严重急性呼吸系统综合症冠状病毒 2 (SARS-CoV-2) 在不同环境中传播的详细特征有助于设计破坏性较小的干预措施。6月发表在PNAS的一篇论文中,研究人员使用纽约市和华盛顿州西雅图大都市地区的实时、隐私增强型移动数据,来构建基于主体的详细 SARS-CoV-2 感染模型,以估计传播的地点、时间和幅度大流行的第一波期间的事件。
研究发现,18%的感染者会导致大多数的病毒传播事件 (80%),其中大约 10% 的事件可以被视为超级传播事件。尽管大规模集会对超级传播事件构成重要风险,但研究人员估计大部分传播发生在工作场所、杂货店或食品场所等小型活动中。模型补充了案例研究和流行病学数据,并表明实时跟踪传播事件有助于评估和定义有针对性的缓解政策。
集智俱乐部组织的「计算社会科学读书会」第二季已经启动报名,将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会6月18日开始,持续10-12周,详情见文末,欢迎从事相关研究的朋友加入。
王百臻 | 作者
刘志航 | 审校
邓一雪 | 编辑
论文题目:Quantifying the importance and location of SARS-CoV-2 transmission events in large metropolitan areas
论文链接:https://www.pnas.org/doi/10.1073/pnas.2112182119
在缺乏有效药物干预的情况下,COVID-19 大流行引发了全球范围内旨在减缓 SARS-CoV-2 病毒传播的严格行动限制和保持社交距离措施的实施。从居家隔离到关闭餐馆/商店或限制旅行,这些措施的基本原理是减少社交接触,从而阻断传播链。尽管个人可能与家庭成员或密切接触者保持高度联系,但这些措施减少了社区中病毒通过人类接触网络传播的联系。一些场所可能会吸引更多来自其他未连接社交网络的个人,或者可能吸引更活跃的个人,从而获得更大的曝光度。了解针对特定场所的干预措施如何影响 SARS-CoV-2 的传播可以帮助研究人员设计更好的非药物干预措施(NPI),以实现公共卫生目标,同时最大限度地减少对经济、教育系统和日常生活其他方面的干扰。
尽管现在很清楚非药物干预措施有助于缓解 COVID-19 大流行,但大多数证据都是基于测量随后的病例增长率或二次繁殖数的下降。例如,使用计量经济学模型来估计引入非药物干预措施对二次再生数的影响。其他研究直接(通过相关性或统计模型)或间接(通过流行病模拟)显示了流动性或个人活动与病例数之间的关系。不幸的是,迄今为止使用的大多数数据都不具备评估非药物干预措施如何修改社会接触和 SARS-CoV-2 传播事件所需的粒度。
