理解大脑在一生的跨度下如何学习仍然是长期的挑战。在人工神经网络(ANNs)中,整合新信息的速度过快常导致灾难性的干扰,即突然失去先前获得的知识。互补学习系统理论(CLST)认为新的记忆会通过与已有知识交叉在一起的方式逐渐整合进新大脑皮层。然而,这种方法也就假定了每次学习新东西都需要交叉所有已知的知识,这难以置信,因为它不仅耗时同时需要大量数据。
近日发表于 PNAS 的最新研究展示了深度、非线性的人工神经网络可以通过交叉仅仅一部分的老知识来学习新信息,这些老知识和新信息在表征上有着很大的相似度。就靠着这种相似度加权交叉学习(SWIL)的策略,人工神经网络能够在取得同样精度水平和最小干扰的情况下快速学习新信息,而每轮训练只需要很少量的老知识(快速且数据高效)。相似度加权交叉学习策略可以应用于各种标准分类数据集(Fashion-MNIST, CIFAR10, and CIFAR100),深度神经网络,以及序列学习框架之中。研究发现,数据效率和学习新项目的速度与存储在网络中的非重叠类的数量大致成正比例,这可能暗示着人类大脑在编码大量不同类的东西时,数据效率和速度会大大加快。最后,论文提出一个合适的理论模型来解释相似度加权交叉学习策略在大脑中的应用。
研究领域:互补学习系统,学习,神经网络,记忆巩固

论文题目:Learning in deep neural networks and brains with similarity-weighted interleaved learning
论文链接:https://www.pnas.org/doi/10.1073/pnas.2115229119
人工神经网络在学习新东西时,会迅速忘记之前学习的信息,必须通过混合新旧样本,重新训练。然而,混合所有旧样本是耗时的也是不必要的。那么我们应该按照什么样的策略来选择旧样本重新训练神经网络呢?
本文作者给出了一个相对更好的策略:只混合与新样本有很大相似度的旧样本就足够了。本文研究表明,通过新旧样本的相似度加权交叉训练,深度神经网络可以在使用更少的数据的同时,快速学习新样本而不忘记旧样本中学习得到的知识。
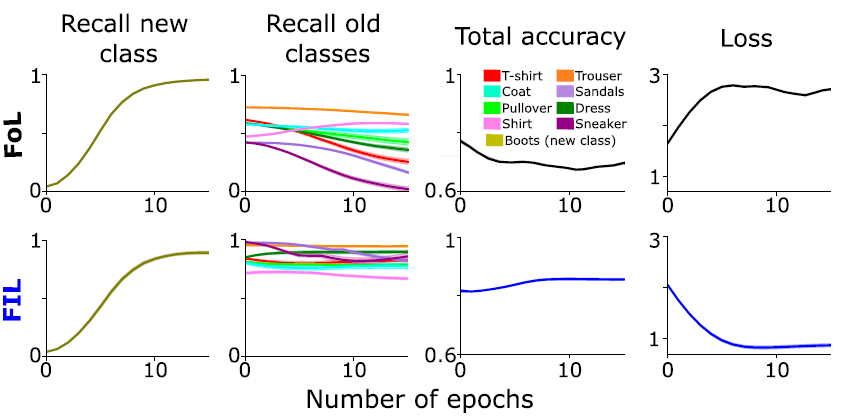
图1. 神经网络在训练新种类的图片后对旧种类图片的召回率,准确率显著下降,但是不同种类的旧图片下降的程度不同。而将新旧混合训练,则召回率,准确率能够保持稳定。
正如图1展示:先用8类图片预训练只有一层隐藏层的线性神经网络,之后预训练网络在两种情况下学习新类(Boots,靴子)的表现。FoL(focused learning):只提供新类的图片;FIL(focused all classes):提供所有类别的图片。第一二列图片表示,在两种训练策略下,分别在新类和训练过的旧类下,召回率(Recall)随着训练迭代(epoch)次数的变化情况;第三列图片表示,在两种训练策略下,所有类的准确率(accuracy)随着训练迭代次数的变化;第四列表示,两种训练策略下,交叉熵损失函数随着训练迭代次数的变化。FoL会使得学过的旧类图片的信息被遗忘,召回率、准确率指标显著下降,而混合所有旧类图片和新类图片,训练效果则保持稳定。
图2表明,在8类图片上预训练好的一层隐藏层的线性神经网络学习新类(Boots 图片),在6种不同的训练策略下,网络表现随迭代次数的变化。A图表示六种不同是训练策略:FoL;FIL;PIL (partial interleaved learning) :9类图片的子集参与每次迭代训练(n=350 images per epoch,39 images/class);SWIL(相似度加权交叉学习):根据训练过的8类图片和新类(Boots)的相似度,决定每类在训练新类过程中的图片数量,越相似则数量越多;EqWIL(Equally Weighted Interleaved Learning):新类的图片数量和SWIL保持一致,其它8类的图片和新类图片相似度权重设置为一致,则训练图片为75 images/class。B图表示,6个训练策略下,召回率在新类和相似度高的旧类(sneaker,Sandals)以及相似度不高的其它6类上随着迭代次数的变化;整体准确率,交叉熵损失函数训练过程的变化。可见,文章作者提出的SWIL训练策略能够很好的缓和神经网络遗忘旧信息的问题,同时提高训练的时间效率。
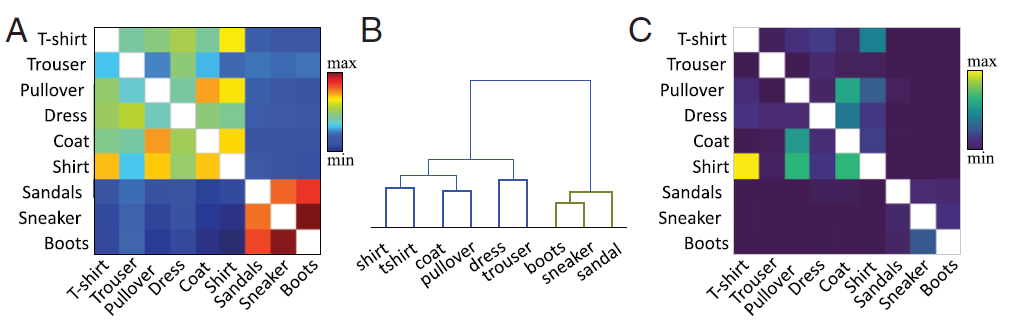
那么,各个种类的图片的相似度指标的计算也是我们需要关注的重点之一,概括来说,文章作者使用公开的方法在特征层面计算相似度。简单地说,作者计算了目标隐藏层中已有类样本和新类样本的激活向量平均值之间的余弦相似度。图3展示了作者计算得到的各种类图片之间的相似度矩阵A图;B图:依据A图的聚类结果;C图:经过FIL策略训练学习“Boots”类图片后的混淆矩阵 。对角线值被删除,以提高缩放的清晰度。
