利用requests和BeautifulSoup4写爬虫 | 周五直播·数据科学基础爬虫课

导语
大数据时代,爬虫是一个重要的基本技能。想要学会爬虫,需要一个完整的技术体系,并动手实践。为了帮助学生真正学会爬虫,集智学园联合西安交通大学应用数学博士、现为南京审计大学讲师的卢燚老师精心设计了 8 小时系列爬虫课程,用简短的代码、精短的课时,讲解 3 种 Python 爬虫的基本方法,给你一个较为完整的爬虫技术体系。
「利用requests和BeautifulSoup4写爬虫」是本系列课程的第二节,也是系列课程最后一次直播课。本节课将先介绍与爬虫相关的HTTP方法、状态码、Robots协议等HTTP知识,再介绍一个Chrome浏览器自带的爬虫必备工具:Chrome开发者工具,该工具是写爬虫代码之前需要花大量时间分析网站的解析工具。最后讲解requests库的使用方法。


课程简介
课程简介
本节课程大纲
本节课程大纲
1. HTTP基础:HTTP方法、状态码、Robots协议
2. 网页查看工具:Chrome开发者工具
3. requests库常见用法
4. 示例:编写一个新闻类网站的爬虫
课后作业
课后作业
讲师介绍
讲师介绍

直播信息
直播信息
-
报名课程,加入腾讯会议交流。

-
集智学园 B 站免费直播,房间号https://live.bilibili.com/6782735
给数据相关工作者的爬虫课
每周更新,持续报名中
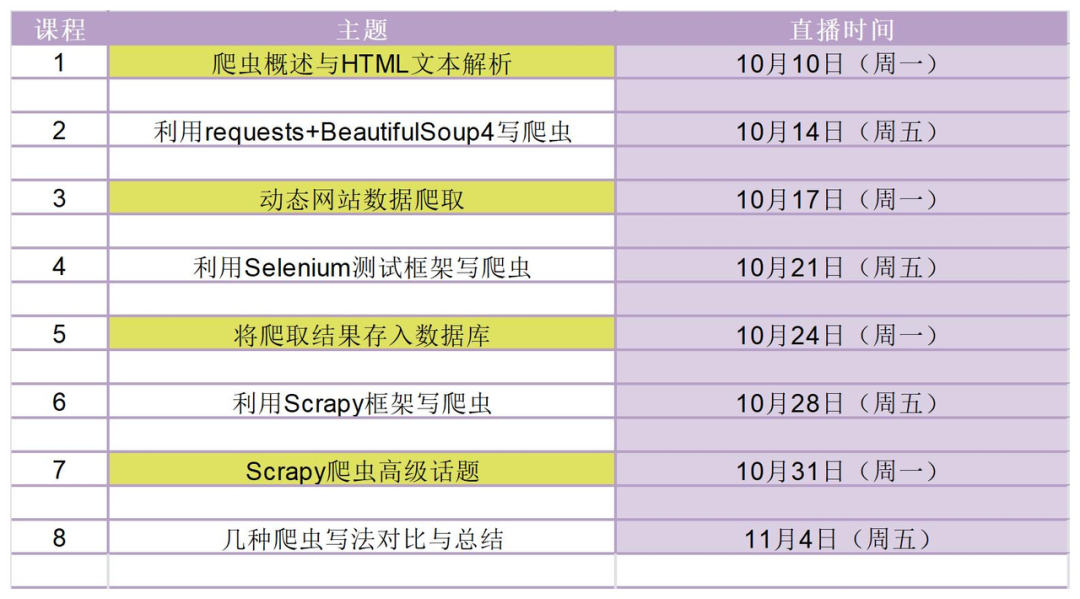
系列课程大纲
本系列课程分为 8 节,每节课程包括 60 分钟的内容分享与 30 分钟的答疑。
课程目的
本系列系统讲述当前流行的三种爬虫思路,三种思路内容互相补充,基本覆盖大多数爬虫使用场景。帮助你:
-
从零到一,系统建立爬虫技术体系;
-
由易到难,学会三种数据采集思路;
-
课堂内外,即学即用快速上手获取数据。
对学员的基础要求
-
具有一定的python编程基础(使用python3)
-
懂一点算法和网络知识(可选)
课程适用对象
-
算法工程师
-
从事数据相关工作的研究者
-
有编程基础,对爬虫感兴趣的开发人员
课程特色
-
线上直播,示例丰富。
-
只讲基本框架,代码简洁有效
-
代码可拓展,实用性强
-
三种方法互相补充,覆盖大多数爬虫场景
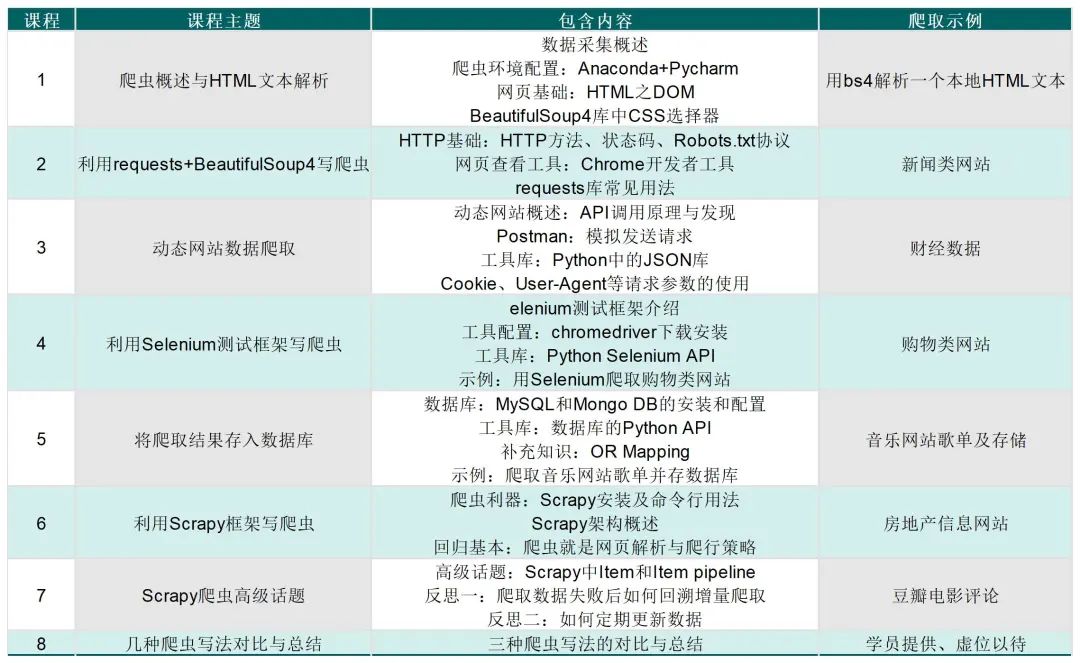
课程内容框架
报名加入课程
课程价格 199,早鸟报名仅需 169 元,优惠于2022年10月14日截止。

第一步:扫码付费
第二步:在课程详情页面,填写“学员信息登记表”
第三步:扫码添加助教微信,入群
微信扫一扫,分享到朋友圈











