自上而下or自下而上?混合类脑计算新框架:全都要

导语
机器学习算法流派众多,但不外乎两种基本构架,即自上而下传播全局误差与自下而上基于相关性调整局部神经元间的连接。近日清华大学的研究团队模仿海马体的神经元权重更新机制,在Nature Communications上提出了一种结合全局与局部权重更新规则的混合模型,并验证了该模型在高噪声、小数据量、持续学习三种任务场景下的优越性,为神经形态算法及其硬件实现的协同开发开辟了一条新的路径。
研究领域:类脑计算,计算神经科学

郭瑞东 | 作者
张澳 | 审校
邓一雪 | 编辑

论文题目:
Brain-inspired global-local learning incorporated with neuromorphic computing
论文地址:
https://www.nature.com/articles/s41467-021-27653-2
1. 类脑计算背景介绍
1. 类脑计算背景介绍
《终极算法》一书提到机器学习的五个学派,分别是连接学派、符号学派、进化学派、贝叶斯学派和类推学派。不同学派各有所长,但其终极挑战却是一致的,即设计一个能够统一解决各学派所面向的问题的“终极算法”。
对于类脑计算,即模仿大脑运行机制的机器学习算法,其主要方向聚焦在连接学派和进化学派上。前者将全局的误差逐层向后传播,其典型算法包括反向传播算法及尖峰神经网络(spiking neural network,SNN)。后者则是通过局部神经元间的竞争,增强相关性高的神经元间的连接,常用于特征提取和记忆等相关任务。尽管基于局部相关性的学习方法能耗及延时均较低,但它在常见数据集上的表现不及当前最佳结果。
三因素学习法则和元学习尝试融合两种方向。其中三因素学习法则通过改变神经元的连接因素(包括突触前后的活动以及自上而下调控的神经递质),以全局的预测误差指导局部权重的调整。元学习则通过持续的学习来提升模型的学习能力,其神经学解释是将神经递质视为一种权重共享机制(通过超参数优化的方式)。元学习仅关注如何提高单个全局模型的学习能力,而对局部神经的可塑性予以忽略。
2. 混合模型算法框架
2. 混合模型算法框架
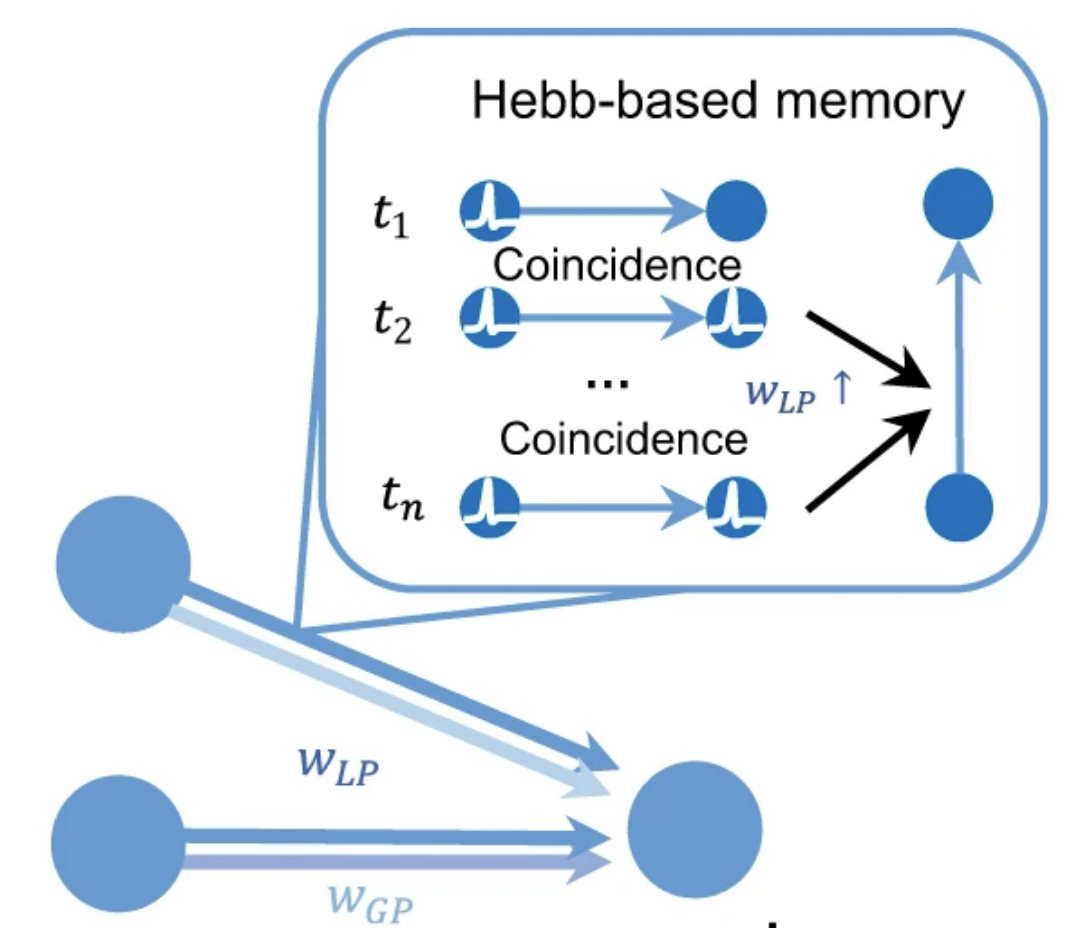
递质可以分为兴奋性神经递质和抑制性神经递质,其中前者促进神经元之间建立连接,后者抑制神经活动、阻止神经元过于兴奋或对无关刺激过度响应。在机器学习中,对各人工神经元间连接权重的训练,可在神经学上解释为改变不同神经元连接间兴奋性和抑制性神经递质的密度,以最小化全局训练误差。
而记忆的形成方式则遵循赫布法则(Hebbian rule),即同一时间出现的神经元,其连接会变得更紧密,从而让大脑中形成专门识别某一特征的神经元。例如,当视觉上总出现线状像素点时,大脑会形成专门识别水平线这一特征的神经元,从而在需要识别数字时提取这些初级特征,不必从头学起。