Stephen Wolfram专访Judea Pearl:从贝叶斯网络到元胞自动机

导语
2022年人工智能与数学国际研讨会(ISAIM 2022)恰逢著名计算机科学家、贝叶斯网络之父 Judea Pearl 85岁生日,会议期间Mathematica创始人 Stephen Wolfram 对 Pearl 做了一次专访交流。在访谈中 Pearl 介绍了他的个人成长与科研经历,分享了对人工智能、统计学、因果结构的深刻认识。两人还探讨了元胞自动机等复杂系统研究中的因果分析,并讨论了因果方法在个性化医疗、社会智能、自适应实验设计与新冠疫苗等领域的应用。智源×集智因果社区的两位成员对本次访谈的主要内容做了文字整理,供大家参考。

闫和东、徐培 | 编译
邓一雪 | 编辑
1. 背景简介
1. 背景简介
这次讨论会是2022年ISAIM(The International Symposium on Artificial Intelligence and Mathematics)会议期间的一次特别会议,纪念Judea Pearl的85岁生日。
朱迪亚·珀尔(Judea Pearl),生于1936年,以色列裔美国计算机科学家和哲学家,加州大学洛杉矶分校计算机科学教授,“贝叶斯网络”之父,2011图灵奖得主,已出版3本著作,分别为《Heuristics:Intelligent Search Strategies for Computer Problem Solving》(1984年)、《Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference》(1988年)和《Causality: Models, Reasoning and Inference》(2009年),出版科普著作《The Book of Why: The New Science of Cause and Effect》(中文版为《为什么:因果关系的新科学》,2018年)。
史蒂芬·沃尔夫勒姆(Stephen Wolfram),生于1959年,英、美籍,计算机科学家,物理学家,Wolfram Research的创始人兼首席执行官,《A New Kind of Science》(《一种新科学》,2002年)作者,系统地研究了基本元胞自动机的类别,并推动了相关研究,曾任Mathematica和Wolfram | Alpha应答引擎的首席设计师。
2. 概率表和贝叶斯网
2. 概率表和贝叶斯网
首先,Stephen和Judea讨论了关于传统的概率表和贝叶斯网的关系。
Stephen: 首先是迟到的祝福,祝85岁生日快乐。其实,我想要和您聊一下您的生活和职业生涯,但在那之前我们可以先聊一些关于因果图的东西。在我研究基础物理时,人们总是问我我的因果图和您的因果图有什么关系,我并不知道答案,我想答案会很有趣。
Stephen:在这个例子中,警报(Alarm)处的东西是否可以看做一个有两个输入,有两个输出的函数或事件?这个事件输入入室盗窃(Burglary)这个变量的状态,地震(Earthquake)这个变量的状态,然后,计算并产生约翰报告(JohnCalls)和玛丽报告(MaryCalls)这两个节点的输出,这个在警报(Alarm)代表的函数不是一个关于它的输入的决定论型的函数(deterministic function),而是一个根据输入产生特定概率的输出的函数。数学上,这些都是各种东西之间的条件概率,可以用一张完全的概率表来表示。
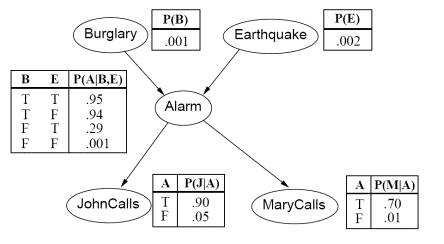
Judea:这个图是在我不知道任何关于因果关系的知识下,依据直觉创建的,被称为贝叶斯网,是纯粹关于数学和概率的东西。椭圆形里的名字表示的是变量或命题。在图中Alarm处的条件概率不是一个决定论型的函数,可能会有一些噪声,这意味着警报可能被一些宇宙中未知的因素触发(当Burglary和Earthquake都是False时)。我们可以从中建立有包含5个二值变量,有1列32行的概率表,这32行的概率加起来是1,这个概率表中不仅仅是有很多项是0,而且有很多约束,例如,Burglary和Earthquake彼此独立在表格中是不明显的。
3. 时间、隐变量和因果图
3. 时间、隐变量和因果图
之后,Stephen和Judea讨论了时间和因果,谁先谁后的问题(更多内容可以参考1956年Reichenbach的《The Direction of Time》)。
Stephen:你在从完全概率表中中精简成这个因果结构时,进行精简所依据的第一源头是不是时间?在现实中,序列的依赖关系的产生,难道不是因为时间上其中一个在另一个之后发生吗?是不是因为时间按照箭头方向进行,所以把Earthquake和Alarm之间的箭头这么画?
Judea:第一源头不是时间,决定哪个变量依赖于哪个变量时,和时间没有关系,时间本身并不在图中。时间是一种约束,但是不能说在时间上原因之后就是结果,时间是影响我们判断因果关系的一种约束,这是我们为什么把Earthquake和Alarm之间的箭头这么画,而不是画成其他形式的原因。但是时间本身不能决定箭头的方向。
Stephen:我好奇的是,因果关系或因果图在实践中很重要的首要原因,是不是因为时间流的方向是确定的?
Judea:不是首要的,是次要的。这是有风险的。我常举的经典例子就是公鸡打鸣不会造成太阳升起,尽管公鸡叫发生在太阳升起之前。
Stephen:但是公鸡想必会有昼夜节律周期,尽管我不完全知道什么造成了公鸡打鸣。也许有人会假设,在公鸡打鸣之前,世界上有些事情会发生了,而这个事情会决定公鸡打鸣。所以,我的意思是这里有个时间的概念,尽管你选定的特定事件(公鸡打鸣),不是另一个事件(太阳升起)的因果关系。
Judea:隐变量的概念确实可以满足我们的这种观念 “原因总是在结果之前”。这个概念可以满足和解释为什么公鸡打鸣在太阳升起前,尽管它不会影响太阳升起。
4. Wolfram Physics Project中的因果图
4. Wolfram Physics Project中的因果图
之后,Stephen介绍了自己的因果图,并与Judea交流(更多内容可以参考Stephen的Wolfram Physics Project)两者之间的关系,提出Judea的因果图有可能不能捕捉一些量子机制引起的效应。
Stephen:在研究基础物理时,我一直在用一些东西,在过去大约30年里,我把这个东西叫做因果图,用来思考一些基本的问题。我认为我们可以通过10到500个节点的因果图来讲述我们宇宙的故事。你最大的因果图有多大?
Judea:最大的大约有30个变量。
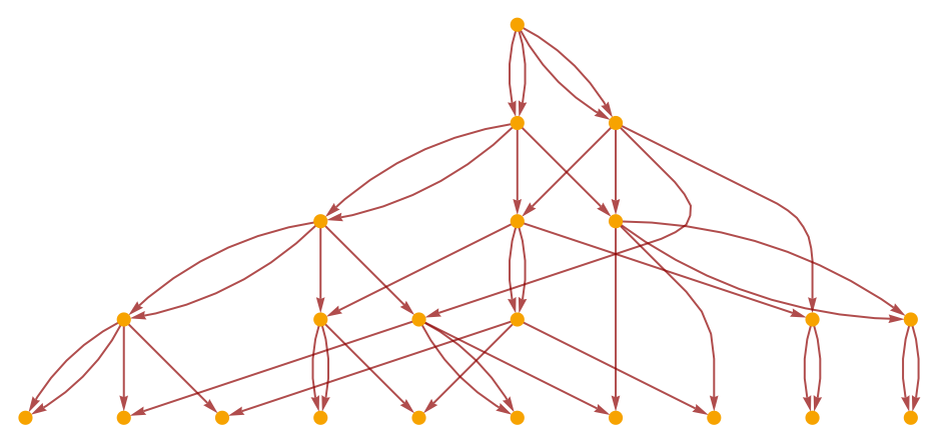
Stephen:举一个例子,这个是一个决定论型的图,每个黄色节点是一个事件,每个箭头确定这个事件的概率,你可以把这些节点理解为函数,给定特定输入,那么这个事件只有当之前节点都激活才能发生。这里有两个箭头是因为因果关系有两种携带者,需要从前一个节点事件获得两种类型的输入,这个事件才能发生。
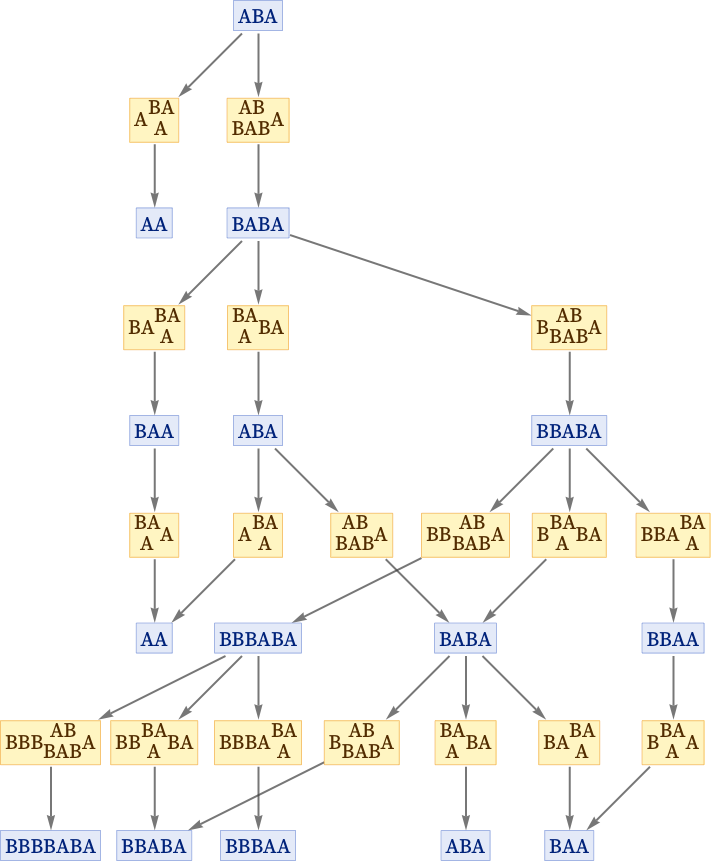
再举一个例子,这个图和你的设置有点不同,蓝色的是状态,黄色的是事件,箭头表示从一个状态或事件到另一个的变换,比如这个蓝色节点的状态BBBABA下有三个事件可能发生BBB(AB,BAB)A,BB(BA,A)BA,BBBA(BA,A),这是一个字符串重写系统(string rewriteing system),所以这里有三种可能的重写(rewriting)发生,在这个字符串(string)上可以有三种rewriting,然后产生不同的状态:BBBBABA,BBABA,BBBAA。所以这个是因果依赖关系,因为除非一个rewriting的输入已经被前一个事件所产生,否则这个rewriting不会发生。
再举一个例子,这个是一个平凡的图,里面每个事件有两个输入,产生两个输出,在我的这个图里面,感兴趣的问题是如何确定哪些事件可以同时发生,如何定义事件的偏序关系,这个在物理学中的解释是,相对论基本上是关于能够选择这个因果图的不同叶子的故事,我们考虑的不同的选择,决定了可以同时发生的事件,这个是决定论型的图。
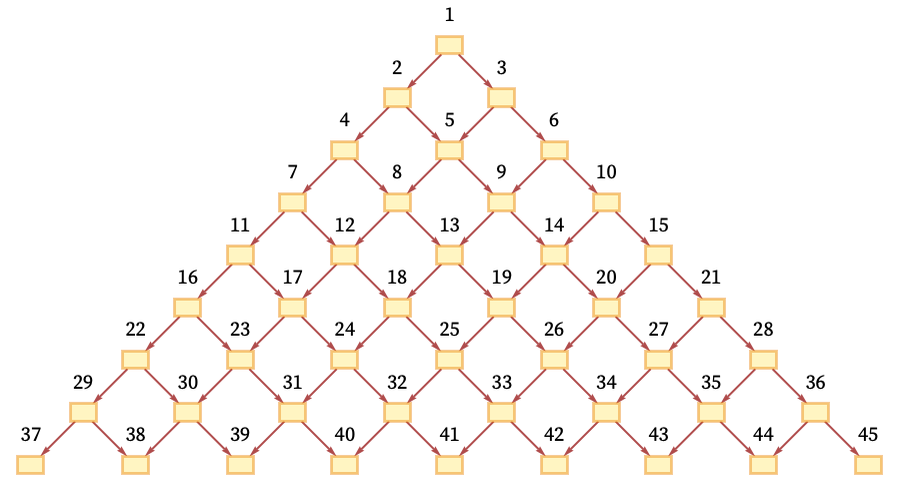
