社交媒体让我们的交流更加平等了吗?

导语
社交媒体上大V的影响力大小,信息传播能力强弱,是社交网络影响力研究的重要课题。2021年发表在《自然·人类行为》的一项研究,借助物理学中的渗流相变理论,针对大规模的微博和推特用户数据,建模了社交媒体的信息传播过程。研究发现,社交媒体声音集中程度和正反馈效应,都被大大低估。社交媒体时代的网络发声,将继续失衡,甚至加剧。
研究领域:社交网络,渗流相变,信息传播
集智俱乐部「社会计算」系列读书会,多位专家牵头,从计算科学与复杂科学等跨学科视角,探讨社会、经济等领域的问题,欢迎感兴趣的读者参加,详情请见文末。

李若兰 | 作者
邓一雪 | 编辑
论文题目:
Detecting and modelling real percolation and phase transitions of information on social media
论文地址:
https://www.nature.com/articles/s41562-021-01090-z
1. 被低估的社交媒体信息传播能力
1. 被低估的社交媒体信息传播能力
社交媒体作为一种新的基础媒体,在许多重要领域发挥着显著作用,理解局部个体行为是如何引发全局集体传播行为的,近年来备受关注。人们普遍认为社交媒体上的信息传播是一个类似于理论物理相变过程的渗流过程。然而,由于完整的实证数据的缺乏和大规模数据处理的困难,学术界一直未能在任何社交媒体上观察到渗流相变。从这个假设提出到现在,近20年内未得到证实或证伪。
研究者连续三年观察了中国主流社交媒体微博,分析了由1亿用户形成的网络结构以及至少18万用户的传播行为数据,同时还分析了大量的Twitter数据。终于在真实的社交媒体上第一次观测到渗流相变、临界指数和临界点。

