然而,要使这个连接方程获得真正的解释和预测能力,还需要一个正式的理论框架将信息和物质联系起来。这种联系的第一条线索出现在1867年。在一封给朋友的信中,苏格兰物理学家麦克斯韦设想了一个微小的生物,它可以感知在一盒气体中四处乱窜的单个分子。通过操纵一扇小门,这个被称为“麦克斯韦妖”的小东西可以将所有速度快的分子引导到盒子左边,将速度慢的分子引导到盒子右边。
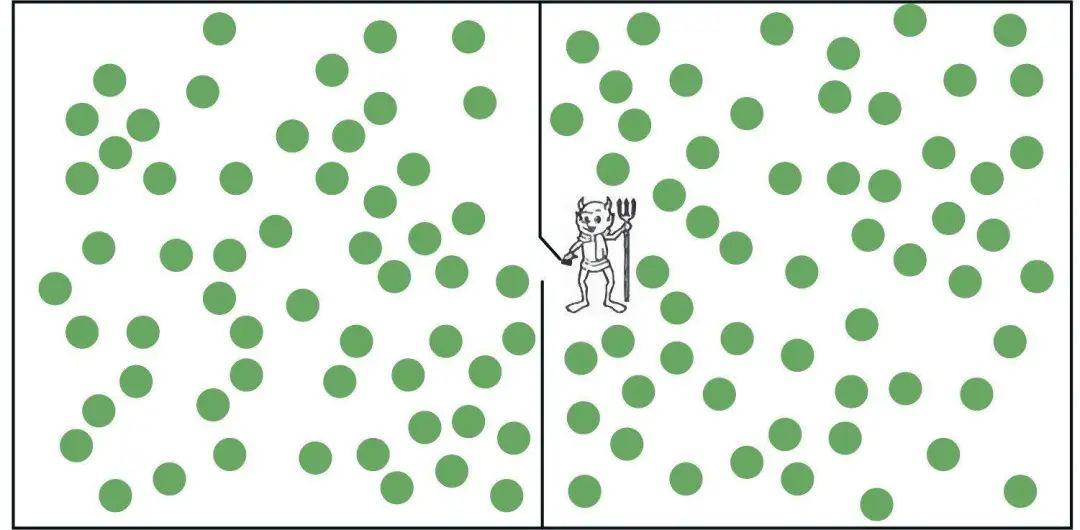 图3:麦克斯韦妖(Maxwell’s demon)
图3显示的是一盒气体被带有小孔的屏障分成两个腔室,(绿色的)分子可以一个接一个地通过小孔。一扇小门阻挡着小孔,并且由麦克斯韦1867年构想的小妖所把守:小妖观察随机运动的分子,它可以打开或关闭小门,从而让快速的分子从右边移动到左边,让缓慢的分子向反方向移动。然后,这个机制就可以用来将无序的分子运动转化为定向的机械运动。
几十年来,这个“小妖”像一个令人颇感为难的事实处于物理学的核心位置,大多数时候它只是被当作一个理论难题忽略掉。在麦克斯韦提出这个思想实验一个世纪以后,科学家们在他的出生地爱丁堡的一个实验室里制造出了一个真正的小妖。实验中用到了一个分子环,它可以在两端有阻拦物的棒上来回滑动。在棒的中间有另一个分子,它可以以两种构象存在——一种阻止分子环滑动通过,另一种允许分子环通过。这个分子因而就像是一扇门,类似于麦克斯韦最初构想的可以移动的小门[17]。
由于这个实验的引导,众多的小妖设备纷纷出现,包括由芬兰阿尔托大学纳米科学小组的 Jukka Pekola 和纽约大学石溪分校的 Dmitri Averin 建造的信息驱动冰箱[18]。在这个冰箱里,气体分子被禁锢于一个双面纳米尺寸的盒子中的单个电子取而代之,这个盒子与热浴耦合。冷却循环利用盒子中具有特定电子能量的两个简并态的存在。在循环最开始,电子处于一个确定的非简并态。外加电场将电子能量提高到简并能级,这样电子可以以相等的概率停留在两种状态中的任何一种。
这种不确定性的引入意味着电子的熵增加,而热浴的熵,也就是温度相应减少。此时与第一个单电子盒子耦合的另一个盒子扮演小妖的角色,它探测电子处于两种状态中的哪一个,并自动将信息反馈给提供驱动的电场,电场利用这个信息快速将电子返回到初始的非简并态,从而完成整个冷却循环。研究人员发现,每次循环产生1比特信息——对应电子所处的状态——的过程能够以75%的平均效率从热浴中提取热量。麦克斯韦是对的:信息确实可以作为一种驱动燃料。
图3:麦克斯韦妖(Maxwell’s demon)
图3显示的是一盒气体被带有小孔的屏障分成两个腔室,(绿色的)分子可以一个接一个地通过小孔。一扇小门阻挡着小孔,并且由麦克斯韦1867年构想的小妖所把守:小妖观察随机运动的分子,它可以打开或关闭小门,从而让快速的分子从右边移动到左边,让缓慢的分子向反方向移动。然后,这个机制就可以用来将无序的分子运动转化为定向的机械运动。
