Bengio团队因果学习论文反思:为何机器学习仍在因果关系中挣扎?

导语
机器学习算法擅长从大量数据中找出精巧的模型,尤其是深度神经网络。它们可以实现实时的转录音频、每秒标记数千张图像和视频帧,或者检查x光和核磁共振扫描中是否有癌症。但却很难像人类一样,自然地推断出上面棒球视频中存在的简单因果关系。
Max Planck智能系统研究所、蒙特利尔学习算法研究所(Mila)和谷歌研究所的研究者们在一篇名为“Towards Causal Representation Learning”的论文中认为,用机器学习模型对因果表示还有很多挑战,但如何构建能够学习因果表示的AI系统,已经有了一些曙光初现的方向。
集智俱乐部联合智源社区,以因果科学和Causal AI为主题举办系列读书会,精读基础教材、研读重要论文,探讨如何借助因果科学构建可解释的人工智能系统。详情见文末。

Ben Dickson | 作者
张雨佳| 译者
数据实战派 | 来源

原文标题:
Why machine learning struggles with causality
原文地址:
https://bdtechtalks.com/2021/03/15/machine-learning-causality/
当你看下面这面这张图片时,可以很简单地推断出不同元素之间的因果关系。例如,你看到球棒和棒球运动员手臂的同步移动,可以自然地想到是运动员的手臂导致了球棒的运动,以及球棒的移动才引起球运动方向的突变。
当然也可以考虑反事实,比如当球飞得更高一点,没有被球棒击中时会发生什么。

这些推论源于人类的直觉。
我们在很小的时候、没有人明确指导的情况下,就通过观察世界学到了这些直觉。但对于在围棋、国际象棋等复杂任务中想要超越人类的机器学习算法来说,对因果关系的预测仍是一个挑战。机器学习算法擅长从大量数据中找出精巧的模型,尤其是深度神经网络。它们可以实现实时的转录音频、每秒标记数千张图像和视频帧,或者检查x光和核磁共振扫描中是否有癌症。但却很难像人类一样,自然地推断出上面棒球视频中存在的简单因果关系。
Max Planck智能系统研究所、蒙特利尔学习算法研究所(Mila)和谷歌研究所的研究者们在一篇名为“Towards Causal Representation Learning”的论文中认为,用机器学习模型对因果表示还有很多挑战,但如何构建能够学习因果表示的AI系统,已经有了一些曙光初现的方向。
独立同分布的数据
独立同分布的数据
首先回答这个关键的问题——为什么机器学习模型不能在自己的领域外或训练数据外起作用?
论文总结道:“动物经常使用的信息,在机器学习的过程中却常常被忽略,比如对世界的干预、地域转移或者时间结构。因为机器学习认为这些因素是无用的,并试图将它们丢掉。据此,目前大多数机器学习都比较成功,归结于对适当收集的独立同分布(independent and identically distributed,i.i.d.)数据进行大量的模式识别。”
这个机器学习中经常使用术语i.i.d.,它假设在问题空间中的随机观测之间不相互依赖,并且发生的概率是恒定的。最简单的例子就是抛硬币或掷骰子,每一次抛或投掷的结果都独立于之前的结果,并且每一种结果的概率保持不变。
当在更复杂的计算机视觉等领域中应用时,机器学习工程师试图通过在非常大的样本集上训练模型,从而将问题转变到i.i.d.领域。假设有足够多的样本去训练,机器学习模型就能够将问题的一般分布规律编码到模型参数中。
但现实情况中,由于无法考虑和控制训练数据中的所有因素,分布往往会发生变化。例如,已经训练了数百万张图像的卷积神经网络,当图像中物体遇到了新的光照条件、从略微不同的角度或新的背景下进行测试时,就很可能会失败。