正是这样的局部信息提取能力,使得人脑不会出现困扰机器学习学界的“灾难性遗忘(catastrophic forgetting)”。
近日清华大学研究团队所提出的神经网络框架(图1)将神经元间的连接方式分为两部分,分别为包含下一层神经元权重和全局预测误差的wGP和基于局部神经元活动的wLP。其中θ代表超参数,用于调节神经元之间的连接,st代表记忆,能够将连续信号转为不连续的判断并最终决定该神经元的输出。
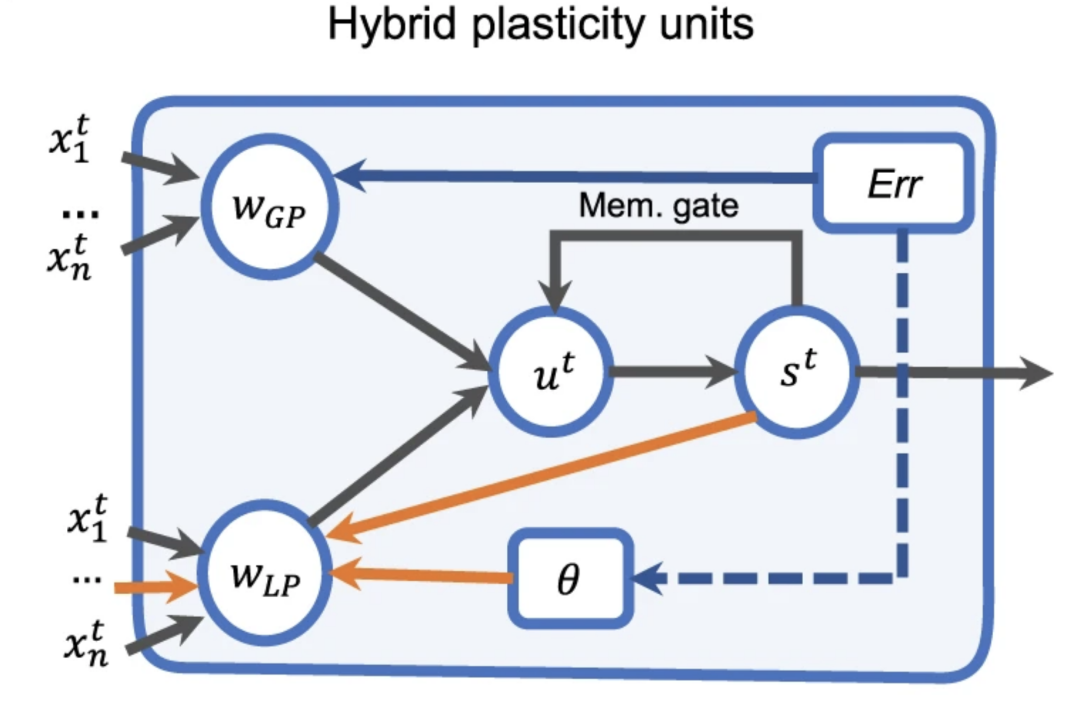
基于上述规则更新的尖峰神经网络,已被用于多种计算任务,并在曾登上 Nature 封面的天机类脑计算芯片上有对应的硬件实现。算法和硬件的协同设计充分发挥了类脑计算的多核并行优势。
3. 混合模型的性能优势
3. 混合模型的性能优势
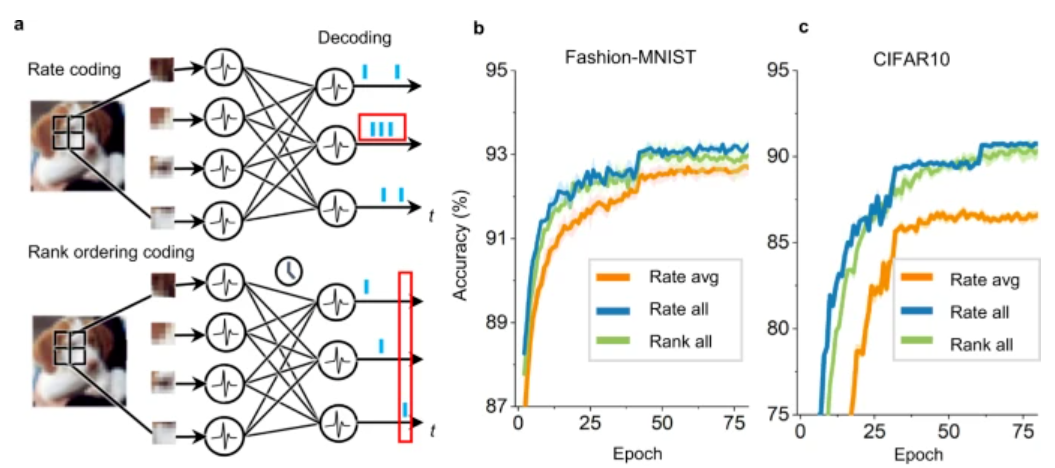
与现有的尖峰神经网络模型相比,混合模型在图像分类的基线任务上准确性更高,且延迟更低。

在跨层级的神经元间采用不同的编码方式,可以平衡计算量与效能。这表明该方案相比传统的机器学习算法,能在相同的架构下保有更高的灵活性。
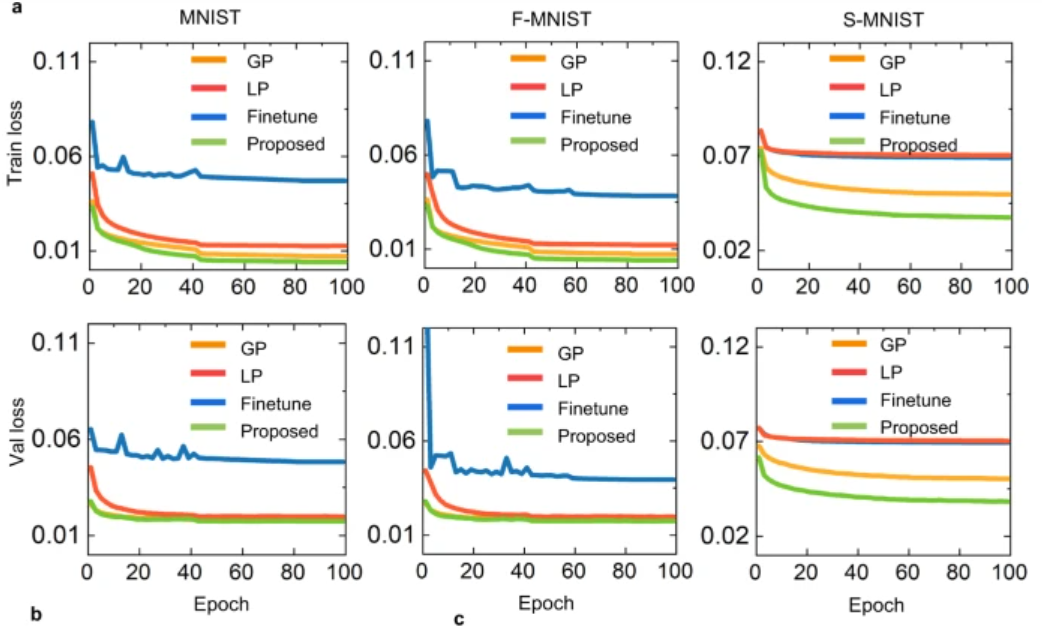
与仅使用局部或全局规则更新权重的尖峰神经网络相比,混合模型的训练效果更好,收敛过程更快也更平滑。