几十年来,这个“小妖”像一个令人颇感为难的事实处于物理学的核心位置,大多数时候它只是被当作一个理论难题忽略掉。在麦克斯韦提出这个思想实验一个世纪以后,科学家们在他的出生地爱丁堡的一个实验室里制造出了一个真正的小妖。实验中用到了一个分子环,它可以在两端有阻拦物的棒上来回滑动。在棒的中间有另一个分子,它可以以两种构象存在——一种阻止分子环滑动通过,另一种允许分子环通过。这个分子因而就像是一扇门,类似于麦克斯韦最初构想的可以移动的小门[17]。
由于这个实验的引导,众多的小妖设备纷纷出现,包括由芬兰阿尔托大学纳米科学小组的 Jukka Pekola 和纽约大学石溪分校的 Dmitri Averin 建造的信息驱动冰箱[18]。在这个冰箱里,气体分子被禁锢于一个双面纳米尺寸的盒子中的单个电子取而代之,这个盒子与热浴耦合。冷却循环利用盒子中具有特定电子能量的两个简并态的存在。在循环最开始,电子处于一个确定的非简并态。外加电场将电子能量提高到简并能级,这样电子可以以相等的概率停留在两种状态中的任何一种。
这种不确定性的引入意味着电子的熵增加,而热浴的熵,也就是温度相应减少。此时与第一个单电子盒子耦合的另一个盒子扮演小妖的角色,它探测电子处于两种状态中的哪一个,并自动将信息反馈给提供驱动的电场,电场利用这个信息快速将电子返回到初始的非简并态,从而完成整个冷却循环。研究人员发现,每次循环产生1比特信息——对应电子所处的状态——的过程能够以75%的平均效率从热浴中提取热量。麦克斯韦是对的:信息确实可以作为一种驱动燃料。
因为分子速度是温度的度量,所以小妖实际上是利用分子的信息在盒子里制造了一个热量梯度。然后,工程师就可以利用这个热量梯度来提取能量,做有用功。从表面上看,麦克斯韦设计了一台纯粹由信息驱动的永动机,违反了热力学第二定律。
为了解决这个悖论,必须将信息量化并正式包含到热力学定律中。现代信息论[4]的基础由克劳德·香农(Claude Shannon)在上世纪40年代末奠定。香农将信息定义为不确定性的减少——例如,通过检查掷硬币的结果来降低不确定性。掷硬币确定正面朝上还是反面朝上时获得的信息就是熟悉的二进制数字,或者说比特。为了结合香农的信息论与热力学,信息被定义为负熵。因此,小妖为获得热力学优势而获取的任何信息都必须在某个阶段以熵的增加为代价——例如,当小妖对于分子信息的记忆被清除和重置以便能够重复循环时。
麦克斯韦只是构想了关于小妖的思想实验,但如今纳米技术的进展使得通过实验实现这个基本想法成为可能。数十亿年来,生命甚至一直在制造和利用各种各样的“小妖”。它们充满了我们的身体[5]。复制DNA的分子机器、沿着纤维的物质运输,或者穿越细胞膜的质子泵的运转非常接近理想的热力学极限。它们游走在热力学第二定律的边缘以获得能量优势[6-7]。人类大脑的连接中也使用了一种“小妖”——电压门控离子通道——来传播电信号。这些离子通道保证大脑能够以相当于一个微弱灯泡的能量运转,尽管它具有相当于一台兆瓦量级超级计算机的强大功能[8]。
