“集智百科精选”是一个长期专栏,持续为大家推送复杂性科学相关的基本概念和资源信息。作为集智俱乐部的开源科学项目,集智百科希望打造复杂性科学领域最全面的百科全书,欢迎对复杂性科学感兴趣、热爱知识整理和分享的朋友加入!
本文是对集智百科中“遗传算法”词条部分内容的摘录,参考资料及相关词条请参阅百科词条原文。
本词条由集智俱乐部众包生产,难免存在纰漏和问题,欢迎大家留言反馈或者前往对应的百科词条页面进行修改,一经修改,可以获得对应的积分奖励噢!
遗传算法 Genetic Algorithms 的基础是“染色体是一串基因”这一经典观点。R.A. 费舍尔 使用这种观点建立了数理遗传学 Mathematical Genetics ,提供了数学公式来说明特定基因在整个种群中的扩散速率(Fisher,1958)。费舍尔的工作可以总结为以下关键要点:
-
染色体每个位置的一组可以相互替代的基因(等位基因),从而指定了所有可能的基因串(染色体)。
-
一代又一代的进化观,在每个阶段,一群个体生产一组后代个体,构成了下一代。
-
一个适应度函数,计算携带某个染色体的个体能贡献的后代数量。
-
一组遗传算子,特别是Fisher的形式化中的突变算子,可以改变个体的后代,从而使下一代不同于当前一代。
在这种表述中,自然选择 Natural Selection可以被认为是一种搜索方法,用以搜索可能个体集合(即搜索空间),以找到具有更高适应度的个体。即使当自然种群仅由一个物种组成时(例如,当前这一代人类),该种群中也存在相当大的差异。这些变体就构成搜索空间的所有样本。
遗传算法是Fisher公式的一种泛化后的计算机程序版本(Holland J, 1995),泛化的要点包括:
-
关注染色体上基因的交互,而非假设等位基因相互独立起作用,以及
-
一套更广泛的遗传算子,包括了交叉 crossing-over(重组 recombination)和倒位 inversion等著名的遗传算子。
上述第一种泛化使得适应度函数变成了一个复杂的非线性函数,不能再简单地用各个基因效应的加和来近似。第二种泛化则强调了像交叉这种作用于染色体的常见遗传算子。交叉操作在每一次染色体配对中都会出现,而变异操作则在每一百万个个体中才可能出现一次。交叉是哺乳动物能产生混合了亲代特征的子代的核心原因。人类群体就是最生动的例证。交叉还使得使用人工杂交育种来创造出具有优良特征的变种动植物成为可能。很显然,交叉的高频出现使得它成为演化中的一个重要角色,以及遗传算法中的一个关键步骤。
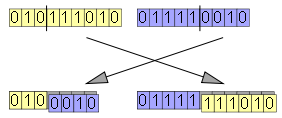
交叉算子的最简单形式(单点交叉)可以被很容易的定义:两条染色体对齐排列好,随机选择染色体上的一点,两条染色体交换从该点起直到末尾的这一段,从而生成了两个后代染色体。
这种简单版本的交叉操作能很好地近似在实际的配对中出现的交叉现象。在单点交叉的作用下,同一条染色体中,相距较近的等位基因可能会被分配到同一个后代中,而相距较远的等位基因则更可能被分割开来,分配到不同的后代中。比如,在一条有1001个等位基因的染色体中,只有1/1001的概率使得一堆邻近的等位基因被分隔开,而在染色体头尾两端的基因则总是会被分割开来。在标准的遗传学术语中,这种现象叫做 连锁 linkage。通过观察由等位基因决定的性状在后代中被分割的频率,连锁现象就可以被确定。事实上,假设单点交叉就能让基因测序变得可能,即便我们没有任何关于DNA的知识——在1944年,使用实验方法来确定连锁效应,华盛顿卡内基研究所 Carnegie Institution of Washington 就发表了一大本记录了果蝇基因序列的手册(Lindsley & Grell, 1944)。
基本的遗传算法程序通过下列步骤来根据当代群体产生后代群体(为简单起见,假设每一个个体都只有一个染色体):
-
从有 N 个等位基因串的群体开始(最初可能是随机产生的)
-
随机从当代群体中选择两个个体,有更高适应度的个体更可能被选中
-
使用交叉算子(偶尔用一下变异算子)来产生两个新的个体,这两个新个体会参与组成下一代群体
-
重复步骤(2)和(3)N/2次,产生新一代N个个体。
-
回到步骤(1),根据新一代群体来继续产生后代
当然,可以有很多种修改这些步骤的方法,但这个基本的流程已经展示了遗传算法的基本性质。