我想说的是,我认为这些因果图的一些版本在物理学中很重要, 我这里谈论的因果图是指一些事件发生,并且这些事件使得另一些事件发生。我刚刚意识到我的因果图中和你的工作有关系的是,叫做multi-way graph,举一个例子,这个是一个博弈图,它表示博弈中所有不同的可能的决策,于是有很多可能的决策路径,所有可能的路径构成的集合表示成我们所说的multi-way graph。你可以从中做出一个因果关系的图,意思是如果你想进行下一步,你需要先走前一步,所以可以用因果图来表示所有可能的博弈和可能的博弈过程。这是一个决定论型的图,它整个是一个大的博弈图。忽略掉细节,写成概率的话,我觉得这类图可能和你的图在某种程度上是一样的。
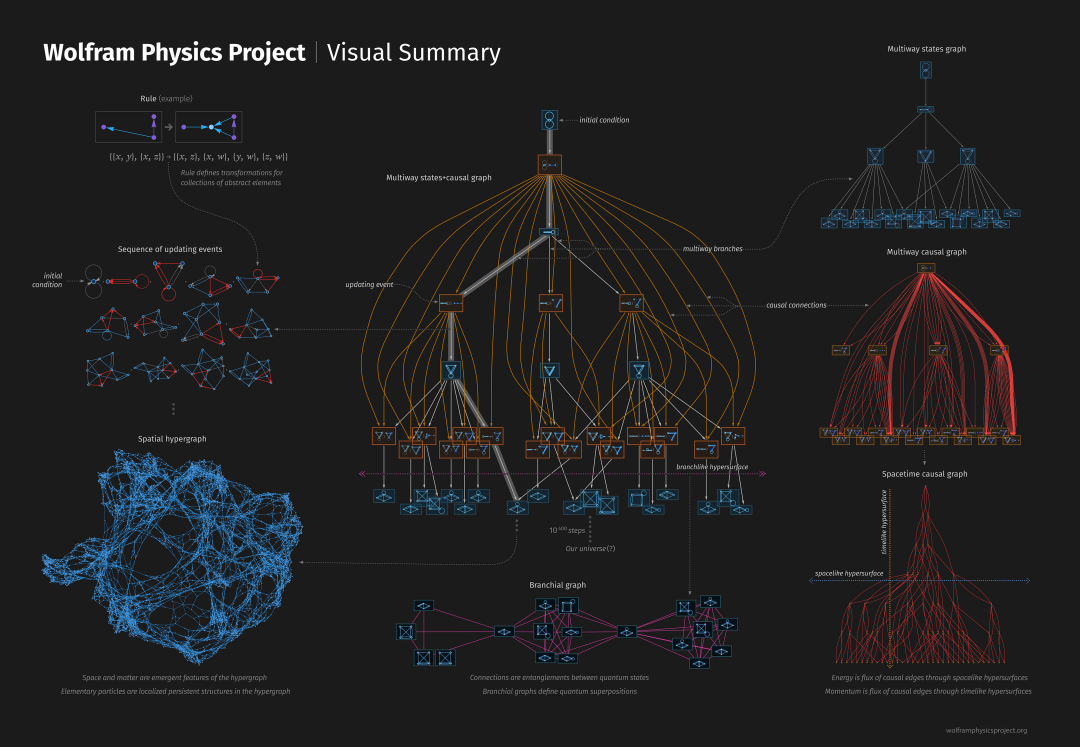
Judea:我怀疑不行。我之前做过一些关于博弈图的工作,它们被称为And-Or graph,它的节点本质上是表示事件,或者game中的position,或者board中的position。
Stephen:我想我们不想在这展开太多技术细节。这个是multi-way graph的一个例子,你可以用它做一个博弈,可以用它来做字符串重写。有了这些规则,我们可以从状态中产生可能的输出。
Judea:这很像一个博弈图,每个节点都有可能发生,每个孩子节点发生前他们的父母节点需要发生,我们把它叫做And-Or graph。我很熟悉它,这个和贝叶斯网或者定义因果模型的图关系不大,除非因果图可以被展开。这样,每个因果图都可以通过宇宙中发生的事件被展开,实际上因果图是And-Or graph的一个压缩版本。
Stephen:是的,所以你把它叫做unrolled graph,然后你可以压缩,可以映射,忽略branchial direction(不同可能的历史方向),然后你可以用概率表达它。如果你可以追踪这些确定的路径,你可以获得额外的效应。这些效应在每个节点表达独立性概率时不能被捕捉到。
Judea:我不确定,因为我刚说的是因果图可以对所有可能的策略产生一个紧凑的表示。
Stephen:你在把所有进入特定节点的路径,所有走出节点的路径用条件概率来表达。实际上,这里有更多的信息。想象Burglary和Earthquake这些输入节点是气体中的分子,它们有相互作用,在Alarm这里有一些额外的信息,但这些信息不能用条件概率表达。我觉得你所不能得到的效应和量子机制中的某些东西有关系,而这些效应和传统的概率是不一样的。我认为如果你增加额外的thread,而不是把它们压缩成概率,这种效应就能被捕捉。我也没想到过类似这些的,我其实也不知道会不会。
5. 统计学中的依赖和独立先验
5. 统计学中的依赖和独立先验
接着,Judea讲述了研究人员交流数学相关的东西时需要注意信息从哪里来的,需要知道为什么要玩这种数学游戏,想要回答什么问题,并和Stephen讨论了统计学中依赖和独立概念的历史。
Judea:当我们谈论数学相关的东西时,我发现关注两个东西是很重要的。一个是,构造图时需要问自己,信息从哪里来的,从而决定箭头是否单向,有没有箭头,你需要问你自己这些问题本身究竟是什么。第二个是为什么你要玩这个数学游戏,你想要这个图给你回答什么问题,这是定义数学相关的东西的另一个准则。在这个Alarm的图中,我们这么画,是因为我们有个重要问题要回答,在我的房间里,如果Mary叫我了,那么Burglary发生的概率是多少。所以我画这个图的目的是进行计算,遵守输入的前提下,一致地给我快速且可信的答案。现在,我想问的就是如果Mary叫我了,Burglary发生的条件概率是多少这个问题。这只是一种个性化回答问题和表达你的知识的方法。
Stephen:这确实是一种优雅的表达方式。如果在某个利用了统计学的研究领域,在人们知道了计算,数学逻辑和函数后,人们很可能会在经典统计学之前就发明这种表达方式。在经典统计学之前,数学方程的概念是非常双向的,描述这种东西与那种东西有关,而不是我们在编程中更习惯的模式,即你有这个输入,现在你将得到那个输出。我的意思是,是否有一种合理的方式来总结输入和输出,是用一种因果图的思维,而不是像更传统的统计学思维那样,仅仅表达这个东西与另一个东西有某种等式关系。
Judea:在Alarm的贝叶斯网中是没有这种关系的。在贝叶斯网的游戏中,可以加入允许人类的知识,这在统计学中并不多见。1831年皇家统计学会宣布所有的判断都是禁忌。这意味着我们发表的应该只有数据,数据,还是数据,不应该有任何观点。与之相反的是,我想以一种紧凑和方便的方法把专家知识加进去,从而得到传统的概率给出的答案。这里不同的地方是在论文中加入人的判断。
Stephen:在经典的统计学中,人们可能会这么想:OK,现在有一些变量集,我们要假设这个变量不依赖于那个,我们要把我们的判断放在事实上,否则一切的联合概率分布的数据没有这个和那个的依赖关系。这似乎更像是一个研究领域的文化:不要只是把所有的变量放在那里,多看看数据暗示它们是如何关联的。我的意思是,统计学相比于因果图,给定数据时,反驳统计学结论的难度比反驳在更简洁的因果图中得到的结论的难度要大得多。

Judea:是的,没错。这可能需要回顾统计学的历史。独立性的概念是在哪里产生的呢?也许是在19世纪?
Stephen:Fisher做农业试验是在1930年代,应该是远在那之前。人们在讨论独立游戏和随机游走等方面的独立性,像是连续掷骰子什么的,Bernoulli肯定是有独立性概念的,分析概率实验时,他们应该是有一些知识,知道什么是依赖,什么是独立的,所以应该是在Bernoulli之前。
Judea:但我认为直到Bayes之前,他们都没有想到过条件独立性,也就是1763年。
Stephen:但是Bayes的工作在很长一段时间里并没有被集中纳入数学文献库。很长时间里,人们会这么讲,“它只是”,“顺便说一句,有这样一个有趣的东西”。也许应该注意一下它在什么时候以一种严肃的方式在统计学提及。
Judea:Laplace大肆宣扬Bayes的理论。
Stephen:Laplace说的是拉普拉斯妖,他对以下问题感兴趣,即如果你原则上知道宇宙中所有原子的位置,你能不能预测未来。所以他可能对以下问题感兴趣,如果你知道未来,你能推断出过去的什么信息。
Judea:我不确定Bayes的理论是不是在这种情况下正式出现的。但在1812年,他的《概率的分析理论》中,阐述了Bayes的理论,并使之成为一套完整的数学分析体系。
6. Judea的成长经历和70年代之前的事情
6. Judea的成长经历和70年代之前的事情
Stephen询问了Judea从1935年出生到1970年代的出生,移居,父母,所在地Brebrak和附近的Telaviv,以及之后的成长,教育经历,和研究工作转换节点等,也是Stephen所感兴趣的部分,这一部分涉及文化历史和地理背景。该部分在原视频30分-1小时24分,本文仅进行简单介绍。
具体的,包括1935-1960Judea所在基布兹的生活工作,教育实验(他的老师鼓励Judea母亲让Judea继续深造),农作物,家畜贸易等社会背景以及Judea所接受教育的方式等等,譬如用历史人物发现规律的时间,历史背景和人际关系进行教学,这使得他们相信自己也可以做到类似的工作。
Judea于1956年决定学习工程学,并于1960年在以色列的Technion获得电气工程学士学位,同年,他移居美国并攻读研究生。他在纽瓦克工程学院(现新泽西理工学院)获得电气工程硕士学位,于1961年获得罗格斯大学物理学硕士学位,并于1965年在布鲁克林理工学院(现纽约大学坦登工程学院)获得电气工程博士学位。

1960年代,当时的人们在1930-1940年代提出的图灵机和之后1950年阿兰.图灵的《机器能思考吗》等一系列工作启发下,在纯机械,真空管,电子管等已有存储基础上,尝试遍历当时已知的一切物理现象模拟存储从而制造先进存储器时,Judea参与利用超导现象制造存储器的工作(在视频中介绍了一些有趣的物理现象和事情),但它很快被半导体存储的快速发展取代,商业研究价值消失,Judea面临失业。当时相关从业人员认为工业界工作优先于大学的工作,最后他在其他人介绍和帮助下在1970年进入UCLA进行教学工作,在教学期间,他因教授决策论和阅读Reichenbach在1956年的《The Direction of Time》等对人工智能产生兴趣,并开始研究,进行了图像压缩编码,博弈算法研究,并出版了《启发法》,在那之后他在不确定形式化中使用基于概率的想法,最后发展为贝叶斯网和之后他的因果理论(另一类主流的因果形式化语言是Donald Rubin在Neyman和Fisher等统计学家基础上建立的Potential Outcome)。
7. 70年的图像压缩编码、决策论和博弈论
7. 70年的图像压缩编码、决策论和博弈论
在半导体初步解决了计算存储的问题后,一部分人开始在此基础上从事一些软件开发,应用性的计算问题和初期的人工智能问题,如图像存储编码,编程语言设计,智力游戏等。
Stephen:1970年时,我很好奇当时谈论人工智能的人,他们用的理论是某种计算还是某种启发?