“小妖”仅仅是生命的信息冰山之一角。生物信息远远超出了优化能量预算的功能;它经常扮演管理者的角色。我们可以考虑受精卵发育为胚胎(图4)的过程。它在每一个阶段都受到由多种物理和化学过程精细调节的信息网络的监督,所有这些安排使得最终复杂的形式以正确的结构和形态出现。
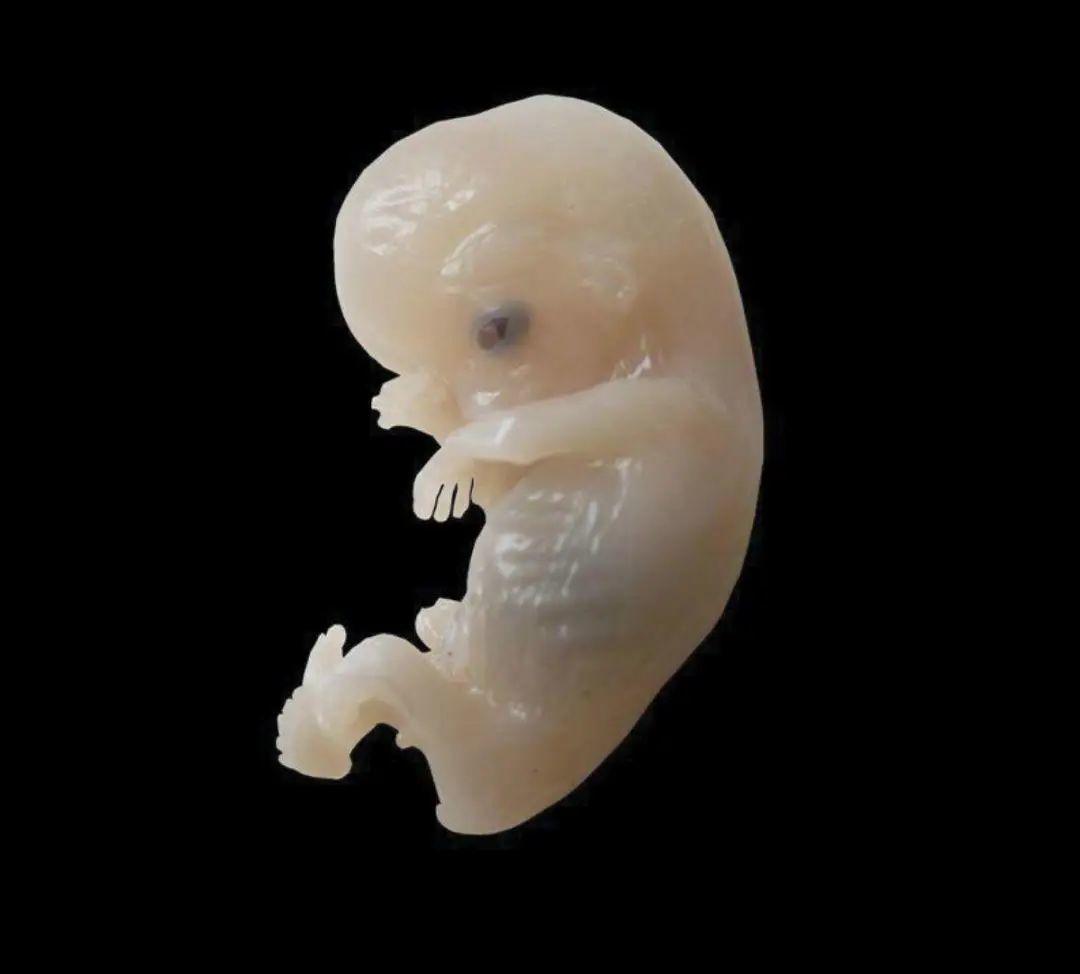
图4:人类胚胎,8-9周,38毫米长 | 图片改编自Anatomist90,维基共享
利用基因调控网络中的信息流来模拟胚胎发生的尝试已经取得了显著成功。加州理工学院的 Eric Davidson 和同事们从化学上描绘出了控制海胆早期发育的基因网络的完整连接图像。通过跟踪信息流,研究小组编写了一套计算机程序来逐步模拟网络动力学。在每一个阶段,他们将回路状态的计算机模型与观察到的海胆发育阶段进行比较,结果获得了令人印象深刻的匹配结果。研究人员还在计算机模型中探讨了用化学方法让特定基因沉默的影响,以预测发生突变的胚胎会遭遇什么;结果他们的模型与实验观察再次相符[9]。
普林斯顿大学的 Thomas Gregor 和 William Bialek 领导的小组一直在研究果蝇发育的早期阶段,特别是其独特的形态特征最初是如何出现的。在发育过程中,细胞需要知道它们在三维空间中相对于其他细胞的位置。那么它们如何获得位置信息呢?人们很早就知道,细胞具有一种基于化学梯度的 GPS,而化学梯度又进一步由特定基因的表达水平调节。普林斯顿大学的研究小组最近将注意力集中在四种所谓的间隔基因上,这些基因通过在身体构造上形成间隔或条带为胚胎的形态奠定基础。研究人员发现,细胞利用贝叶斯概率从基因表达水平中提取最佳位置信息,精度达到了惊人的1%。他们还将贝叶斯优化模型应用到突变菌株上,并正确预测胚胎变化后的形态[10]。

图5:果蝇早期胚胎中的间隔基因,它们的突变会导致特定身体片段的缺失 | Haecker A, Qi D, Lilja T, Moussian B, Andrioli LP, Luschnig S, Mannervik M
这些分析提出了一个关键的哲学问题,直指物理学和生物学概念不匹配这一问题的核心。基因调控网络的研究和贝叶斯算法的应用目前被视为现象学模型,在这里,“信息”是产生真实生物体的逼真模拟的一种方便的替代品或标签。但麦克斯韦妖给我们的启示是,信息实际上是一个物理量,它可以深刻地影响物质的行为方式。香农定义的信息不只是一个非正式参数,它是一个基本的物理变量,在热力学定律中占有一席之地。
香农强调,他的信息论纯粹是处理信息流动的效率和能力,并不包含所传达信息的含义。但在生物学中,意义或环境至关重要。如何才能从数学层面上探得指导、监督或环境信息的性质呢?有一种方法是分子生物学中所谓的中心法则——这是克里克(Francis Crick)和沃森(James Watson)在推导出DNA双螺旋结构大约十年后创造的一个术语,中心法则认为,信息是单向流动的,从DNA到制造蛋白质的机器,再到生物体。我们或许称之为“自下而上”的流动。