最近以大脑为灵感的缓解灾难性干扰的方法可以分为:1.基于正则化的方法(regularization-based )2.基于生成重放的方法(generative-replay–based methods)。基于正则化的方法有:EWC(Elastic Weight Consolidation);Learning without Forgetting;Synaptic Intelligence;这些通常包括测量每个参数的重要性和添加一种正则化项,惩罚网络中最相关的参数或映射函数的变化。当需要增量地学习许多新类时,这些方法通常会受到影响。基于生成重放的方法,通常包含深度生成和任务解决网络。在重学习的过程中,新类样本与生成的伪数据混合在一起(捕捉先前学习的代表性统计信息)。生成重放方法不用再访问旧样本,然而,问题转向了改进生成器(一个重要和困难的问题)。另一方面,作者计算了新类的目标层的平均激活与旧类之间的相似度。因为他们关注的是类层次上的学习动力,而不是跨类的单个属性,所以研究单个的特征映射的学习动力也会很有趣。相似度也可以在不同层次上计算:像素级或功能性。
Understanding how the brain learns throughout a lifetime remains a long-standing challenge.In artificial neural networks (ANNs), incorporating novel information too rapidly results in catastrophic interference, i.e., abrupt loss of previously acquired knowledge. Complementary Learning Systems Theory (CLST) suggests that new memories can be gradually integrated into the neocortex by interleaving new memories with existing knowledge. This approach, however, has been assumed to require interleaving all existing knowledge every time something new is learned, which is implausible because it is timeconsuming and requires a large amount of data. We show that deep, nonlinear ANNs can learn new information by interleaving only a subset of old items that share substantial representational similarity with the new information. By using such similarityweighted interleaved learning (SWIL), ANNs can learn new information rapidly with a similar accuracy level and minimal interference, while using a much smaller number of old items presented per epoch (fast and data-efficient). SWIL is shown to work with various standard classification datasets (Fashion-MNIST, CIFAR10, and CIFAR100), deep neural network architectures, and in sequential learning frameworks. We show that data efficiency and speedup in learning new items are increased roughly proportionally to the number of nonoverlapping classes stored in the network, which implies an enormous possible speedup in human brains, which encode a high number of separate categories. Finally, we propose a theoretical model of how SWIL might be implemented in the brain.
随着电生理学、网络建模、机器学习、统计物理、类脑计算等多种技术方法的发展,我们对大脑神经元相互作用机理与连接机制,对意识、语言、情绪、记忆、社交等功能的认识逐渐深入,大脑复杂系统的谜底正在被揭开。为了促进神经科学、系统科学、计算机科学等领域研究者的交流合作,我们发起了【神经动力学模型读书会】。
集智俱乐部读书会是面向广大科研工作者的系列论文研读活动,其目的是共同深入学习探讨某个科学议题,激发科研灵感,促进科研合作。【神经动力学模型读书会】由集智俱乐部和天桥脑科学研究院联合发起,已于3月19日开始,每周六下午14:00-16:00(或每周五晚上19:00-21:00,根据实际情况调整)进行,预计持续10-12周。期间将围绕神经网络多尺度建模及其在脑疾病、脑认知方面的应用进行研讨。
详情请见:
神经动力学模型读书会启动:整合计算神经科学的多学科方法