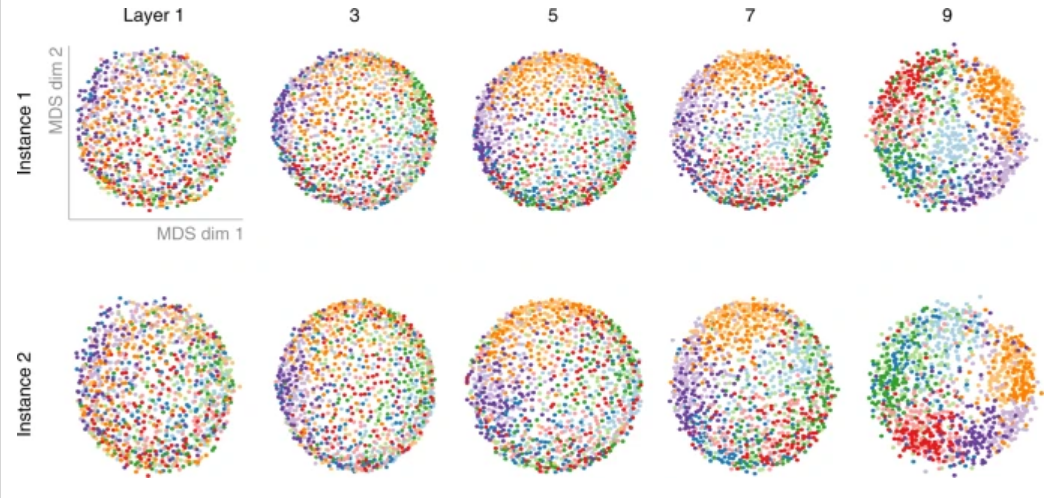深度学习的成功,正在反哺神经科学。例如现在如果想研究哺乳动物的大脑是如何区别猫和狗的,可以去考察判别猫和狗的神经网络是如何工作的。然而11月12日Nature Communications杂志在线发表的论文指出,由于神经网络的训练初始条件和超参数不同,即使具有相近的判别精度,不同的神经网络也存在显著差异。该研究还指出在比较网络结构差异性时,需要考虑对比多组而不是多个神经网络间的区别。这对计算神经科学尤其是视觉模型研究具有启发意义。
论文题目:
Individual differences among deep neural network models
论文地址:
https://www.nature.com/articles/s41467-020-19632-w
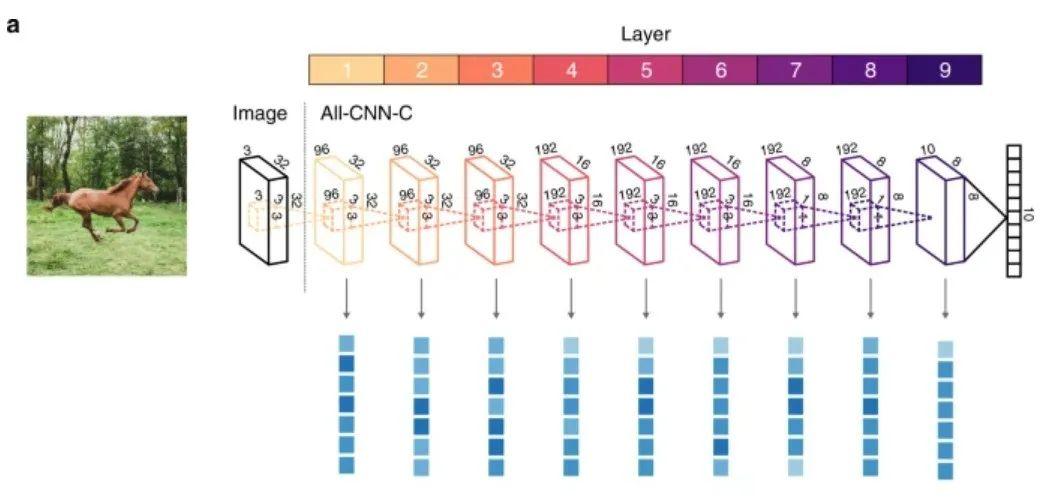
卷积神经网络作为目前最成功AI模型,其灵感来自于模仿大脑的视觉皮层腹侧视觉流(ventral visual stream)。由于视觉处理是分层次的,早期阶段处理诸如边缘、颜色等低级特征。而整个物体和面孔这样的抽象程度更高的特征,只会在下额叶皮层这样的后期处理阶段才会涌现。
借鉴神经科学对大脑的研究,卷积神经网络也采取了类似的结构。上图表示的卷积神经网络分为9层,通过对数据的分层压缩,提取高层特征,最后再利用该特征分类。
研究大脑的神经科学家,需要了解大脑如何判别不同的物体。例如判别植物和动物,是否使用了相同的神经机制。但直接观测大脑太难。而观测和大脑具有相近结构的人工神经网络就容易多了。神经科学家可以根据人工神经网络在判别动物与识别植物时,有何差异,推断大脑识别动物和植物的脑区的异同。