Judea:对我个人来说人工智能当时是把图像编码变换和表示成最少的比特,我花了三年时间做图像编码。有各种各样的变换,比如Walsh变换等,当时的任务是把他们表示成最少的比特。当时所有正交的变换都是候选。
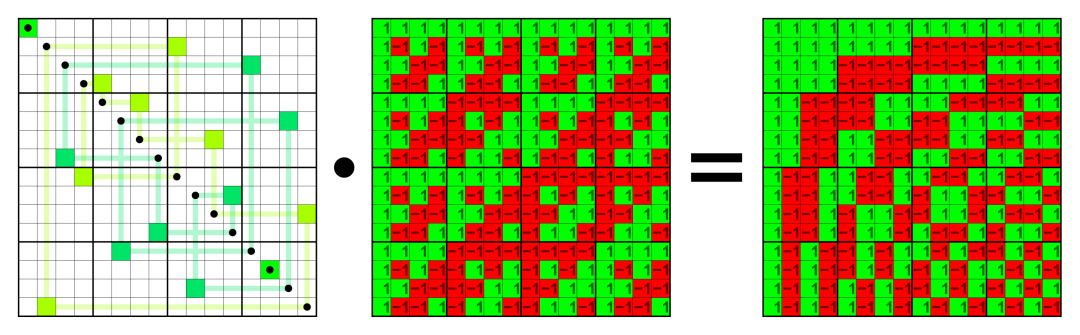
Stephen:我估计就像是今天的gif或者jepg格式,像Walsh变换一样,这是一种类似离散的傅里叶变换的东西,你当时在尝试去除图像中的高频部分。当你在做这些研究时,你是把它们变成了论文吗?
Judea:是的,发表在IEEE Transaction on Image Processing。
Stephen:是像tiff或gif这种格式吗?他们用了傅立叶变换而不是Walsh变换,但我估计想法是一样的。在那之后,他们又用了字典压缩方法,比如lzw压缩。
Judea:我不知道,这些都是些新东西。我当时教决策论,这使我进入了统计学,序列分析等领域。像是传统的运筹学,传统线性规划的东西。当时运筹学是统计学的一部分,因为当时我在决策论上读了这种东西。那让我进入了科学哲学领域,我阅读了Reichenbach的东西,那很令人着迷。那令我思考概率是什么,统计是什么。
Stephen:传统的运筹学和线性规划不是统计学的东西了,是有很多限制然后找到最优条件的东西。但当时有联系,是因为大学的安排使他们和统计学联系起来,还是因为有某种智力上的互动呢?
Judea:我忘了是谁或者哪个部门让我教这个课的,但我很感谢他。我当时用的一个统计学家的书,他会讲minmax等各种策略,序列分析等,这使我开始思考这些东西的哲学。没有决策论,我不会有语言和工具去思考不确定性和决策的本质。
Stephen:那你的决策论有什么特殊的应用吗?
Judea:没有,只是为了成就学生而教授决策论。关于怎么获得信息,并把信息转化为最优决策。
Stephen:那当时里面有博弈论的东西吗?或者博弈论是独立于决策论的?
Judea:当时是分开的。我接触博弈论也是在1970年代,是因为另外的原因。我进入了人工智能的领域,当时的主要问题是下国际象棋,这是当时主要关注的东西,70年代末,他们想让它在下国际象棋上击败人类,从而检验其智能程度。当时大家都在玩游戏(play game),比如alpha-beta过程,最小化步数,最大化向前看的步数,学习演化函数等,我是在写了我的第一本书《启发法》后进入的这个领域。我进入这个领域是因为它测试涉及直觉和推理之间的连接。你关于游戏局势的评判需要被显式地存储,然后你需要向前看,进行minmax和rollback。minimax和rollback也是香农在1948的发明。这很有趣,需要在前向搜索上花费更多时间和构造更好的评估函数上权衡,我当时把时间都花在这些游戏上了,至少我证明了一些有意思的定理。
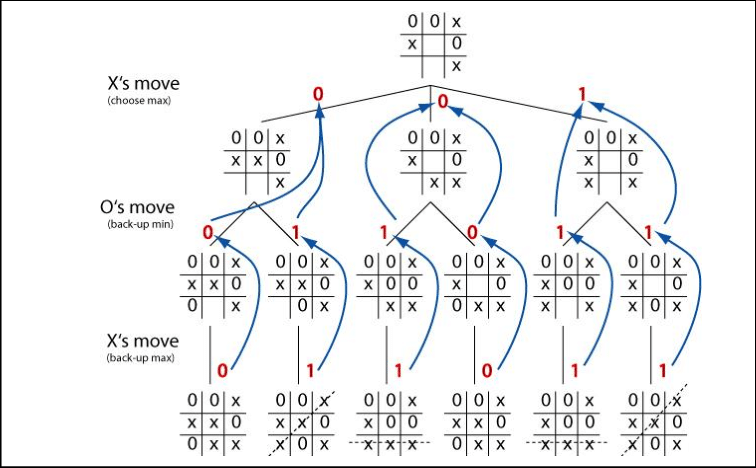
Stephen:你在做游戏局势的评估函数时,它更像是Fortran语言的一串代码还是某种原则?
Judea:我不知道底层代码,但我知道仅仅是简单的线性回归。
Stephen:今天的机器学习会自动生成很多特征,一些游戏状态的指标,来表示他们。
Judea:我认为需要知道这些权重的重要性,从而给局势一个全局的评估。这是Samuel在60年代初的工作。我的基本工作是关于前向搜索和回滚,你可以知道关于算法的哪些最优性质,某些搜索算法通过某些规则可以如何对某些没有看到的节点剪枝,比如,1982年我证明了alpha-beta算法是最优的。
Stephen:你知道在multi-way system中,当你实现某些博弈时,当你不知道某些证明的理论或逻辑规划时,你总是想在集合中找到最优路径,今天剪枝已经是一致的选择,就像你在做自动证明机器时,怎么才能向下走,怎么忽略其他的一些节点。其中一些依然是未解决的问题。
8. 人工智能初期Judea的启发法
8. 人工智能初期Judea的启发法
接下来,Judea讲述了在人工智能的早期,他关于启发法的相关工作。(详细内容可参考1984年的《Heuristics:Intelligent Search Strategies for Computer Problem Solving》)
Judea:问题是,程序能否自动生成启发?答案是可以。你可以按照下面的机制来做。启发是某种简化问题的最优方案,所以不是处理一个复杂的问题,而是把它简化到一个你能找到全局最优解的空间。这个简化问题的全局最优解是原问题的一个启发。如果你知道简化和另一个元素是什么意思,那么这可以是自动的,我忘了另一个元素是什么了。简化可以通过放松条件达到。
Stephen:所以,可以这样,有一个棋局,我不关心每个棋子的位置,我只关心有多少个棋子,然后你可以在一个简化的空间中描述局势,仅仅用它全部自由度的一个子集。
Judea:这个有点粗暴,没人会买账的。我以寻找走出迷宫的最优路径为例,这里的启发是当没有任何障碍时,你走出迷宫的最短路径,这很明显是一条直线。所以在无障碍游戏中最优路径的长度,是一个有障碍迷宫中最优路径的启发。
Stephen:我的问题是,发现某个更平滑视野中的最优方案是比在崎岖不平的视野中做简单太多了。当你说最优解时,我会想到在某个视野中进行最优化,比如发现这个视野的一些覆盖,一些山峰的凸包,等等。然后在这些山峰的凸包上解决问题,然后我就知道要做什么了。
Judea:当然,这会告诉你接下来要探索什么。在原问题里,它不是解决方案,它只是指导你接下来要探索什么。
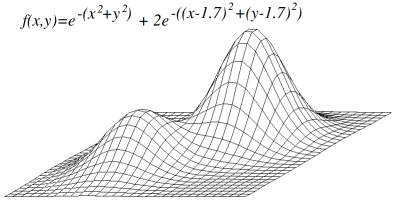
Stephen:这取决于问题的结构,比如,这种近似是否能否指导出正确的方向,以及最后的结果是不是一个山里的一个小坑,但是你却没能通过这种近似来发现。
Judea:你会发现的,因为你要不停的思考并且做评估,所以你会向前看,还会回溯,然后一直这样,最后你会发现这个最优的。但是问题是在你发现它之前你要做出多少努力。这个是可接受启发的概念(admissble heuristic),是建立把原问题放松的基础上的。这可以被证明在你最后找到最优解时代价是可接受的。
Stephen:比如你想要找到图中的一条路径,这取决于这个图有多宽,然后这里有特别短的一条路径。你可以说,让我们把图变模糊,让我们找一些近似的东西,只是单独看每部分,然后把它们合并起来,那么这个图必须有某种条件,这样我们的聚合才能是发现最后结果的一个好的指导。
Judea:我的想法没有那么成熟。我只是关心可接受性(admissiblity),以及是否保证最后找到最优解,这是被证明了的。然后是发现启发的媒介化,需要放松什么。为了得到简化的图,需要放松原图中的哪些障碍来得到一个好的启发。这是自动化的,今天已经在自动规划领域使用了。
Stephen:我研究图,还有扫描图的方式,这和一个人理解时间和空间的概念很有关系,比如用10-500个节点表达物理学之类的。但是这会偏离我们的主题。
9. 70年代的人工智能系统
9. 70年代的人工智能系统
Stephen:在你最初发现因果这个领域的时候,什么让你感到兴奋?
Judea: 我是通过概率论间接的接触因果的。在1970年代末,专家系统应运而生。人们关心如何编码来自专家的知识。
Stephen: 我也记得这些事情。
Judea: 所以,我们有像Mason这样的系统。
Stephen: 你最喜欢的知识表示方法是什么?
Judea: 我并没有在如何构建系统方面研究太深入,关键问题在于如何表示不确定性 (uncertainty)。最初的想法是使用规则,然后利用不确定性的程度来量化这些规则,最后合并这些规则。例如,如果你发烧,那么就有存在得疟疾的某种确定性(certainty)。又或者,你有疟疾,便预示着你有某种去过非洲的确定性。你必须结合这些规则,结合的方式是通过它们的实例。而这种规则的合并并不能用简单的“概率”一词来表达,它们不能展示我们用以处理不确定性的某些属性。例如,你发现有烟,那么在某个地方就存在着火的确定性;如果你确定了在某个地方有火,那么有烟就有了确定性。这样便有了反馈循环,突然你发现你必须发出警报,所以你开始逃跑,因为火灾必须有一种确定性。这种确定性不知从何而来,只是出于反馈。如果你不关心知识的来源,那么你会有“逃跑”这个行动所带来的正反馈效应。
Stephen:早期的像Mason,Dendral这样的系统,都是纯粹基于规则编写的确定性系统,还是怎样的设计?他们是否在一开始就有一些问题?
