打破谷歌量子霸权!经典计算机扳回一城

导语
在3月4日的arXiv论文上,中科院张潘研究团队利用经典器件就实现了对谷歌量子优越性的超越。至此,潘建伟、陆朝阳团队的九章是目前唯一实现量子优越性的机器。
论文通讯作者张潘是中科院理论物理所研究员,集智科学家社区成员,研究方向为统计物理与机器学习的交叉领域;论文第一作者是潘峰是张潘的博士研究生。 光子盒 | 来源
光子盒 | 来源
论文题目:
Simulating the Sycamore quantum supremacy circuits
论文地址:https://arxiv.org/abs/2103.03074
也许量子霸权或量子优越性并没有我们想象的那样强大。在3月4日的arXiv论文上,两位中国研究人员利用经典器件就实现了对谷歌量子优越性的超越。至此,潘建伟、陆朝阳团队的九章是目前唯一实现量子优越性的机器。 2019年10月,谷歌的论文称他们的Sycamore量子处理器在200秒内完成了一项任务,估计在Summit超级计算机上需要10000年。但IBM后来提供了一篇论文分析,指出使用不同的体系结构,即使用RAM和硬盘空间来存储和操作状态向量,一台高性能的经典计算机可以在2.5天内完成这项工作。 此前,阿里巴巴采用了一种叫张量网络(tensor network)的经典模拟方法已经将谷歌的优势从10000年缩短为20天。现在,来自中国科学院的潘峰和张潘继续采用张量网络方法,虽然计算时间仍需5天,但保真度远高于谷歌的结果。
60个GPU即可实现
中国科学院的张潘及其博士生潘峰使用60个英伟达GPU组成的小型计算集群在5天的时间内完成了谷歌的量子优越性实验。他们从具有53个量子比特和20个周期的Sycamore电路中生成了100万个固定条目的相关位串,线性交叉熵基准保真度(FXEB)为0.739,远高于谷歌的结果。 论文称,基本上有两种方法来模拟量子电路。第一种方法存储和演化全量子态向量ψ,称为薛定谔方法。基于这种方法,Google估计在Summit超级计算机上模拟20个周期的 Sycamore电路需要10000年的运行时间。 第二种方法,不是将所有2n个位串概率存储在内存中,而是基于张量网络计算一个或一小部分位串概率。中国研究团队采用的就是这种方法。 他们提出了一种big-head张量网络方法,来计算量子电路的大量位串概率。
与谷歌的方法相比,他们的方法能够输出任何位串的确切幅度和概率,而且产生的噪声更少。他们还能计算条件概率并相应地进行采样,这对谷歌的量子电路硬件来说是困难的。 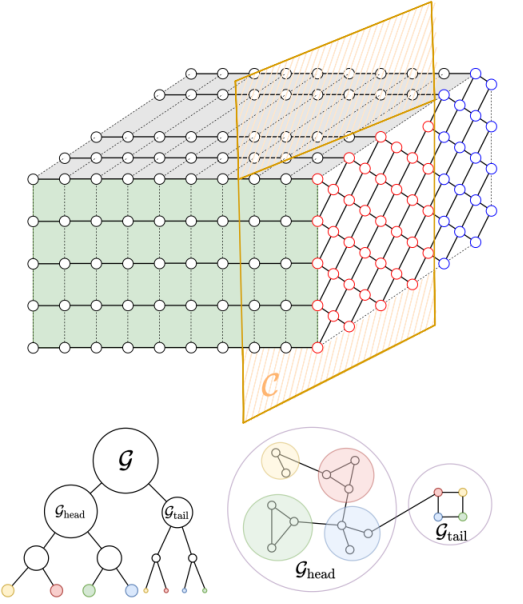 对应于量子电路的准三维张量网络的图示。最左边的一层表示初始状态,最右边的一层表示结束状态,其中蓝色圆圈表示测量的(封闭的)量子比特,它固定了最终位串s中的条目,而红色圆圈表示开放的量子比特,其中s中的相应条目可以变化。黄色平面C切入张量网络,并将网络分成两部分,Ghead和Gtail,如左下角。Ghead包含所有封闭的量子比特Gtail包含所有开放的量子比特。Ghead和Gtail进一步被分为两个子图,直到子图的大小小于60。右下角显示Ghead和Gtail之间的瓶颈(bottleneck),由C给出。
对应于量子电路的准三维张量网络的图示。最左边的一层表示初始状态,最右边的一层表示结束状态,其中蓝色圆圈表示测量的(封闭的)量子比特,它固定了最终位串s中的条目,而红色圆圈表示开放的量子比特,其中s中的相应条目可以变化。黄色平面C切入张量网络,并将网络分成两部分,Ghead和Gtail,如左下角。Ghead包含所有封闭的量子比特Gtail包含所有开放的量子比特。Ghead和Gtail进一步被分为两个子图,直到子图的大小小于60。右下角显示Ghead和Gtail之间的瓶颈(bottleneck),由C给出。