c :98.4%的信息项被均匀渗流模型预测为处于亚临界状态。
研究发现,临界点的值远小于之前理论预测的值,仅仅是理论预测值的1/10,同时实际观测到的爆发开的信息,有98.4%被之前的渗流模型错误地预测为非爆发态。
这表明社交媒体传播信息的能力比以往的理论预测值要高出一到两个数量级,传播过程必然是一种新的渗流。
社交网络网络结构与用户使用社交媒体的上瘾行为的之间正反馈协同演化
网络结构与用户使用社交媒体上瘾行为存在正反馈协同演化,这种协同进化导致用户影响力分布两级分化严重。
本研究的发现表明信息在社交网络中的传播能力高于预期,这可能对很多信息传播问题有影响。
2. 社交网络的庞大数据
2. 社交网络的庞大数据
为了计算社交网络中的渗流相变,需要分析大量的信息传播轨迹,上述信息传播轨迹不仅包括转发用户的好友数据还包括信息接收用户的好友数据。
由于社交媒体网络的小世界性和无标度性,具有大级联规模的信息轨迹包含几个可以拥有数百万追随者(粉丝)的中枢节点(用户)。庞大的数据量和计算难度导致信息级联理论尚未被验证,先前理论预测的渗流相变也没有在任何社交媒体中观察到。为了避免偏差,必须在短时间内收集几乎整个动态网络数据。
数据集
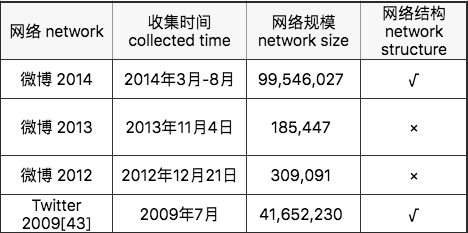
微博数据包含三个数据集:(1)将近1亿用户的全部好友关系网络;(2)185 000个微博用户在近三年内关注、粉丝和推文的演化数据;(3)253条真实爆发信息的轨迹。
Twitter数据集是一个包括约4100万用户和184万用户的演化数据网络。上述数据的获取和使用均获得平台条款的支持。
论文团队使用装箱方法(binning method)量化节点(用户)活动和粉丝增长率。如果一个bin中的用户数量过少(在微博中最少为10),则该bin被排除在分析之外。
3. 信息传播渗流模型
3. 信息传播渗流模型
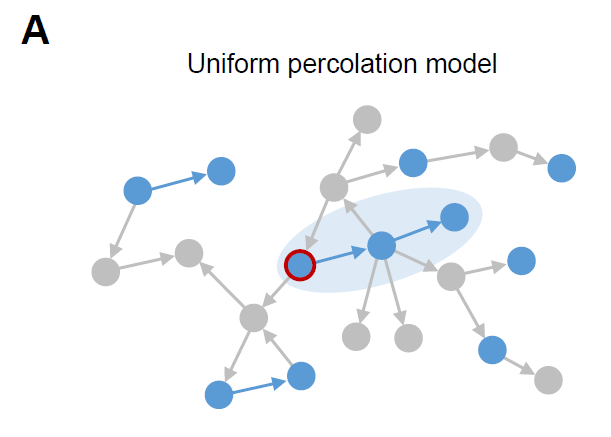
(A)均质渗流模型
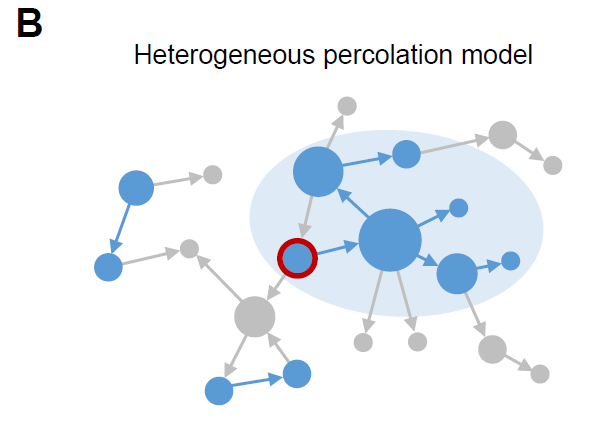
(B)非均质渗流模型
节点被选中的概率与它的出度正相关,出度由节点的大小来表示。在A和B中,蓝色节点对应的是被占用的节点,即人们收到消息会转发,灰色节点对应的是被移除的节点,即不会转发消息的人。在阴影区域内,如果带有红色外框的用户发布消息,则阴影内的用户都会转发该消息。我们可以看到,对于一个占用节点数相同的网络,异质渗流的GOUT更大。
研究者假设对于每条消息而言,假如某些用户对该消息感兴趣,这些用户则会在收到消息后转发(被看作是被占用的节点occupied nodes,蓝色),不感兴趣的节点用户则不会转发(被看作是被移除的节点removed nodes ,灰色)。如果所有节点的转发(占用)概率相同,我们称之为均质渗流模型(图A),否则将被称之为非均质渗流模型(图B)。
在上述两个模型中,全球信息级联中转发用户的集群对应于点渗流模型种的巨型输出组件(gaint out-component)(GOUT) 。
4. 被低估的信息爆发临界点
4. 被低估的信息爆发临界点
研究者利用包含约1亿个用户的微博,4100万用户的Twitter,以及30余万的即时线上活跃用户,定量确定了信息爆发的临界点βc (见表1、2)。
对于在大小为N的社交网络中给定的消息, 我们将该网络中转发该消息的用户的比例定义为𝛽 ,将转发该消息的用户数定义为𝑃∞(𝛽) ,将接受该消息的用户定义为𝑃𝑒(𝛽) 。信息项转发次数越多,𝑃∞ 和𝑃𝑒值越大。假设𝑃∞ 代表所有有意转发的用户,𝑃𝑒 代表所有用户,𝑃∞/𝑃𝑒≈𝛽 。
如图1C所示,研究发现98.4%凭经验观察到的全球爆发信息数据被均匀渗流模型错误地预测局部传播信息。

此外,实际的信息爆发临界值也仅为渗流模型预测值的十分之一(图1D)。这些发现表明前人理论研究中假设的均匀渗流概率𝛽 可能严重低估了社交媒体网络中信息的外延。
实际临界值和先前预测临界值之间的显著差异促使研究者使用定量的方法来地探索信息轨迹和网络结构之间的相互作用。
5. 推文越多,粉丝越多?
粉丝越多,推文越多?
5. 推文越多,粉丝越多?
粉丝越多,推文越多?
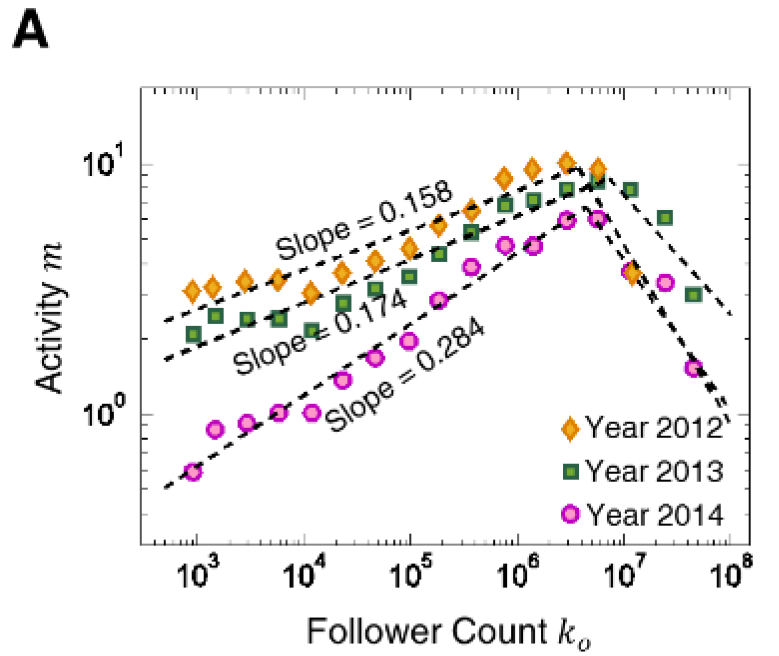

