事实关联的中间层MLP模块,实现知识的高效更新。
Meng, Kevin, et al. “Locating and editing factual associations in gpt.” Advances in neural information processing systems 35 (2022): 17359-17372.
9.提出稀疏特征电路方法,通过可解释的因果子网络定位和编辑语言模型行为。
Marks, Samuel, et al. “Sparse feature circuits: Discovering and editing interpretable causal graphs in language models.” arXiv preprint arXiv:2403.19647 (2024).
模型性能与安全性
1.通过稀疏激活控制(SAC)技术,独立调控注意力头以同时提升模型的安全性、事实性和无偏见性。
Xiao, Yuxin, et al. “Enhancing Multiple Dimensions of Trustworthiness in LLMs via Sparse Activation Control.” Advances in Neural Information Processing Systems 37 (2024): 15730-15764.
https://arxiv.org/abs/2411.02461
2.揭示DPO对齐算法通过分布式微调绕过(而非消除)毒性生成区域,解释模型易被逆向破解的机制。
Lee, Andrew, et al. “A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity.” arXiv preprint arXiv:2401.01967 (2024).
https://arxiv.org/pdf/2401.01967
3.研究发现链式思维(CoT)提示生成的推理过程并不总是忠实反映模型的真实推理意图,提示监控CoT可能不足以检测罕见或意外的模型行为。
Chen, Yanda, et al. “Reasoning Models Don’t Always Say What They Think.” arXiv preprint arXiv:2505.05410 (2025).
https://arxiv.org/abs/2505.05410
4.通过表征工程(如LAT方法)监控和控制模型内部的高层认知概念(如诚实性)。
Zou, Andy, et al. “Representation engineering: A top-down approach to ai transparency.” arXiv preprint arXiv:2310.01405 (2023). https://arxiv.org/pdf/2310.01405
5.通过微调关键子模块(<5%)解决大模型中的谄媚行为,保持通用能力。
Chen, Wei, et al. “From yes-men to truth-tellers: addressing sycophancy in large language models with pinpoint tuning.” arXiv preprint arXiv:2409.01658 (2024).
https://arxiv.org/abs/2409.01658
模型融合
1.研究多语言模型中语言特定和语言无关的模块划分,分析跨语言知识迁移的机制。
Zhao, Yiran, et al. “How do large language models handle multilingualism?.” arXiv preprint arXiv:2402.18815 (2024).https://arxiv.org/pdf/2402.18815
2.类比生物系统研究LLM内部组件的协同机制,提出模块间动态交互形成复杂行为的理论框架。(回路发现中也有这篇文章)
Lindsey, Jack, et al. “On the biology of a large language model.” Transformer Circuits Thread (2025).
https://transformercircuits.pub/2025/attribution-graphs/biology.htm
3.提出一种自动化生成高质量神经元描述的方法,通过微调模拟器和解释器模型,实现对大规模语言模型内部神经元的低成本、高效描述。
Scaling Automatic Neuron Description. Transluce AI. https://transluce.org/neuron-descriptions
4.利用子模块的线性特性独立合并模型,提升多任务算术性能。
Dai, Rui, et al. “Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs.” arXiv preprint arXiv:2504.10902 (2025).
https://arxiv.org/abs/2504.109025.
5.提出“伪遗忘”概念,通过冻结底层参数缓解持续学习中的任务对齐退化问题。
Zheng, Junhao, et al. “Spurious Forgetting in Continual Learning of Language Models.” arXiv preprint arXiv:2501.13453 (2025).https://openreview.net/forum?id=ScI7IlKGdI
书籍推荐
杨强,范力欣,朱军,陈一昕,张拳石,朱松纯,陶大程,崔鹏,周少华,刘琦黄萱菁,张永锋,可解释人工智能导论,2022,电子工业出版社

Christoph Molnar,郭涛(译),可解释机器学习:黑盒模型可解释性理解指南(第2版),2024,电子工业出版社

关于集智俱乐部读书会和举办方
关于集智俱乐部读书会和举办方
集智俱乐部读书会是面向广大科研工作者的系列论文研读活动,其目的是共同深入学习探讨某个科学议题,了解前沿进展,激发科研灵感,促进科研合作,降低科研门槛。
读书会活动始于 2008 年,至今已经有 50 余个主题,内容涵盖复杂系统、人工智能、脑与意识、生命科学、因果科学、高阶网络等。凝聚了众多优秀科研工作者,促进了科研合作发表论文,孵化了许多科研产品。如:2013 年的“深度学习”读书会孕育了彩云天气 APP,2015 年的“集体注意力流”读书会产生了众包书籍《走近2050》,2020年的开始因果科学读书会孕育了全国最大的因果科学社区等。
主办方:集智俱乐部
协办方:集智学园
集智俱乐部成立于 2003 年,是一个从事学术研究、享受科学乐趣的探索者的团体,也是国内最早的研究人工智能、复杂系统的科学社区。它倡导以平等开放的态度、科学实证的精神,进行跨学科的研究与交流,力图搭建一个中国的 “ 没有围墙的研究所 ”。集智科学研究中心(民间非营利企业)是集智俱乐部的运营主体,其使命为:营造跨学科探索小生境,催化复杂性科学新理论。
集智学园成立于2016年,是集智俱乐部孕育的创业团队。集智学园致力于传播复杂性科学、人工智能等前沿知识和新兴技术,促进、推动复杂科学领域的知识探索与生态构建。

6. 加入集智,玩转复杂,共创斑图!集智俱乐部线下志愿者招募
微信扫一扫,分享到朋友圈











