因果推断:现代统计的思想飞跃

导语
探求事物的原因,是人类永恒的精神活动之一。从古希腊的哲学到中国先秦的诗歌,都充满了对原因的追问和对因果关系的思考。本文将回顾统计因果推断的历史背景,评述中国因果推断研究的现状,并且大胆推测它未来的发展前景。
集智俱乐部联合智源社区,于2021年3月到7月组织了因果科学系列读书会第二季,从基础和实操角度出发,精读两本因果科学教材,研讨因果科学前沿文献。因果科学读书会持续开放报名中,目前已有超过600位国内外学者加入,详情见文末。

1. 引言
1. 引言
2. 哲学基础:因果推断何以成为可能?
2. 哲学基础:因果推断何以成为可能?

图1 亚里士多德《 物理学》的一个英译本。这本书的 Book II 3 的开篇写道:“Knowledge is the object of our inquiry, and men do not think they know a thing till they have grasped the ‘why’ of it (which is to grasp its primary cause)”,翻译成中文就是,我们探索的目标是知识,只有掌握了“为什么”,才算真正理解一个事物,即,掌握该事物的根本原因。
人们常常问关于原因和结果的问题。比如,某人死于肺癌,是不是因为他常常吸烟导致的?比如,我感冒症状减轻了,是不是因为服用了维生素 C 片导致的?比如,大学教育是否能够提高收入水平?类似的问题,充满了我们的日常生活。
大部分西方哲学家都认为因果关系是一条本质的、似乎毋庸置疑的定律。但是,苏格兰哲学家大卫•休谟(David Hume, 1711-1776)曾经抛出了一条惊人的论点。简言之,他认为人类仅仅凭经验,只能认识事物之间恒定的前后相继关系(constant conjunction),并不能认识任何因果关系。很多哲学家都努力回应休谟的质疑,因为若是承认休谟是对的,那么知识何以成为可能?若人类的知识仅仅是经验性的前后相继关系,那么人类似乎没有拥有任何“心智的荣耀”[2]。

3. 统计学中“哥白尼式的革命”:
内曼的“潜在结果”模型
3. 统计学中“哥白尼式的革命”:
内曼的“潜在结果”模型

一个显而易见的估计量是
4. 统计学的拓荒者:
鲁宾关于观察性研究中的因果推断的研究
4. 统计学的拓荒者:
鲁宾关于观察性研究中的因果推断的研究
虽然潜在结果模型成功地数学化了随机化实验中的因果推断,但是它长期并未用于观察性研究——内曼本人是持怀疑态度的,因为缺乏随机化,观察性研究有太多复杂性,比如抽烟的人和不抽烟的人,可能就是两群完全不同的人,不具有可比性。虽然他从未尝试用他的潜在结果模型分析观察性数据,但是他间接地启发了一些更加有冒险精神的学者。其中一人就是鲁宾[6]。

图4 鲁宾教授正在作报告(截屏自https://www.youtube.com/watch?v=N4tQC3elGK4)
-
: 个体 吸烟与否的指示变量; -
: 个体 是否得肺癌的指示变量; -
: 个体 的年龄、性别、教育、收入、家庭病史等等,统计学中称它们为协变量(covariates)。
Rosenbaum 和鲁宾的这篇文章是 Biometrika 这个杂志创刊以来引用率最高的两篇文章之一[7]。在它发表后的三十多年里,引起了很多理论统计学家和应用统计学家的兴趣,他们提出了很多推广的、更加精致的理论和方法,这些理论和方法被用在流行病学、经济学、政治科学等诸多学科的研究中。