Judea:他们是从确定性的规则开始的。然后他们不得不基于不确定性来重新构建。因为所有事物都有例外,而且一定会有一定的异常。
Stephen: 但它仍然是离散概率,就像这些规则会触发这个概率,其他规则会触发其他的概率。
Judea: 没错。它只是触发最终结果的概率。
Stephen:明白了。所以他们也会有概率分布,就像这些事物的发生的结果遵循高斯分布。
Judea:不是高斯分布。它们仅仅是确定性因子(certainty factors)。他们称之为不确定性因子(uncertainty factors)。每种规则都被确定性因子所修饰。当你有一系列的规则,你试图询问优先级或者一个结论,你必须结合所有的这些规则以及它们的确定性因子,确定的算子(calculus)。而且,没有无用的算子,只有结合它们的特定过程。而这个特定的过程,使得我们难以获得我们迫切想要的结果。
例如,回顾我们之前提到过的概率图。要么发生了地震,要么就是发生了盗窃。我们都明白,一旦有更多的证据表明发生了地震,那么防盗报警器响的概率就降低了。这就是所谓的“解释效应”(explain away effect)。你有证据证明其中一个原因,它就降低了另一个原因的可信度,这被叫做“解释效应”。我们期望在专家系统当中看到这样的东西,但它没能成为现实。因为规则总是呈现单调性,这些想法从来没有证据,所以总是被无视。再加上因果和诊断规则的组合,并不能很好的匹配。例如,如果草是湿的,那就意味着下雨了,如果我打开草地上的洒水器,草也会被弄湿。因此如果我打开洒水器,系统会认为是下雨了。它们只是遵循规则链路。
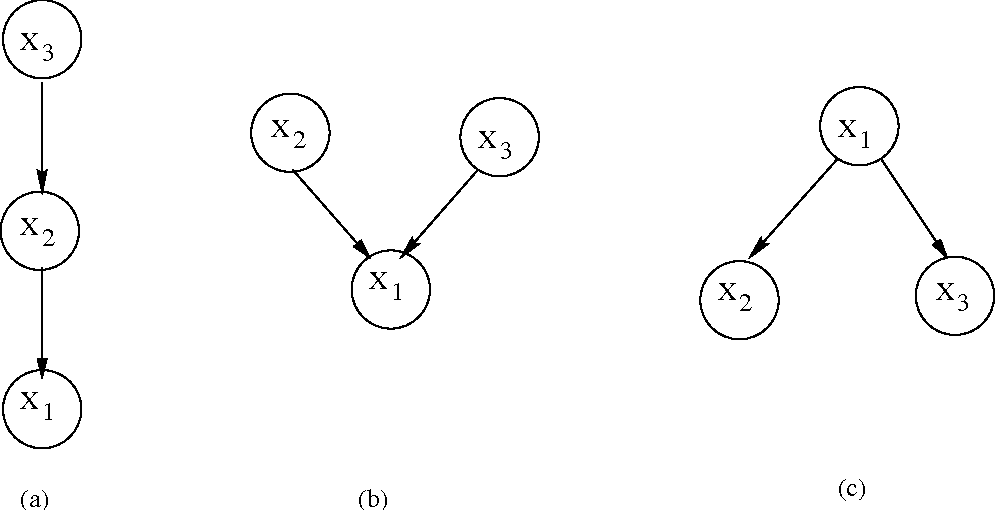
如果你想要不确定性,也可以。但如果你链接两条规则,其中一条是诊断性的,另一条是因果关系,那么你很可能得到不合理或自相矛盾的结果。你不会想要根据打开洒水器的事实做出下雨了的结论。这样的矛盾结果使得每个人都疯了,我们对于不确定性的管理一定出了什么问题。
但我知道基本定理并没有这样的自相矛盾,我是从决策论的教学当中知道的。所以我说通过贝叶斯理论来做,这样我们就不会陷入这种矛盾境地。但不幸的是,用贝叶斯条件概率来实现,存在一个复杂度问题。正如我们之前看到的那样,如果你用一张张概率表格去表达概率分布,那么当你用正统的概率去处理该问题的时候,你就会遇到一个指数级时间和指数级空间的难题。所以你负担不起回到概率表格并将你的知识编码为标准概率的成本。所有人都想过,走概率这条技术路线已经不可能了,因为这涉及到计算复杂性。所以,在人工智能社区,概率不合适用来处理人类的不确定性当时是一个共识。
10. 80年代的专家系统和概率的来源
10. 80年代的专家系统和概率的来源
Stephen:在80年代初,他们采访了石油专家关于如何勘探石油,医学专家如何治病,或者他们想要编码的任何其他专家知识。他们认为将所有的这些数据构建到专家系统中,一切便会很好的运行,但实际上这并没有成功,这种一般性的方法并不成功。我并非完全理解为什么这种专家系统不能很好运行,在我看来,至少它的某些方面似乎有些天真。它们是关于如何表示人类的知识,然后完全基于逻辑运行,例如,这个发生那个就会发生,这看上去不一定是正确的模型类型。我很好奇,基于你对专家系统的印象是什么,以及你怎么看待专家系统没有接管世界?
Judea:我觉得可能是因为他们试图建模专家,而不是建模环境,他们对医生进行建模,而不是对疾病进行建模,但医生并不能清楚地说明他或她在做诊断时经历的各种程序(比如有些时候医生自己也不知道自己怎么决策的,只是那么做就对了;运动员自己也不知道自己为什么跑的快或篮球打得好),特别是,当他们是融合了多种源头的知识时。
Stephen:所以也许那种AI的实现方式太AI导向了,因为它尝试建模大脑本身,而不是大脑所研究的系统。
Judea:建模环境,例如,疾病,而非大脑,例如,医生的大脑。建模这些真正令人信服的事物,需要我们进行第二轮工作的是可重构性(reconfigurability),这意味如果你拿到了知识,如果某小块改变了会怎么样。以汽车引擎为例,如果你有一个关于汽车的模型,汽车的泵位于不同的地方,你不想重新换引擎,你想做的事是基于新的泵位置的一些事情。这个问题是可重构性。你可以局部的改变一些组件,从而基于之前的知识系统模块化地重构出新的知识系统,这是一个真正的问题,在用户领域是决定性的。这是人们从基于规则的系统,转向基于贝叶斯网的决定性原因(专家的大脑是高度集成的,但环境可能是模块化的,这使得专家系统无法面对环境扰动)。

Stephen:但是,在决定论型规则的系统中,并不存在没有模块化的问题,因为决定论型的规则会有一些子模块,可以改变某些规则,实际上,他们可能是为了把概率加入他们的系统转向了贝叶斯网。
Judea:每个规则都会有例外。(专家的规则的模块化是专家大脑的模块化,而非直接是环境的模块化,专家的认知和表达能力总是有限的,所以总会有规则是例外的)
Stephen:在我自己的努力和事情中,我总是认为概率是一种承认某种程度上的失败的概念。使用概率其实意味着我们不知道系统中的某些东西,比如什么外源性的东西之类的。很多时候人们看到了随机的行为,那么他们认为肯定是某种东西我们不知道引起的概率。但是,实际上,这个系统它本身内在就可能是有随机性。最经典的例子就是数字π,这个数字通过了目前的所有的标准的随机性检验,尽管我们已经有很好的办法生成这些数字。然而并不是因为数字π小数位的下一个数字是概率的,所以数字π才是随机的。概率意味着你并没有真正确定住这个模型,换句话说,可能系统的有些部分我们不能很好的理解。现在,显然有很多实际的应用场景中,这种概率模型是正确的模型。但是,在我们现在的基础物理学的模型中,我们现在是可以用10-500个节点的因果图建模,这是一个完全决定论型的模型,宇宙中根本没有什么奇迹。简单说,就像是有决定论型的规则,然后开始运行,它恰好有很多的分支,这些分支的产生和量子力学中的某些机制有关,但归根结底,它还是个完全决定论型的故事。对我来说,当你谈论概率时,这意味着你不了解系统中的某些部分,如果你能知道更多,你就可以避免用概率进行建模。如果你说人们必须要有概率,在某些情况下人们需要把概率加进去,我对此是有异议的。但是我理解这种想法,因为概率是个很实用的东西,概率是一种很好的参数化世界的方式。
11. 80年代后期
贝叶斯网的消息传递和神经网络的对比
11. 80年代后期
贝叶斯网的消息传递和神经网络的对比
Stephen:我猜测我们已经快要触及你现在关于因果关系的思考了,现在我们是不是已经在触及你的因果理论了?还是说我们需要更多步骤才能触及?
Judea:是的,当使用贝叶斯网时,创建贝叶斯网的人思想的背后就有因果关系,尽管他们自己可能并不知道。正式地定义时,他们只是把这些东西以条件独立性的形式定义,这个还只是纯概率的概念。尽管因果关系并不是他们讨论的一部分,但是它已经在使用贝叶斯网的人的脑中了。这种条件独立性是贝叶斯网络在提供可重构性这种能力时拥有好的性质的根本原因。接下来便是因果关系,应该说到了后门准则。
Stephen:所以,重点是相较“所有事物都相互影响”这样的理念,实际上我们构建的是一种从原因到结果的因果流,使得我们直接打交道的是有向无环图(DAG),而不是一团巨大的概率表集合。
Judea:那就是贝叶斯网络,这使得我们可以优雅地处理贝叶斯网络而不是一个巨大的概率表集合。
Stephen:那它是基于什么工作的呢?
Judea:基于贝叶斯网的判断性假设作为它的输入,那些判断性的假设是指存在于某些节点之间的条件独立性。
Stephen:为什么当你有足够的数据时,你依然不能发现这些因果联系?
Judea:的确是可以发现的,这和贝叶斯网的学习有关。因为你有观察不到的隐变量,这是不能发现他们的原因的一种解释。如果没有隐变量,你当然可以发现贝叶斯网的结构,但方向不行,因为有些方向改变后,和数据一样是相容的。
Stephen:传统的贝叶斯网已经不是专家系统的一部分了。在专家系统的时代,神经网络比较低迷,尽管他们在1940年代和1950年代辉煌过。他们在1980年代开始有类似Hopfiled网络等,但它们没有被当时搞AI的人严肃对待过。就我个人观点,这些东西是工程上的解决方案,而不是数学上的某种原理,他们做的东西很工程,甚至不是软件工程,比如让我们把这些东西凑在一起,看看会不会有什么有用的结果。
Judea:这曾是一种黑客文化背景下,整洁(unity)和邋遢(scruffy)之间的对峙。这是两种思路。邋遢的做法是先把事情做了,以后再讨论理论保证。整洁的做法是,在构造过程中保证事物有一些连贯性,拥有你所期望的一些属性。但是邋遢的做法成为了这个领域的主流。
Stephen:但这么做的人大多在工业界不是吗?我印象中,有很多的大公司和政府机构,都想要把一些东西都弄成专家系统。但是我不知道大学里的哪个系是来发现专家系统的专家的?
Judea:也许是计算机系?我不知道。
Stephen:我猜测类似商学院会有一些决策理论的东西,我不确定。所以,你做的东西,有没有最后进行大规模应用?
Judea:贝叶斯网进行过大规模应用,贝叶斯网在1980年代出现的。
Stephen:在专家系统的年代,它进入了专家系统的世界了么?在我的印象中,在1990年代,专家系统的整个倡议(initiative)都在销声匿迹。
Judea:贝叶斯网络出现于1980年代。在1985年,我发表了第一篇论文,但在我看来,我是受神经网络领域的一篇论文启发。那时,我在加州圣地亚哥待了一段时间,拜访Roman Heart,一个神经网络领域的新人。他在做孩子如何进行文本阅读理解的研究。他构建了一个模型,拥有由处理器组成的层次结构。每个语法处理器、文字处理器、特征、单词和字母,当他们来来回回,相互交流时,每个都为邻居节点提供支撑或反对某些选项的证据。他假象,这样的分布式的消息传递系统是解释孩子们在文本阅读理解中表现出快速和可靠的唯一方式。所以他从阅读理解这个领域提出了这个消息传递的方案。如果你只依靠概率来实现这一切就太棒了,那就意味着我们可以一石二鸟:消息传递的计算优势和概率所提供的连贯性。
Stephen:在那个时代,整个并行分布式计算,正在谈论关于神经网络。但他们实际上看起,Roman Heart的方法来自更高的层次,例如从心理学角度,而不是底层的将神经元连接在一起的层面。现代的深度学习的狂热,试图从简单的神经元开始构建,而不是心理导向,让我有更大的模块,并从这些模块中构建,这很有意义。在你的网络当中,每个节点或变量都有名字和含义。这与制作巨大的拥有上亿个权重的神经网络有很大不同。
Judea:这个构想来自第二层面,也就是心理学的视角。我们的谜题是为什么孩子们读得那么快?对于不同层次的分析,我们都知道或者至少部分知道其名字。例如,语法约束,文字和光学特征。我们知道它们存在的特征。那么它们之间有何互动?这就是Roman Heart提出的高质量的问题。他提出了一个消息系统方案。
Stephen:在研究孩子阅读的方面,有没有一个贝叶斯网络?
