可解释性方法概览与类脑潜空间推理框架展望丨周四直播·大模型可解释性读书会
导语

分享简介
分享简介
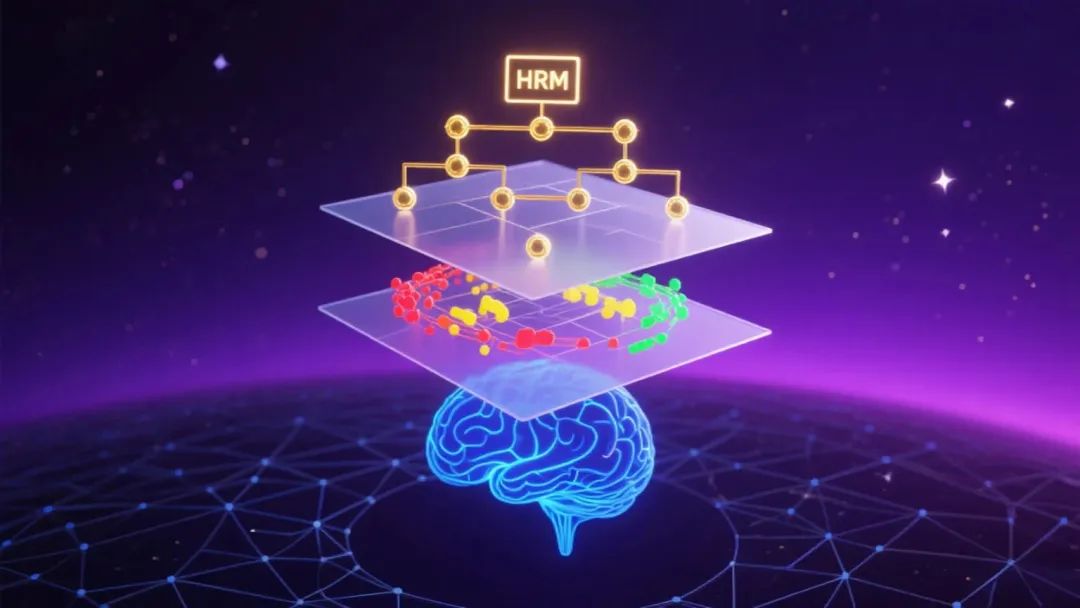
大语言模型(LLMs)的机制可解释性是一个典型的跨学科问题。本次分享将结合复杂系统、神经科学、计算机科学与物理学等不同领域的研究进展,概览并比较可解释性的多种方法路径。除了回顾既有工作外,还将展示部分新的研究结果,并重点探讨如何评估模型输出的可靠性。最后,分享将介绍与可解释性高度相关的潜空间推理领域,分享层级化推理模型(Hierarchical Reasoning Model, HRM)的框架与未来应用潜力。
分享大纲
分享大纲
一、大模型可解释性方法回顾
-
基于回路分析的方法:解析模型内部电路与表示路径
-
基于复杂系统的方法:从动力学与涌现角度理解模型
-
基于神经科学的方法:借鉴脑科学实验与表征分析
-
基于认知心理学的方法:对比人类思维模式与模型机制
-
模型输出可靠性预测研究:从解释性走向实际可控与可验证
二、潜空间推理 HRM 模型介绍
-
HRM 计算框架与训练方法:结合层级化结构与类脑动力学
-
HRM 的可解释性分析:低维流形、层级推理与透明机制
-
未来应用潜力:在科学发现、知识推理与跨领域泛化中的可能性
三、圆桌讨论
-
在不同的应用场景下,企业应该投入多少研发成本来追求解释性?
-
是否可以基于可解释性研究建立一套通用的“算子库”?例如模型情绪算子,回答可靠性算子等。
-
大模型的可解释性与神经科学之间的互相启发还有多大的前景?
-
可解释性是否能够帮助我们更好地利用潜空间进行推理?
-
社区成员提问
黑心概念
黑心概念
Circuit(回路)
模型内部特定能力或完成特定任务的相关模块及其连接(head/neuron等)构成的子图。
Path Patching(路径修补)
通过对模型各模块进行扰动并分析对模型特定行为的影响,定位模型内部与特定任务相关的关键模块(head/neuron等)。
PCA(主成分分析)
一种降维方法。在大模型可解释性中,常用于对模型的高维特征(如神经元激活值、隐藏层输出)进行降维,将复杂的高维数据映射到低维空间,提取最具代表性的主成分。
LORA(低秩适应)
一种模型微调技术,核心是通过低秩矩阵分解来近似表示模型参数的更新量,仅训练少量低秩矩阵参数而非全部模型参数。
Phase Transition(相变)
原是物理学概念,指系统在外界条件变化时从一种状态突变到另一种状态的过程。在大模型中,指模型的行为或性能在某些参数变化到临界值时发生的突然、显著的变化。
Small-world Network(小世界网络)
一种网络结构特征,兼具 “高聚类系数”(节点的邻居间联系紧密)和 “短平均路径长度”(任意两节点间通过少量步骤即可连接)。大模型的内部模块(如神经元连接)常呈现小世界网络特性,这种结构既保证了局部模块的高效协同,又能实现全局信息的快速传递。
Hierachy (层级结构)
指模型内部模块或特征表示的层级组织方式。大模型通常具有多层级结构,底层可能编码简单特征(如文本中的字符、图像中的边缘),高层则编码更抽象、复杂的概念(如语义、物体类别)。
Recurrent (循环)
指模型中具有 “循环连接” 的结构(如循环神经网络 RNN),即输出会被反馈到输入端,使模型能处理序列数据(如文本、时间序列)并保留上下文信息。
Slow fast timescale separation(快慢时间尺度分离)
指系统中存在两种不同时间尺度的动态过程:“慢过程”(如长期记忆的更新、模型参数的缓慢调整)和 “快过程”(如短期信息的处理、实时输出的计算)。
参考文献
参考文献
1. Emergent Response Planning in LLMs (ICML 2025)
揭示大语言模型(LLMs)在生成首个词元前已通过隐藏层编码全局输出的结构、内容和行为属性(如回复长度、故事角色选择、答案可信度),提出 “前瞻规划” 机制,为模型可控性和透明度提供新视角。
2.Geva, Mor, et al. “Transformer Feed-Forward Layers Are Key-Value Memories.” arXiv:2012.14913, 2020
提出 Transformer 的前馈层(FFNs)本质上是键值记忆结构,键对应文本模式,值对应输出分布,底层捕捉浅层模式,高层编码语义信息,为解释模型的知识存储和推理机制提供了新框架。
3.Zou, Andy, et al. “REPRESENTATION ENGINEERING: A TOP-DOWN APPROACH TO AI TRANSPARENCY.” arXiv:2310.01405, 2023
提出一种自上而下的 AI 透明度方法,通过分析模型的 “群体级表示” 而非单个神经元,实现对诚实性、无害性等复杂认知现象的监测与操控,为大模型的安全对齐提供了可操作的技术路径。
4.Cambria, Erik, et al. “SenticNet 7: A Commonsense-based Neurosymbolic AI Framework for Explainable Sentiment Analysis.” Semantic Scholar, 2021
构建融合常识知识与神经符号 AI 的 SenticNet 7 框架,通过自动发现概念原语并链接常识概念,实现情感分析的可解释性,同时支持多语言和多模态场景的情感推理。
5.Topology of reasoning: understanding large reasoning models through reasoning graph properties
提出通过构建推理图分析大模型的拓扑结构(如探索密度、分支比、收敛性),发现图结构特征与推理准确性强相关,为评估和优化模型推理能力提供了量化框架。
6. “Hierarchical reasoning model.” arXiv:2502.06772, 2025
受大脑层级处理机制启发,设计包含 “抽象规划” 和 “细节计算” 双循环模块的分层推理模型(HRM),仅用 2700 万参数在数独、迷宫等复杂任务上超越传统思维链模型,实现计算深度与效率的平衡。
7.Learning-at-Criticality in Large Language Models for Quantum Field Theory and Beyond
该论文提出临界学习(LaC)理论框架,通过强化学习将大语言模型(LLMs)参数调整至临界状态,使模型在极少量训练数据下实现最优泛化性能。
8.从「无限深」到「一步之遥」:隐函数定理如何为神经网络「抄近道」
https://zhuanlan.zhihu.com/p/1941426523631486436
主讲人简介
主讲人简介