鉴于 SARS-CoV-2 的异质性传播,这一点尤为重要。由单个个体产生的继发感染数量的过度分散是 2003 年 SARS 大流行的一个重要特征,在 SARS-CoV-2 中也观察到了类似的情况。已经提出了几个超级传播事件 (SSE) 的驱动因素:由于个体传染性的差异引发的生物学因素;由异常大量的联系人聚集引起的行为因素;以及有利于传播的环境因素。传播能力在很大程度上取决于接触发生地点的特征,许多超级传播事件发生在拥挤的、通风不良的室内活动中。这种过度分散的一个特点是大多数感染(约 80%)是由少数人或少数地方(20%)引起的,这表明可以设计更有针对性的非药物干预措施或基于集群的接触者追踪策略来控制大流行。尽管有几项研究提供了关于超级传播事件的见解,但鉴于它们对 SARS-CoV-2 的巨大重要性,研究人员需要更好地了解这些超级传播事件 发生的地点、时间和程度,以及它们如何被减轻或放大非营利组织。
为了量化大都市地区新冠传播事件的重要性,该文使用纽约市和华盛顿州西雅图大都市地区的实时、隐私增强型移动数据来构建基于主体的详细 SARS-CoV-2 感染模型,以估计第一波大流行期间传播事件的地点、时间和强度。研究者估计只有 18% 的个体会导致大多数感染(80%),其中大约 10% 的传播事件可以被视为超级传播事件(superspreading events,超级传播事件)。尽管大规模集会构成了超级传播事件的重要风险,但该文估计大部分传播发生在工作场所、杂货店或食品场所等小型场所中,并且在不同城市之间有所不同。该结论表明在这类传播之下,存在着巨大的潜在行为成分。该文给出的模型补充了案例研究和流行病学数据,并表明实时跟踪传播事件有助于评估和定义有针对性的缓解政策。
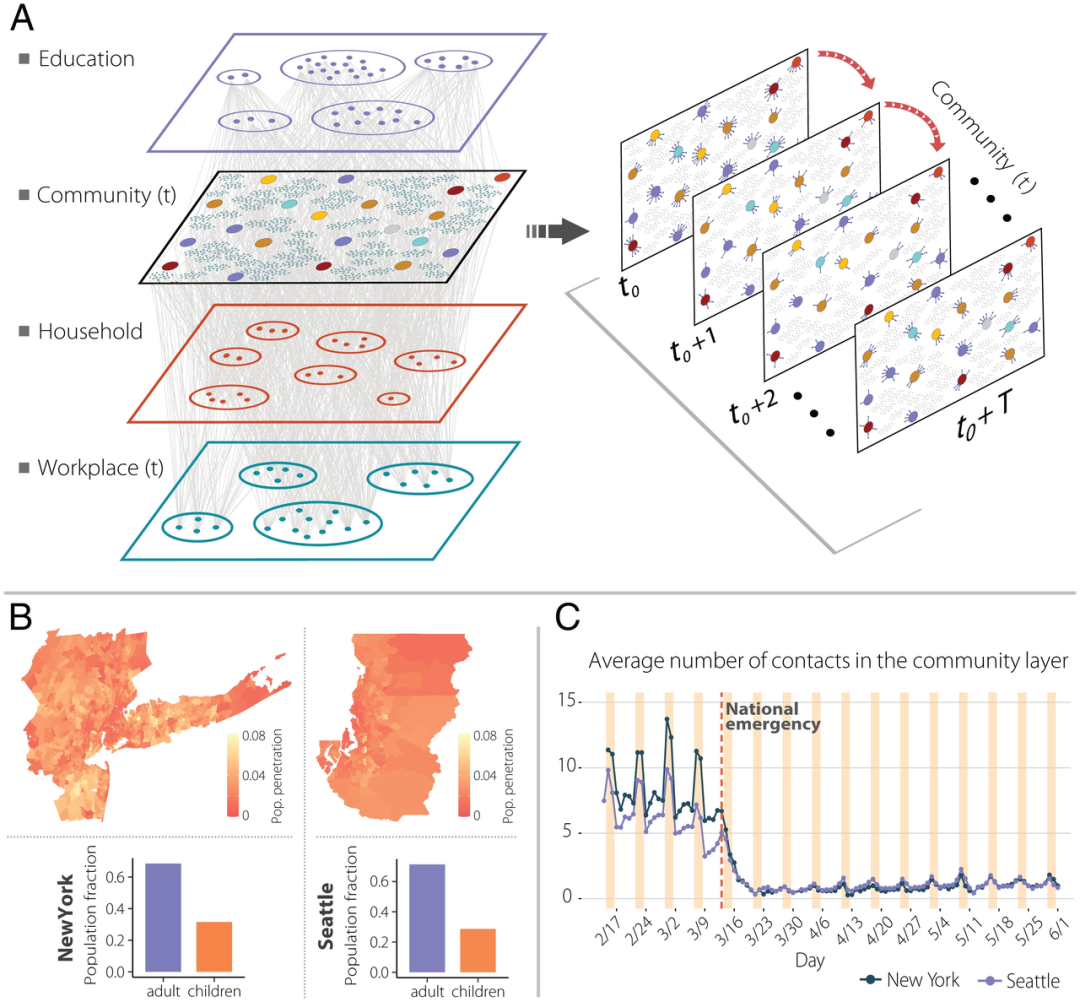
图:网络组件模型图式,以及纽约和西雅图大都市地区的人口和社区层的社会联系动态随时间变化。(A)根据移动数据构建的合成人口的加权多层和时间网络示意图。有四个不同的层;学校和家庭层随着时间的推移是静态的,而工作场所和社区层的组合则具有日常的时间成分。(B)与纽约和西雅图大都市区总人口相比,该文计算得到的移动数据中的地理渗透率(按人口计算的移动设备比例)。(C)两个大都市区社区层的平均每日接触人数。