Judea:我的意思是,消息传递的想法,引发了我在贝叶斯网络方面的工作。同时,这样的因素,使得我的贝叶斯网络可被接受。因为如果你能使这样的消息传递方案运行,你甚至不必编写任何程序规则。只要使得邻居能够与它的邻居通讯即可,其余都是通过消息机制异步完成。
Stephen:所以你需要写下一个架构,关于什么级别与什么级别进行通信以及这些层级的邻居节点。
Judea:是的,你需要编写知识库的结构,就像我们之前构建的那个警报系统那样。紧接着,你需要为每个节点指定的是其职能,定义他们与其家庭节点和父母节点相互作用。就像这样定义网络中每个分割的子网络(家庭网络),那就可以了。然后,你便可以提出,诸如,我观察到第17号节点,节点23号为真的概率是多少,这样的问题。
Stephen:所以,这是完全不同的两回事。一个是,给定每个节点的概率方程集合,然后,便可以在各种方向上进行演绎。例如,如果一件事情发生了,那么火灾发生的概率是多少。一旦你拥有了这样的网络,你可以计算不同事物的概率。另一种是,利用数据,便可以更新网络内的概率函数。
Judea:这是不同的任务:学习贝叶斯网络和使用贝叶斯网络。换句话说,是构建贝叶斯网络和利用它进行推理。
Stephen:用现代神经网络的语言类比,这就像是人们经常谈论执行或推理阶段与训练阶段。这两种不同的事情,需要不同程度的努力来达到目标。神经网络的训练,例如反向传播算法和自动微分类的方法与你在贝叶斯网络方面的工作相比,是一个单独的工作分支吗?
Judea:完全不相关。我并没有关注神经网络在架构和训练方面的发展。那是在我完全不知情的情况下发展的。我非常惊讶于他们可以做得这么好。
Stephen: 在2012年左右时,所有人都对此感到惊讶。
Stephen:关于那些用于训练贝叶斯网络的算法。在每一个节点会有怎样的分布或函数。当拥有数据之后,有类似反向传播算法这样的方法进行训练么?是采用类似蒙特卡洛的方式或者其他方式来做训练?
Judea:我只工作在一些具体的案例上,所以无法告诉你概况。我用“and or”,噪音或噪音结果的门(gates)。所以,当运行的时候只有分支结构或对撞结构通过整棵树。
12. 早期不确定性的形式化方案
12. 早期不确定性的形式化方案
Stephen:我很好奇关于不同的想法之间的关联。模糊逻辑(fuzzy logic)与你的构想之间有关联么?
Judea:在我们寻找不确定性的calculus的那个年代,模糊逻辑是一个竞争对手。所以他没有提出概率论之外的模糊逻辑作为替代。理论上如果你分配每个命题(proposition),一定程度的不确定性或每个变量,本质上都具有一定的不确定性(uncertainty)。但他们不叫它不确定性(uncertainty),而是叫他模糊性(fuzziness)。原本期望它能够解决问题,但它并没有,原因是它彻底地与将网络中不同部分的不确定性组合到一起的思想背道而驰。它不能解决组合的问题,它无法把诊断和因果规则结合起来,所以是与概率完全正交的,不能结合不确定性。另一种具有竞争力的方案,是信念函数,它是Dempster-Shaffer的calculus,那是一种完全不同的想法,但是仍然存在满足这些要求的困难。这些想法是完全正交的。最后概率的想法胜出了,人们相信概率是用来组织知识的一种方式。在图模型中,它的输入是条件独立性,一个随机场的数量,所有这些都是基于对它输入条件独立性的。
Stephen:马尔可夫随机场这种东西,有很多自由度,而不是你所说的这里有很多的起了名字的变量。
Judea:马尔可夫是基于贝叶斯网的,它的边没有方向,通过把条件独立性编码成无向边的形式,从而关闭不确定性。如果你想知道给定一些集合,两个节点是不是独立,只需要看看是不是那个集合是不是切断了所有的路径,非常简单。
13. 贝叶斯网Wolfram | Alpha的应用
13. 贝叶斯网Wolfram | Alpha的应用
Stephen:你最喜欢的因果模型或概率因果模型的应用是什么?我个人常常会建立一些工具,发明一些理论和其他东西,但我经常不知道这些东西实际上是怎么被其他人使用的。
Judea:我也不知道。人们曾告诉我,每个IPhone里面的输入信号的纠错机制实际上就是一个贝叶斯网,实际上他们具体怎么做的我不确定。
Stephen:是Turbo码吗?
Judea:Trubo码是一种贝叶斯网信念传播机制,有个加州理工的写了论文,说Turbo码是一种并行信念传播的特例。
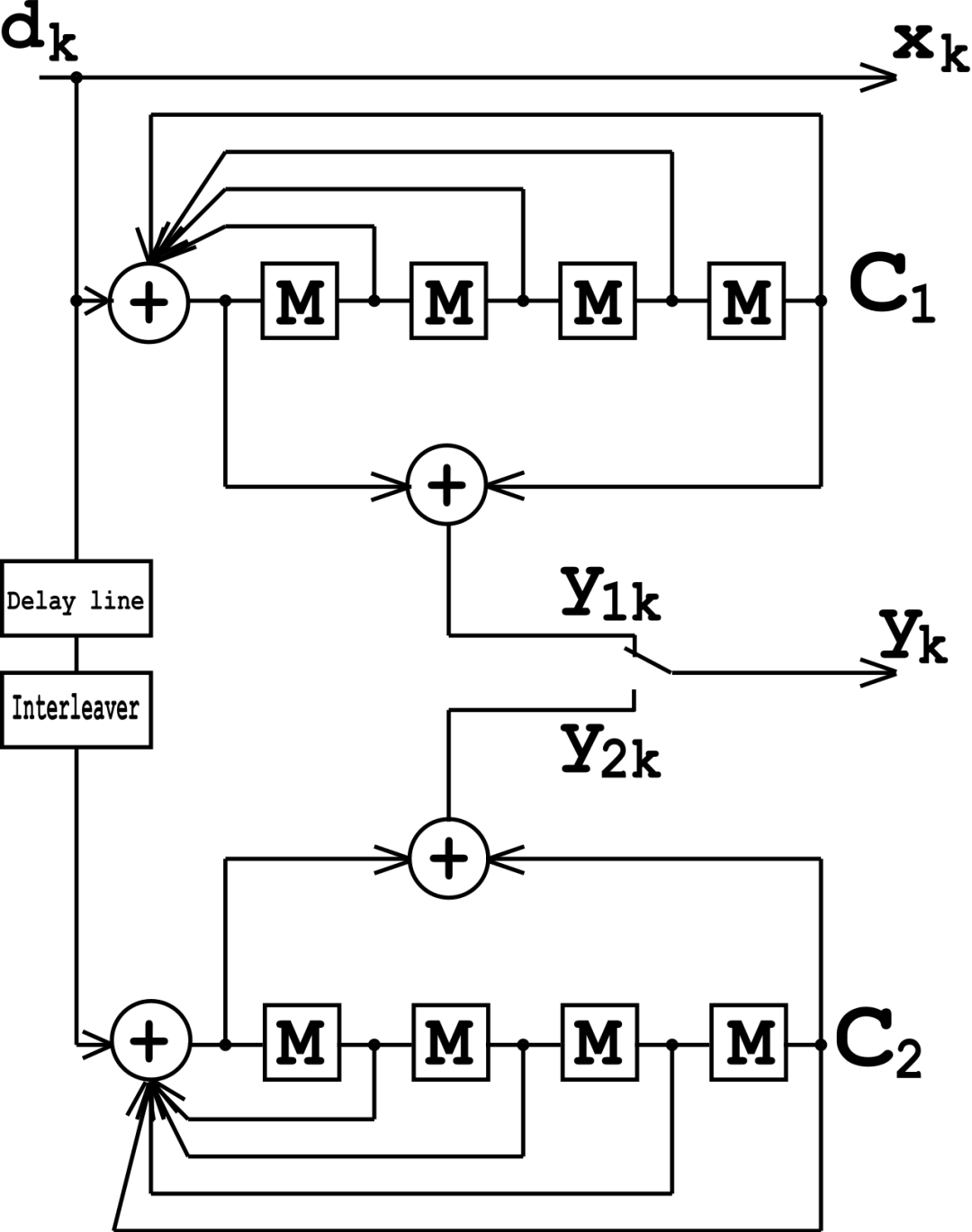
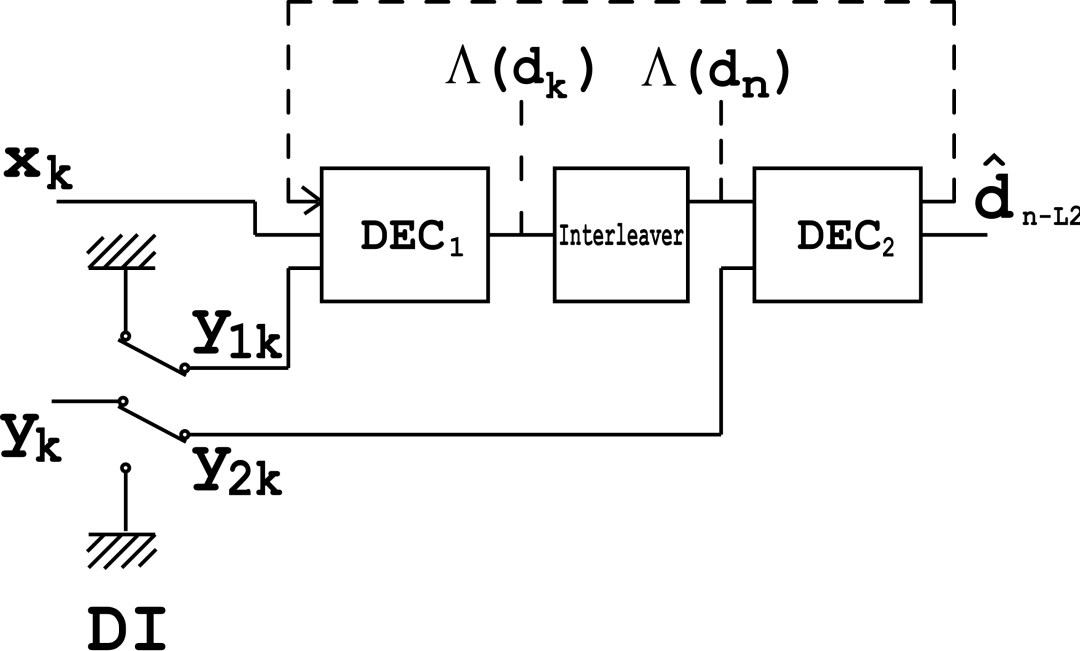
Stephen:所以贝叶斯网是他们解码器工作的方式,很酷。
Judea:还有人说siri也用过,但我不确定,应该是谣言。
Stephen:实际上,我可以告诉你,因为,原始的公司siri在SRISRI 国际人工智能中心,他们用我们的Wolfram | Alpha作为问题回答的方法,但是他们的前端是像贝叶斯网络的东西,它们用来猜测用户说了什么,我不确定是不是有评分还是什么,但它能工作。我想这可能是一种实现,因为在自然语言理解的例子中,我们经典的问题是,第十个质数是什么,我们的隐藏在下面的Wolfram | Alpha可以完美回答,他可以计算出来,但是有段时间,siri会告诉你最近的黄金排骨餐厅(prime rib restaurant)的位置,可能分析输入的概率方法有些问题,那很有趣。我们处理语言其实不是很概率的,我猜测应该是有特定概念,也许会进行打分。这是个好问题:如果我们思考我们自己的自然语言理解系统,一个人是否会按照概率传播的方式思考,实际上我不知道。

Judea:我也不知道,每当我发表了论文,到涉及应用时,我就没兴趣了,我开始关心下一个任务,下一个谜题。我对于人们怎么用我以前的结果丧失了兴趣,对我来说很没意思,当会谈时,人们问我这些东西人们是怎么用的时,我完全不知道。
Stephen:当你的东西被使用时,人们不必要发送一个邮件给你,说嘿,这是个很酷的技术,它用了你的想法,人们极少会发送这种邮件,不过有时当你走近他们的工作时你会发现它被使用了,但是这种邮件是很罕见的。
14. 自动科学家、个性化医疗和社会智能
14. 自动科学家、个性化医疗和社会智能
之后,Stephen询问Judea所认为的值得去做,且容易做的问题,并对每个问题和已有研究进行了对比,展开了详细的讨论。
Stephen:当你在致力于解决某些问题时,你是否有一个你想要接下来去做的问题列表?比如,这个列表是很久以前你计划去做,然后你终于有机会去做了,或者更像是,特殊的机会在此时出现了,接下来你可以去做了?什么是你目前在果园里看到的唾手可得的成果?
