理想情况下,科学发现应该是客观可靠的,然而近日发表于 PNAS 的一项研究指出,让73个独立研究小组使用相同的跨国调查数据来检验一个社会学假设,结果不同团队的结论并非趋同,而是大相径庭。这种隐藏的不确定性提醒研究者,特别是那些研究人类社会和行为复杂性的科学家们,应该保持谦逊,并努力解释他们工作中的不确定性。

论文标题:
Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty
https://www.pnas.org/doi/10.1073/pnas.2203150119
相比于物理学这样的硬科学,人们印象中的社会科学是“公说公有理,婆说婆有理”,针对某项议题,总难以得出一个确定的结论。之前对此的解释,是针对模型和量化结论的诠释上存在不确定性,从而得出夸大的结论。相比之下,数据分析应是客观中立的,至少在理想情况下是。但事实却非如此,已知的可能影响数据分析准确性的因素包括由于研究人员的能力不足导致的偏差,以及确认偏差,即研究者倾向于认同自己已认可的结论,从而导致分析过程中的偏差。
该研究招募了总计161名研究者(73个团队),其中46%的研究者来自社会学,25%来自政治科学,其余的研究者是跨学科或数据分析背景。161人中有83人曾教过数据分析的课程,70人曾在相关领域发表过研究。为评价研究者对待验证假设(更多的移民减少了公众对社会政策的支持)的态度,所有研究者还在分析数据前填写了相关问卷。
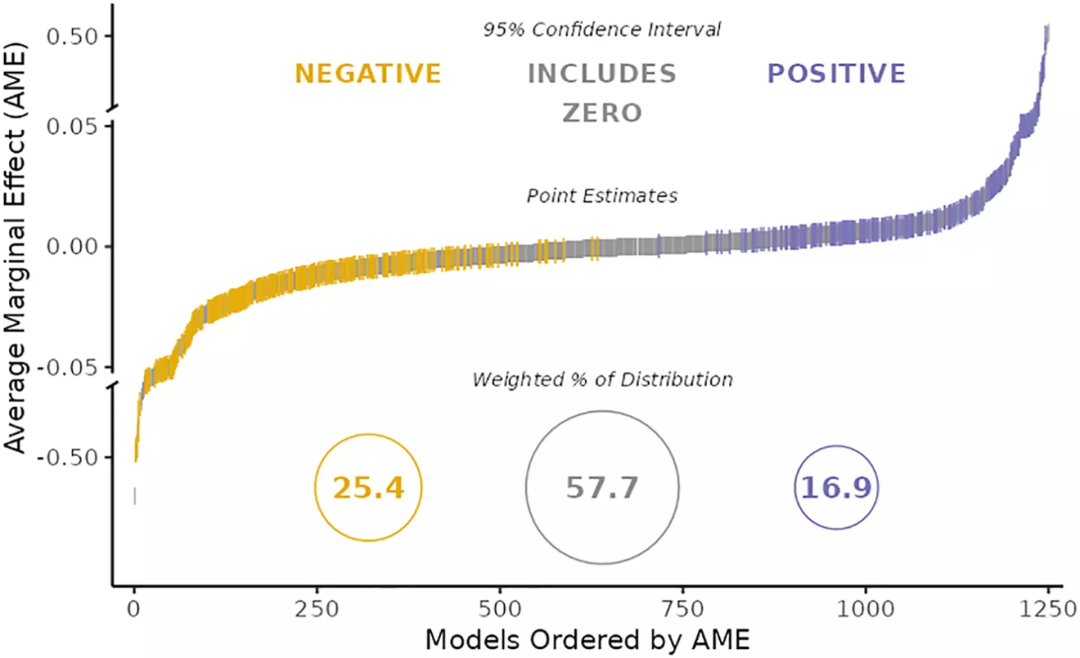
结果发现,使用相同的数据,不同团队得出的结果差异明显:57.7%的团队得出移民与公众对社会政策的支持无关,25.4%认为移民增加减少了公众对社会政策的支持,另外16.9%则得出了相反的结论。
图1:不同团队针对同一数据得出的结论差异,注意图中纵轴的刻度尺是对数化的,这意味着同一批数据,不同团队得到的差异显著不同
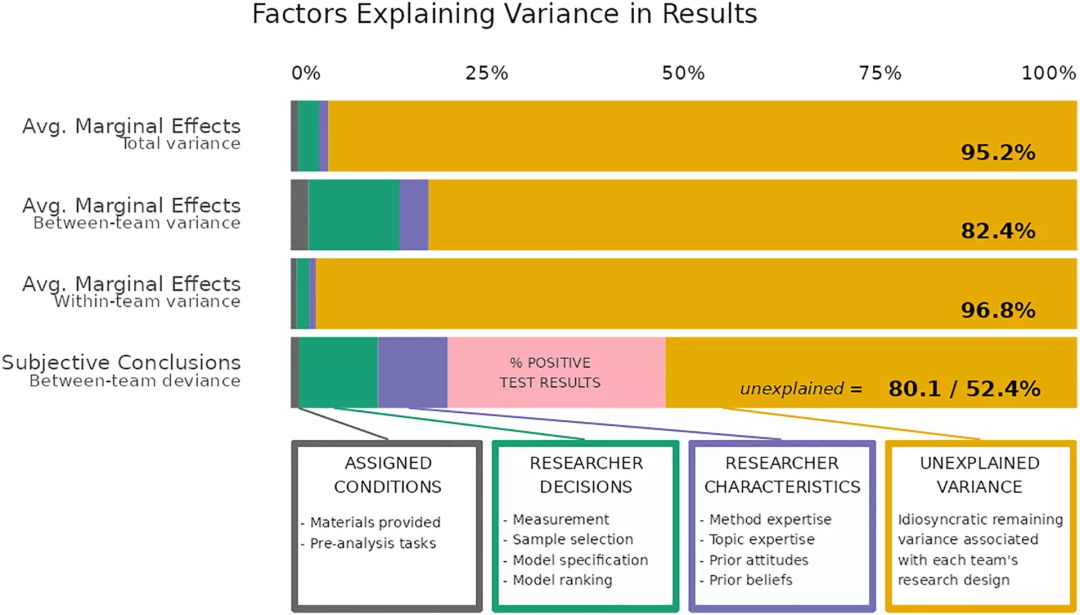
为了探究出现差别的原因,研究者检查了所有1,261个模型,并确定了166个与这些模型相关的不同研究设计决策。“决策”是指统计模型设计中的任何方面:例如,测量策略、估计量、层次结构、自变量或数据子集的选择。通过将分析中决策组合和分析结果进行回归分析,并将决策分为给予条件、研究者特征、研究者决策和未知因素,结果发现,研究结论的不同,绝大多数差异无法归因于一个特定的因素,而是由未知因素导致的。这一发现部分解释了为何政治相关的议题,近年来会呈现两级分化。
图2:全部差异、团队间、团队内差异可以被四种因素解释
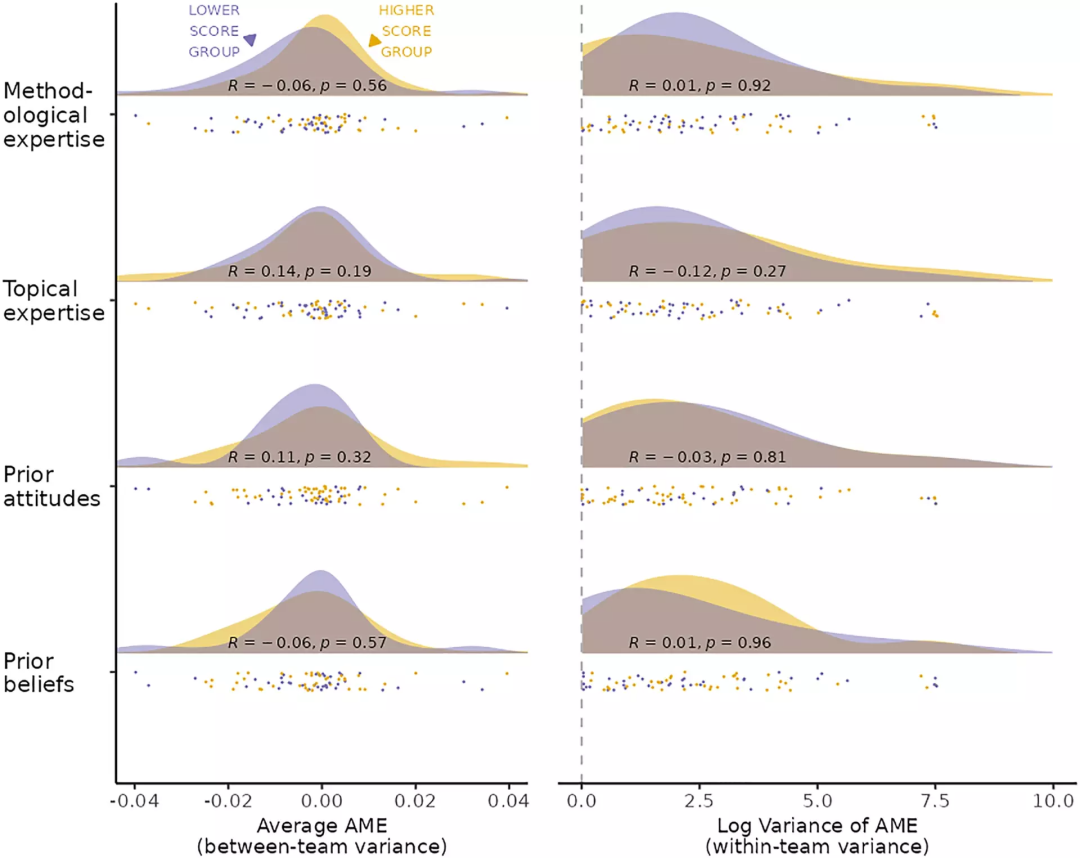
