什么是可忽略性Ignorability | 集智百科

本词条由集智俱乐部众包生产,难免存在纰漏和问题,欢迎大家留言反馈或者前往对应的百科词条页面进行修改,一经修改,可以获得对应的积分奖励噢!
目录

在统计学中,可忽略性是实验设计的一种特征,即数据收集方式(以及缺失数据的性质)不依赖于缺失数据。若在给定已观测数据的条件下,表示哪些变量被观测到或缺失的缺失数据指示矩阵与缺失数据独立,则称该数据缺失机制(例如处理分配或抽样调查策略)是“可忽略的”。
这个想法是20世纪70年代早期Donald Rubin和Paul Rosenbaum 合作提出的鲁宾因果推理模型 Rubin Causal Model的一部分。但那时,他们文章中可忽略性的确切定义不同。1978年鲁宾在一篇文章中讨论了可忽略的分配机制 ,其可理解为将个体分配到处理组的方式与数据分析无关,因为已经记录了有关该个体的所有信息。后来,在 1983 年,Rubin 和 Rosenbaum 更确切地定义了“处理分配的强可忽略性”,这是一个更强的假设条件,数学上表示为
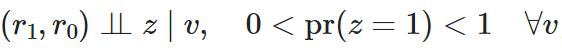
其中rt是给定处理状态 t 下的潜在结果,v是协变量,z是实际的处理状态。
Pearl在2000年设计了一个简单的图形准则,称为“后门 back-door” ,它需要可忽略性并能识别满足后门准则条件的协变量集。
定义
可忽略性(或外生性)的简明含义是,当涉及潜在结果(Y)时,我们可以忽略一个人是怎样最终处于一个群体中而非另一个群体中(“处理组”Tx = 1,或“控制组”Tx = 0)。它也被称为无混淆杂性、基于可观测变量的选择或无遗漏变量偏差。
其数学形式可记为:[Yi1, Yi0] ⊥ Txi ;或者用文字表述为:个体“i”是否接受处理的潜在结果Y并不取决于他们是否真的(可观测到的)接受处理。换句话说,个体最终是通过什么方式处于一种与另一种处理状态我们是可忽略的,并将其潜在结果视为等价可交换的。虽然这看起来很复杂,但如果用下标表示“已实现”的真实处理状态,用上标表示“理想”(潜在)世界的处理状态,就会变得很清楚。(符号的提出可参考David Freedman;可视化帮助文档可参考:potential outcomes simplified)。
所以,如果个体接受处理(上角标为 1),其对应的潜在结果Y为Y11/*Y01,实际上它们可观测的结果是(Y11, 下角标也为 1) ,而不是*Y01。注意:* 表示这个值是无法获取或不可观测的,即完全与事实相反或称为反事实 counterfactual(CF)。
同样,如果个体未接受处理(上角标为 0), 其对应的潜在结果Y为*Y10/Y00。在现实中它们是(Y00),而不是(*Y10)。
对于相同的处理分配条件,每个潜在结果(PO)中只有一个是实际发生可观测的,而另一个不会发生也无法观测,所以当我们尝试估计处理效应时,需要用可观测值(或估计值)来替代无法观测的反事实结果。当可忽略性/外生性成立时,例如个体是否接受处理是随机的,此时可利用已观测的 Y11’替换’*Y01,利用已观测的 Y00’替换’*Y10,不是个人层面的Yi,而是从平均角度出发,如 E[Yi1 – Yi0 ],这正是大家尝试获取的因果处理效应(TE)。
由于“一致性准则 consistency rule”,潜在结果可利用实际观测值表示:Yi0 = Yi00 ;Yi1 = Yi11(“一致性准则指出,个体的潜在结果正是该个体的实际产生结果p. 872)。所以,TE = E[Yi1 – Yi0] = E[Yi11 – Yi00]。
现在,我们通过简单的加减相同的完全反事实量 *Y10 得到:
E[Yi11 – Yi00] = E[Yi11 –*Y10 +*Y10 – Yi00] = E[Yi11 –*Y10] + E[*Y10 – Yi00] = ATT + {选择性偏差},
其中,第一项 ATT = 处理组的平均处理效应,第二项是当个体可选择属于“处理”组或“控制”组而非完全随机分配时引入的偏差。
无论是普通的还是在给定一些变量条件下的可忽略性,都意味着这种选择偏差可以被忽略或消除,因此人们可以得到(或估计)因果效应。
编者推荐
书籍推荐

-
统计因果推理入门 对应英文Causal Inference in Statistics: A Primer
-
Counterfactuals and Causal Inference: Methods and Principles for Social Research
课程推荐
文章总结
-
知乎上RandomWalk总结的关于因果推断之Potential Outcome Framework的内容,其中提到因果退镀and额目标就是从观测数据中估计treatment effect。
-
Mesonychid在自己的个人主页上分享的关于Donald-Rubin潜在结果模型的解释。
-
Yishi Lin在自己的个人主页上分享的关于因果推断的一些介绍因果推断漫谈(一):掀开 “因果推断” 的面纱
https://dango.rocks/blog/2019/01/08/Causal-Inference-Introduction1/
相关路径
-
因果科学与Casual AI读书会必读参考文献列表,这个是根据读书会中解读的论文,做的一个分类和筛选,方便大家梳理整个框架和内容。
https://pattern.swarma.org/path?id=99
-
因果推断方法概述,这个路径对因果在哲学方面的探讨,以及因果在机器学习方面应用的分析。
https://pattern.swarma.org/path?id=9
-
因果科学和 Causal AI入门路径,这条路径解释了因果科学是什么以及它的发展脉络。此路径将分为三个部分进行展开,第一部分是因果科学的基本定义及其哲学基础,第二部分是统计领域中的因果推断,第三个部分是机器学习中的因果(Causal AI)。
https://pattern.swarma.org/path?id=90
百科项目志愿者招募
作为集智百科项目团队的成员,本文内容由shlay用户参与编译,PengWu参与审校,薄荷编辑。我们也为每位作者和志愿者准备了专属简介和个人集智百科主页,更多信息可以访问其集智百科个人主页。




在这里从复杂性知识出发与伙伴同行,同时我们希望有更多志愿者加入这个团队,使百科词条内容得到扩充,并为每位志愿者提供相应奖励与资源,建立个人主页与贡献记录,使其能够继续探索复杂世界。
如果你有意参与更加系统精细的分工,扫描二维码填写报名表,我们期待你的加入!

来源:集智百科
编辑:王建萍
点击“阅读原文”,阅读词条可忽略性原文与参考文献
微信扫一扫,分享到朋友圈