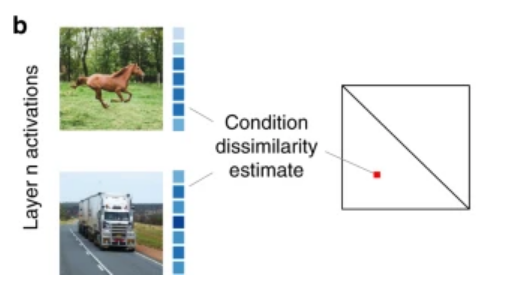
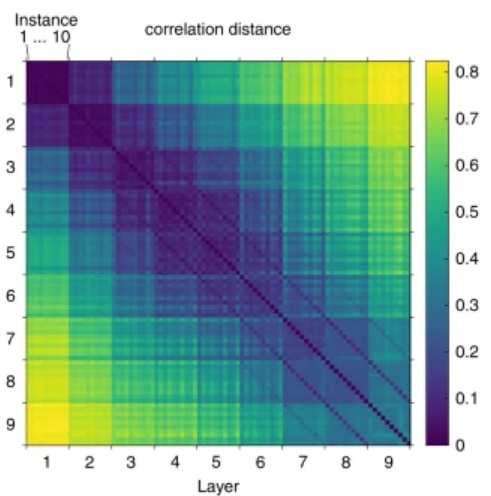
根据人工神经网络中的激活情况(即训练好的网络中的神经元权重向量),可以计算判别马和卡车的神经网络的差异,偏离右图中的斜线越远,两个神经网络的差异越大。这被称为表征差异性矩阵(representational dissimilarity matrices,RDMs)。
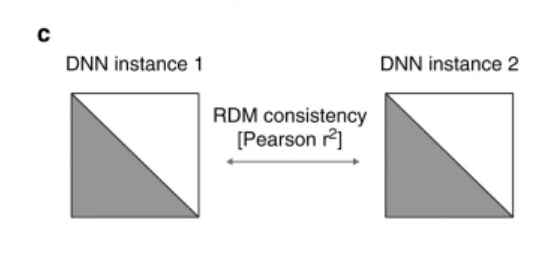
对于两组功能相同的神经网络(例如一组判别马,一组判别卡车),可以通过两两比较功能A和功能B网络的RDMs,之后计算两组网络之间的皮尔森相关系数,来衡量这两种功能对应的神经网络间的差异。
2. 深度的增加
带来了神经网络间表征差异性的异同
不论是判别动物还是植物,最初都是要分别诸如图像的局部直线还是曲线这样的特征,而随着抽象层次更高的特征被抽取出来,判别任务相同的神经网络,会在经由多维标度(multidimensional scaling)分析进行可视化后聚在一起,如图4所示。
图4:每一个点代表一个神经网络,不同的颜色对应不同的判别功能,从左到右,神经网络的深度不断提升
将图中判别每个物体的神经网络看成一类,再将不同层的神经网络间的相关性差异距离用设色热图展示,可以看到最神经网络的第一层,判别不同物体的神经网络并没有什么区别。
而随着网络层数的增加,对角线上的小正方形渐渐变浅,说明判别不同物体的神经网络出现差异,这进一步说明了和待判别对象相关抽象表征会在神经网络的较高层次出现。如图5所示。
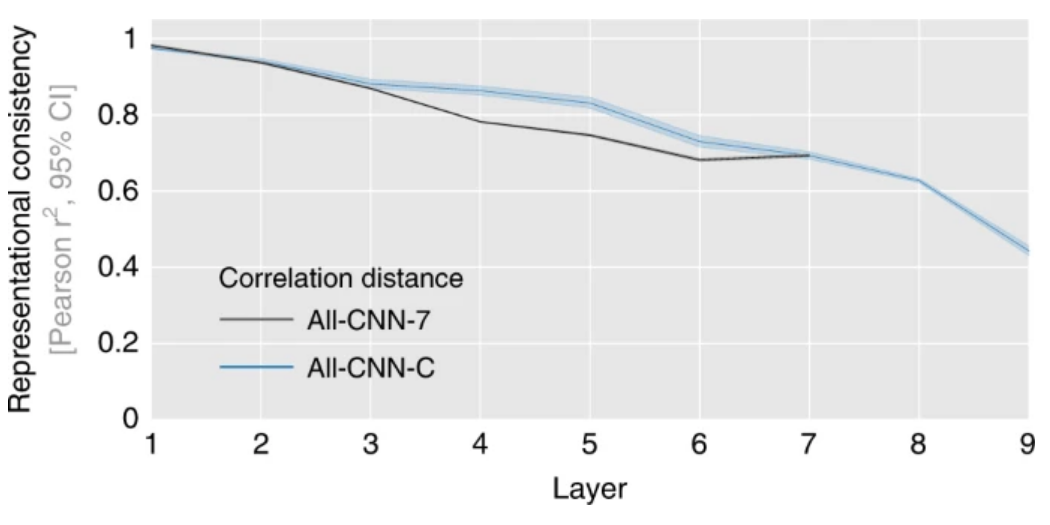
该研究的另一发现是,相同结构、相同判别能力的神经网络,仅仅因为训练过程中的随机性,会导致高层表征的差异。