许铁,之江实验室研究员,毕业于以色列理工大学复杂系统专业,研究领域为人工智能。
圆桌嘉宾简介
圆桌嘉宾简介

肖达,人工智能公司彩云科技联合创始人、首席科学家、北京邮电大学网络空间安全学院副教授。
研究方向:主要负责深度神经网络模型和算法的研发用于彩云天气、彩云小译、彩云小梦等产品。

沈旭,阿里云-飞天实验室高级算法专家。博士毕业于中国科学技术大学。曾获浙江省科技进步一等奖,在ICLR/ICML/NeurIPS/ACL/CVPR/ECCV/ICCV等国际顶会上发表论文40余篇,google scholar引用1900余次。
研究方向:大模型可解释性、主权大模型。

杨明哲,北京师范大学系统科学学院硕士生,张江老师因果涌现研究小组成员。
研究方向:因果涌现、复杂系统自动建模。

姚云志,浙江大学计算机科学与技术学院在读博士生,导师为陈华钧教授与张宁豫教授。现在是加州大学洛杉矶分校的访问研究学者,与Nanyun Peng教授一起工作。
研究方向:自然语言处理的机器学习,特别关注支撑大型语言模型 (LLM) 的知识机制。研究 LLM 如何获取、存储和利用知识进行推理,以及不同架构和模式的模型之间的交互方式。目标是开发简洁而精确的模型编辑方法。

章彦博,塔夫茨大学博士后,美国亚利桑那州立大学复杂系统博士,本科毕业于中国科学技术大学凝聚态物理系,集智科学家,曾在瑞典卡罗琳斯卡医学院进行访问交流。研究方向:统计物理、复杂系统等。他的研究兴趣主要是试图理解我们这个世界的“特殊尺度”。为什么原子会存在?为什么分子会存在?为什么“事物”的概念是一个有用的概念?此外,他还致力于利用化学反应网络探索生命的起源。 在他的主要研究之外,他喜欢研究在线社交网络和古代音乐史。
参与方式
参与方式
参与时间:
北京时间2025年8月21日(周四)晚上19:30-21:30
扫码报名加入社群交流,并获取腾讯会议链接。

(可开发票)
https://pattern.swarma.org/study_group_issue/969?from=wechat
扫码参与「大模型可解释性」读书会,加入社群,获取系列读书会永久回看权限,与社区的一线科研工作者沟通交流,共同探索大模型可解释性这一前沿领域的发展。
大模型可解释性读书会
集智俱乐部联合上海交通大学副教授张拳石、阿里云大模型可解释性团队负责人沈旭、彩云科技首席科学家肖达、北京师范大学硕士生杨明哲和浙江大学博士生姚云志共同发起「大模型可解释性」读书会。本读书会旨在突破大模型“黑箱”困境,尝试从以下四个视角梳理大语言模型可解释性的科学方法论:
自下而上:Transformer circuit 为什么有效?
自上而下:神经网络的精细决策逻辑和性能根因是否可以被严谨、清晰地解释清楚?
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