具体而言,在本文中,研究人员使用了 2020 年 2 月至 2020 年 6 月期间分布在纽约和西雅图大都市区的超过 50 万人的个人级流动性数据,以估计人们可能进行互动并产生传播事件的场所的日期和类型。为此,研究人员从移动数据中提取了大约 440,000 组停留数据。有了这些信息,研究人员构建了两个合成人群,每个大都市区一个,其中主体可以在不同的环境中互动:工作场所、家庭、学校和社区(兴趣点)。然后,研究人员使用在该人群之上应用的分区和随机流行病模型探索 SARS-CoV-2 的传播。
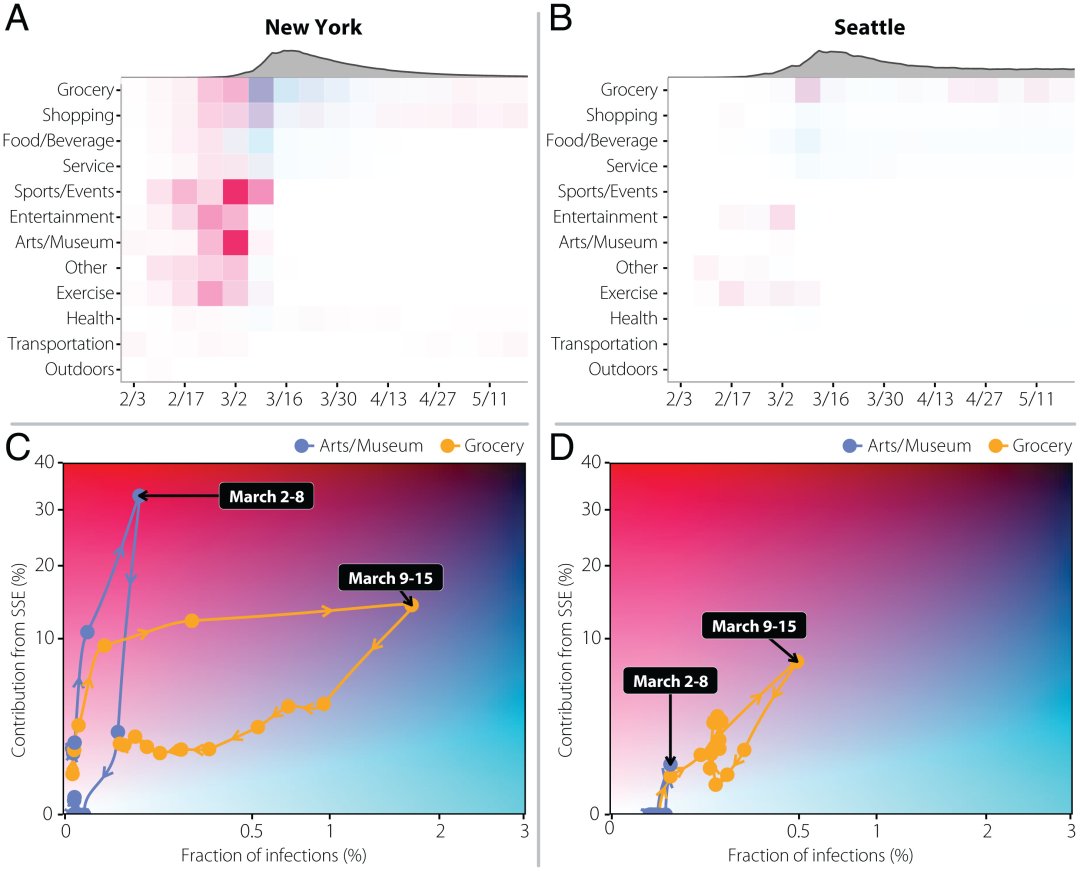
研究人员的研究结果强调了人类行为、非药物干预措施和 COVID-19 大流行在两个主要大都市地区的演变相互交织的性质。具体来说,研究人员的研究结果表明,个体之间的异质连接和行为模式自然会导致不同环境的风险差异和超级传播事件的产生。特别是,对不同场所(例如体育场馆、博物馆、工作场所)实施的部分或全部关闭对塑造家庭以外个人的混合模式产生了巨大影响。因此,负责大多数传输事件和超级传播事件的设置会随着时间而变化。就绝对值而言,估计食品和饮料环境在确定流行早期传播事件和超级传播事件的数量方面发挥了关键作用;然而,这种设置是干预的首要目标之一,因此由于引入了非药物干预措施,它的贡献随着时间的推移变为零。另一方面,杂货店等环境对整体传播和超级传播事件的绝对贡献始终较低,相对而言,在大多数其他活动根本无法进行的封锁期间,它们成为了超级传播事件的来源。这些发现表明,有针对性的措施有优化的空间,例如延长工作时间以减少接触次数或使用旨在减少超级传播事件机会的智能工作。当繁殖数量略高于或低于流行阈值时,这可能与避免局部病例突然爆发特别相关。
图注:超级传播事件的动力学。风险随着时间的推移而演变,是人口行为和现行政策的函数。(A 和 B)每周每个类别带来的风险,使用下面的相应地图定义。作为参考,顶部的灰色区域显示了估计的每周发病率。(C 和 D)x 轴代表与每个类别相关的总感染比例,而 y 轴代表每个类别中可归因于超级传播事件的感染份额。请注意,在整个时期内所有社会环境中产生的所有感染中,感染的比例是标准化的。这定义了一个连续风险地图,其中感染较少且超级传播事件贡献低的地方将位于左下角。感染人数高但超级传播事件贡献低的地方位于右下角。相反,超级传播事件贡献大但感染量低的地方位于左上角。最后,感染人数多且上证所做出重要贡献的地方位于右上角。与 A 和 B 中的每个图块相关的颜色是从 C 和 D 中定义的平面中点的位置提取的。C 和 D 中的点显示类别艺术/博物馆和杂货店每周位置的演变,箭头表示时间演化。
