PNAS速递:结合群体智慧与机器智能,辨别虚假视频

摘要
研究领域:人工智能,群体智慧,人机协作

郭瑞东 | 作者
张澳 | 审校
邓一雪 | 编辑

论文题目:
Deepfake detection by human crowds, machines, and machine-informed crowds
论文地址:
https://www.pnas.org/content/119/1/e2110013119
1. 数据世界真假难辨
1. 数据世界真假难辨
眼见未必为实,英剧《真相捕捉》中监控影像就被恶意修改。在虚构的影视世界之外,也存在如 Deepfake 等能够生成虚假视频和图片的技术。为了探讨如何更好的应对虚假视频带来的问题。2019-2020年间,亚马逊、脸书和谷歌共同悬赏百万美金,在机器学习平台Kaggle上寻求能够精准辨别虚假视频的机器学习算法。参赛算法的平均准确率约为 65%,其中最佳算法的准确率也未超过80%。
实际上,Deepfake的换脸视频在背景和光照等细节上,难免会和真实视频有所不同。然而一般认为正常人并不擅长捕捉这些细微的差异,因此机器学习模型成为应对此类问题的常见方法。但是人类也有模型所不具备的优势,比如对面部重要特征十分敏感。那么机器学习模型和人到底孰强孰弱呢?如何能将辨别的准确度最大化?
2. 人机大战,孰强孰弱?
2. 人机大战,孰强孰弱?
PNAS最近发表的一项研究解答了上述问题。在两个有大量参与者的在线实验中,研究人员向被试展示了真实视频和虚假视频,并要求他们辨别视频的真假。第一个实验共有882人参与,被试至少辨别了 10 组视频片段。结果表明,82% 的被试准确度高于机器学习模型的平均值。在用于实验的共 56 组视频中,28组被超过83%的被试成功辨别,16组被65%-82%的被试成功辨别,9组被50%-65%的被试成功辨别,仅有3组视频,被试成功辨别的比例小于50%。
第二项实验中共有 9492 人参与,他们需要对所给视频的真实程度打分,总计打分7.4万余次。结果表明,人类被试的表现(蓝色和黄色)均略低于机器学习模型,其中仅有 13%-37% 被试的表现优于模型。然而,将众人给出的真实程度打分平均后,其方差变小,且准确度达到甚至超过了机器学习模型。这说明可通过群体智慧,判别视频真假。
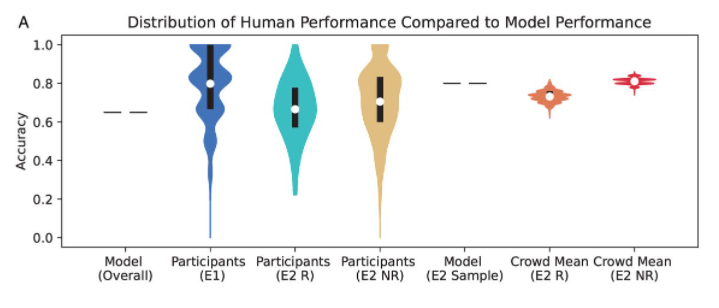
该研究还测试了人机协作辨别虚假视频的准确度。被试可在做出判断后看到模型做出的判断,并据此决定是否改主意。结果表明,人机协作后,被试辨别的准确率从66%提高到了73%。从图2展示的机器学习模型(红线)、群体智慧(蓝线)和人机协作(绿线)辨别虚假视频准确度的ROC曲线中,能够看出人机协作能够最好地辨别虚假视频。
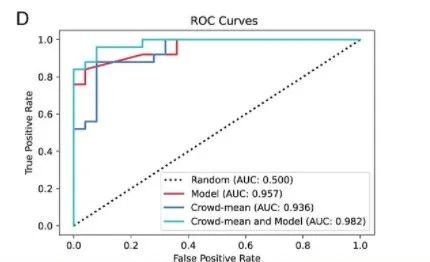
图2.不同方法辨别虚假视频准确度的ROC曲线
人机协作时,若机器的预测是正确的,则被试准确度提升最明显,而若机器的预测不准确或者不确定时,被试准确度反而降低,如图3所示。
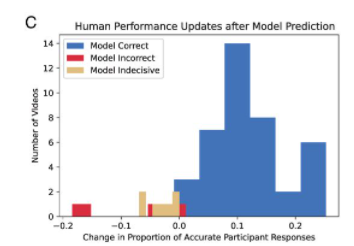
面对机器学习模型给出的错判,人们往往会受其影响。对此,一个预期更有效的人机协作方案是打破机器学习模型的黑箱,让模型在给出结果之外,指明做出判断所依赖的特征。
3. 人机协作,各取所长
3. 人机协作,各取所长
视频是异构的、高维的媒体,人类在某些场景下必然比机器表现更好。例如在辨别政治人物的视频时,人类具备背景知识,自然能达到更高的准确度。而当视频中出现两人而不是一人时,机器学习模型的表现也不如人类。但在另一些场景下,比如视频不够清晰或背景较暗时,机器学习模型的辨别则更准确。此外,人类被试在辨别涉及到愤怒情绪时的虚假视频时,准确度也会降低。
尽管该研究的实验环境及虚假信息的比例与真实媒体环境有所不同,但其初步结论仍具有指导意义。未来辨别数据世界中虚假信息的研究,需要考虑如何结合人类的群体智慧以及机器的智能,各取其所长。
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读
-
Nature 机器智能综述:AI如何自动生成游戏 -
Michael Jordan:人工智能研究的目标变了,不再是构建单个智能 -
PNAS前沿:自适应社交网络促进群体智慧的产生 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











