如何在经济和社会系统中重新分配资源?例如,一群人决定集中资金进行投资,获得回报后该如何分配收益?简单的平均分配看起来不太公平,但按照每个人的初始投资规模按比例分配,就真的公平吗?近日,DeepMind公司开发了名为 Democratic AI 的系统来探索解决这个机制设计问题。Democratic AI 可以直接学习最大化一群人的偏好,融合人类思想家和专家之前为解决再分配问题而提出的各种想法,从而设计出更受欢迎的分配策略。该方法解决了 AI 研究中的一个关键挑战——如何训练符合人类价值观的人工智能系统。
集智俱乐部组织的「计算社会科学读书会」第二季已经启动报名,将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会6月18日开始,持续10-12周,详情见文末。
研究领域:人工智能,社会机制设计
Human-centred mechanism design with Democratic AI
https://www.nature.com/articles/s41562-022-01383-x
构建与人类价值观一致的人工智能(AI)是一个尚未解决的问题。近日DeepMind公司发表于Nature的最新研究开发了一个名为“民主AI”(Democratic AI)的方法,利用强化学习设计一种大多数人喜欢的社会机制。
一群人在玩一个在线投资游戏,其中涉及决定是保留一笔货币捐赠,还是与其他人分享,以实现集体利益。共享收益通过两种不同的再分配机制返还给玩家,一种是由AI设计的,另一种是由人类设计的。AI发现了一种机制,可以纠正最初的财富失衡,制裁搭便车者,并成功赢得多数投票。通过优化人类偏好,“民主AI”为与价值一致的政策创新提供了概念证明。表明深度强化学习可用于找到人们将在简单游戏中以多数票赞成的经济政策。因此,该论文解决了人工智能研究中的一个关键挑战——如何训练符合人类价值观的人工智能系统。
关于如何在我们的经济和社会中重新分配资源的问题,长期以来一直在哲学家、经济学家和政治科学家中引起争议。在经济学和博弈论中,被称为机制设计的领域研究如何最优地控制财富、信息或权力在受到激励的行为者之间的流动,以达到预期目标。这篇文章提出了一个问题:深度强化学习(RL)主体是否可以用来设计一种使被激励的人群偏好的经济机制。
构建行为受人类偏好的人工智能系统的挑战被称为“价值校准”问题。实现价值一致的一个关键障碍是,人类社会承认多种观点,这就不清楚人工智能应该对哪一种偏好进行一致。在人工智能研究中,人们越来越意识到,要建立与人类兼容的系统,需要新的研究方法,让人类和智能体相互作用,并加大努力直接从人类那里学习价值,以建立与人类价值一致的人工智能。
