崔鹏:推荐系统的分布外泛化 | 因果派论坛回顾

导语
因果AI作为下一代AI技术的重要方向之一,可以将产业界的真实需求和科技理念深度结合与碰撞,产生更强的力量,让因果科学在商业社会开花结果。因果AI在营销领域带来的核心商业价值之一就是挖掘和还原用户每一次交易背后的真实需求。并且追求的是高于“观察到”的浅层交易因素背后,那些尚未被有效探索的巨大价值。
7月2日,由零犀科技与集智俱乐部共同打造,旨在加速人工智能学界和产业界在因果科学领域融合探索的“因果派”论坛成功召开。清华大学计算机系长聘副教授、博士生导师崔鹏教授则是从另一个视角来看待因果。他更加注重于将因果应用到预测和决策场景时如何解决相关领域的痛点问题。由此提出了稳定学习的概念,希望能够解决机器学习的稳定性、解释性和公平性的问题。
特别是针对推荐系统出现的分布外泛化(Out-Of-Distribution, OOD)方面的问题,崔鹏教授分享了一些利用对于因果的理解去解决的方法。

丁善一 | 作者
邓一雪 | 编辑
1. 从I.I.D到OOD的范式转移
1. 从I.I.D到OOD的范式转移
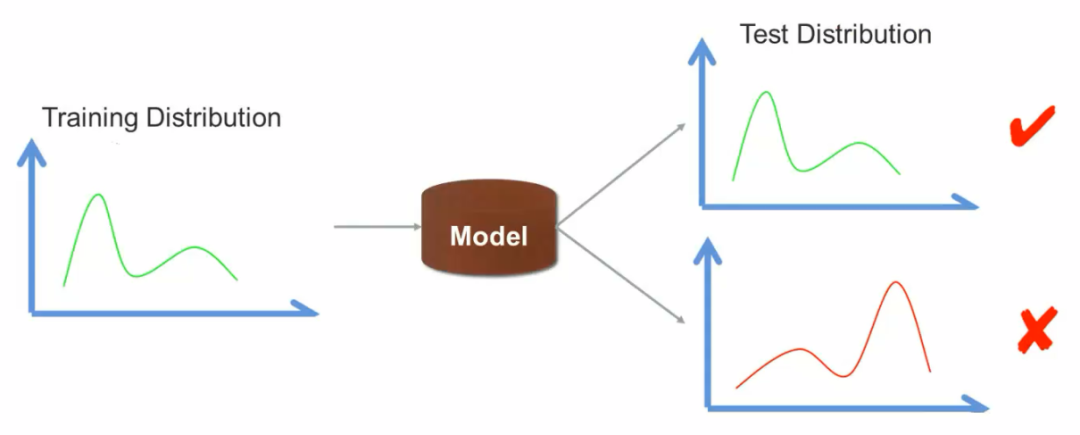

