因果发现最新进展及其在电信网络运营维护的实践探讨

导语
霍克斯过程是一种能描述复杂系统的点过程,广泛应用于社交网络分析、生物信息学、金融分析等多个领域。目前,在霍克斯过程中发现格兰杰因果关系是因果推断的重要研究内容,日益受到关注。本文分析了当前因果推断技术的最新研究进展以及其应用于复杂故障诊断系统的工程实践。
本文创作源于PCIC 2021华为因果推理挑战赛。作者是业界研究员,一直关注因果推断在业界的具体应用及商业价值,也是竞赛的参与者。作者的参赛选题是电信网络运营维护中的警报器因果发现问题。本文是作者及其团队对比赛一些Trick和坑的分享。
PCIC 2021华为因果推理挑战赛由北京大学和华为诺亚方舟实验室共同组织,参赛人数达500多人,相关活动详情见文末。
研究领域:因果科学,霍克斯过程

刘曼霞 | 作者
邓一雪 | 编辑
壁仞科技研究院 | 来源
1. 摘要/背景
1. 摘要/背景
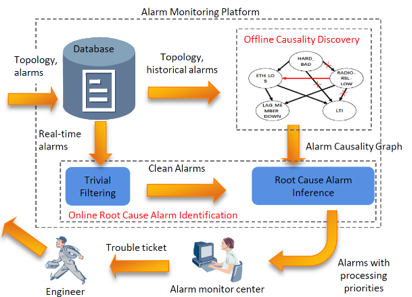
因果发现可用于识别问题的原因,是分析问题和解决问题的一种方法,广泛应用于事故敏感领域,如IT运营、电信、工业流程控制、事故分析、医学诊断、医疗保健行业等,其目的是通过快速定位事故原因,从而提高整体业务等的安全和质量。比如,在电信网络运营维护中,经常通过警报器来识别异常,而网络营运人员每天需要面对上千上万的警报器以及大规模的相互关联的网络结构。网络中单个故障会触发多个相连设备上的警报器。因此,营运人员的主要目标是快速定位故障点并在较短时间内完成故障修复。因果发现通过从历史数据中挖掘警报器之间以及警报器与设备之间的因果关系,能有效地帮助运营人员快速识别故障根源。
在处理时序数据中的因果关系时,检测两个变量之间的因果关系通常采用格兰杰因果关系(Granger causality)。霍克斯进程是一种能描述复杂系统的点过程,在霍克斯进程中发现格兰杰因果关系是因果推断的重要研究内容,日益受到关注。本文分析了当前因果推断技术的最新技术进展以及其用于电信网络运营维护的工程实践。本文首先探讨了霍克斯过程及文[1]在多变量霍克斯过程引入拓扑结构的设计思路和方法,其次,将之与同样用于连续时间因果关系建模的连续贝叶斯模型[2]进行对比,最后探讨了文[1]方法在工程实践上可能遇到的挑战和问题。本文希望借此探讨为在因果发现的工程实践者提供一定的技术借鉴和参考。
2. 霍克斯过程(Hawkes process)
2. 霍克斯过程(Hawkes process)
霍克斯过程是一种强度函数值依赖于历史事件的自激励点过程,其特征是其历史事件的影响以时间累加的形式进行。在霍克斯过程中一个重要的概念就是条件强度函数λ(t|Ht),表示在单位时间内事件到达的平均速率。与一般的点过程不同的是,霍克斯过程的强度函数随着时间而变化,且其历史事件对未来事件的影响是单调指数递减,然后以累加形式进行叠加,其形式化定义如式(1)所示。其中Ht表示截止到时间t的所有历史事件,λ0(t)是给定的确定性函数,Φ是核函数,描述了过去事件对当前事件的影响。也就是说,这是对在时间点t之前的所有事件都进行了考虑。为了描述这些影响随着时间的衰减效应,尤其是最新事件对未来事件影响最大,核函数一般采用类似于指数函数的形式,但将标准的指数函数的一个参数演变为两个参数αμν、δμν,分别表示事件类型ν对事件类型μ的影响程度及衰减率,如式(2)所示。随着时间变化的强度函数λ(t|Ht)的实例如图1所示。