训练数据集中的物体vs现实世界中的物体(来源:objectnet.dev)
解决上述问题的主要方法,是在更多的样本上训练机器学习模型,但随着环境越来越复杂,通过增加训练样本的方法也很难覆盖整个样本分布。
尤其是在机器人、自动驾驶汽车等人工智能必须与世界进行互动的领域,面对的挑战更加严峻。无法对因果关系进行理解的机器学习模型,就很难做出准确的预测或者处理新问题。这就是为什么自动驾驶汽车在经过数百万英里的训练后,仍然会犯一些奇怪和危险的错误。
“要让机器学习模型在i.i.d.领域之外也起作用,不仅需要学习变量之间的统计关联,还需要学习潜在的因果模型”,论文写道。
因果模型允许人们将以前获得的知识应用到新的领域。例如,当你学会玩《魔兽争霸》这种即时战略游戏后,就可以快速地将知识应用到《星际争霸》和《帝国时代》等其他类似的游戏中。
然而,机器学习算法中的迁移学习只能起到非常简单的作用,比如将图像分类器参数微调以检测新类型的对象。而当机器学习模型应用在电子游戏等更复杂的任务中时,则需要数千年的游戏训练,并且很难对微小的环境变化(更换新地图或对规则的进行微调)做出适当的调整。
“在学习因果模型时,我们应该用较少的样本来训练,让大多数模块化的知识可以在不经过重新训练的情况下使用”。
因果学习
因果学习

为什么i.i.d. 有这些已知的弱点,却仍然是机器学习的主导形式?
你可以通过添加训练数据来提高模型的精度,也可以通过增加算力加速训练过程。实际上,深度学习能取得成功的一个关键原因,就是有更多的可用数据和更强大的处理器。
并且,基于i.i.d.的模型也更容易评估:先选取一个大数据集,将其分成训练集和测试集。然后用训练集调整模型,用测试集上的预测准确度验证模型的性能。之后一直训练直到模型实现预期的准确度。
现在有很多可用的公共数据集,比如ImageNet、CIFAR-10和MNIST。还有针对特定任务的数据集,如诊断covid-19的COVIDx数据集和威斯康星州乳腺癌诊断数据集。因此,对于所有任务来说挑战都是相同的:设计一个可以根据统计规律预测结果的机器学习模型。
但AI研究者也在他们的论文中观察到,准确的预测能力往往不足以为决策提供帮助。
比如在新冠病毒流行期间,许多用统计规律而不是因果关系训练的机器学习系统开始失败,并且随着现实模式的改变,模型的准确性也随之下降。
但当问题的统计分布改变时,因果模型却仍然是稳健的。
例如,当你第一眼看到某个物体时,大脑就会下意识地去除光照因素。这就是为什么你在新的光照条件下,仍然可以认出这个物体的原因。
因果模型还允许我们对从没见过的情况做出反应,并思考反事实。比如我们不用把车开下悬崖,就知道会发生什么。反事实就可以减少机器学习模型所需的训练样本数量。
因果关系在应对对抗性攻击时也很重要,因为一些微小的干扰都会让机器学习系统以意想不到的方式失败。
论文作者写到,“这些攻击显然违反了基于统计的机器学习的i.i.d.假设”,并且无法应对对抗性攻击的弱点证明了,机器学习算法的鲁棒性机制与人类智慧还有很大差距。研究人员还指出,因果关系可能可以防御对抗性攻击。