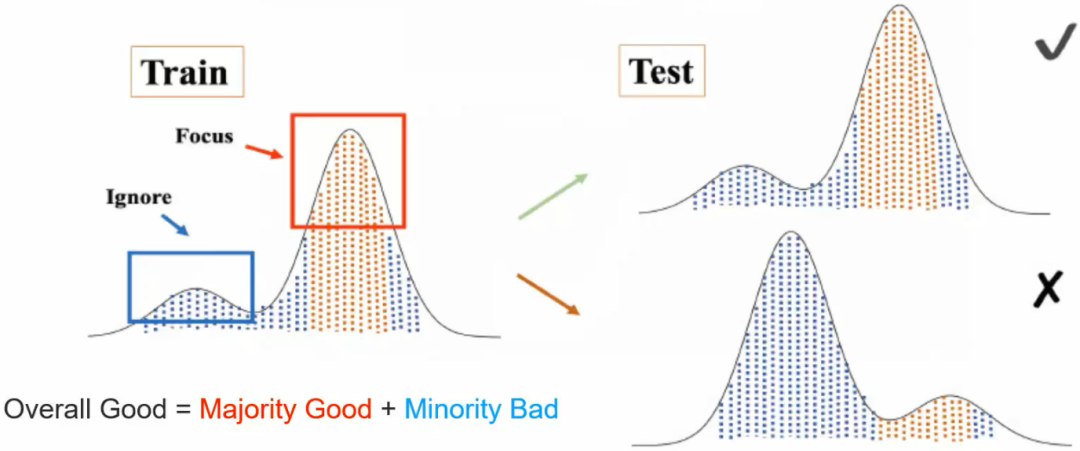
1.1 推荐系统中的OOD问题
1.2 OOD泛化与传统机器学习泛化的区别

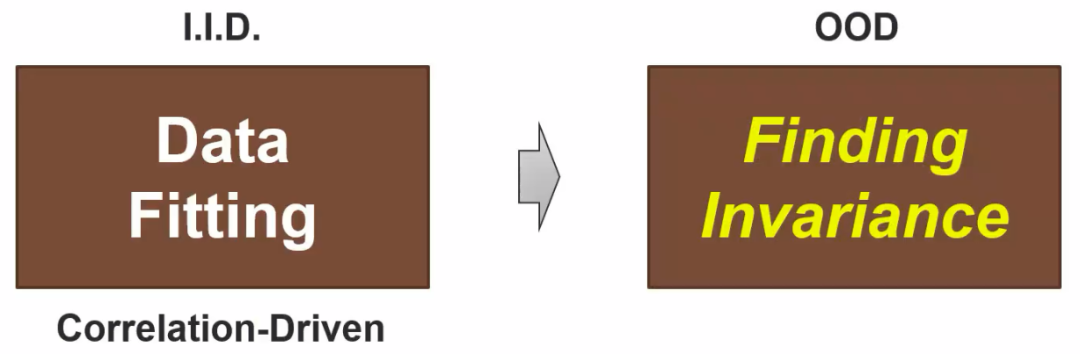
2. 不变性的技术探索之路
2. 不变性的技术探索之路
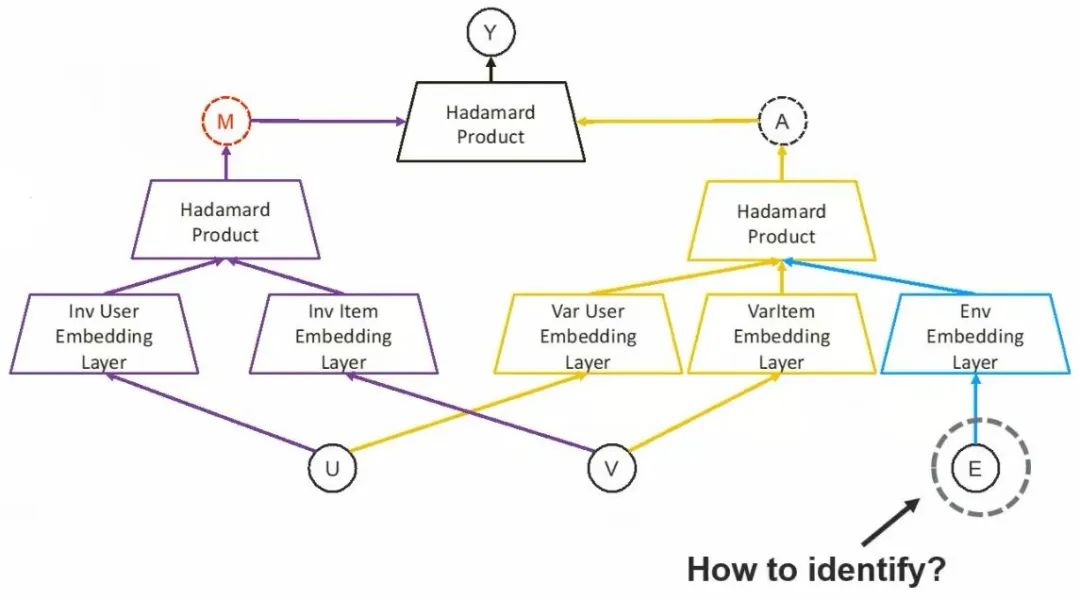
2.1 因果推理与不变性的等价关系
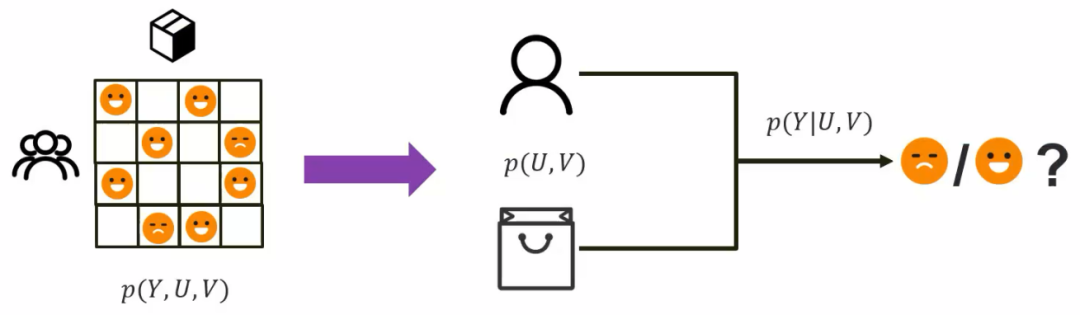
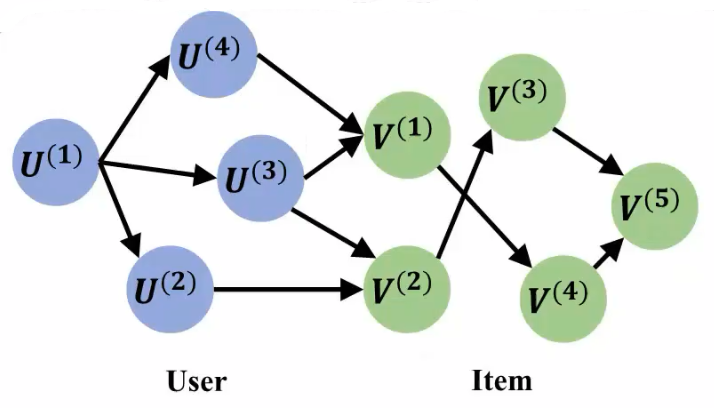
2.2 异质性中的不变机制


3. 结论
3. 结论
推荐阅读
-
因果表征学习最新综述:连接因果科学和机器学习的桥梁 -
寻找可落地的因果科学范式:从因果推理到因果学习 -
因果涌现学习路径:当「因果」和「涌现」相遇 -
CausalML:如何将因果推断与机器学习结合? -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