如今我们早已得知:生物学中的信息传递是一个双向过程,包括反馈循环和自上而下的信息流。例如,如果培养皿中的细胞过于拥挤,它们就会停止分裂,这种现象被称为接触抑制。此外,国际空间站上的微生物实验表明,细菌在失重环境下会表达的基因可能与在地球上不同。显然,系统层面的物理作用会在分子水平上影响基因表达。
美国塔夫茨大学艾伦发现中心的 Michael Levin 和同事们的工作为自上而下的信息流提供了一个引人注目的例子。Levin 的小组正在探索,对于控制一些生物体的生长和形态而言,系统层面的电模式如何能像机械力或化学模式一样重要。健康细胞是电极化的:它们通过泵出离子,在细胞壁两侧维持几十或几百毫伏的电势差。与之相反,癌细胞则倾向于去极化。
Levin 的小组发现,在多细胞生物中,跨组织的细胞极化模式在生长发育、伤口愈合和器官再生中发挥着关键作用。通过从化学上破坏这些电极化模式,可以产生新的形态秩序[11]。扁形动物门涡虫纲的片蛭科生物(planaria,一类简单的两侧对称动物)可以作为方便的实验对象。如果一只普通的虫子被切成两半,头部的一半会长出一条新的尾巴,尾巴的一半会长出一个新的头部,这样就形成了两只完整的虫子。但通过改变伤口附近的电极化状态,可以形成有两个头或两个尾巴的虫子(图6)。
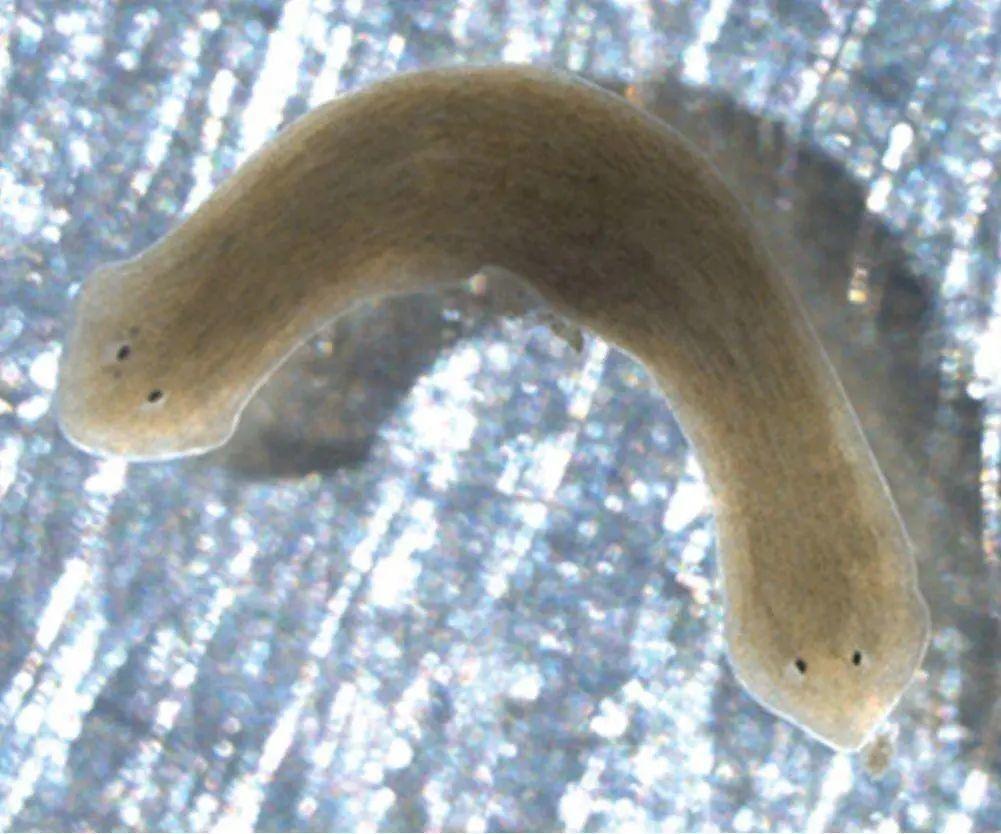
图6:这只双头虫是通过操纵电极性创造出来的。当这种虫子被切成两半时,它会繁殖出更多的双头虫,就好像形成了一个不同的物种,尽管它和正常的单头虫有着相同的DNA。整个身体发育的信息以某种方式表观遗传给了后代 | Adapted from T. Nogi et al., PLOS Negl. Trop. Dis. 3, e464, 2009
令人惊讶的是,如果将这些怪物切成两半,它们不会恢复到正常形态,相反,双头虫会产生更多的双头虫,双尾虫同样如此。尽管它们都拥有相同的DNA,看起来却像是不同的物种。系统的形态信息必然以一种分布式的方式存储在截断的组织中,并在基因水平指导合适的再生。但这一切是如何做到的?是有一套电信号密码与遗传密码同步运作吗?
表观遗传学是在不改变DNA序列的前提下,通过某些机制——比如超出基因层面的物理作用——引起可遗传的基因表达或细胞表现型的变化。对表观遗传的信息存储、处理和传输机制,我们知之甚少,但它们在生物学中的作用至关重要。若要取得进展,我们需要发现电的、化学的、基因的这些不同类型的信息模式如何相互作用从而产生一个调节框架,管理生命物质的组织,并将其转化为特定的表现型。