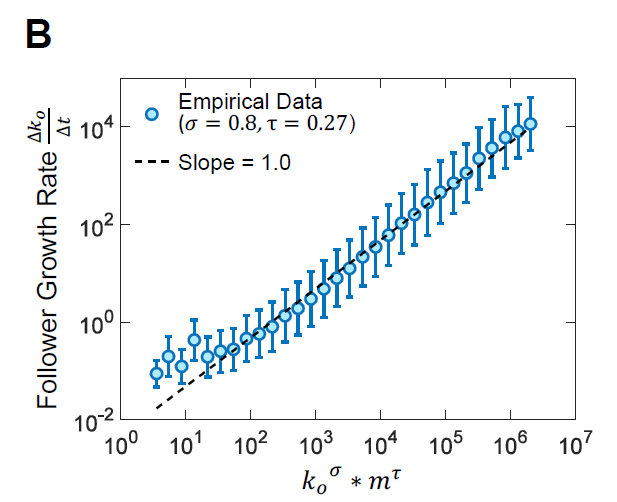
从上两图可以看出,发表推文和粉丝数量成明显正相关,即发表的推文越多,博主的粉丝数越多,但是博主的粉丝并不是一直高速增长的,随着时间的推移,粉丝增长速度趋于平缓(图2A,3A),随着粉丝数量的增多,博主发推的频率也会逐渐降低(图2A,3A)。而m和博主数量之间的相关性可以忽略不计。
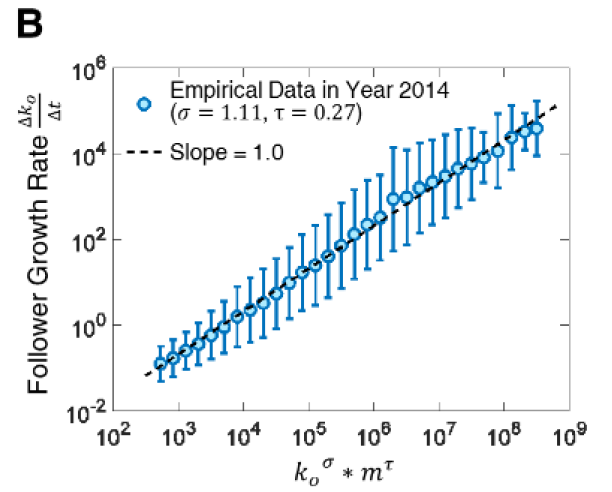
三年的网络演化数据分析结果表明社交网络结构与用户活动存在协同演化正反馈效应(图2B,3B),