交叉算子在后续世代的研究中引入了大量的复杂性:在亲代中极其有效的个体(比如爱因斯坦)在后代中不会出现,因为该个体中地等位基因被分割开来,传到了不同的后代个体中。这就引发了一个重要的问题:如果不是亲代的染色体,那到底是什么在一代又一代中遗传着呢?回答这个问题,需要预测在一代又一代中扩散的等位基因团,还需要对费舍尔的基本理论做进一步的扩展和泛化。模式定理 Schema Theorem 就是这么一个泛化。模式定理把任意一个等位基因团成为“模式”。一个模式使用符号 * 来表示染色体中不属于该模式的位置。例如,如果一个位置中有两个不同的等位基因,分别为1和0,那么位置2为1,位置4为0,位置5为0的基因团就被表示成符号串*1*00**…*。用 N(s,t) 表示在第t代中携带模式s的染色体数目模式定理揭示了携带模式s的染色体在下一代中预期的数目 N(s,t+1)。下面是一个简化后的版本:N(s,t+1)=u(s,t)[1-e]N(s,t)
其中 u(s,t) 指在第 t 代中携带模式 s 的染色体的平均适应度,e指模式e会被变异算子和交叉算子破坏的概率(通常会很小,但如果模式中的等位基因在染色体中分布很广,即模式的长度很大,则 e会很大)。上述公式可以被重写为一个概率值形式 P(s,t),这是在数理遗传学中更加典型的形式:P(s,t)=N(s,t)/N(t) ,其中N(t) 是群体在第 t 代的规模。
模式定理说明了,群体中每一个等位基因团的比例都会提高或降低,其速率由它所能带来的平均适应度决定。特别地,能带来更高适应度的模式,会在群体中快速传播开来。结果就是,交叉算子会使用这些高于平均适应度的模式,尝试各种新的组合。这些模式成为了构建解的组件块 building blocks。尽管遗传算法每一代只处理 N(t) 个符号串,它能有效处理在群体中承载的多得多的模式。比如,一个长度为40的符号串中包含的模式的数量为 2*exp(40)~16,000,因此遗传算法只要处理几十个长度为40的符号串,就能处理成千上万个模式。这是一个及其出色的速度。
遗传算法经常被用于为那些没有标准解法(如梯度上升、相加近似)的问题寻找一个好的解(Mitchell, 2009)。一些已经应用了遗传算法的典型问题包括控制流设计、飞机引擎设计、规划、蛋白质折叠、机器学习、对语言的获取和演化建模、以及对复杂适应系统(例如市场和生态系统)建模等。要使用遗传算法,搜索空间必须被表示成用一个固定符号集生成的一组符号序列,就像生物的染色体只由四种碱基构成一样。这些符号串可以表示任何事物,从生物体,到信号处理规则,到复杂实应系统中的智能体等。遗传算法要初始化一个由这些符号串组成的群体,这可以用随机的方式生成,也可以用一些关于问题的先验知识来生成。然后,遗传算法就会处理这些符号串,后续的世代就会显示出一些模式,这些模式能是个体拥有高于平均值的适应度。当高于平均、优良连接的模式频繁地出现时,遗传算法就会迅速发现并用来优化。
下面是一个用python实现的简单遗传算法示例,要解决的问题是求下面函数在区间[0,127]内的最大值点。下面代码仅作演示目的,没有遵循严格的编程规范,且可能有各种奇奇怪怪的bug,望体谅。
'''
遗传算法最简单的示例实现
本例展示了如何使用遗传算法来求解使得下面函数值在区间[0, 127]上获得最大值的x
f(x) = x^2 - 50*x
按照我们在教科书得学到的方法,我们知道当 x=25 时,f(x) 的值最大
遗传算法有许多变体,我们使用最简单的二进制遗传算法,即把候选解表示为二进制字符
串,在这些二进制表示的“染色体”上做选择、交叉、变异的操作。
:file: GA.py
:author: Ricky Zhu
:email: rickyzhu@foxmail.com
:license: MIT
'''
import random
N_bits = 8 # 我们只求f(x)在区间[0, 127]上的最优解,因此只需要8个比特
def encode(num: int) -> str:
'''
把数字编码成二进制字符串。
注意这里假设num是从零开始数的整数,该函数不能用于对于任意区间、任意精度的编码。
'''
chrom = bin(num)[2:]
chrom = chrom.zfill(N_bits-len(chrom))
return chrom
def decode(gene: str) -> int:
'''
把二进制字符串解码成数字。
注意这里假设数字是从零开始数的整数,该函数不能用于对于任意区间、任意精度的解码。
'''
return int(gene, 2)
def selection(pop: list, fitness) -> (str, str):
'''
从群体中任意选择两个个体。
注意这里先把所有个体按照适应度排序,然后只在表现最好的一半中挑选,