用信息的术语而非纯粹的分子术语来思考生命物质的物理学,就像计算领域软件和硬件之间的区别一样。正如要完全理解一个特定的计算机应用程序(例如PowerPoint)需要对软件工程原理和计算机电路的物理理解得同样多,只有当生物信息动力学的原理被充分阐明,我们才能理解生命。
自牛顿的时代以来,一种基本的二元论就渗透于物理学。虽然物理状态会随着时间演化,但底层的物理学定律通常被认为是不变的。这个假设是哈密顿力学、轨迹可积性和遍历性的基础。但是,不变的定律不那么适用于生物系统,在生物系统中,信息的动态模式与随时间变化的化学网络相耦合,而表达的信息——例如基因的开启——可能既依赖于全局或系统的物理作用,也依赖于局部的化学信号。
生物学演化具有开放的多样性、新颖性和不可预测性,这也与非生物系统随时间变化的方式形成鲜明对比。然而,生物学并不意味着混沌,我们可以找到许多发挥作用的规则的例证。以通用的遗传密码为例,核苷酸三联体 CGT 编码氨基酸中的精氨酸。虽然这个规则没有什么已知的例外,但把它看作像是万有引力定律一样一成不变的自然法则是错误的。几乎可以肯定的是,CGT分配给精氨酸作为密码子是数百万年前从一些更早更简单的规则中出现的。生物学这样的例子比比皆是。
对生物系统变化的一个更逼真的描述将是,动力学规则作为系统状态的函数而变化[2, 12]。依赖于系统状态的动力学为各种新奇行为开辟了广阔的图景,但它还远不是一个正式的数学理论。为了理解这当中可能需要什么,不妨将它与一盘国际象棋做类比。在标准国际象棋中,系统是封闭的,规则是固定的。从传统的初始状态开始,棋手可以自由探索棋子的各种布局,虽然这意味着巨大的可能性,但却受到不可更改的规则的约束,只局限于棋盘上所有可能的棋子排布的一个小子集。可能的模式虽多,不允许的模式更多——比如让所有主教占据相同颜色的方格。
现在想象一种经过修改的国际象棋游戏,它的规则可以根据游戏的整体状态,也就是系统层面或者自上而下的标准而改变。举一个看上去有点傻的例子,如果白棋处于优势,那么或许可以允许黑棋的兵既可以向前走,也可以向后走。在这个扩展版本的国际象棋游戏中,系统是开放的,新的游戏状态将会出现,这是应用标准国际象棋的固定规则时根本不可能出现的。这个虚构的游戏就像是生物学,生物体也是开放的系统,它们能够实现非生命系统看似不可能完成的事情。
我在亚利桑那州立大学的研究小组使用了一维元胞自动机的一种修改版本,在一个捕获自上向下信息流的简单模型中,探索与状态相关的动力学的影响。标准的元胞自动机是一排方格(正方形或像素),它们要么空白,要么是填充的(例如分别是白色和黑色);然后根据每个元胞的现有状态及其最近邻的状态,应用一套固定规则来更新它们的状态。我们的系统有256种可能的更新规则[13]。
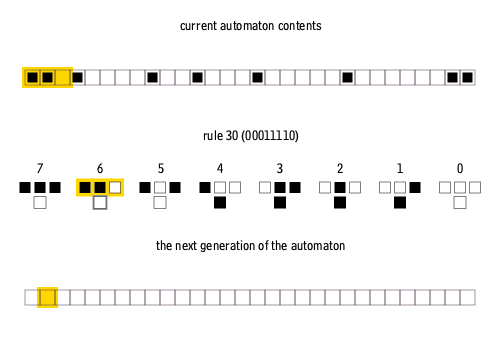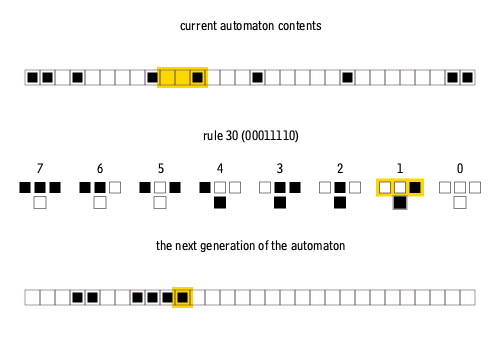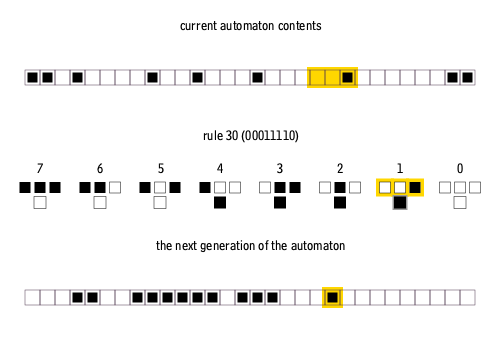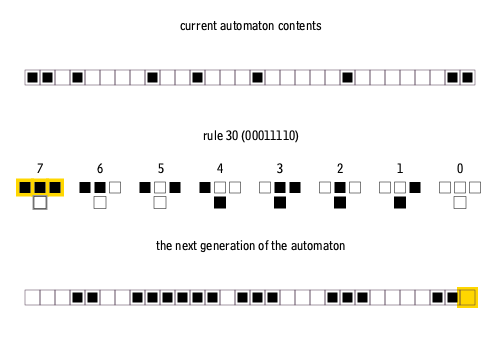