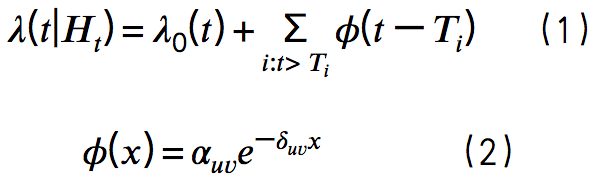
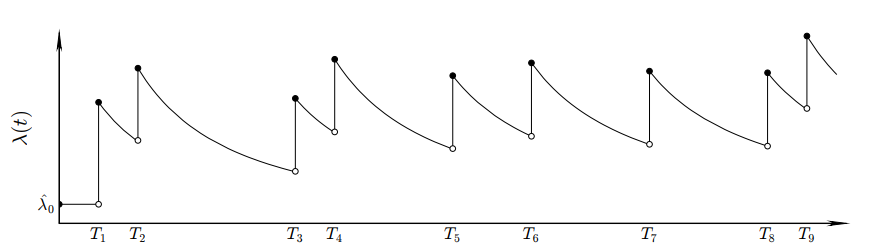
图1:变化的强度函数λ(t|Ht)(来源:文[3])
作为点过程的变体,霍克斯过程也继承了点过程的基本语义。比如,图2中的随机变量τ

图2:点过程 (来源:文[3])
同时,截止到时间事件发生的总次数表示为变量Nt,是一个右连续函数,如式(3)、图3所示。
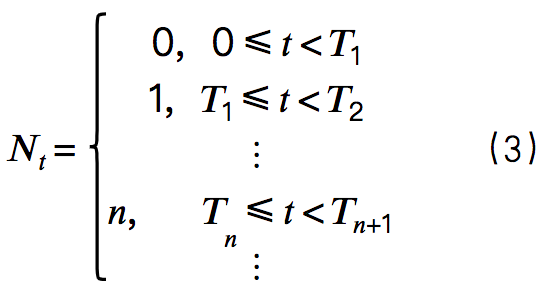
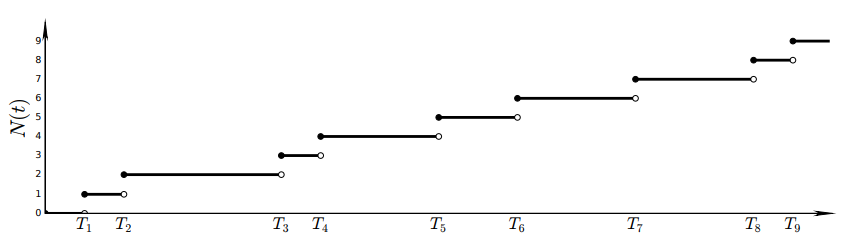
图3:事件次数随机变量Nt(来源:文[3])
3. 拓扑结构的霍克斯过程
(Topological Hawkes Process,TTPM)
3. 拓扑结构的霍克斯过程
(Topological Hawkes Process,TTPM)
标准霍克斯过程表示只有事件之间存在相互影响,事件并不受其他因素影响。这种假设没有考虑事件发生的物理结构,这往往会造成模型训练得到虚假、错误的因果关系。比如,假设现有三种事件类型ν1, ν2, ν3,这些事件发生在三个设备n1, n2, n3,以及设备之间的拓扑结构Gn和事件类型的因果关系图Gν,如图4所示,该结构图表示ν2、ν3同时受设备n1, n2, n3上的事件类型ν1影响。如果我们仅仅将观察数据按照时间序列进行训练而忽略设备之间的拓扑关系,会导致我们训练得到图5中的错误结构,由于忽略了n2设备对时间ν2、ν3的影响,误认为ν2→ν3也是因果关系图中的一部分。换言之,也就忽略了n2设备作为混淆变量的作用。正确的解读方式应该如图6所示。
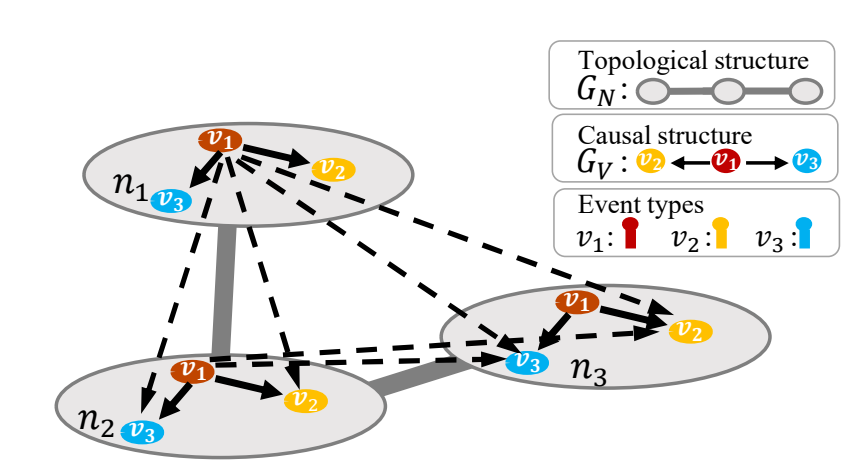
图4:真实的因果图(来源:文[1])

图5:错误的数据解读方式(来源:文[1])
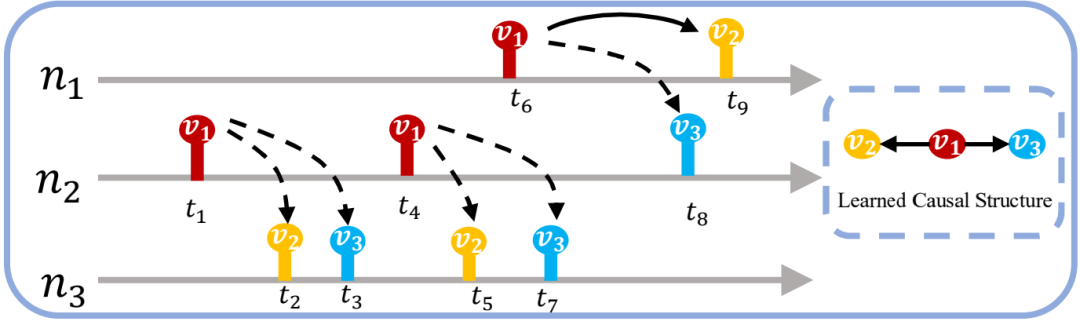
图6:正确的数据解读方式(来源:文[1])
4. TTPM训练方法
4. TTPM训练方法
在文献[1]中,模型训练主要采用了EM(Expectation Maximization)迭代算法来评估最好的模型参数,其主要思想是从没有任何连边的空图和随机参数开始,然后在当前最优图结构上进行一次的边增加、删除、reverse操作,得到当前图的邻居图。然后在这些邻居图中根据模型的似然值 (Likelihood)找到比当前图更优的图,直到找不到为止。具体算法可参见[1]。