对抗性攻击的目标是机器学习对i.i.d.的敏感性。在上图中,给熊猫图像上添加一层难以察觉的噪音,卷积神经网络就会错判为长臂猿。
广义上说,因果关系可以增强机器学习的泛化能力。研究人员写到:“事实上,当前大多数为了解决i.i.d.基准问题的实验和大多数在i.i.d.设置中进行泛化的理论结果,都不能解决跨问题泛化这个严峻挑战。”
在机器学习中加入因果关系
在机器学习中加入因果关系
AI研究者们已经整合了一些对于构建因果机器学习模型至关重要的概念和原则。
其中有两个概念:“结构因果模型”和“独立因果机制”,它们表明AI系统不应该只是寻找表面的统计相关性,而是应该能够识别因果变量,并去除它们对环境的影响。
这种机制可以使模型在不同的视角、背景、光线和噪音下都能够正确检测对象。理清这些因果变量将有助于AI系统更加稳健地应对不可预测的变化和干预。因此,因果AI模型就不需要庞大的训练数据集了。
因果机器学习论文的作者写到,“无论是通过外部人类知识还是机器学习过程,只要得到了因果模型就可以得出干预、反事实和潜在结果的影响”。
作者还探讨了如何将这些概念应用于强化学习等机器学习的其他分支,使智能代理可以不依靠大量的探索环境和试错就能发现问题。由于因果结构允许模型在训练刚开始就有根据的做出决定,而不是采用随机和不合理的决策,所以可以使强化学习的训练更加有效。
因此,研究者们为结合机器学习机制和结构因果模型的AI系统提供了新思路:“为了将结构因果建模(SCM)和表示学习相结合,我们应该将SCM嵌入到输入和输出是高维非结构化的大型机器学习模型中,但至少模型中有一部分工作是由神经网络调整过参数的SCM完成的。最终获得的模型可能具有模块化的架构,不同的模块可以单独调整用于不同的新任务。”
这些概念就更接近于人类思维的模块化方法,比如我们知道大脑的不同领域和区域会联系和使用不同的知识和技能。
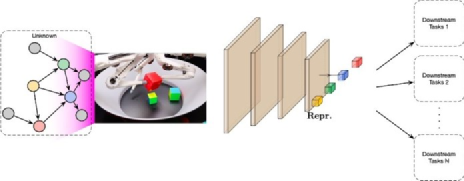
通过将因果图与机器学习相结合,AI代理在少量训练样本的情况下就可以构建应用于不同任务的模块
需要注意的是,本文想法是在概念层面上提出的。而真正要实现这些概念面临着以下挑战:“(a)很多时候,我们需要从现有的底层特征中推断出抽象的因果变量;(b)对于哪种类型的数据揭示了因果关系没有达成共识;(c)通常在训练和测试集上的实验方案,不足以推断和评价现有数据集中的因果关系。我们可能需要获得更多的环境信息和干预措施,建立新的基准;(d)即使在我们擅长的领域中,也经常缺乏可扩展的、数值上合理的算法。”
不过也有许多研究人员从一些现有工作领域中获得了灵感。
这篇论文参考了被称为“贝叶斯网络之父”的图灵奖获得者Judea Pearl的工作,他以因果推理方面的工作而闻名,也曾直言不讳地批评了纯深度学习方法。而且这篇论文的另一位作者Yoshua Bengio也是图灵奖得主,是深度学习的先驱之一。
论文中的一些想法还与Gary Marcus提出的混合AI模型相重叠,它将符号系统的推理能力与神经网络的模式识别能力相结合。但这篇论文并没有直接提到结合后的混合系统。
该论文也符合逻辑分析系统system 2深度学习——Bengio在2019人工智能大会(NeurIPS 2019)上提出的概念。system 2深度学习的理念是构造一种能从数据中学习更高层表示的神经网络框架。而高层表示对于因果关系、推理和迁移学习都非常重要。
虽然还不清楚提出的哪种方法可以解决机器学习的因果关系问题,但只要互相冲突、不同来源的观点汇聚在一起,就会碰撞出有趣的结果。
最后,作者认为:“深入来讲,i.i.d.模式识别只是一种数学抽象,而因果关系对于大多数生命体来说都是必不可少的一部分。到目前为止,机器学习一直忽略了对因果关系的全部整合,但我们认为,整合因果概念很有可能让机器学习受益。”
Reference:
https://arxiv.org/abs/2102.11107
https://bdtechtalks.com/2021/03/15/machine-learning-causality/
因果科学第二季读书会报名中
因果科学第二季读书会报名中
推荐阅读
点击“阅读原文”即可报名
微信扫一扫,分享到朋友圈











