第二种想象力:社会科学中的因果推断

导语
在《社会学的想象力》一书中,社会学家米尔斯强调研究者要把个人经历和社会整体联系起来,呼唤一种“社会学的想象力”。在当下,我们应该如何完整、科学地理解“社会学的想象力”?如何把数据、模型算法、因果逻辑与社会理论更好地连接?这需要“社会学的第二种想象力”。
在集智俱乐部「因果科学读书会」第三季,南京大学陈云松教授从“因果”和“数据”两个维度,用因果推断、大数据和机器学习等方面的系列研究案例,阐释第二种想象力的八类思维面向。本文是此次读书会的文字整理。
研究领域:因果推断,计算社会学,机器学习

陈云松 | 讲者
周俊铭 | 整理
邓一雪 | 编辑
美国社会学家查尔斯米尔斯在1959年提出“社会学的想象力”这个概念,他强调是,研究者要把个人经历和社会整体联系起来,把个人体验和历史经验转变为社会学的议题。不过,米尔斯版本的社会学想象力,虽然有助于提出学术概念和理论因果假设,但却无助于验证假设和理论体系的扩展。此外,米尔斯习惯用诗意笔法来描绘想象力的内涵,但对于提升社会学想象力的具体学科路径,却言语暧昧,仅在书末附录中就质性研究方法,以他自己批评过的工程师式的笔法,寥寥数页匆匆带过。在互联网时代、信息时代、数据时代,我们呼唤一种基于理论、数据和方法的“第二种想象力”。这新的社会学想象力,具体而扎实,体现在定量研究的八类思维。
一、横向思维:拓展关联
一、横向思维:拓展关联
通过横向思维,我们对传统社会学理论作平行延展,有可能发现新的社会现象关联。以“维特效应”为例,当我们观察到“阅读自杀小说—模仿自杀行为”的社会现象,并接受了这一理论假设,我们可以进一步就这一关系进行内延和外展:比如“阅读小说—个体抑郁—模仿自杀”和“阅读小说—模仿自杀—出台预防政策”,前者是内延至个人的心理因素,后者是外展至社会治理的政策措施。
二、纵向思维:理解跃迁
二、纵向思维:理解跃迁
跃迁是指传统的社会学理论在解释层次上的垂直变化,科尔曼之舟就是最直观的体现。当然,在空间或者时间上都可以进行,可上升也可下降。如果我们从空间上拓展维特效应,可以尝试研究美国“自杀小说销量大的州,自杀率是否更高”。从时间序列分析沉降到面板分析,从个体微观分析跃迁到宏观分析,都是典型的跃迁。
三、逆向思维:定量扎根(数据扎根)
三、逆向思维:定量扎根(数据扎根)
借助机器学习的黑箱拆解,我们可以采用定量研究的方法进行扎根研究。具体到因果关系,对于给定的“果”Y,当我们从数据中找出对预测贡献度大的系列X,从中筛选出理论。我们的团队已经提出了具体的算法路径和案例。
为了拆解机器学习算法模型的黑箱,目前可用的指标包括:置换特征重要性、沙普利值、部分依赖图。找出最具预测力的变量,就有可能产生新的理论。
[1] 陈云松, 吴晓刚, 胡安宁, 贺光烨, & 句国栋. (2020). 社会预测:基于机器学习的研究新范式. 社会学研究(3), 25.
[2] Chen, Z., Guo,W., Chen,Y.(2022) Developing Social Theory Using Data-grounded Approach: An analysis framework, working paper
四、外生思维:识别因果
四、外生思维:识别因果
受到成本和伦理的限制,社会科学的定量研究基本上不可能做实验,而是采用潜在结果框架的因果模式,通过对抽样调查的问卷数据作回归,分析回归系数的统计显著性。关联的思维本质上也是一种解释世界的方式。例如,《晋书五行志》记录了皇帝施政和五行现象的相关关系,但古代人们还不理解自然现象的科学机制,有系统的理论,但无法形成真正的机制性解释。直到最近十年,中国社会学界才逐渐认识到内生性问题,即“相关非因果”。内生性问题主要产生四种偏误:遗漏变量偏误,自选择偏误,样本选择偏误,联立性偏误。其中后三者可以视为遗漏变量偏误的变体。
解决内生性问题,社会学常用以下6种方法:(1)代理变量,比如用IQ数值作为个人能力的代理变量。(2)固定效应,这种方法的原理是,多次观测同一个体,再把估计结果作差分,就消除去不随时间变化的遗漏变量。(3)工具变量,寻找和Y无关,但和内生的X相关的变量。(4)赫克曼两步法,可以用来处理样本选择偏误。(5)双重差分(6)断点回归。此外,实验和匹配,也是目前社会科学的常用方法。当然,PSM不能解决遗漏变量问题。
[3] 伍德里奇, & J.M.). (2014). 计量经济学导论:现代观点(第5版). 清华大学出版社.