4. 混合模型的容错性
4. 混合模型的容错性
机器学习算法在噪声环境下或图像数据缺失时所呈现的性能,决定了其是否能真正落地。

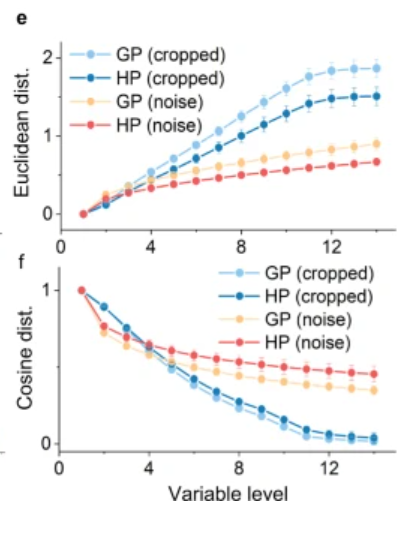
混合模型融合了基于局部信息的权重更新,因此在识别缺失数据的图像上,表现出了良好性能。尤其当数据缺失严重或噪声程度高时,混合模型的表现明显优于全局模型。
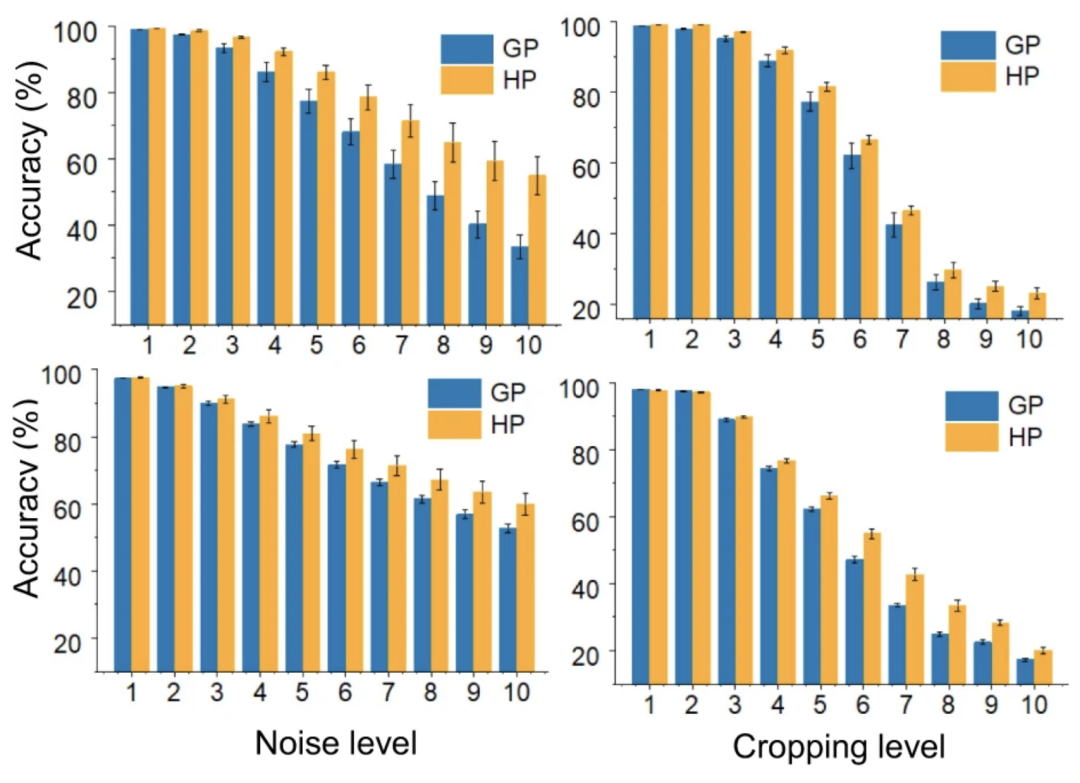
针对此类任务,混合模型相对于全局模型的优越性能,源于局部规则的更新能够提取不随噪声或数据缺失而改变的特征。这使得模型能够利用在先前训练数据中重复出现的模式,并通过权重衰减(weight decay)在相似刺激出现时激活相关模式。
混合模型不仅在噪声环境下表现优越,其神经元间的权重也和识别完整数据的模型中的神经元更相似。
5. 混合模型的小数据学习能力
5. 混合模型的小数据学习能力
对于某一类别的对象,若模型仅依据少量数据即可成功对其分类,那么该模型具有小数据学习能力。而要达成这种能力,模型需要能够充分利用以前学到的知识,而这正是人脑所擅长的。
混合模型对小数据学习能力的解决方案,是以足够抽象的特征作为全局权重更新的输入,从而减少调整权重所需的训练次数,同时通过局部连接建立小数据学习的推断基础。