之后还分析了研究者具有的方法学或话题经验,以及对该问题的预设信念和态度与其所得出结论的差异,可以看到认为移民减少了公众对公共政策支持的研究者和持相反观点的研究者,在上述四种因素上的分布没有显著差异,也不存在相关性。这意味着研究者的预设观念可能不如之前以为的那样,会影响科研人员所得出的结论。
图3:研究者的特征无法解释不同团队或同一团队间的差异
该研究指出:即使是技术高超,不受预设偏见激励的科学家,当他们得到相同的数据和假设进行检验时,得到的结果也会有很大的不同。研究者有责任准确地描述和解释这个世界的本来面目,也有责任传达与其知识主张相关的不确定性。
该发现对社会科学的研究者有两点启示。首先,如果一项研究是由不同的研究人员或者甚至是同一个研究人员在不同的时间进行的,考虑到结果可能会有很大的不同,在根据看似客观的定量程序得出结论时,需要保有谦逊的认知态度。其次,对研究过程中的每一项决策都应该记录,因为即使是看起来微不足道的决策,也可能影响分析结果。
更广泛的视角来看,该研究呼吁社会学及相关的研究者更多地关注概念、因果假设和理论清晰度,做出更多有意识的努力,以补充方法论透明度与理论清晰度。该研究还指出在证据无法支持可做出决定的假设时,需要收集更多的证据,以确保研究结论能够反映事实。
This study explores how researchers’ analytical choices affect the reliability of scientific findings. Most discussions of reliability problems in science focus on systematic biases. We broaden the lens to emphasize the idiosyncrasy of conscious and unconscious decisions that researchers make during data analysis. We coordinated 161 researchers in 73 research teams and observed their research decisions as they used the same data to independently test the same prominent social science hypothesis: that greater immigration reduces support for social policies among the public. In this typical case of social science research, research teams reported both widely diverging numerical findings and substantive conclusions despite identical start conditions. Researchers’ expertise, prior beliefs, and expectations barely predict the wide variation in research outcomes. More than 95% of the total variance in numerical results remains unexplained even after qualitative coding of all identifiable decisions in each team’s workflow. This reveals a universe of uncertainty that remains hidden when considering a single study in isolation. The idiosyncratic nature of how researchers’ results and conclusions varied is a previously underappreciated explanation for why many scientific hypotheses remain contested. These results call for greater epistemic humility and clarity in reporting scientific findings.
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
【计算社会科学读书会】第二季由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,进行了12周的分享和讨论,一次闭门茶话会,两次圆桌讨论。本季读书聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、人类移动、新冠疫情、科学学研究等课题。读书会详情见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与学习。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动