尽管从研究西雅图和纽约得出的总体情况是一致的,但重要的是要强调,由于当地交通、旅游或其他经济驱动因素,每个城市地区都可能具有特定的特点,从而区分城市的生命周期。研究人员的研究结果表明,一种千篇一律的解决方案可以最大限度地减少 SARS-CoV-2 的传播,可能会对不同城市产生截然不同的影响。此外,所提供的结果可能无法推广到农村地区。尽管西雅图都会区的大部分地区可以被视为农村地区,但个人连接模式可能会受到该国其他一些地区普遍较低的人口密度的不同限制。
该文还注意到,不太复杂的均匀混合模型足以重现 SARS-CoV-2 在不同城市传播的聚合特征,以及详细(尽管仍然是均匀混合)聚合对地点的访问模式可用于评估地点在传播中的平均作用。然而,这里提出的模型结合了个人移动行为和家庭、学校和工作场所多层时间网络的详细描述,从而使研究人员能够同时捕获 COVID-19 的关键方面,例如传染过度分散(超级传播事件)、社会环境感染风险的时间演变,或学校停课或居家政策的影响。通过在个人层面更好地描述流动模式,研究人员的方法仅依赖于最小的参数集,使其比通过拟合地点、住宅、城市的传播参数来编码该行为的模型更适用于流行病背景的其他位置,甚至是时间段。
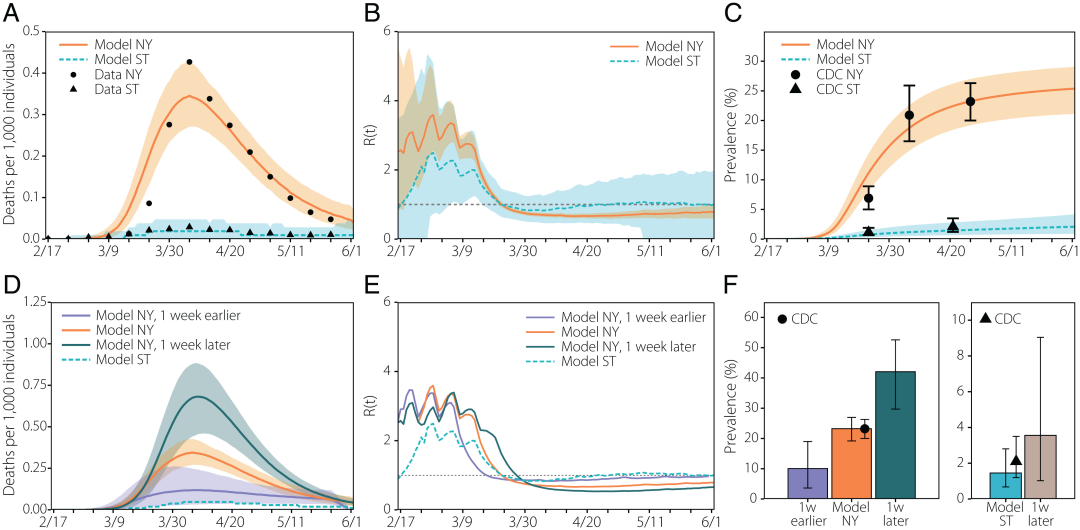
图注:第一波的演变图式。(A) 纽约 (NY) 和西雅图 (ST) 都会区的每周死亡人数。点/三角形代表用于模型校准的报告监测数据。线条代表每个位置的模型集合的中值,阴影区域代表校准模型的 95% CI 。(B) 根据模拟输出的有效再生数的演变。实线(虚线)表示模型集合的中值,阴影区域表示模型的 95% CI。(C)研究人员模型中的估计患病率(中位数用实线/虚线表示,95% CI 用阴影区域表示)和 CDC 报告的值(点/三角形分别代表纽约和西雅图的数据)。(D) 如果非药物干预措施早/晚 1 周在纽约应用,估计的死亡人数。实线(虚线)代表模型集合的中值,阴影区域代表 95% CI。(E)如果这些措施早/晚 1 周在纽约实施,则估计的有效繁殖数量的演变。实线(虚线)表示模型集合的中值。(F) 纽约(左)和西雅图(右)的估计患病率,如果非药物干预措施早于/晚 1 周在纽约应用,1 周后在西雅图应用。条形的高度代表模型集合的中值,而垂直误差条代表 95% CI。点/三角形显示 CDC 报告的 2020 年 4 月最后一周的值。
Detailed characterization of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) transmission across different settings can help design less disruptive interventions. We used real-time, privacy-enhanced mobility data in the New York City, NY and Seattle, WA metropolitan areas to build a detailed agent-based model of SARS-CoV-2 infection to estimate the where, when, and magnitude of transmission events during the pandemic’s first wave. We estimate that only 18% of individuals produce most infections (80%), with about 10% of events that can be considered superspreading events (SSEs). Although mass gatherings present an important risk for SSEs, we estimate that the bulk of transmission occurred in smaller events in settings like workplaces, grocery stores, or food venues. The places most important for transmission change during the pandemic and are different across cities, signaling the large underlying behavioral component underneath them. Our modeling complements case studies and epidemiological data and indicates that real-time tracking of transmission events could help evaluate and define targeted mitigation policies.
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
新一季【计算社会科学读书会】由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动