Judea:更像是后者,现在有很多机会出现了,有了这些工具,我们便可以做这些工作。目前我看到的是,一个是自动化的科学家,这是第一位的,我们可以做到这一点;个性化的医学,我们有足够的工具来做到这一点;第三个将是,社会智能,我们可以做到这一点。
社会智能
Stephen:我不知道社会智能意味着什么?社会智能是什么意思?
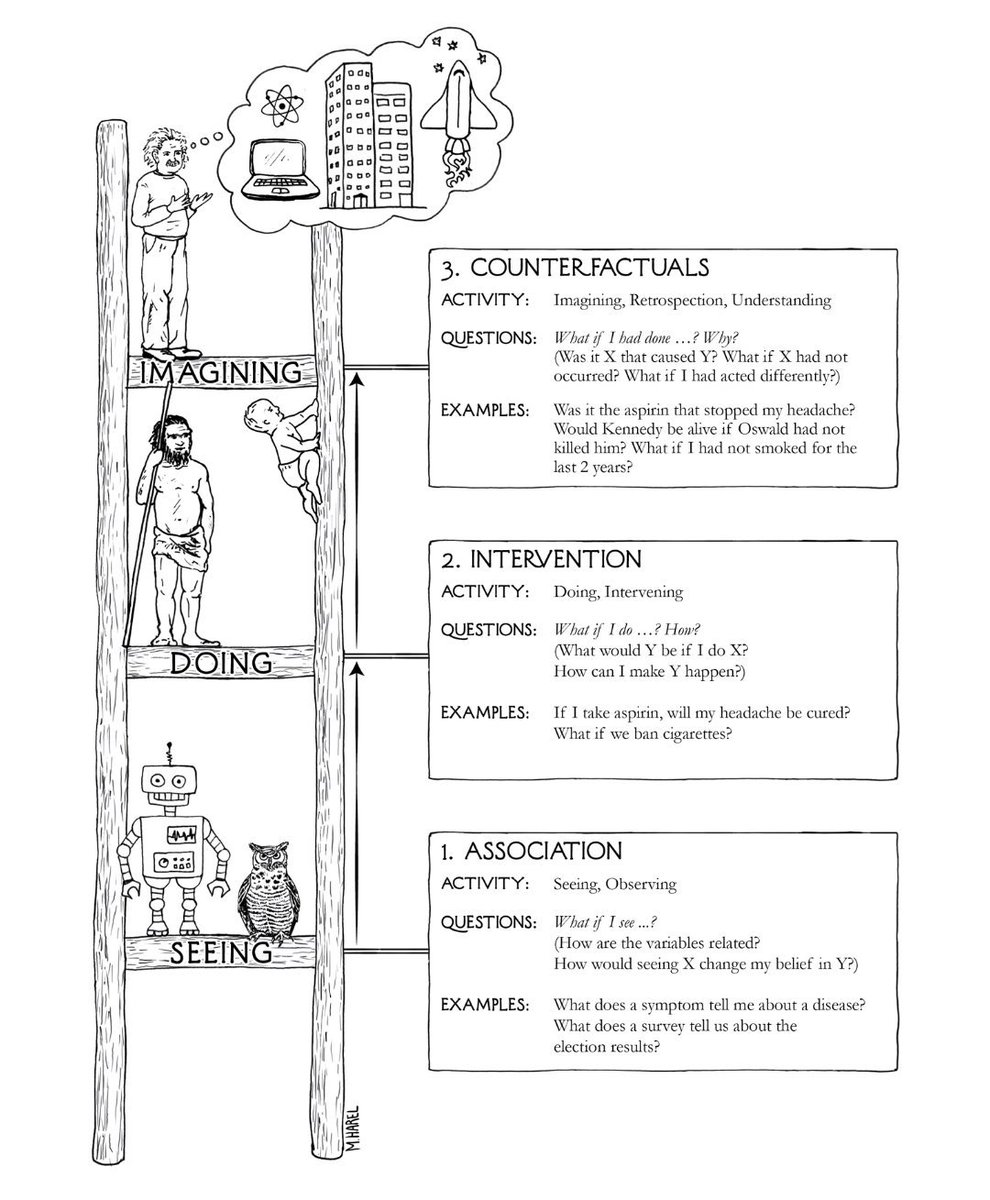
Judea:社会智能是一个知识系统,它能够回答在其词汇中具有人类关系的问题。 比如,信任,可靠,同情等。这些概念对我们是有好处的,这是我们从小到大的社会关系,我们对这些关系比对疾病更熟悉。我们是在这种关系中长大的,我们对母亲的微笑或皱纹非常敏感,所以这对我们非常重要。我们可能以某种方式对其进行编码,并以这种方式进行交流,这就是社会的发展和文化的发展,而AI界和计算机科学界都忽视了它,现在我们有工具来解决这个问题。为什么我这么说?因为我们现在有了深度理解的工具,我们正坐在一个金矿上,这是第一个我们可以对某个领域表现出深度理解的系统的第一个计算机模型,我对社会智能的定义,对社会智能的形式化是每一个在因果关系阶梯的三个层次上回答问题的系统都表现出深度理解,这意味着它理解关联,干预和反事实。
Stephen:所以,所以当你谈论社会智能的时候,这个系统将能回答这样的问题吗?如果你的社交网络设置正确的话,它应该能够回答这个人是否会决定购买我的产品或其他东西,或者这个人是否会和这样的人成为朋友?
Judea:朋友是社会智能的一部分,比如现在我给错误的结果,错误的建议,这个朋友是否会在未来信任我。“你意识到”,这一点意味着你有两种知识,一种是你可以获得的知识,另一种是明确被传授的知识,如果你熟悉这些知识,它就在你的工作记忆中被用到,所有这些关系都是我们社会对话的一部分,这些都应该被编码。我之所以说我们有这些工具,是因为我们对智能体和环境有深入的了解,利用这些了解,我们可以用一个智能体来增强另一个智能体。
Stephen:这有点让我想起了虚拟世界,比如《模拟人生》或其他什么的。《模拟人生》是一个虚拟的世界,里面有一些人与人之间的互动。我认为实际上它们的那种算法基础是你所说的那种东西的简化版本。
Judea:我不了解也没玩过《模拟人生》,那是谁写的?

Stephen:是个在我的公司工作了一段时间的小伙子,直到他写《模拟人生》,我才认识了他。《模拟人生》是EA公司的游戏,但它是Will Wright写的,他是这个游戏最初的游戏设计师。我承认我不是一个游戏从业者,我只是一个游戏的观察者,但是,我和这个小伙子在一家公司工作了一段时间,他是一直负责那个游戏制作的人。当时,我总是给他一个难题,因为我认为他在现实生活中的行为很像《模拟人生》中的模拟人,给了这些输入,他就会做这样的事情。
Judea:希望这个游戏系统会更复杂,而不是基于规则,然后在上面仿真人们之间的关系。
自动科学家
Stephen:让我们回到自动科学家的问题,我认为你是不是在说,这里有很多的数据,它能在数据里发现很多关系?
Judea:不是,你在说的是关联层的问题。
Stephen:是不是回答这样的问题,如果这个发生了,那么会怎么样?
Judea:科学家考虑的是,为了区分两个具有竞争力的假设,我接下来应该做什么实验。首先,他有一些假设,还有一些问题,如是否应该以这种方式治疗病人。我们需要从以下两种方式中决定,接下来需要做什么实验,或者是否需要为了观测花钱,因为研究会有很多代价 ,这些是科学家每天思考的问题。
Stephen:所以你是在说自适应实验设计吗?
Judea:自适应的,且是自动的,由理论所驱动的。我们需要编程在研究中注意力的管理机制。
Stephen:人们在油田钻井或者其他挖掘工作时,他们会有一套算法框架,来决定需要在哪钻井来得到最多的关于这一片区域有没有石油的信息。


所以,你所说的是给定确定的,已存在的知识体系,询问做什么实验可以最大化额外的信息量。比如,当你在建立一些像是K-d Tree的事情,什么样的切分可以使我能够最大程度地区分这边和那边。
Judea:是的,这两者有一定关系,但这个涉及的更多。因为这个是建立在关于因果知识的先验上的,除非有一个理论能告诉你你能从那个实验中获得什么,否则你不能讨论下一个实验是什么。这是关于信息量的一个想法。只有当你有一个理论能够告诉你实验的预期输出是什么时,你才可以形式化这次实验或这次观察的信息量。所以,将这一理论运用到实践中,就可以得到一个自动科学家。
Stephen:所以,你所想的是,通过了解概率分布,最大化某种熵?如果你问了这个问题,接下来,这里肯定会有什么准则。
Judea:所以你下一步的决策就会在这种准则的意义上带来最大的信息量,比如,这种意义是最大可能治好某个特定的患者。注意,即使当问题是询问治好的最大可能时,这个问题也仅有30年时间进行形式化的工作,“治好的最大可能”意思是最似然的(诊疗)动作序列对应的治愈可能性最高。这种询问你的动作产生的结果的问题是新的,仅仅有30年的历史。
个性化医学
Stephen:当你思考个性化医学时,一个问题是,美国食品药物管理局(FDA)有某种准则,来决定是否通过某种疗法。如果变成个性化的疗法,那么概率空间将会天文数字般增加。所以,你有什么办法吗?比如,嗨,FDA,我这里有一个贝叶斯网,然后,你怎么说服他们?您如何评价做临床试验的传统方法?

Judea:个性化医学或者个人行为决策是一个全新的话题,我会简单介绍一下。对某个总体进行随机实验来通过一个药品,和回答一个特定的个体吃了这个药会怎么样,是不同的。比如,在随机实验中,你发现这个药在总体上没有效果,这意味着在每个案例,每个分支,安慰剂和药都有10%的hearing。但你不知道是这个药品对于每个个体的作用都是0,还是说它杀死了10%的人,又治好了另外10%的人。这意味着,在总体中的个体,从来不知道他自己会不会被这个药杀死,你所知道的只是它对总体的性质。现在,我们要改变思维,讨论的是个体的反应,这个特定的个体将会从这个药品中获益的概率是什么?总的来说,这是一个涉及反事实思考的新的游戏。反事实是将思考层次从总体变到个体的一种方法。所以,这是一种新的算子(calculus),一种新的准则,一些新的技术。我强烈相信,现在我们有能力谈论个体情况,消费个体,投票个体,也许是比较危险的话题,但这些都是可以做到的。另一点特殊的是,是不是有实验数据和观测数据的组合。只有通过这种结合,我们可以获得一些它们各自单独不能得到的东西。个性化医学是关于个体行为的知识。
Stephen:我在理解你说的意思,作为一个个体,你有很多的特性,比如年龄,血压等等,你会得到一个向量,可能会有几百个,来表征你的医学状态。有些人会做一些试验,把进入试验的人塑造为一个总体,来搞清楚某些东西,其中一个隐藏的统计学秘密或类似秘密的东西是,我们不知道到底在试验中的某种规则是什么(所以才会做试验)。假设有了一个试验,对于试验中的每个人,你都知道他们的这个医学向量,所以你会怎么做,你想要问的问题是什么?
