Nature通讯:基于先验知识的网络推断

论文题目:
A strategy to incorporate prior knowledge into correlation network cutoff selection
论文地址:
https://www.nature.com/articles/s41467-020-18675-3

1.传统方法与先验知识辅助方法
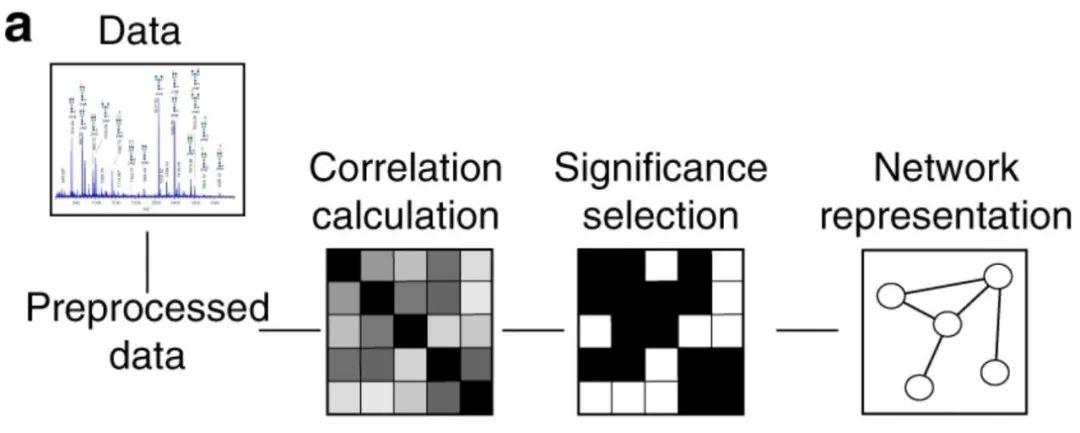
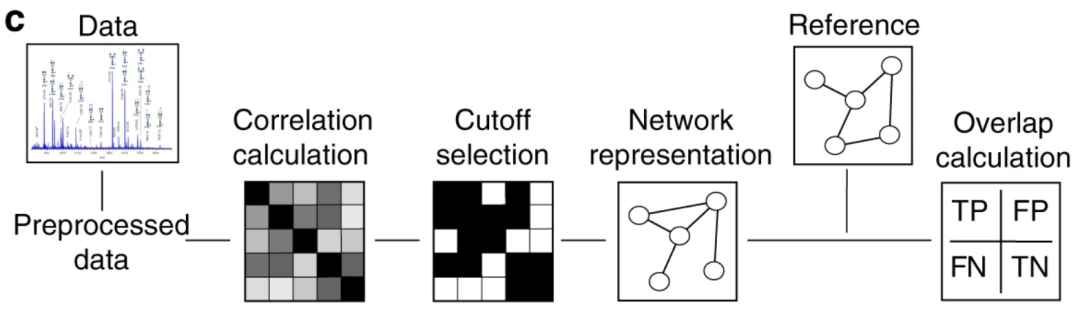
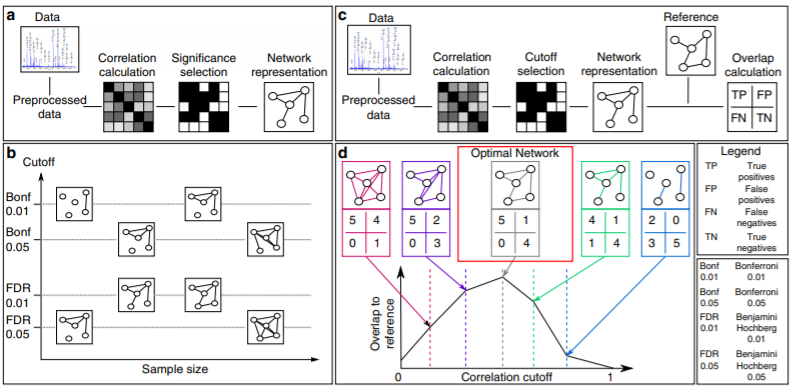
2.在具体网络中验证
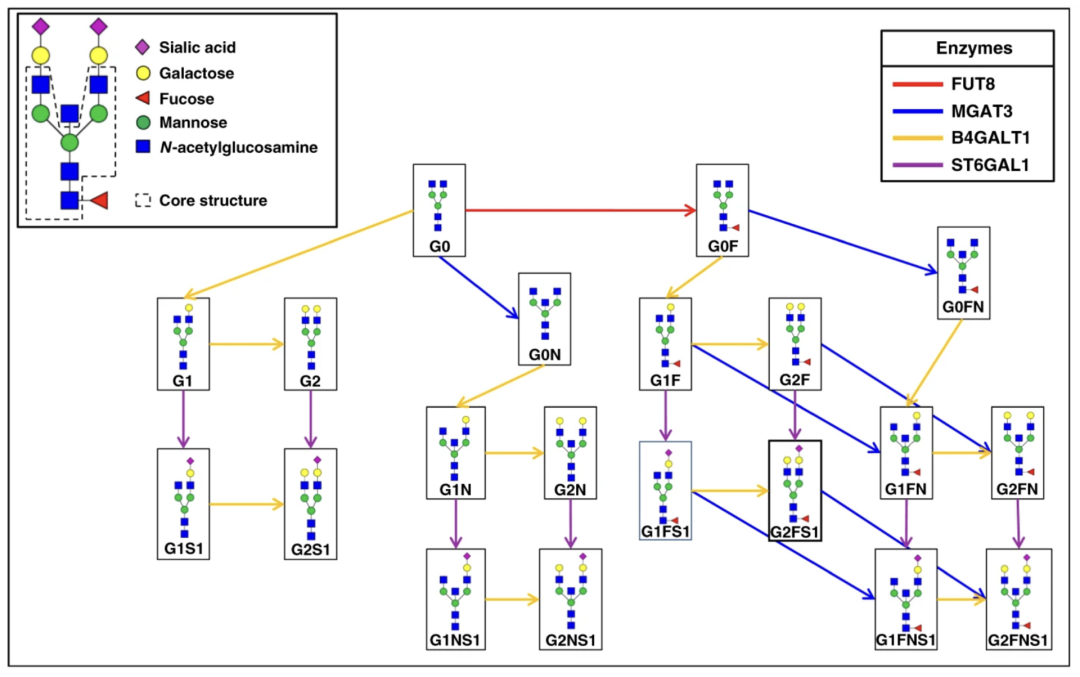
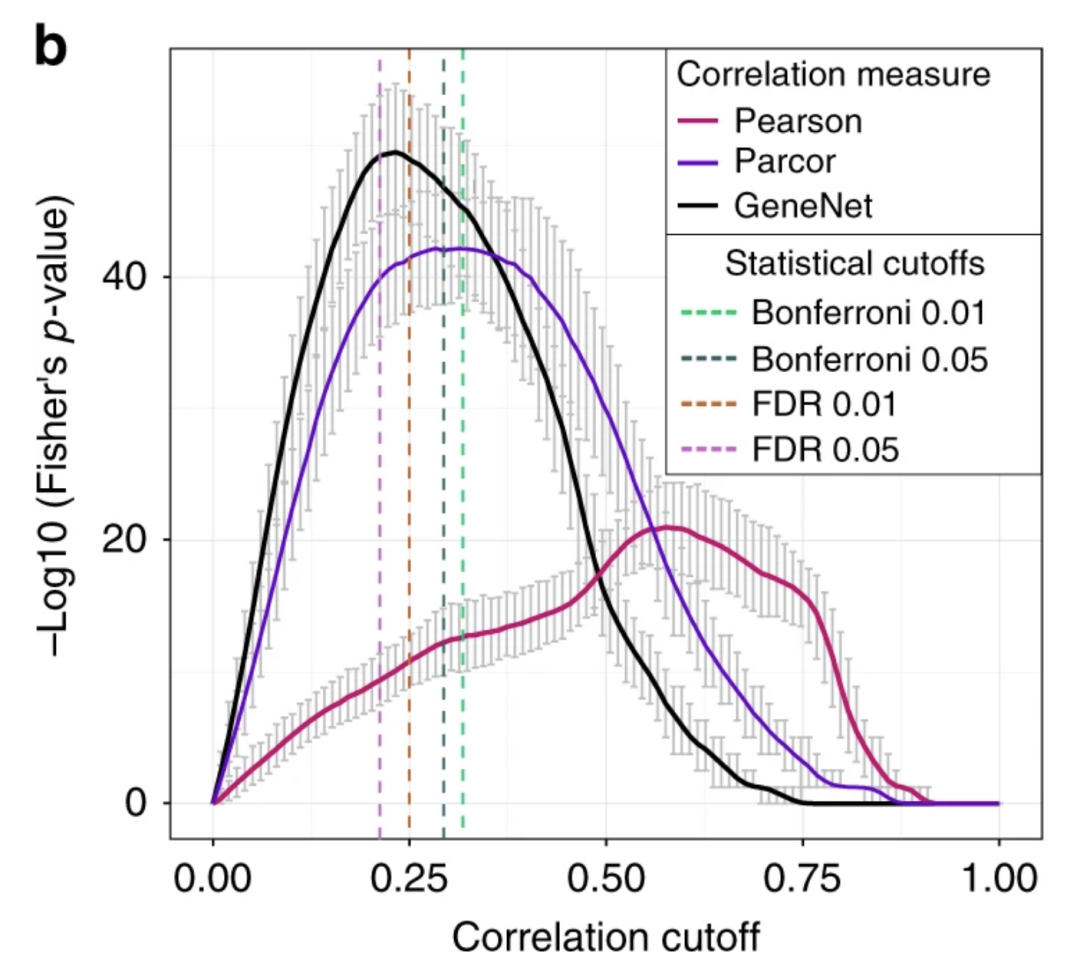