下图中,对于共享权重差异的神经网络(蓝线)以及7层的类似Alex Net的神经网络(黑线),网络深度的增加,会造成网络间标准差异性的增加。
图6:100种判别神经网络每一层的表征矩阵对应的相关系数的均值
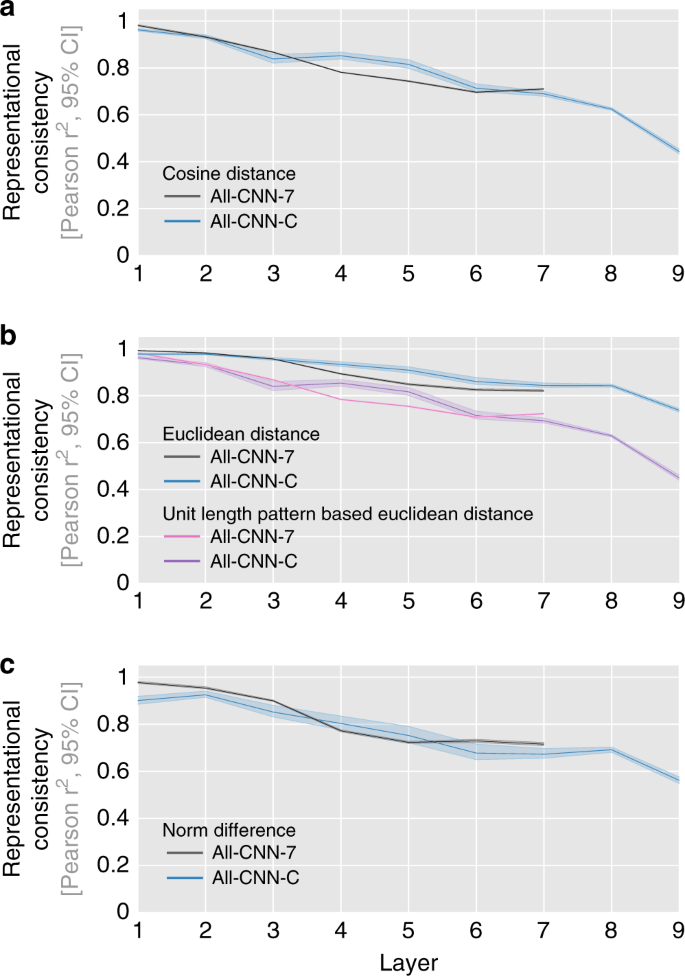
这意味着训练过程中的随机性,会造成具有相同判别能力的神经网络,依据着各自提取的、不尽相同的抽象特征进行判别。而无论使用何种方式计算抽象特征间的相似度,都会得出相近的结果。
如下图所示,当将衡量差异的方式换成cos距离,曼哈顿距离或正则化后的距离时,也会得出相似的结果。
图7:不同的衡量方式下,神经网络每一层的表征矩阵对应的相关系数的均值随层数增加降低
为何会出现上述“完成同一种判别任务的神经网络,具有不同的高层表征”,是本研究接下来讨论的问题。
在人类的学习中,该问题可以类比为,为何老师教会学生一个任务,但不同的学生在最后的步骤中会自发地出现差异。
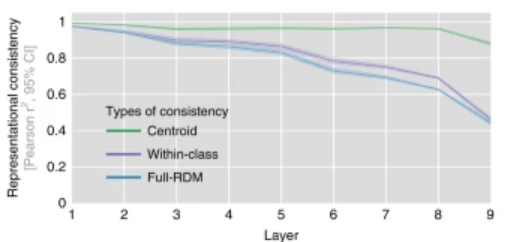
假设有10个判别猫的神经网络,对这些网络的表征向量求质心(centroid),再用这样的质心来计算判别不同物体的神经网络间的相关性,会发现随着网络深度的增加,标准差异性并没有显著增加(下图中绿线)。
图8:不同层的表征向量质心对应的相关性不随网络层数深度增加而增加
这意味着判别不同的任务,所需的特征是类似的,同一任务间的表征差异性来自于训练初始化中引入的随机性。
神经网络在训练过程中,为了避免梯度爆炸,会对权重进行正则化。这会在造成部分人工神经网络中的神经元在实际中等效与被剔除。在深度学习中,为了提高泛化能力,一种常见的方式是dropout,即随机失活部分神经元。