五、具象思维:数据测量
五、具象思维:数据测量
传统的社会学定量研究主要着眼于个体状态对个体结果的影响,这可以考察微观层面的因果关系,例如个人收入对个人幸福感的影响。但是在宏观层面,却缺乏对于集体状态和集体结果之间的因果关系的研究,这是受宏观层面的可观测数据不足所制约。直到进入大数据时代,传统问卷调查未覆盖的宏观指标才变得可以获得。
回到“维特效应”的例子。在过去,“大众媒介的自杀内容会不会传播自杀”这一命题只能被定性地讨论,无法被定量地检验。当我们拥有了大数据,就可以从中提取出以往无法获得超大时间空间跨度的指标。比如陈云松和严飞等人利用google、IMDB、proquest等数据,构建不同媒体(书籍、影视、报纸)中的自杀指数,作为影响自杀的原因,考察20世纪下半叶的美国社会,在影视媒体、新闻媒体高度发达的情况下,是否存在书籍的“维特效应”。马文、陈茁等利用IMDB数据对中国电影百年国际传播进行了探讨。

基于大数据的宏观定量研究是传统定量社会学和计算社会学的结合,使我们不仅可以在宏观层面检验大理论,而且能够进行社会学的因果推断。
[4] Chen, Y. , Yan, F. , He, G. , & Yan, W. . (2020). The Werther effect revisited: do suicides in books predict actual suicides?. Poetics, 101441. [5] Ma, W., Sun,W., Chen,Z., & Chen,Y. (2022).International Cinema’s Shifting Image of China: From the Barbarian to the Schemer, and to the Civilized Great Power. Journal of Contemporary China,forthcoming.