通过仲裁相互冲突的观点——人类选民中的多数民主——来开发一个以人为中心的研究方法,实现价值一致的人工智能研究。这篇文章没有给主体(agent)灌输所谓的人类先验价值,潜在地使系统倾向于人工智能研究人员的偏好,而是训练它们最大化一个民主目标:设计人类更喜欢的政策,从而在多数选举中投票实施,这种方法称为“民主AI”。
文章创建了一个包含四名玩家的简单游戏。游戏的每个实例都进行了10轮以上。在每一轮中,每个玩家都被分配了资金,捐赠的大小因玩家而异。每个玩家都做出了选择:他们可以为自己保留这些资金,也可以将它们投资于一个共同的资金池中。投资的资金保证会增长,但存在风险,因为玩家不知道收益将如何分配。相反,他们被告知前10轮有一名裁判(A)做出重新分配决定,而后10轮则由另一名裁判(B)接管。比赛结束时,他们投票给A或B,并与这位裁判进行了另一场比赛。游戏的人类玩家被允许保留最后一场游戏的收益,因此他们被激励准确地报告他们的偏好。
在10轮的每一轮中,每个参与者i都向公共投资基金贡献整数ci的硬币,捐赠数额为ei,剩余的总和(ei-ci)留在私人账户中(捐赠基金可能会因参与者的不同而有所不同,有一个参与者得到的比其他人多)。k=4个玩家的累计贡献以 r = 1.6 的增长因子(投资的正回报);这相当于边际资本收益(marginal per capita return ,MPCR=0.4)。公共基金通过再分配机制返还给玩家,该机制规定了返还给每个玩家的公共投资总额的比例,取决于他们的贡献和捐赠。这种博弈承认存在一种连续的再分配机制,这种再分配机制通常与政治光谱中对立的两端有关,在这种机制中,回报在不同程度上取决于自己和他人的贡献。
参与者(n = 756)被分成4人一组,其中1名正面参与者获得10枚硬币,3名反面参与者获得2、4或10枚硬币。因此,当尾部玩家获得少于10枚硬币时,禀赋是不相等的,而当所有玩家获得10枚硬币时,禀赋是相等的。每组玩10轮游戏,每次获得相同的捐赠,但在不同的再分配机制下体验每一场游戏。每一种再分配机制都决定了玩家所获得的支付是自己和他人的公共贡献的不同函数。
-
严格的平均主义再分配机制将公共资金平均地分配给所有参与者,无论他们的贡献如何。
-
自由意志主义机制按照每个参与者的贡献的比例向他们返还一份报酬,使之成为帕累托有效纳什均衡。这种机制有效地实现了捐款私营化,消除了社会困境,鼓励玩家增加捐款。
-
自由平等主义提出,每个参与者对自己的行为负责,而不是对最初的优势负责,因此支付取决于贡献的捐赠资金的比例。