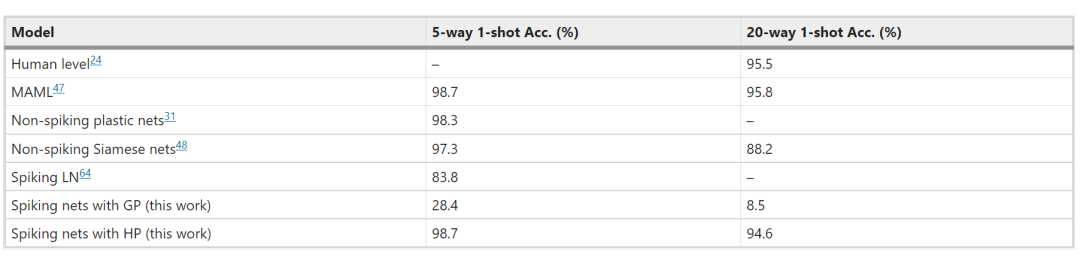
从以上比较可看出混合模型具有小数据学习能力。不仅如此,相比于局部模型,混合模型在并行训练时所需的CPU间通讯和计算量均更少。这不仅意味着混合模型的低碳化,还意味着在并行训练时,其能耗不会随着CPU数目增加而显著提升,使其更适合应用于大规模并行计算。
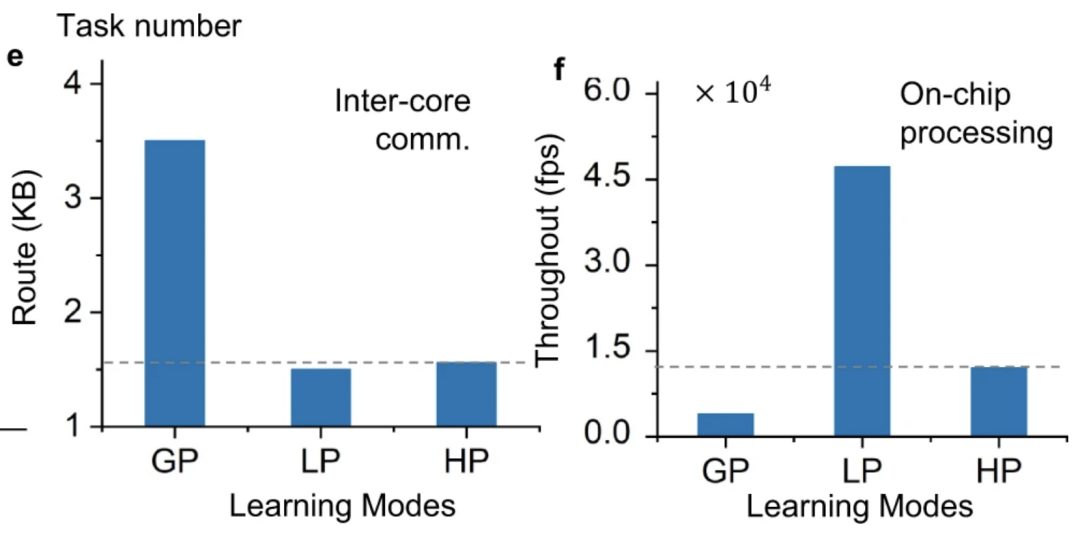 图9. 全局(GP)、局部(LP)及混合模型(HP)的跨核通信带宽(左)及计算量(右)。
图9. 全局(GP)、局部(LP)及混合模型(HP)的跨核通信带宽(左)及计算量(右)。
6. 混合学习的持续学习能力
6. 混合学习的持续学习能力
让模型在学到新分类标签的同时,不影响已学到标签的分类,此类任务被称为持续学习。通过随机打乱标签不同的训练数据所出现的顺序,并比较此时模型准确度的差异,可确定模型持续学习能力的强弱。例如在MINST数据集中,对比常规训练方式得出的模型(训练数据随机排列的训练数据)和逐个出现的训练数据集(先出现1和2,后出现3,依次类推)的模型,两种训练方式得出的模型间准确度差异越小,该模型的持续学习能力越强。
人脑运动皮层的持续学习能力源于稀疏编码,即为新学习的任务单独分配部分神经元连接,从而减少周围神经元受其的影响。受此启发,混合模型在相同局部连接调整的神经元之上,尽可能融合已学任务的全局连接,从而使混合模型具备持续学习能力。

7. 软硬兼施,走向未来
7. 软硬兼施,走向未来
尖峰神经网络作为类脑学习中的基础工具,其性能一直不如主流的深度学习模型。而该研究模仿海马体的神经元权重更新机制,提出了一种在高噪声、小数据量和持续学习三种任务场景下均表现优异的模型。利用算法和硬件协同设计,研究者验证了混合模型的优越性。该框架可用于开发具有低能耗的在线混合学习硬件,也可与现有的几种有效学习算法相结合,从而促成更高效的学习算法,为神经形态学算法和神经形态计算芯片的协同开发开辟了一条新的路径。
大脑中相互连接的神经元能够结合自上而下的调控信息和自下而上的局部信息,以解决各类任务。而如何模仿大脑这一能力,则是神经科学和机器学习领域的一个重要问题。本研究所提出的模型从神经元动力学出发,结合了尖峰神经元的各种动力学行为,以及许多突出的生物学属性,为基于尖峰神经网络的元学习提供了一种通用的方法。
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读
-
类脑计算前沿:基于有机电化学网络的生物信号分类 -
Nature通讯:判别神经网络间的个体差异——计算神经科学新工具 -
Nature 长文综述:类脑智能与脉冲神经网络前沿 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