六、预测思维:黑箱插补
六、预测思维:黑箱插补
问卷调查的一些指标会出现数据缺失,而这种缺失不一定是随机的。社会学的研究往往依赖调查数据,就容易出现偏误,产生测量误差的内生性问题。例如家庭暴力的调查,往往受害者不愿意说出真实,而这类“缺失值”人群可能正是家暴的受害者。再如,性少数群体被访者往往不愿意透露真实信息,造成性取向调查的人口学数值缺失。
在以上两个例子,非随机的缺失值导致了向下偏误,使得遭受家暴和性少数人群的比例被低估。为了解决数据缺失的问题,陈云松、句国栋等利用监督学习的方法,对样本中的缺失值进行插补。总体上,传统的测量方法的确低估了这两者的比例。
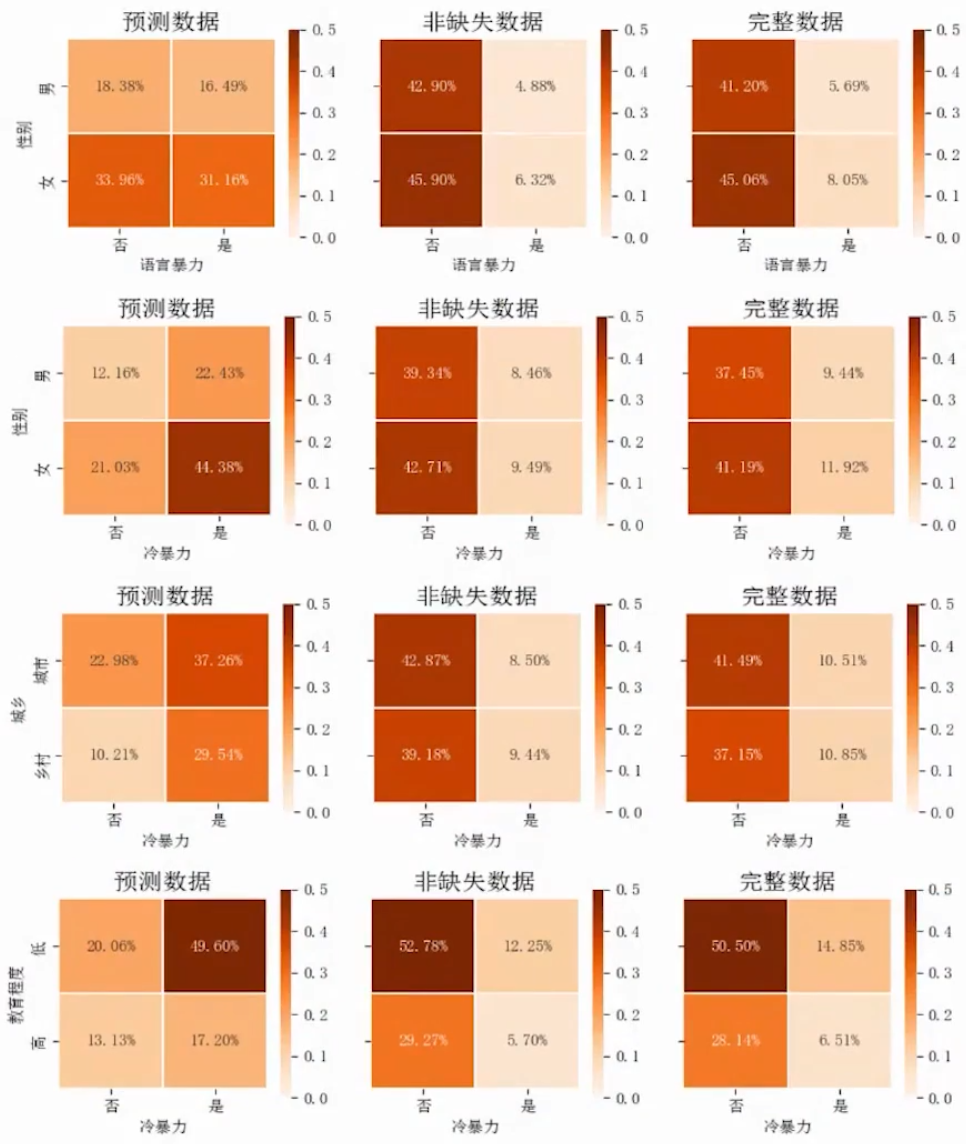
[6] Chen, Y. , Ju, G. , He, G. (2022). The Hidden Sexual Minorities: Machine Learning Approaches to Estimate the Genuine LGBTQ Percentage of Chinese Youth. Journal of Social Computing(forthcoming)
七、可视思维:社会结构
七、可视思维:社会结构
大数据的可视化能够阐发社会学理论的直觉。陈云松团队对《全唐诗》的文本进行聚类分析,根据隐含狄利克雷分布进行主题建模,把4.2万首完整的诗作分入十个主题类别。可视化后能看到隋唐五代中国诗人创作题材比例的时间演变过程。在此基础上,提出诗歌创作与边境用兵等等时间序列的假说。此外,陈云松、陈茁等利用句相似法研究了诗人作品风格之间的相似和传承。

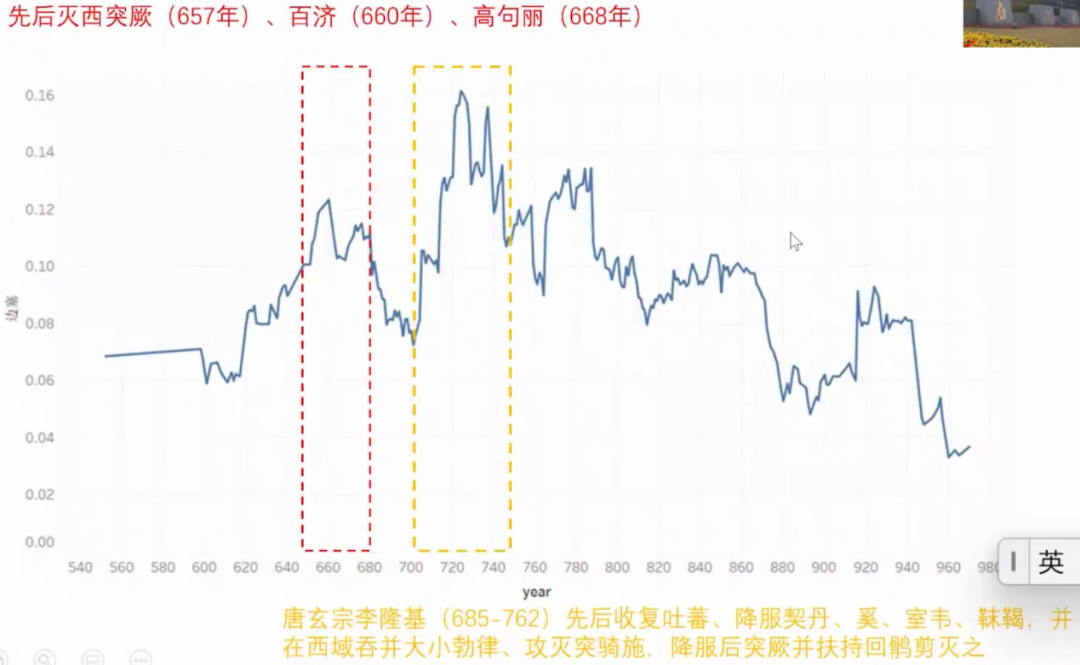
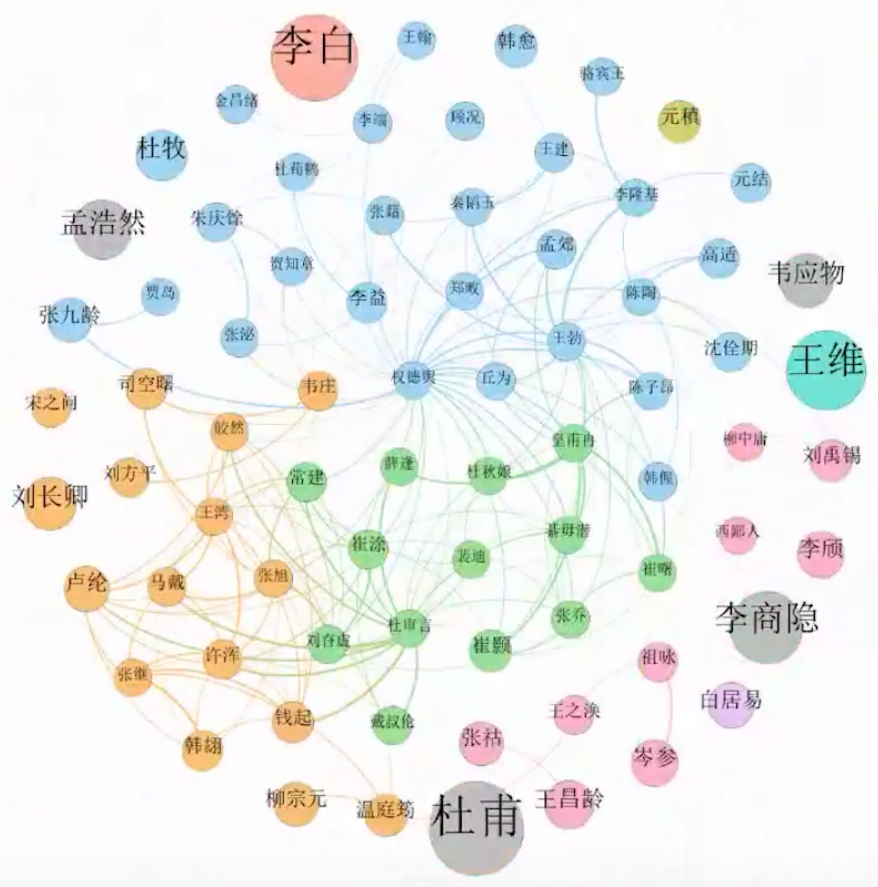