公共资金的分配策略可能是这三种规范机制中的一种,或者完全是其他的东西。潜在搜索空间的大小使得使用传统行为研究方法难以确定首选的机制。因此,研究开发了一个“人在循环的研究管道”(Human-in-the-looppipeline)来解决这个问题。首先,收集人类数据的初始样本(Acquire),然后使用它来训练“虚拟人类玩家”,这些反复出现的神经网络在游戏中学习模仿人类行为,并根据与人类玩家相同的原则投票(Model)。第三,利用深度RL优化机制设计,利用策略梯度法最大化虚拟人类玩家的投票(Optimize)。第四,对一组新的人类样本进行了采样,并将RL设计的再分配机制与对手的基线进行了一系列正面交锋的多数选举。这些新的人类数据随后被用于增强我们的玩家建模过程,这反过来又改善了优化并带来了潜在的更好的机制(Repeat)。
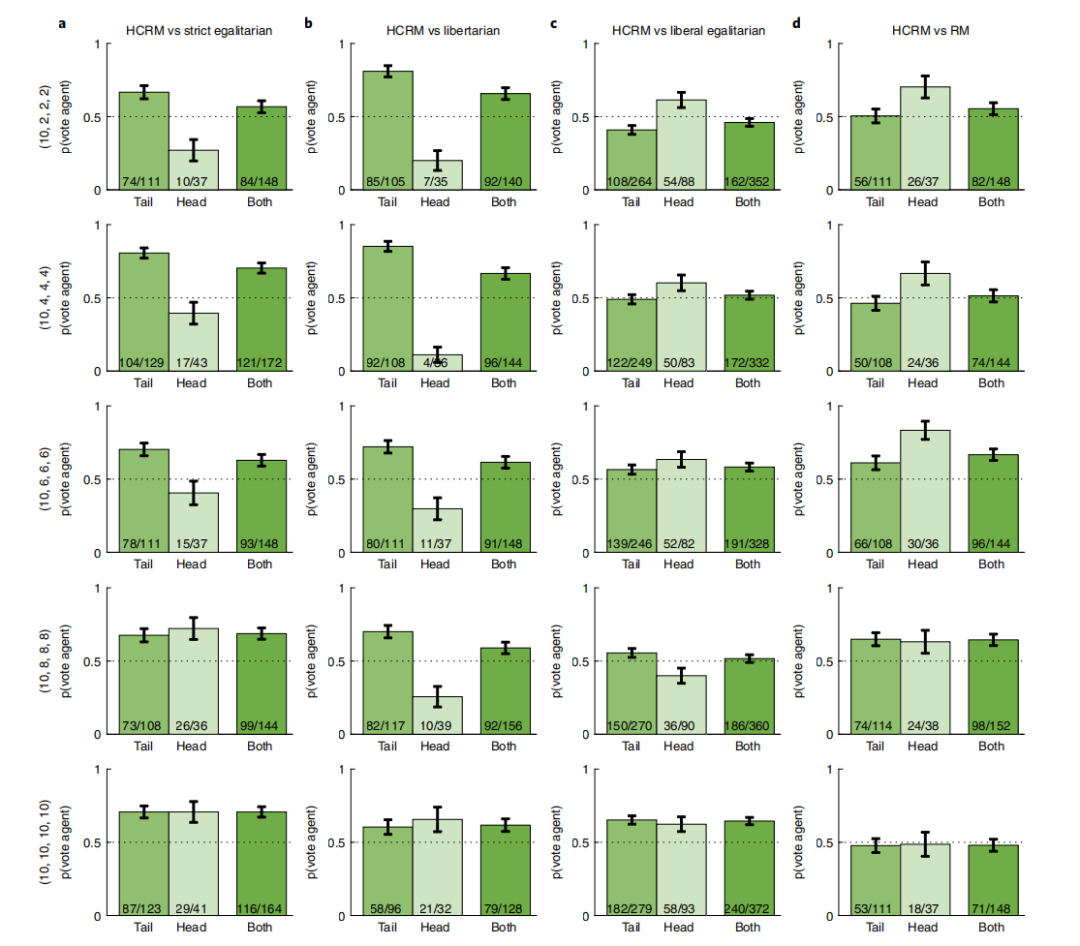
在实验2a-c中,文章根据上面介绍的三个规范基线评估了人工智能设计的HCRM(Human Centred Redistribution Mechanism),发现HCRM比三条基线都更受欢迎(图1a-c)。我们将玩家随机分为五种禀赋条件,其中一个正面玩家获得10个硬币禀赋,三个反面玩家获得的数量∈{2,4,6,8,10}。
与严格的平等主义和自由意志主义相比,人工智能设计的机制在所有五种禀赋分配测试中也更受欢迎,从完全平等到最不平等的禀赋条件[(10,2,2,2)意味着衡量财富不平等的指标——基尼系数为0.38。在这些条件下,它的投票份额从56.0%到67.0%反对平等主义,从57.5%到66.7%反对自由意志主义。尽管HCRM在完全平等(64.5%)和中度不平等(禀赋(10,8,8,8)和(10,6,6,6)]下得票率为54.5%的情况下总体上更受青睐,但在最不平等的条件下,HCRM和自由平等主义之间的投票偏好没有可靠的差异(HCRM的得票率为47.4%),这表明在最不平等的条件下,自由平等主义的再分配提供了与HCRM同样好的选择。
总体而言,57.2%的参与者更喜欢HCRM而不是RM(rational mechanism)(图1d)。RM在不平等禀赋下学会了一个激进的策略,忽略了头部参与者,并主要向尾部参与者支付。尽管尾部参与者与头部参与者的比例有利,但是,即使在最不平等的禀赋条件下,这也是不成功的,因为头部参与者迅速停止了对所有人(包括尾部参与者)的不利影响,导致整体群体剩余低于HCRM。
图1. 不同禀赋和竞争机制下的整体投票份额
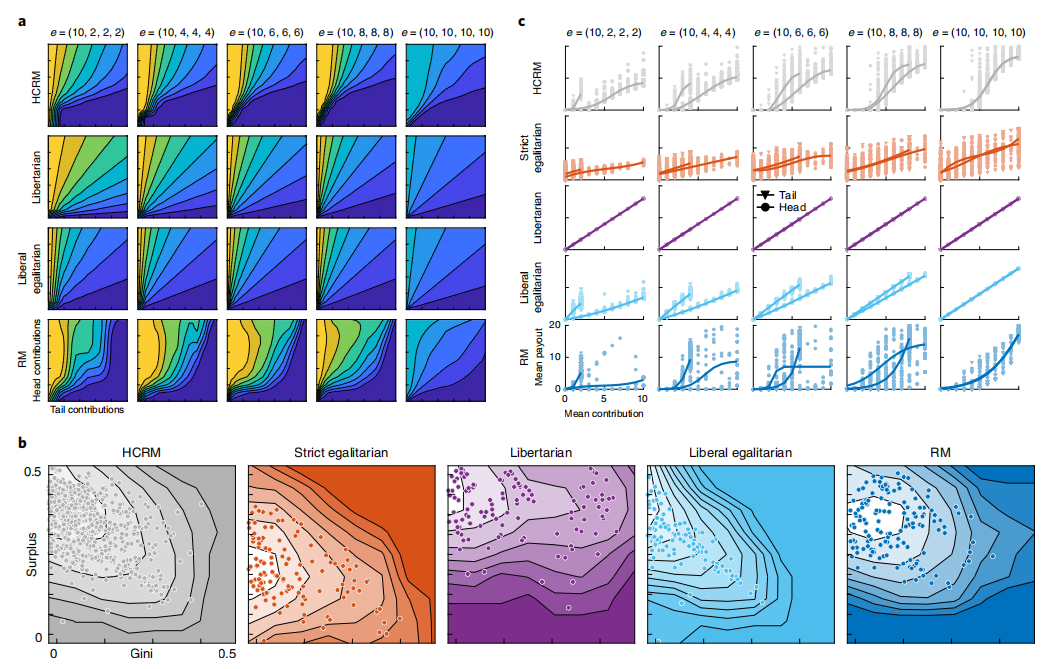
RL机制设计者可以被描述为一个二维曲面,将头部和尾部玩家的相对贡献映射到他们的收益份额(图2a)。RL设计的机制会受到人类玩家的欢迎,是因为RL发现了一种混合机制,它避开了传统上提出的再分配方案,这种再分配方案强调个人的自由裁量权,而不是资源分配(自由意志主义)或集体平等(严格的平等主义)。