图7:一维元胞自动机的演化。第一行表示初始元胞状态,第二行表示更新规则,第三行表示下一代元胞状态 | Cormullion/Wikipedia
要玩元胞自动机游戏,需要选择一个初始元胞模式——元胞模式可以方便地表示为0和1组成的二进制序列——然后反复应用所选择的更新规则让系统演化。许多更新规则会导致乏味的结果,但有少数规则会产生复杂的演化模式。为了实现修改版本的、依赖于系统状态的元胞自动机,我的同事 Alyssa Adams 和 Sara Walker 计算耦合了两个标准的元胞自动机。其中一个代表生物体,另一个代表环境。然后,这两位研究人员允许生物体的更新规则在每次迭代时改变[14]。
为了确定在给定的步骤中,到底要应用256种规则中的哪一个,他们将生物体元胞自动机的元胞捆绑成相邻的三联体——000、010、110等等,并将每个三联体的相对频率与环境元胞自动机中的相同模式进行比较。这样的安排就改变了更新规则,使其既是生物体状态的函数——使其具有自指性,也是环境状态的函数——使其成为一个开放的系统。
Adams 和 Walker 在电脑上进行了数千个案例研究,以寻找有趣的模式。他们想要识别出既开放——生物体不会很快回到其初始状态——又创新的演化行为。创新在这个语境下意味着,观察到的生物体状态序列永远不会出现在从任何初始状态开始的、具有256种可能的固定规则的元胞自动机中。这就好比在修改版本的国际象棋游戏中,四个主教最终出现在相同颜色的方格中。
虽然这种开放、创新的行为很罕见,但还是出现了一些明确的例子。这个过程花费了大量的计算时间,但 Adams 和 Walker 的发现足以让人相信:即使在他们的简单模型中,依赖于状态的动力学提供了通往复杂性和多样性的新路径。他们的研究表明,仅仅处理信息比特是不够的。为了捕捉生物学的全部丰富性,信息处理规则本身也必须演化。
如果生物学运用了新物理,比如依赖于状态的动力学规则,那么它在简单分子和活细胞之间的哪个位置出现呢?元胞自动机模型或许具有指导意义,但它们是卡通,不是物理;它们不会告诉我们去哪里寻找涌现的新现象。事实上,物理学中已经包含了依赖于状态的动力学的一个熟悉例子:量子力学。
在孤立的状态下,由相干波函数描述的纯量子态会以可预测的方式演化,遵循一个众所周知的数学公式——幺正演化(指量子态随时间演化时,其波函数在任何时刻都将保持归一化,即在空间中找到粒子的总概率等于1,是守恒的)。但是当进行测量时,量子态会突然改变——这种现象通常被称为波函数的坍缩。在理想测量中,波函数坍缩会将系统投射到与被测量的可观测量相对应的一个可能本征态上。在这一步,幺正演化规则被玻恩规则取代,后者预测测量结果的相对概率,并将不确定性引入量子力学。这标志着从量子到经典领域的转变。因此,量子力学能告诉我们是什么让生命运转吗?