图5 费希尔否定吸烟导致肺癌
5. 人工智能的“因果革命”:珀尔对图模型的因果解释
5. 人工智能的“因果革命”:珀尔对图模型的因果解释
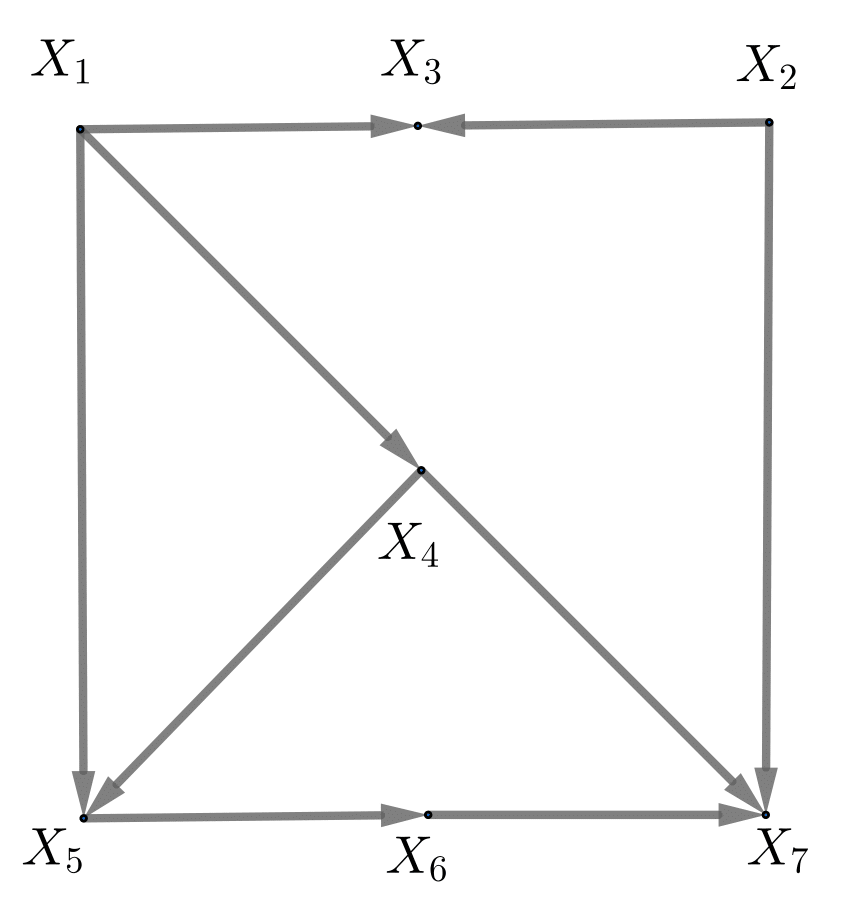
图6 一个 DAG 的例子
5.1 后门准则
5.2 前门准则

图7 珀尔和他的畅销书《为什么》
图片来自:https://momentmag.com/author-interview-judea- pearl/
6. 中国因果推断的研究
6. 中国因果推断的研究
从古希腊开始,西方的哲学家似乎就钟情于因果关系的讨论。这种传统一直流传至今。爱因斯坦曾说,西方科学的发展以两个伟大的成就为基础:一是希腊哲学家发明的形式逻辑体系,二是通过系统的实验寻找因果关系。前者集中体现在欧几里得几何学中,后者肇始于文艺复兴时期,以伽利略为代表。

图8 屈原的《天问》反映了中国古人对自然和历史的好奇心(图片来网络)