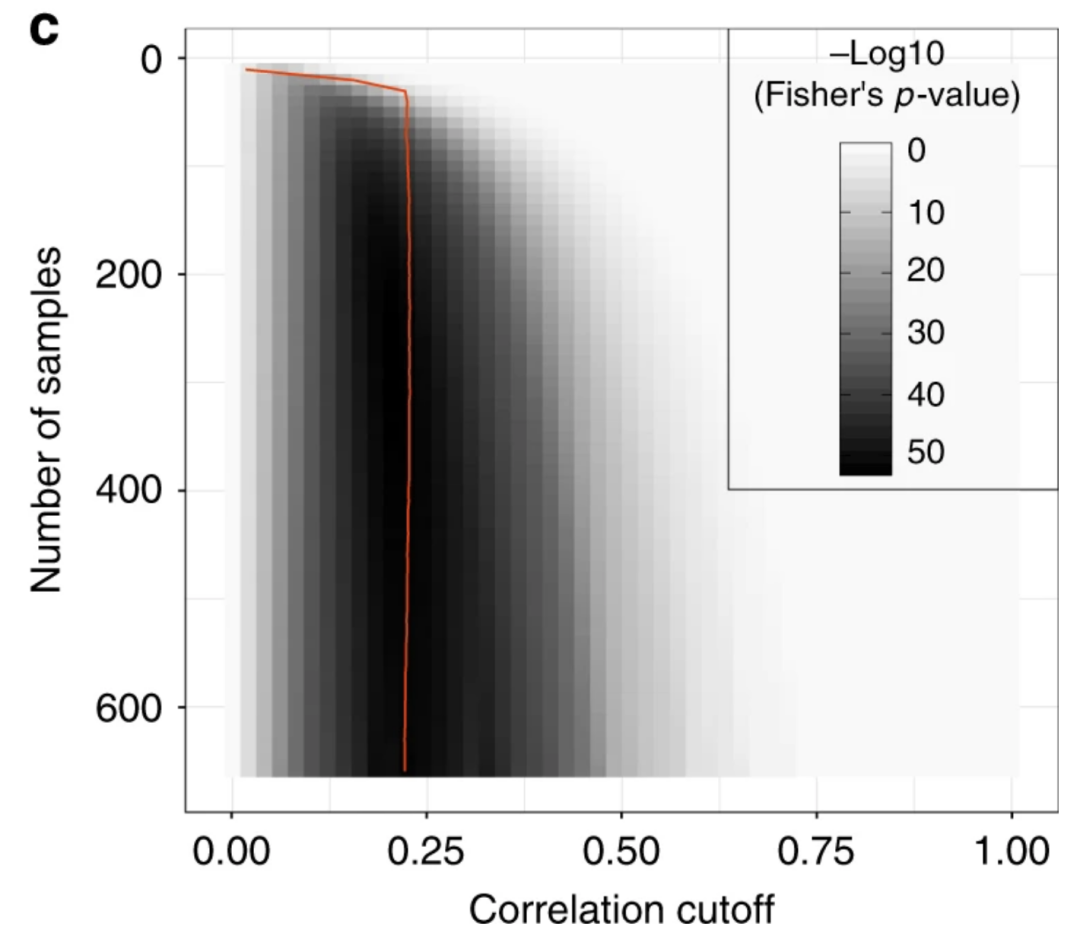
3.先验知识质量不同,
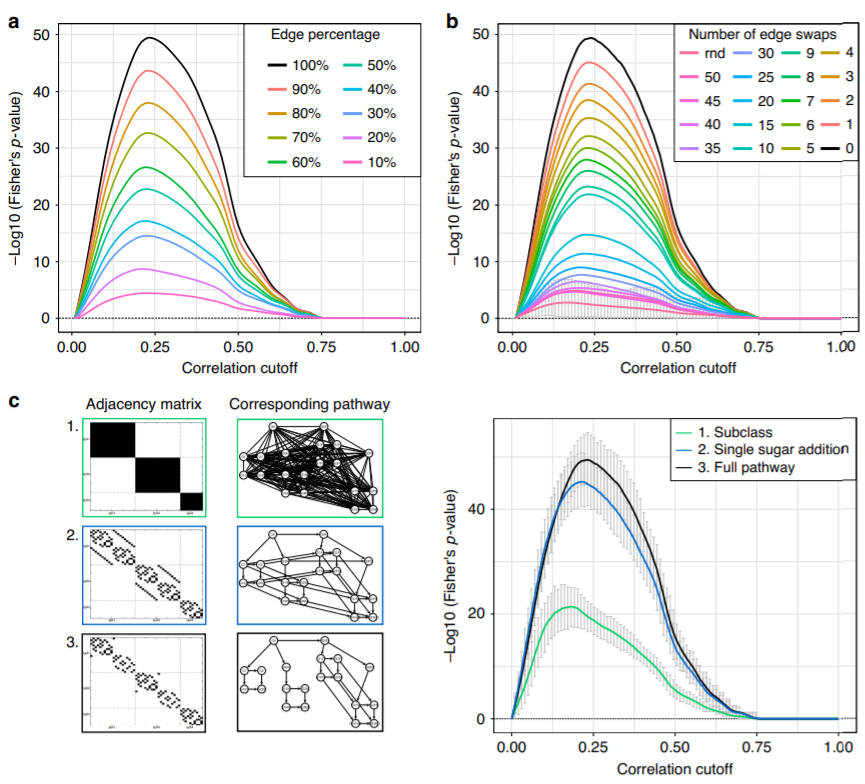
网络推断结果依旧
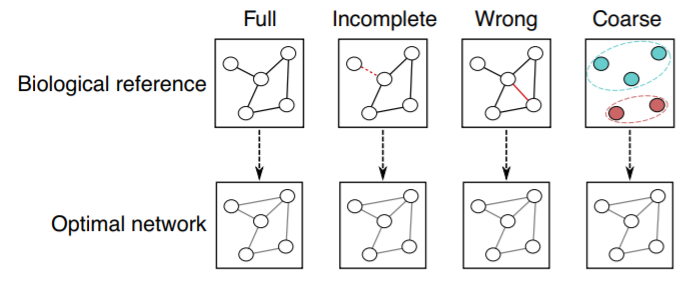
4.前景
作者:刘培源、陈昊 审校:王力飞 编辑:邓一雪
复杂科学最新论文
集智斑图收录来自 Nature、Science 等顶刊及arXiv预印本网站的最新论文,包括复杂系统、网络科学、计算社会科学等研究方向。每天持续更新,扫码即可获取:


推荐阅读

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”

让苹果砸得更猛烈些吧!
👇点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