薛定谔在他著名的都柏林演讲中曾求助于量子力学来解释遗传信息存储的稳定性。在克里克和沃森阐明 DNA 结构之前,薛定谔曾推断,信息必须在分子水平上存储于他所谓的“非周期性晶体”(不具有周期性规则排列的晶格结构,但衍射图样有锋锐的尖峰)中,而这最终被证明是对作为遗传物质载体的核酸聚合物的一个直观描述。然而,一种可能性仍然存在,那就是量子现象在生物体中或许扮演着更普遍的角色。
在之后的几十年里,一个普遍的假设流传开来:在生命物质的温暖嘈杂的环境中,量子现象将被扼杀,经典的球棒化学足以解释生命。然而,在过去十年左右时间里,人们对一种新的可能性越来越感兴趣——非平凡的量子现象,如叠加、纠缠和隧穿效应等,可能对生命至关重要。尽管仍有相当多的怀疑,但科学家目前正对量子生物学这一新领域进行深入研究[15]。研究专注于各种各样的课题,如光合作用中的相干能量传输、鸟类的磁感知,还有苍蝇的嗅觉反应。
在纳米尺度上研究生命物质的量子特性面临着重大挑战。对生命运转至关重要的系统可能只有几个自由度,可能远离热力学平衡,并且可能与周围的热环境强烈耦合。但正是在非平衡量子统计力学领域,我们期待可能出现新物理。
一组可能相关的实验是测量有机分子中的电子电导(载流子是电子或空穴的电导)。最近,Gábor Vattay 和同事们声称,许多重要的生物分子,如蔗糖和维生素D3,都具有独特的电子电导性质,与绝缘体和无序金属导体之间的临界转变点有关。他们写道:“这些发现表明,生命物质中存在一种普遍的电荷输运机制。”[16]尽管他们的发现并不能说明量子奇异性可以解释生命,但他们确实暗示,在量子调谐的大分子领域,人们可能会发现薛定谔和他的同时代人所猜测的新物理学的出现。
理论物理学家惠勒(John Archibald Wheeler)常说,科学的重大进展更多地源于不同思想的碰撞,而非事实的稳步积累。生物物理学处于物理科学和生命科学这两大科学领域的交叉点。每个领域都有自己的词汇,也有自己独特的概念框架,物理学根植于力的概念,生物学根植于信息的概念。这两者碰撞出的火花预示着一个新的科学前沿,在这里,现在被正式理解为是一个物理量——或者说是一组量的信息占据了中心位置,从而将用于统一物理学和生物学[2]。
分子生物学在过去几十年的巨大进展很大程度上归功于力的概念在生物系统中的应用,这是物理学对生物学的渗透。奇妙的是,相反的事情正在发生。许多物理学家,尤其是那些致力于量子力学基础问题的物理学家,主张将信息放在物理学的核心位置,而另一些物理学家则猜测:新物理学潜藏在引人注目且令人困惑的生物体的世界中。生物学正在成为物理学的下一个伟大前沿。
参考文献:
[1] E. Schrödinger, What Is Life? The Physical Aspect of the Living Cell, Cambridge U. Press (1944).
[2] P. Davies, The Demon in the MachineHow Hidden Webs of Information Are Solving the Mystery of Life, U. Chicago Press (2019).
[3] U. Alon, An Introduction to Systems Biology: Design Principles of Biological Circuits, Chapman & Hall/CRC Press (2006).