正反馈效应使得方程(1)的相关性随着时间的推移而增强。如图2A所示,微博的α值从2012年的0.158(±0.019)增加到2014年的0.284 (±0.017)(表2)。α值的增加造就了更低的信息级联临界值以及社交网络用户网络影响的极度不平衡。
![]()
方程1表示用户活动是异质的,即粉丝越多的博主发布推文的频率越高;方程2表示粉丝的增长率也是可变的,即如果该博主具有更多粉丝或更频繁地发推,则该博主的粉丝数量增加得更快。
6. 社交媒体
可以让我们平等地表达观点吗?
6. 社交媒体
可以让我们平等地表达观点吗?
社交媒体是一个开放的平台,使每个人都能表达自己的观点,但是由于用户触发信息级联的能力可能存在不平等。这种能力代表了社交媒体用户的影响力,会对政治、经济和社会问题的舆论形成产生了深远影响。
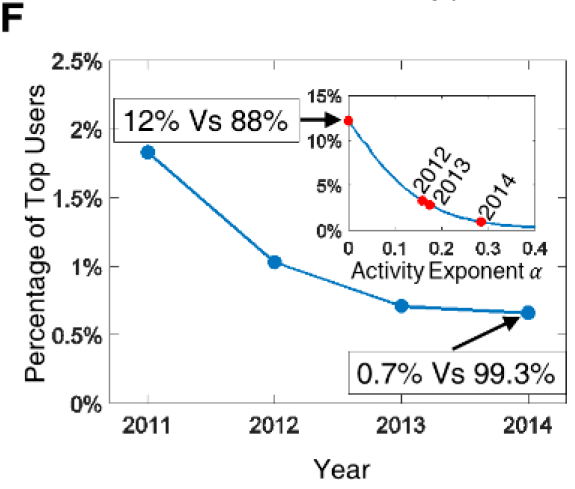
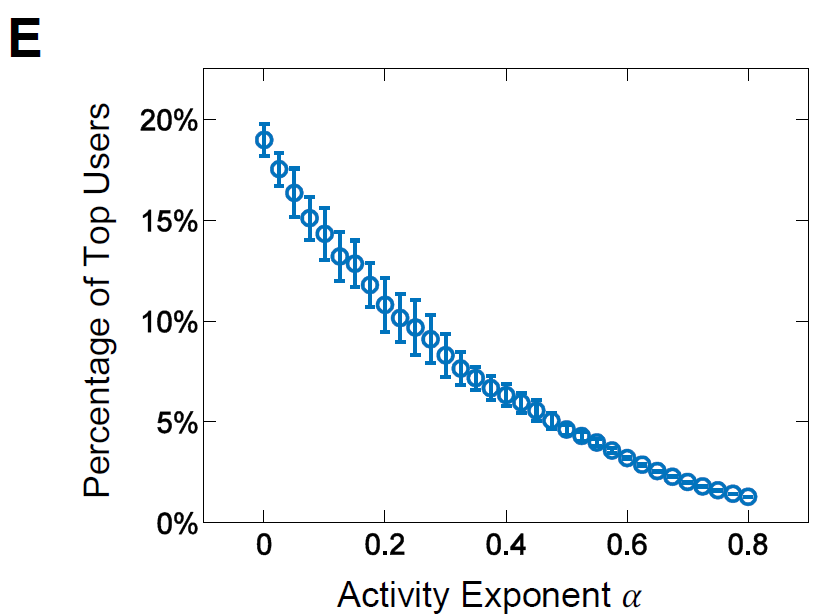
经验和理论分析发现用户影响力随着𝛼随时间增加变得越来越集中(图2F,3E)。事实上,在2014年,前0.7%的用户拥有99.3%的影响力。相比之下,统一理论uniform theory预测前12%的用户拥有88%的影响力。虽然精英用户不可避免地拥有更大的影响力,但现实社会网络中的不平衡比均匀渗透的预测严重17倍。
这一发现意味着,当前旨在让人们自由表达自己的社交媒体,实际上并不像预期的那样分散。很大一部分普通用户的声音仍然受到压制。更糟糕的是,我们的实证和分析结果表明,由于正反馈效应,随着社交媒体系统的发展,用户影响力的不平衡往往变得更加严重。
7. 结语
7. 结语
总结来说,本文通过上述事实经验证明信息传播可以非常有效地通过非均匀渗流模型建模,并且可以在社交媒体网络上检测出相应的二阶相变。此外,网络结构和用户上网上瘾程度之间存在存在协同进化中的正反馈机制,正反馈机制导致某些用户的信息传播能力异常的高,以及不同用户之间影响力的极度失衡。本研究的结果表明有必要重新思考一些与信息级联有关的问题,例如通常在静态网络上分析的影响最大化、社会感染(social contagion)和社交媒体的协议设计(protocol design of social media)等。
该研究模型抓住了决定信息级联动态特性的主要因素,但不同年份和不同数据集上的变化趋势仍存在一定的差异,尤其是网络结构和节点(用户)活动水平随时间变化的相关性趋势。研究发现很难有一个简单的机制来解释这种变化,这可能是由于一些隐藏的因素没有从数据本身观察到。总体而言,这一机制与优先连接机制preferential attachment类似,但更为复杂,值得深入探索。
社会计算系列读书会
随着大数据的持续积累和数字技术的迭代,社会计算(social computing)这一交叉领域正快速兴起,社交网络分析、自然语言处理、机器学习、系统动力学、多主体建模等技术在这一领域碰撞融合,逐渐挖掘出信息时代社会行为的深层规律。
为了推动交叉学科间的合作,促进社会计算的发展和研究,集智俱乐部以「社会计算」为主题组织读书会,已举办12期。由多位专家牵头,研读经典和前沿文献,交流激发科研灵感。读书会由王硕老师发起,专家顾问团包括孟小峰、罗家德、王晓、吕鹏、王静远、李勇等多位老师。本读书会希望将新的研究范式呈现出来并集结起来,通过分享和讨论加强社区的交流碰撞,促进对这个领域的梳理和建设。欢迎对社会计算、社会智能、复杂科学、社会科学等领域感兴趣的朋友报名参加!

详情以及报名方式见:
融合计算科学、社会科学与复杂科学:社会计算系列读书会启动招募
推荐阅读
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