图9 学术界的“四世同堂”:耿直(右二)、学生郭建华(左二,东北师范大学副校长),学生的学生朱文圣(右一,东北师范大学数学与统计学院副院长),学生的学生的学生王鹏飞(左一,东北财经大学讲师)
6.1 混杂因素
6.2 替代指标悖论和准则、统计和因果关系的传递性
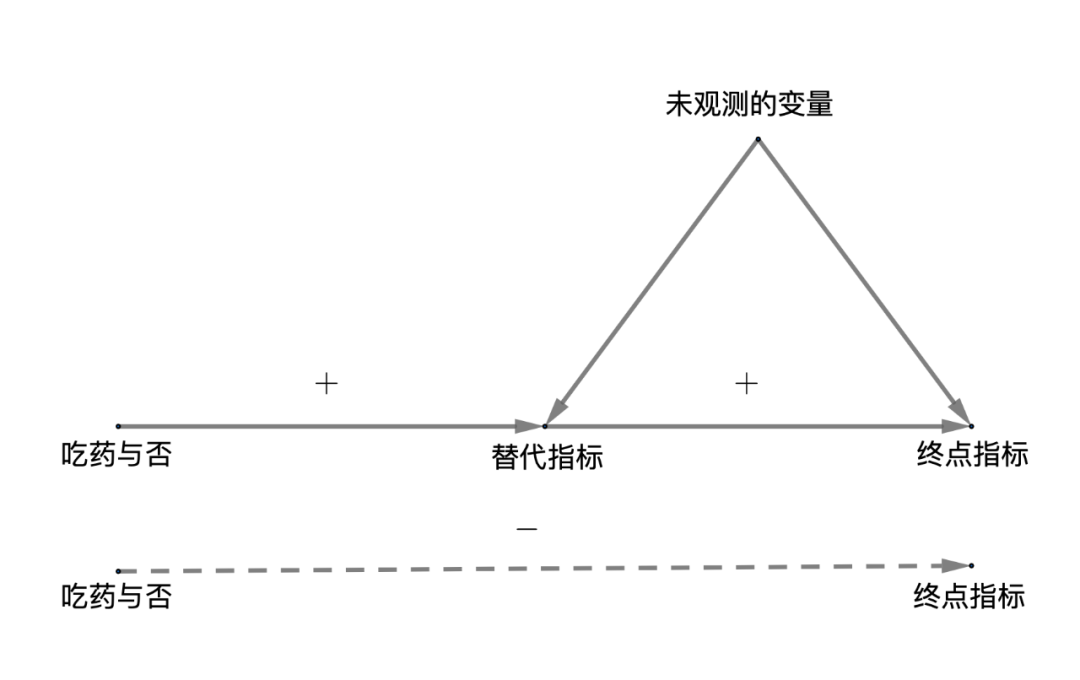
图10替代指标悖论的图模型。此图表示一个随机化实验中,“吃药与否”是随机化的,所以和“未观测的变量”都独立,但是这些“未观测的变量”可能同时影响“替代指标”和“终点指标”。即使“吃药与否”对“终点指标”没有直接的影响,替代指标悖论也会发生:“吃药与否”对“替代指标”有正作用,“替代指标”对“终点指标”有正作用,但是“吃药与否”对“终点指标”的作用却是负的。这个悖论类似于前面提到的 Yule-Simpson 悖论, 它的关键是存在“未观测的变量”同时影响“替代指标”和“终点指标”。如果“吃药与否”对“终点指标”有直接的影响,那情况则更复杂,悖论更加不可以避免。注意,这个图和前面提到的“前门准则”有本质的不同。
6.3 因果图的结构探索
如上面所述,珀尔关于因果作用可识别性的理论依赖一个完整已知的图模型。一个更有挑战性的问题是:如何从数据中学习未知的图模型?耿直提出了分解和局部学习的方法,化繁为简, 有针对性地构建图模型。在数据不能完全确定变量间因果图结构的情况下,他提出了一种实验设计的方法,干预最少的变量,将相关关系的图转变为因果关系的图。这对科学研究中的实验,有指导意义。这一系列文章发表在机器学习领域的顶级期刊 Journal of Machine Learning Research 上[18]。
7. 统计因果推断的未来
7. 统计因果推断的未来
虽然因果推断已经有了一些基础性工作,但是这些工作还不足以回应现实世界向我们发出的挑战。理论上,目前的研究范式还不能完美地应对复杂的实际工作需要。一些学者考虑了因果推断和微分方程的关系,但是这方面的研究还在草创阶段。不管是鲁宾还是珀尔的范式,对于有反馈的因果系统, 都有致命的缺陷,这也是值得思考的问题。另外,现有的工作大多数都是在评估某个给定的原因对某个给定的结果的作用,而科学研究的本质是探索未知的原因。虽然因果图的结构学习对探索原因有帮助,但是这方面的理论还不够丰富。因果推断对整个思想界都有更深刻的意义,它是一种独特的思辨方式,很多层面上是传统的数学和概率论所不具备的。更广地来说,研究因果推断,对于丰富我们的精神世界,大有裨益。
作者简介
丁鹏,2004 年至 2011 年在北京大学数学科学学院获得本科和硕士学位,2015 年获哈佛大学统计学博士学位,2016 年起任教于加州大学伯克利分校统计系,2021 年晋升为副教授。其主要研究方向是因果推断。

注释
(注释可上下滑动查看)
欢迎加入因果科学社区
欢迎加入因果科学社区
目前因果科学读书会(即因果科学社区),已经有超过600位海内外相关科研工作者以及互联网一线从业人员参与,如果你也对这个主题感兴趣,想要深度地参与,就快加入我们吧!

点击“阅读原文”,即可报名读书会
微信扫一扫,分享到朋友圈