[4] J. Soni, R. Goodman, A Mind at Play: How Claude Shannon Invented the Information Age, Simon & Schuster (2017).
[5] P. Hoffman, Life’s Ratchet: How Molecular Machines Extract Order from Chaos, Basic Books (2012).
[6] P. M. Binder, A. Danchin, Eur. Mol. Biol. Org. Rep. 12(1), 495 (2011). https://doi.org/10.1038/embor.2011.83.
[7] P. Ball, “Bacteria replicate close to the physical limit of efficiency,” Nature (20 September 2012). https://doi.org/10.1038/nature.2012.11446.
[8] W. Loewenstein, The Touchstone of Life: Molecular Information, Cell Communication, and the Foundations of Life, Oxford U. Press (1999), p. 227.
[9] J. Smith, E. Davidson, Proc. Natl. Acad. Sci. USA 105, 20089 (2008). https://doi.org/10.1073/pnas.0806442105.
[10] M. D. Petkova et al., Cell 176, 844 (2019). https://doi.org/10.1016/j.cell.2019.01.007.
[11] M. Levin, Regen. Med. 6, 667 (2011). https://doi.org/10.2217/rme.11.69.
[12] N. Goldenfeld, C. Woese, Annu. Rev. Cond. Mat. Phys. 2, 375 (2011). https://doi.org/10.1146/annurev-conmatphys-062910-140509.
[13] S. Wolfram, A New Kind of Science, Wolfram Media (2002).
[14] A. Adams et al., Sci. Rep. 7, 997 (2017). https://doi.org/10.1038/srep37716.
[15] J. McFadden, J. Al-Khalili, Life on the Edge: The Coming of Age of Quantum Biology, Broadway Books (2014).
[16] G. Vattay et al., J. Phys.: Conf. Ser. 626, 012023 (2015). https://doi.org/10.1088/1742-6596/626/1/012023.
[17] V. Serreli et al., Nature 445, 523 (2007). https://doi.org/10.1038/nature05452,
[18] J. V. Koski et al., Proc. Natl. Acad. Sci. USA 111, 13786 (2014). https://doi.org/10.1073/pnas.1406966111.



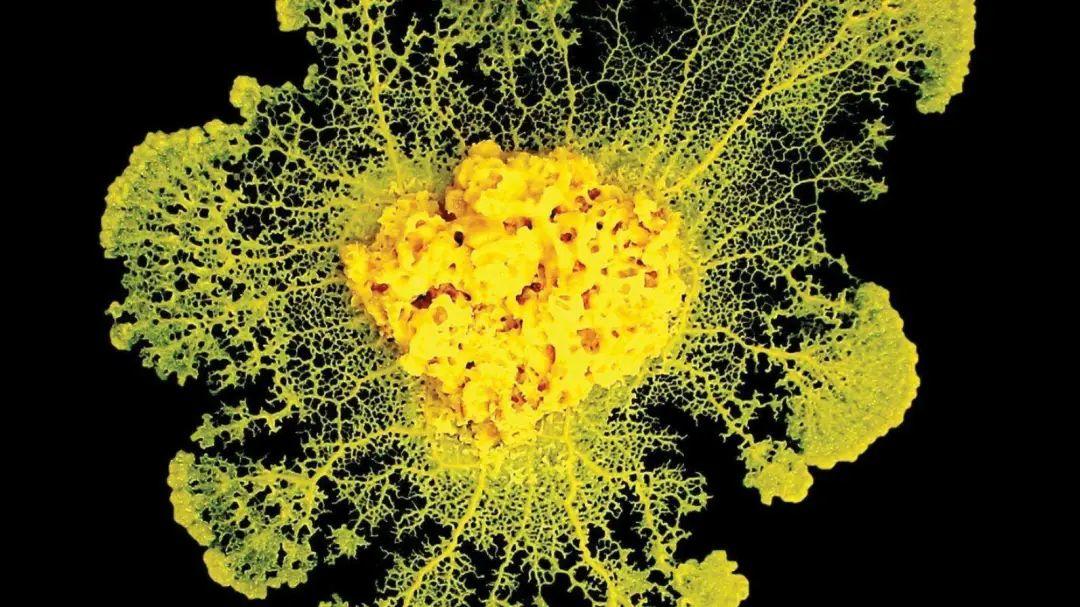 图2:黏菌。有时候,自由的单细胞集合会彼此合作,表现得像是具有共同行动计划的单一生物体 | Audrey Dussutour, CNRS
图2:黏菌。有时候,自由的单细胞集合会彼此合作,表现得像是具有共同行动计划的单一生物体 | Audrey Dussutour, CNRS
