相当于把表现不好的一半个体淘汰掉了。
'''
pop.sort(key=lambda x:fitness(decode(x)))
return random.sample(pop[:len(pop)//2], 2)
def crossover(chrom1: str, chrom2: str) -> (str, str):
'''单点交叉'''
point = random.randint(1, len(chrom1)-1)
return chrom1[:point]+chrom2[point:], chrom2[:point]+chrom1[point:]
def mutation(chrom: str, rate=0.05) -> str:
'''变异操作,染色体上每个碱基都有rate的概率翻转:从0变1,从1变0'''
for i in range(len(chrom)-1):
if random.random() < rate:
if chrom[i] == '0':
chrom = chrom[:i] + '1' + chrom[i+1:]
else:
chrom = chrom[:i] + '0' + chrom[i+1:]
return chrom
def _GA(fitness, pop):
'''遗传算法中的一次迭代的操作,从旧的一代中产生新的一代'''
new_pop = []
for i in range(len(pop)//2):
par1, par2 = selection(pop, fitness)
kid1, kid2 = crossover(par1, par2)
kid1 = mutation(kid1)
kid2 = mutation(kid2)
new_pop.append(kid1)
new_pop.append(kid2)
return new_pop
def GA(fitness, pop, runs=100):
'''遗传算法总流程'''
for i in range(runs):
pop = _GA(fitness, pop)
print('finial population:', [decode(i) for i in pop])
pop.sort(key=lambda x:fitness(decode(x))) # 选出表现最优的个体,作为最终解
return decode(pop[0])
def main():
'''主函数'''
# 定义问题,亦即适应度函数
def fitness_func(x):
return x**2 - 50*x + 100
# 随机初始化
init_pop = [random.randint(0, 127) for i in range(10)]
print('initial population:', init_pop)
# 把数字编码成二进制字符串
encoded_init_pop = [encode(i) for i in init_pop]
solution = GA(fitness_func, encoded_init_pop, 1000)
print('solution:', solution)
if __name__ == '__main__':
main()
# One run in my machine:
# initial population: [92, 122, 54, 111, 122, 126, 20, 43, 106, 49]
# finial population: [25, 25, 25, 25, 27, 25, 25, 17, 25, 25]
# solution: 25
关于遗传算法的更高阶的使用,可以参考使用pythony实现遗传算法这一词条。
作为集智百科项目团队的成员,本文内容由 Ricky 参与贡献。我们也为每位作者和志愿者准备了专属简介和个人集智百科主页,更多信息可以访问其集智百科个人主页。
以上内容都是我们做这项目的起点,作为来自不同学科和领域的志愿者,我们建立起一个有效的百科团队,分配有审校、翻译、编辑、宣传等工作。我们秉持:知识从我而来,问题到我为止的信念,认真负责编撰每一个词条。

在这里从复杂性知识出发与伙伴同行,同时我们希望有更多志愿者加入这个团队,使百科词条内容得到扩充,并为每位志愿者提供相应奖励与资源,建立个人主页与贡献记录,使其能够继续探索复杂世界。
如果你有意参与更加系统精细的分工,扫描二维码填写报名表,我们期待你的加入!
点击“阅读原文”,阅读遗传算法词条原文与参考文献