诚然,对流传下来的古代文本应用机器学习的方法进行文本挖掘,不一定充分满足算法模型的数学假设。但是,基于大数据的研究,还是能够在某种程度上带来新的启发,补充社会学既有的理论知识。
[7] 陈云松. (2022). 社会计算在文化社会学中的运用. 学术月刊, 54(1), 8.
八、简化思维:数据仿真
八、简化思维:数据仿真
多主体仿真建模(ABM)是历史悠久的计算社会科学方法,主要功能在于展示从微观到宏观的涌现现象。但从社会学直觉出发,也可能存在三个悖论。(1)复刻悖论。通过参数调整,简化模型能够再现各类宏观社会现象,但预测全部的可能有不给与概率分布,相当于不预测。(2)复杂性悖论。当模型参数很多,武断地设定参数关系就会丧失复杂性;但加入不确定性又会使模拟结果难以形成解释。(3)长臂悖论。有别于对传染病、城市交通等短链条进行建模,社会现象的模型往往有着从微观到宏观的漫长链条,对建模带来实际困难。瑞典社会学家、科尔曼的弟子赫斯特洛姆提出“实证校准”解决思路,如用现实回归模型的系数来提供ABM参数。但仍然不能解决上述悖论。
[8] 彼得・赫斯特洛姆. (2010). 解析社会:分析社会学原理. 南京大学出版社.
讲者介绍
陈云松,牛津大学社会学博士,南京大学社会学教授,教育部“长江学者”青年学者,国家社科基金重大项目首席专家,Social Science Research等杂志编委。主要研究领域为计算社会学、社会网络和社会心态。
因果科学读书会第三季启动
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
大数据揭示社交电商如何成功:购物连通社交关系,平台优化算法设计 -
因果推断在医药图像的应用:数据缺失和数据不匹配 -
量化涌现:信息论方法识别多变量数据中的因果涌现 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