值得注意的是,该训练方法中由于使用了EM算法,也无可避免地具备EM迭代优化方法的计算属性。首先,EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值,因此是局部最优算法。这跟算法的初始值有关,因此为确保结果的准确性和稳定性,运行时可以设置多个初始值。当然,当优化目标是凸函数时,可以保证收敛到全局最大值,这与梯度下降的迭代算法相同。由于是迭代优化算法,训练时间与效果往往跟实际经验相关,比如,超参数中迭代次数决定了运行时间,核函数中的衰减系数决定了算法效果,这也说明了工程能力或者说调参能力在算法实践中的巨大作用。此外,该训练方法与事件类型数量成平方阶关系,与EM的迭代次数一起,对计算成本提出了更大的需求。
5. 思考和总结
5. 思考和总结
作为霍克斯过程的演变模型,TTPM只关注事件发生的时间点,而不管事件的持续时间,即事件间隔时间τ由两个事件的起始时间所决定,而每个事件持续时间却是未知。在这方面,现有的连续贝叶斯模型[2]却能很好地捕捉事件的停留时间,这对实际建模可能存在很大的影响。因为现实中,往往数据包含持续时间信息(end_timestamp – start_timestamp),如图7所示的警报器的历史数据。在模型训练过程中,从连续贝叶斯模型的角度来看,只需要从观察数据中获得足够的统计数据,即计算每个事件类型的持续时间和状态转变次数,而不像TTPM需要这样的EM迭代优化算法,其计算速度远远超过TTPM,这对算法设计节省了巨大的计算和时间成本。
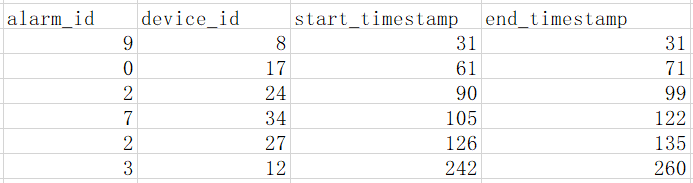
图7:基于观察的警报器数据
同时,在电信网络运营维护中,找出根故障节点可以为排除其他故障提供了解决方向。比如,系统中的两个警报器 A、B,如果警报器B是警报器A导致的,在解除了故障A多久之后故障B会自动解除?对于这样的问题,TTPM就不能很好解决。
当然,TTPM算法的性能严重依赖于BIC(Bayesian information criterion)惩罚因子、核函数中的衰减因子δ等超参数,这对工程实践提出了较高的要求。与之相反,连续贝叶斯模型的性能就比较稳定。在实践工程中,我们也发现,通过对给定时间点进行一定的扰动,在一定程度上能改进连续贝叶斯模型的性能。最后,在数据缺失的情况下,如在图7中,如果alarm_id的起始时间缺失,TTPM只能通过删除该条数据,以便适应算法。当缺失数据在观察数据中占到一定比例时,这种抛弃信息的方法必然对TTPM不利。相反的,连续贝叶斯网络却可以不做任何处理就能适用。
由于水平有限,文中存在不足的地方,请各位读者批评指正,也欢迎大家参与我们的讨论。
参考文献:
[1] Cai, Ruichu / Wu, Siyu / Qiao, Jie / Hao, Zhifeng / Zhang, Keli / Zhang, Xi
THP: Topological Hawkes Processes for Learning Granger Causality on Event Sequences
2021
[2] Nodelman, Uri, Christian R. Shelton, and Daphne Koller. “Continuous time Bayesian networks.” arXiv preprint arXiv:1301.0591 (2012).