谷歌量子优越性实验的目标是获得大量采样,实现足够高的FXEB用于具有足够深度的Sycamore电路,从而使经典计算难以处理该任务。
现在,中国研究团队已经在XEB保真度方面超越了谷歌。 FXEB计算公式如下: 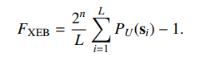
其中,L是位串的数量,PU(si)是电路U中位串的概率,这需要精确计算振幅。 当采样由波特-托马斯分布生成时,FXEB=1。如果从随机均匀分布中对位串进行采样,则FXEB=0。在谷歌的量子优越性实验中,他们实现了FXEB=0.002。 而在最新的工作中,在不失一般性的情况下,他们将32个条目固定为s1=0,0,0,····,0,并列举了位串中其他21个条目的所有可能组合。这就产生了221个相关位串的集合。 由于为所有221个位串分配了相等的权重,所以位串的分布可以被视为均匀分布Pgen(s1;s2) =2−21,给定FXEB应该依赖的其余32个条目s1的赋值。 他们绘制了获得的221个比特串的直方图,其中可以看到获得的分布非常接近波特-托马斯分布。 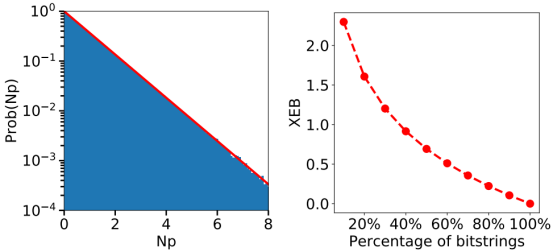 左图中红线代表波特-托马斯分布,所有位串的FXEB=-0.000926;右图为从按概率排序的总共221个位串中后选择的位串集合计算的FXEB。
左图中红线代表波特-托马斯分布,所有位串的FXEB=-0.000926;右图为从按概率排序的总共221个位串中后选择的位串集合计算的FXEB。
通过选择具有最高概率的位串,他们得到FXEB=0.739的106位串(bitstrings),远高于谷歌的结果。  53个量子比特20个周期Sycamore电路不同方法计算量的比较。
53个量子比特20个周期Sycamore电路不同方法计算量的比较。
计算时间上仍未超越
中国研究团队通过在60个GPU上运行张量网络算法,在线性交叉熵基准保真度方面超越了谷歌的实验,使得谷歌的量子优越性已经不复存在。因为量子优越性必须全方位超越经典计算机,而不是仅在某一方面领先。 然而,全量子方法仍然有显著的优势,因为谷歌在200秒内提供了答案,而不是5天。 该论文作者也承认,“我们的实验也反映出谷歌硬件相比我们的几个优势”,“最重要的一点是,谷歌硬件在对具有足够深度的量子电路进行采样方面要快得多,而我们的算法具有指数复杂性,因此在深度和量子比特数量上都不可扩展。” 因此,如果谷歌能够用更多的量子比特或更高的级别重新运行他们的实验,那么GPU实现的成本和运行时间将很快使这种方法变得难以处理。 但最新的实验目的不在于赶超量子计算机。研究人员表示,他们希望研究这种新开发的张量网络模拟方法的使用,将经典计算和NISQ量子计算相结合,以解决具有挑战性的现实世界问题。
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:
推荐阅读
如何把量子计算机调教成终极随机数生成器?
我们的宇宙时空如何起源于量子网络?
尤亦庄:量子纠缠,时空几何与机器学习量子>经典——科学家们找到了量子计算有用性的关键证据!
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