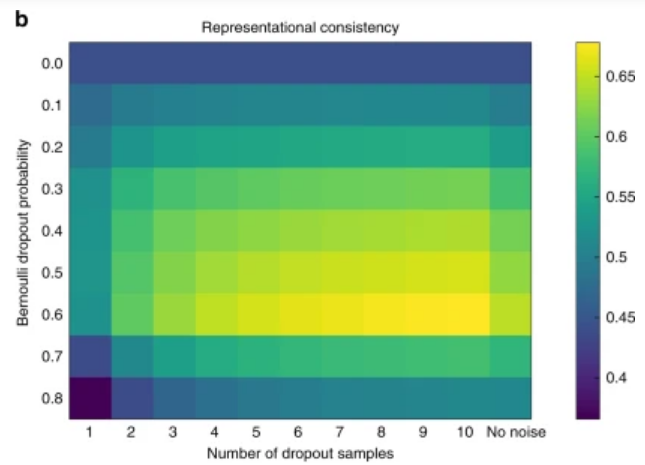
下图展示了训练过程中,随着dropout的神经元的比例(纵轴)增加,神经网络最后一层的表征一致性先增加,后降低。
图9:训练过程中dropout比例不同的神经网络最后一层的表征一致性热图
如图9所示,图中的点越靠近黄色,抽象表征的相似度越高。由于判别不同物体神经网络间的抽象表征相似,使得网络具有了更好的泛化能力,进而解释了为何dropout是一个有效的正则化机制。而当dropout的比例过高时,网络无法提取出对分类任务有意义的特征,因此最终的表征有所差异。
5. 神经网络模型个体差异性
对神经科学和人工智能的启发
该研究通过一系列的实验,说明了由于前馈深度神经网络训练过程中初始权值的随机性,在保持其他所有因素不变的情况下,会造成网络学到的内部表示不同。且个体差异出现随着网络层数深度的增加而显著增加。而涌现出的个体差异,部分可以通过正则化随机导致的部分神经元失活解释。
对于神经科学的研究者,如果忽略了相同功能的神经网络本身的差异性,那么在使用神经网络类比大脑的运行时,得出的结论就会受到随机性的影响。更合适的做法是去研究多个相同功能的神经网络的质心,以此克服随机因素的影响。
而对于人工智能的研究者,该研究可使研究人员能够估计在给定训练参数(例如网络结构多大,不同的网络类型、不同的训练集及待完成的任务目标)时,训练得出的网络,可能具有多少表征差异性,这反映了预期网络可变性。
据此可使研究者能够更好地调整神经网络的超参数和训练过程,以确保从他们那里得出的模型能够具有更强的泛化能力。并更深入地理解不同难度的分类任务上,不同的神经网络为何会出现性能差异。
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!
👇点击“阅读原文”,追踪复杂科学顶刊论文