Judea:传统的方法是选择一些总体,总体中的个体尽可能相似,所以它们其实是共享一个这样的医学向量,比如家族病史之类的。然后在这个子总体上计算和执行一个随机实验,看看治疗组和控制组的不同,从而知道个体被治好的概率,所以,现实中并没有到涉及到个体层。我的意思是,有一个100维向量,可能会有男性女性,60岁以上和60岁以下,但是从来没产生过这样的随机实验,因为这样的变量有上百个。Cell数量是天文数字,每个Cell里的样本都很少,这很难,不能这样推广和泛化。但是神经网络做这一点很好,他们能够在稀疏数据上拟合函数,但是我不是在讨论这一点,神经网络是一种传统的方法,因为这不是关于个体的,而是关于子总体的,子总体内的个体都相似,这是不一样的。个性化医学给了我们新的问题,我们可以谈论,在不同的子总体中,给定我们在这个子总体中发现的其他个体时,这个个体的期望行为,我们谈论的仅仅是这个个体会被治好还是被杀死。他会从这种过程中获利,还是从另外一种过程中获利。可以简单对个体分成这几类:不管吃不吃药都会治好,只有不吃药才会治好,只有吃药才会治好,吃不吃药都不会治好,然后我们可以计算某类个体中的概率上下界,然后告诉这个个体,是不是要冒险进行治疗,把这种风险告诉他或他的家人。
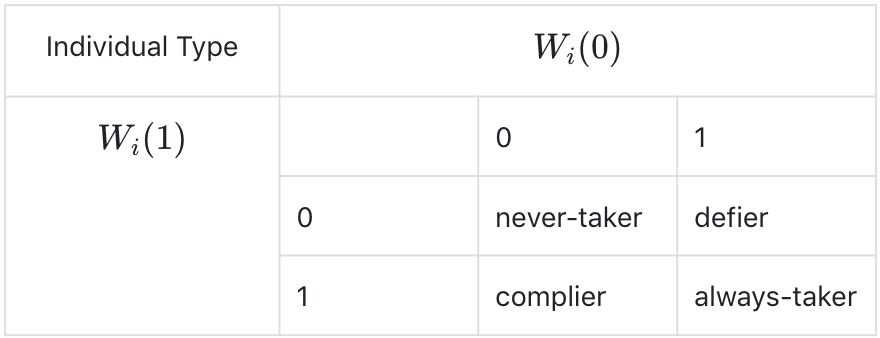
Stephen:你有放入某种独立于统计学观测的你认为是真实的某种因果模型吗?然后你在模型里填入统计观测。
Judea:这个不是人所认为的因果模型。它来自于两种数据:一种是你可以在某个总体中去做的随机控制试验,另一个是当它们有机会时,个体依据自身偏好所进行的行为,这种被叫做观测数据,如,发问卷,打电话,即所了解到的他们按照自己的意愿所做的事情。两者结合可以给出单独一个所不能给出的信息。
Stephen:在医学试验中,可以分为被要求服药或不要求服药,为了这么做,需要有一个试验片被选取出来,这是怎么做到的?因为正常情况下,总体会被划分为两部分或者更多。
Judea:我们并不会把总体分为两部分,我们观察他们有选择时,他们去药店购买这种治疗时的数据。
Stephen:等一下,在药品试验中是所有人都是一无所知的,包括科学家,医生,患者,没人知道会发生什么(给药的医生、服药的患者、数据分析者,单方面都不知道自己行为的实际含义,无法预测试验结果,从而避免带入暗示效应,心理作用和分析偏见),比如这个药品有些问题,很难被肾脏清除等等。
Judea:我们假设这个药品被FDA通过了,上市了,那么患者有购买或不买的自由,但这里有很多流言,比如有人说这个药有副作用,他叔叔就这么死了。他们建立了自己的观点,来决定是否购买和使用这种药品。做个调查,看看自愿选择买药的人结果怎么样,比如有些人死了,有些人被治好了。把这个数据和随机控制试验中的数据结合起来。在随机控制试验中,治疗组病人是被强制吃药,控制组病人是被强制不吃药的,然后你强制让另外的人吃安慰剂,等等。你把这两类数据结合起来,包括自由选择的数据,强制治疗的数据,我们有可以这么做的calculus,然后我们就能从数据结合中得到更多的信息。
15. 新冠疫苗个性化效果评估
15. 新冠疫苗个性化效果评估
之后,Stephen对于Judea的工作如何在现实中应用和产生影响进行了讨论。
Stephen:下面是一个有争论的话题,关于Covid-19的疫苗问题,比如有一些疫苗试验,还有一些人们自由注射或不注射疫苗的数据,你可以把它用到这种情境下吗?假如你有了很多疫苗,而且能够做标准的随机控制实验了,你会怎么做?你还有数据,比如某些比例的人自由选择了注射疫苗,有些人被强制注射疫苗,而且他们的数据你都有,还有最后的统计结果。比如选择注射疫苗的人中,是否恢复了健康,是否感染了,在多长时间后恢复或感染的,在哪些病重的人中,哪些接种了疫苗哪些没接种,这些数据在入院记录会有。
Judea:应该可以。但我没有资源做试验,我和试验派的人打了赌,他们说这绝对不会有用的。我不会在这里深入计算的细节,我直接告诉你我能从这两类数据得到的结果:某个特定的人因为注射疫苗而获益的概率,某个人因为药品而被杀死的概率。
Stephen:等等,到底是在哪里产生了更多的信息?为什么这个会比随机控制试验的信息量更大呢?
Judea:因为某种意义上,你对自己的系统更了解。
Stephen:所以这个信息来自于病人对于自己的系统的了解。这个假设有点……怎么说呢,我必须说一下,这有点像是医学的元理论,在大部分医学领域中的假设是,绝对不可以相信病人知道任何东西(任何数据和知识)。看上去,你的假设和这一点是相悖的。
Judea:这是给你提供这些额外信息的成分,这些东西能让我们触及个体层次。
Stephen:等等,这种自我感知的信息和知识,万一是基于网络上某种疯狂的阴谋论呢?
Judea:假设你的堂弟患病了,还有一些副作用,你还在网络上听到一些其他流言。如果你的决策是基于某种错误的理论,这依然是某种输入,“某人认同某种疯狂的阴谋论”这种输入本身就蕴含信息,我们可以进行正面的使用。
Stephen:所以,人们的自由选择就是额外信息,但是在传统的三期临床试验中没有这种信息。这一点不错,但是,我想医学界肯定会对此非常反感,因为他们认为“医生知道最好的方案”。我觉得,你应该找人在类似疫苗的事情上真正的去做这件事,这种数据肯定是有的,我印象中以色列有很多数据。
Judea:是的,他们有中心化的医疗系统。
16. 如何支持研究并让研究产生社会影响
16. 如何支持研究并让研究产生社会影响
接着,Stephen想要了解Judea如何支持自己的非应用的研究想法,并使得自己研究间接产生社会影响的方法论。
Stephen:之前你提到,你对于人们对你工作的应用并不是很感兴趣,是不是有这样的例子,人们看了你的论文或者书,然后成功的使用它?我这里有几本你写的书,《为什么:因果关系的新科学》,《因果关系:模型,推理,推断》和《智能系统中的概率推理》,还有一本《启发法》。我很好奇,你是怎么找到这样的方法论,当你有了想法后,能把他们在现实社会中翻译成实际的实现?(你获取研究资金和将研究在现实中产生影响的方法论是什么?)


Judea:我不是很理解你的意思。亚马逊如果想要广告最优化的话,或者缓存替换等问题,他们应该用反事实。如果能够可以处理个体层的事情,对于很多公司来说都可以节省很多钱。
Stephen:有些人是这样做的,先培养一连串的学生,然后这些学生也许会去亚马逊做教育培训,或者从事一些咨询工作,或者从事软件开发创业然后卖掉公司,等等。你用过类似于这种策略吗?
Judea:没有,我是发表论文,希望一些亚马逊的智慧的管理者能够看懂这样做可以产生多大的经济价值。也许他们已经在这样用了。
Stephen:不过他们不会告诉你他们用的什么工具的,很少有人会发邮件告诉你,嘿,我用了你的东西很成功。
17. 因果之梯中的不确定性
17. 因果之梯中的不确定性
之后,Judea给Stephen讲述了因果之梯的基本想法,Stephen指出Judea的想法可能会对于mutil-way system不生效,并且再次讨论了概率式的不确定性的来源。(因果之梯的更多详细介绍可以参考《为什么:因果关系的新科学》)
Judea:当我们谈论因果问题时 ,我们可以把问题分为三类:一类是统计问题,主要是条件概率,现在的机器学习一般是在做这件事。第二类是如果做了某事会怎么样,这个是干预层。第三层是如果某事发生会怎么样,一般在现实中不存在,比如如果我没参加这次会议会怎么样。这个是先有了一个结果,然后如果改变过去的某个条件,这个结果会怎么变化。
Stephen:为了实现某一层,每一层需要多少额外的建模?
Judea:我们需要逐层回答这个问题,因为我们需要不同的输入。对于关联层,统计数据总是很好的;对于干预层,我们需要随机实验;对于反事实层,我们需要变量之间的函数型的赋值关系。比如在贝叶斯网中,我们有概率表,这是不够的,即使做了随机实验也是不够的,我们需要某种赋值关系。
Stephen:如果因果之梯继续的话,你可能会在mutil-way system停止。我的理解是,问题是概率从哪里来的。
Judea:你可以把概率放在内生变量上。
Stephen:所以在系统内,所有东西都是决定论的,对吗?
Judea:是的。一旦你知道了所有的隐变量,所有的外生变量,所有的噪声项,我们都给它们起个名字,尽管我看不到它们,我也不知道它们是什么(未知的),但它们是承载了这种多样性。
Stephen:当没有概率时,有很多变量,它们是各种决定论型的函数,它们会彼此连接,会有个确定性的网络给定输入时,给出确定的输出,然后你把其中一部分隐藏起来。
Judea:是的,这是种好的模型,这是理解不确定性来源的一种想法。
Stephen:我要强调的是,当你谈论噪声时,会有更多信息。当这个原始的决定论型的网络给出时,你隐藏了一部分,问题是你应该怎么参数化隐藏的部分。当我问你时,你认为可以用噪声来参数化,你认为噪声来自隐藏的部分,这个模型肯定不是一个完备的模型。当你说它们将会有关联时,它们有噪声时,比如,有两个地方可以插入噪声,你可以说这些噪声是独立的,因为它们仅仅是概率,但是在现实中,这两个地方是有关联的。
Judea:但是如果你不假设独立,那么就不能消除某些东西。
Stephen:我在尝试爬到你的梯子的下一层上。
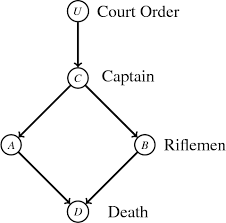
Judea:以队长-火枪手-囚犯为例,火枪手a或b射击,囚犯就会死亡,然后有个队长会给它们下命令,整个图是钻石形状的,这是个决定论型的图,假设了每个火枪手都会严格执行法律,都是清醒的,在此基础上我们可以问具体的干预问题和反事实问题。例如,我们知道囚犯死了,那么我们想知道如果火枪手a不射击会怎么样,囚犯会不会依然死亡?这是个反事实问题,我们可以从这个决定论型的模型中回答。
Stephen:在这种情况下,答案是那个火枪手被解雇(the answer is rifleman be fired)。
Judea:我们怎么知道它被解雇了(how do we know it’s fired),因为囚犯死了,某些人在那里。顺便一提,你不能用命题逻辑回答,因为命题逻辑是等价于下边的东西的,每个人都看作二值变量,这里有四个人,会有四个变量,然后有一个全部组合的真值表。
Stephen:打断一下,问题是,这是一个程序,还是某种静态的东西?
Judea:这是某种程序,你明白了。火枪手a在等待队长的信号,这个队长决定他的行为,或会给他的行为或赋某个值。这是一种赋值,而不是命题,不是经验法则。一旦理解了这点,我们就在这类事情中了,现在你可以回答各种反事实问题,但是我们有一种calculus来做这件事,所以你给我各种决定论型的关系,各种各样的证据,变量的各种各样的真值,我就可以回答这个事件如果没发生会怎么样。
18. 元胞自动机中局部观测、干预和反事实
18. 元胞自动机中局部观测、干预和反事实
Stephen展示了元胞自动机,谈论了元胞自动机系统中基于局部观测推理导致的推理不确定性,Judea和Stephen讨论了反事实在Stephen的元胞自动机中的体现。(更多信息可以参考Stephen的2002年的《一种新科学》以及对应的网站https://www.wolframscience.com/,关于反事实的更多内容,参考《因果论:模型、推理、推断》)
Stephen:假设某种布尔网络,上面是输入,下面是输出,有某种数据流经这个布尔网络,每个节点都由某种布尔函数决定,这可能和你的依据概率决定有点不同。所以对应于这个布尔网络,都有对应的颜色表示他可能的时空历史,如果我没猜错的话,当给定了网络的输入顶点时,网络的剩余部分就完全确定了。我花了数十年来研究元胞自动机,它很像是以这种方法工作的。稍等,我给你看下我最喜欢的科学发现,可能和你的工作有点无关。
Judea:那么我们之间的交流的连接应该是你想让你的这个系统回答什么问题。
Stephen:举个例子,

译注:该元胞自动机的纵向维度为时间
这是一个系统,这个系统每一行都有很多元胞,每个元胞是黑或白。这里有某种规则,基于它的邻居元胞的状态,来确定下一步这个元胞的颜色是什么。令人大大惊喜的是,即使它是从一个黑色的元胞开始,即使规则这么简单,它依然可以生成复杂的图案。
Judea:但是这种复杂的东西是完全由初始条件和规则来确定的。
Stephen:是的,就我所知,这个应该和你的东西一样吧?