HRCM奉行一种广泛的自由平等主义政策,试图通过对参与者的贡献与捐赠的比例进行补偿,来缩小先前存在的收入差距。换句话说,这一机制不是简单地最大化效率,而是渐进式的:它以初始禀赋较高的人为代价,促进了那些在财富上处于劣势的人获得选举权。通过这样做,它在竞争机制中实现了生产率(盈余)和平等(基尼系数)之间的有利平衡(图2b);然而,与自由平等主义不同的是,它几乎不会给玩家任何回报,除非他们贡献大约一半的捐赠(图2c)。换句话说,RL有效地发现,面对社会困境的人类更喜欢允许制裁搭便车者的机制。主体因此学会了一种政策,这种政策不容易被指定为分配正义的特定哲学,而是创造性地结合了来自各个政治派别的想法。
文章探究受过训练的人类玩家是否能够设计出像HCRM那样受欢迎的机制。研究首先招募了61名之前的玩家,并在大约1个小时的时间内训练他们,以便将资金重新分配给虚拟公民,从而最大化选票,然后我们招募了另外一组新的人类玩家(n = 244)在HCRM下玩一场游戏,在训练有素的人类裁判下玩另一场游戏。这些人类选手强烈倾向于HCRM而不是人类裁判(62.4%的人投票支持HCRM)。
人工智能系统有时会因学习政策可能与人类价值观不相容而受到批评,而这种“价值对齐”问题已成为人工智能研究的主要关注点。该研究方法的一个优点是,人工智能直接学习以最大化一组人的陈述偏好(或投票)。这种方法可能有助于确保人工智能系统不太可能学习不安全或不公平的政策。事实上,当我们分析人工智能发现的政策时,它融合了人类思想家和专家先前提出的解决再分配问题的想法。
首先,人工智能选择根据人们的相对贡献而不是绝对贡献来重新分配资金。这意味着在重新分配资金时,主体会考虑每个玩家的初始资金,以及他们的出资意愿。其次,人工智能系统特别奖励了相对贡献更大的玩家,也许会鼓励其他人这样做。重要的是,人工智能只是通过学习最大化人类投票来发现这些政策。因此,该方法确保人类保持“循环”,并且人工智能产生与人类兼容的解决方案。
通过要求人们投票,该研究利用多数民主原则来决定人们想要什么。尽管它具有广泛的吸引力,但人们普遍承认,民主伴随着一个警告,即大多数人的偏好要高于少数人的偏好。该研究确保了——就像在大多数社会中一样——少数群体由更慷慨的捐赠者组成,但是需要做更多的工作来理解如何权衡多数和少数群体的相对偏好,通过设计允许所有投票的民主制度。
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
新一季【计算社会科学读书会】由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动