[3] Rizoiu, Marian-Andrei, et al. “A tutorial on hawkes processes for events in social media.” arXiv preprint arXiv:1708.06401 (2017).
PCIC 2021泛太平洋因果推理挑战赛
为了更多地推动因果科学学科的发展,聚集国内外因果科学的一线科研工作者,共同讨论因果科学的最新进展,北京大学讲席教授、北京大学公共卫生学院生物统计系系主任、北京大学北京国际数学研究中心生物统计和信息研究事室主任周晓华等发起了PCIC2021泛太平洋因果推断大会,本次会议将集中讨论因果科学在不同领域的最新进展。
会议期间会议组委会,北京大学和华为诺亚方舟实验室共同组织了PCIC 2021华为因果推理挑战赛。竞赛分为两个赛道:
-
赛道1的目标是从连续时间事件型数据中发现因果关系。事件型数据在实际应用中会经常遇到,例如监测电信系统是否正常运行的报警记录。学习报警之间的因果关系可以用来识别根因报警,从而帮助快速定位系统的实际故障。 -
赛道2则关注用户的偏好预测。实际中,每部电影通常都会有一定的描述性标签。参赛者基于关联数据(电影的标签)和因果数据(用户标明他喜欢某部电影的原因标签)建模,并纠偏有偏的推荐数据(用户选择偏置、前序模型偏置等),学习用户的兴趣标签。
竞赛的数据集为经过抽取脱敏的实际数据或者根据实际场景抽象出来的模拟数据。获奖团队获得现金奖励和证书,并邀请在大会上做技术报告。欢迎从事因果推理相关研究的朋友报名参与!
详情请参考:
诺亚方舟实验室简介
诺亚方舟实验室是华为的AI能力研究中心,立足于人工智能基础算法研究,聚焦打造数据高效和能耗高效的AI引擎。实验室广泛分布于世界各地,在香港、深圳、北京、上海、西安、伦敦、巴黎、多伦多、蒙特利尔、埃德蒙顿等均设有研发分部。
诺亚的使命是通过在人工智能、数据挖掘及相关领域的持续创新,为公司和社会做出重大贡献。在创新的每一个阶段,基于长期和重大项目驱动,我们追求在AI相关领域打造最先进技术,助力公司提供更好的产品和服务。
作为一个世界级的实验室,诺亚正在全力推进AI各领域的前端研发,我们勇于面对人工智能和大数据时代的挑战与机遇,秉承“把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界”这一理念,通过全流程智能化,彻底改进人们工作和生活的方式,以及公司开展业务的模式。
诺亚的研究领域主要集中在计算视觉、语音和自然语言处理、推荐系统和搜索引擎、决策推理、AI基础理论五大方向,自2012年创立至今,现已发展成为一个在学术界和工业界都取得了重大成就的研究机构。我们欢迎有才华的研究人员和工程师加入我们,共筑人类在人工智能时代的梦想。
官网链接:www.noahlab.com.hk/
2021泛太平洋因果推断大会
2021泛太平洋因果推断大会是自2019年起由北京大学公共卫生学院生物统计系,北京大学北京国际数学研究中心发起的因果科学领域一年一度的盛会。本次盛会将于9月11日至12日线上举办,面向所有对因果科学感兴趣的相关研究人员,盛会聚集了海内外大批因果科学相关领域的学术大拿,汇聚一堂共同探讨因果科学的最新进展,探索新的科研方向。本次泛太平洋因果推断大会为了满足对因果科学感兴趣的相关研究者,我们采取了提名+邀请嘉宾的方式,吸引力来大批业界大拿的关注,也为因果科学的研究进程提供更加开放平台。





推荐阅读
点击“阅读原文”,了解更多会议信息
微信扫一扫,分享到朋友圈