Judea:我想想,是的。
Stephen:稍等,我找个例子。稍等,我换一个例子,

这个图里是在说,如果你在某些步骤后看到了某些东西,你能否重建出其他地方发生了什么吗?换句话说,如果你看到犯人最后死了,你能说之前一定发生过什么事情吗?
Judea:哦,也许不止如此,如果你看到犯人在最后死了,是对应图中的如果这个方块是黑色的话。但你说它不可能是黑色的,因为根据规则,它必须得是白色的。我是说你破坏了规则,我现在在破坏规则。我的问题是说,如果那个枪手,即使他得到了队长的信号也不开枪,我打破了数据的产生规则。
Stephen:好吧,我不明白你的意思。我所理解的是,你有一个布尔网络,你可以问这个问题,如果你看到布尔网络中的某些东西,比如如果 你在布尔网络中看到了某些输出,然后,你就可以做出某些决定论型的推论,或者你可以做出某些推论,它们可能不是决定论型的。它们可能是你所看到的东西完全决定了网络的其余部分,也可能是它们可能不足以完全决定网络的其余部分,或者说也可能是你看到的那个东西仍然留下了一堆未确定的网络的其余部分的特征。
Judea:为什么在你的元胞自动机的情况下,它们是不确定?
Stephen:我在这里展示的是在前向的演变之前,系统绝对是确定的。所以换句话说,给定一个初始状态,我们绝对知道接下来会发生什么,因为我们有这样的规则,这个规则说这个元胞的颜色是基于之前的元胞,等等等等。但这个特别的例子是说,假设我们只知道中间那一列的这些单元格的颜色,那么我们能知道系统其余部分的情况吗?左上角那个图的意思是如果我们知道两个相邻的列,我们就能完全确定所有在左边的东西。这表明我们确定了一定数量的节点,比如如果我们有关于中间那一列的信息较少,我们就会确定一定量的关于左边的东西,但其中有些东西,只是有一定的概率确定的。这和你说的一样吗?这和你说的是同一种东西,还是说这不是?
Judea:不,这是不一样的。我说的是打破规则的问题。那么,我从遵守规则的火枪手开始说起,然后我说,如果一个火枪手就喜欢扣动扳机而不是听命令呢?尽管我打破了规则,但它仍然会决定将会发生在囚犯身上的事情,对吧?
Stephen:如果你认为你有某些规则,然后你说,实际上,那些火枪手可能会互相攻击并互相射击什么的,然后,囚犯就会存活或怎么样的。
Judea:你有破坏规则后的规则,这意味着你只能在局部地破坏规则。比如如果你有这样的问题,如果火枪手倒下睡觉会怎么样?你会假设所有其他的系统部分仍然完好无损,这些部分是根据之前规定的规则。
Stephen:我明白了,就像在一个错误的纠错代码什么的,有一个位的错误,或者有一个地方出了问题。那么问题来了,这是什么类型的错误?这些地方的位错误有影响还是其他什么?
Judea:是的,这就是我们交流的方式。

我给你举个例子,如果我说如果Cleopatra有一个不一样鼻子,世界的历史就会改变。你可以想出一些结果,比如那么Julius Caesar就不会爱上她了。但这样你就可以开始计算出一些东西。但不管是什么,这都是局部的改变,这个意思是只有她的鼻子改变,而不是Antonio的性格,或是Octavius性格,而不是我们所知道的其他关于历史的一切。只有她的鼻子改变了。这种想法是局部的反事实,反事实的解释必须是相对于你所拥有的模型的局部变化而言的,它不能是其他一切东西都发生变化,比如他们的武器系统改变了。所有东西都改变这不是我们解释反事实的想法。比如当我说如果火车准时到达,我及时上了火车,我就能赶到会议,我们就能做一笔大买卖,我是说在宇宙中唯一允许我改变的是火车及时到达,其他的都必须保持不变。
Stephen:拿一个简单的例子来说,如果世界是线性的,如果所有的关系都是线性的,那么那一个变化就会产生这种叠加态,你只是叠加了那个变化的效果,而所有其他东西都是一样的。所以事实上这是一个非平凡的问题,因为世界不是线性的。如果只有线性,如果每一个变量关系只是线性,如果你只是说你改变这个变量的话……
Judea:但我不相信线性的说法, 即使是非线性的函数或赋值机制,你也必须使这种关系不受变化的影响,使得某些机制是稳定的。即使函数是非线性的,你仍然必须使某种关系对这个变化不产生影响,使得某些机制是稳定的,对其他机制的变化不产生影响。这就是我们所说的不变量,我所说的稳定性。火枪手A的行为与火枪手B的行为是不同的,他们是独立的,一个人可以睡觉,另一个人不睡觉。当给定子弹这一条件时,囚犯的行为与火枪手如何听从队长命令无关,所以这些是不同的机制,这就是反事实背后的想法。
Stephen:但是,我的意思是,一旦事情发生了,就会有一种锥形扩散的结果。
Judea:是的,但是改变只针对那个结果,改变发生之前的过去是一样的,这很重要。
Stephen:我是说你在描述一种处理事情的方式,你说如果我们做一个改变,那么你就可以有一个calculus来描述一个改变的后果。好的,这很有趣。我的意思是,我在试图思考。
Judea:哈哈,你好像在寻找这个东西的应用。
Stephen:我在试图把它融入到我所知道事情中去。我的意思是,像纠错码就是一个例子,你可以理解一个比特变化产生的影响。
Judea:可以多想想动作(行为)。当我告诉你,你把墙涂成红色时,我不是说你把墙涂成红色,然后去谋杀你的表弟。我的意思是只做这个,只做那个,所以整个关于行动和干预的对话都依赖于这个局部性。
Stephen:所以会有关于世界的模型,一旦你把房间刷成红色,那就会不可避免的产生后果。
Judea:是的,而且过去的情况没有改变,而且你表弟的生活也没有改变,因为他与房间的颜色没有任何关系,对吗?
Stephen:但我的意思是,那些可能受到刷房间颜色所带来的前向影响的东西,我不一定知道这些受到这种前向影响的东西会是什么,也不必要知道(反事实在所谓唯一真实的物理世界中的意义不明)。
Judea:为什么会不知道呢?如果你有一个模型,你就知道了。
Stephen:好的,如果我有一个模型我就知道了。是的,我明白了,这非常有趣。好吧,我们到了因果之梯的顶端,所以这可能是一个信号,我们应该把这个结束了,这非常有趣。
19. 结束语
19. 结束语
Judea:非常感谢你们抽出时间来采访我。哦,对了,我的第一篇关于反事实的论文就发表在AI和数学的论文集,在一九几几年发表来着,我忘了。
Stephen:你现在已经有多少篇论文了?你有没有数过?
Judea:我想大概有500篇吧,学生论文,合作论文等等。
Stephen:非常令人印象深刻。我想我们应该结束了,我们应该怎么结束呢。多谢您参加这次会议,至少对我来说很有意思。
Judea:谢谢你,我知道你会把我引向我想走的正确道路,而不是我想去的过去没有走过的路,这是另一个反事实的概念。
Stephen:我其实对太多的反事实没有非常感兴趣。我们应该结束了,我想他们的会议可能要结束了,我们已经进行了很长时间了。
主持人:我并不讨厌看到你们,那么,我代表会议的组织者,感谢你们两个,非常感谢这个非常长而有趣的采访,还可以再长一点,因为我看到你们两个人都有很多精力继续,但是三个小时之后,我想观众会很乐意休息一下,但是如果你们想在另一个机会再继续,我们很乐意再安排三个小时,时间过得很快。非常感谢Judea和Stephen。
参考资料
-
Reichenbach H. The direction of time[M]. Univ of California Press, 1956.
-
Pearl J. Heuristics: intelligent search strategies for computer problem solving[J]. 1984.
-
Pearl J. Probabilistic reasoning in intelligent systems: networks of plausible inference[M]. Morgan kaufmann, 1988.
-
Wolfram S. A new kind of science[M]. Champaign, IL: Wolfram media, 2002.
-
Judea Pearl. Causality: Models, Reasoning and Inference. Cambridge University Press. 2013.
-
Bareinboim, E., Pearl, J., 2016. Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences 113, 7345–7352.. doi:10.1073/pnas.1510507113.
-
Pearl J, Mackenzie D. The book of why: the new science of cause and effect[M]. Basic books, 2018.
-
Imbens G W, Rubin D B. Causal inference in statistics, social, and biomedical sciences[M]. Cambridge University Press, 2015.
-
Elnaggar A A, Gadallah M, Aziem M A, et al. A comparative study of game tree searching methods[J]. International Journal of Advanced Computer Science and Applications, 2014, 5(5): 68-77.
-
van Rooij R, Schulz K. Natural kinds and dispositions: a causal analysis[J]. Synthese, 2021, 198(12): 3059-3084.
-
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.
-
https://isaim2022.cs.ou.edu/
-
https://www.wolframphysics.org/
-
https://www.wolframphysics.org/technical-introduction/the-updating-process-in-our-models/the-role-of-causal-graphs/
-
https://www.wolframphysics.org/technical-introduction/the-updating-process-for-string-substitution-systems/events-and-their-causal-relationships/
-
https://www.wolframphysics.org/technical-introduction/the-updating-process-for-string-substitution-systems/foliations-and-coordinates-on-causal-graphs/
-
https://www.wolframphysics.org/visual-summary/dark/
-
https://www.wolframscience.com/
-
https://www.wolframscience.com/nks/p27–how-do-simple-programs-behave/
-
https://www.wolframscience.com/nks/p604–cryptography-and-cryptanalysis/
-
https://www.wolframscience.com/nks/p605–cryptography-and-cryptanalysis/
其他图片来源
https://www.wolframphysics.org/
https://www.wolframscience.com/
https://en.wikipedia.org/wiki/The_Book_of_Why
https://en.wikipedia.org/wiki/Causality
https://en.wikipedia.org/wiki/Will_Wright_(game_designer)
https://en.wikipedia.org/wiki/Hill_climbing
https://en.wikipedia.org/wiki/Walsh_function
https://en.wikipedia.org/wiki/Expert_system
https://en.wikipedia.org/wiki/Food_and_Drug_Administration
https://en.wikipedia.org/wiki/Cleopatra
https://en.wikipedia.org/wiki/Lawry%27s_The_Prime_Rib
https://zh.wikipedia.org/wiki/%E6%9D%BE%E5%9F%BA%E4%B8%89%E4%BA%95
http://bayes.cs.ucla.edu/WHY/why-ch1.pdf
https://math.stackexchange.com/questions/1393848/bayesian-network-query
https://mp.weixin.qq.com/s/RWnbX5sn4RJS-tFmJnm9Tw
【科研小技能】漫谈前瞻性、随机、开放标签、盲终点(PROBE)试验
原会议视频链接:
https://www.youtube.com/watch?v=230PsGBxkCo
因果科学读书会第三季
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办。读书会社区长期开放招募。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
贝叶斯网络之父Judea Pearl推荐:迈向可解释的知识驱动系统 -
贝叶斯网络之父:如何真正教会机器理解 -
什么才算好的解释?贝叶斯框架下给出的四个评价标准 -
Wolfram长文全译:从简单规则到系统物理学 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











